

R语言聚类、文本挖掘分析虚假电商评论数据:K-Means(K-均值)、层次聚类、词云可视化
原创
聚类分析是一种常见的数据挖掘方法,已经广泛地应用在模式识别、图像处理分析、地理研究以及市场需求分析。本文主要研究聚类分析算法K-means在电商评论数据中的应用,挖掘出虚假的评论数据。
本文主要帮助客户研究聚类分析在虚假电商评论中的应用,因此需要从目的出发,搜集相应的以电商为交易途径的评论信息。对调查或搜集得到的信息进行量化录入处理,以及对缺失值过多的分析对象进行删除。之后进行多维度的数据描述。由于地图最多只能显示三维空间,而顾客指标属性很可能不止三个,因此在数据描述中可以进行单一指标与某个确定指标的二维展示,这样大致先了解客户分布。
最终,通过应用改进的K-means算法对数据进行挖掘,得出了直观有用的形象化结论,对之后公司管理层做销售决策提供了必要的依据。本次改进,也可以作为今后其他数据的参考,来进行其他数据的可靠挖掘,可以说提供了可靠的参照。
研究内容
本项目主要是针对现实中的市场营销与统计分析方法的结合,来挖掘潜在的客户需求。随着电子商务的发展和用户消费习惯改变,电商在销售渠道的比重将大大增强,2014年电商销售已经超过了店面销售的数量。因此,这为通过数据挖掘算法来分析客户的交易选择行为,将客户的喜好通过分类来组别,这样进一步能挖掘潜在客户和已交易客户的下一步潜在需求。
本文在基础的K-means聚类算法的基础上,结合该算法固有的一些缺陷,提出了一些改进措施,即通过改进的K-means聚类算法来对“B2C电商评论信息数据集”数据进行处理,在最终得到结果之后依据形象化的结论提出相应的公司决策,以满足市场的要求。
K-means的改进
文献[7]是Huang为克服K-means算法仅适合于数值属性数据聚类的局限性,提出的一种适合于分类属性数据聚类的K-modes算法"该算法对K-means进行了3点扩展:引入了处理分类对象的新的相异性度量方法(简单的相异性度量匹配模式),使用mode:代替means,并在聚类过程中使用基于频度的方法修正modes,以使聚类代价函数值最小化"这些扩展允许人们能直接使用K-means范例聚类有分类属性的数据,无须对数据进行变换"K-modes算法的另一个优点是modes,能给出类的特性描述,这对聚类结果的解释是非常重要的"事实上,K-modes算法比K-means算法能更快收敛,与K-means算法一样,K-modes算法也会产生局部最优解,依赖于初始化modes的选择和数据集中数据对象的次序。初始化modes的选择策略尚需进一步研究。
1999年,Huang等人[8]证明了经过有限次迭代K-modes算法仅能收敛于局部最小值。
K-medoids聚类算法的基本策略就是通过首先任意为每个聚类找到一个代表对象(medoid)而首先确定n个数据对象的k个聚类;(也需要循环进行)其它对象则根据它们与这些聚类代表的距离分别将它们归属到各相应聚类中(仍然是最小距离原则)。
综合考虑以上因素,本文考虑了孤立点。传统的聚类分析将全部点进行聚类,而不考虑可能存在的孤立点对聚类结果的干扰,这使得聚类结果缺乏可靠性和稳定性。对于聚类结果,需要进行判别分析,包括内分析和外分析。内分析主要是在聚类之后,点到类中心的阈值来寻找孤立点,从而剔除孤立点,保证样本和聚类中心的可靠性,在剔除了孤立点后需要重新计算类中心,如果出现极端情况,甚至有可能进行再一次聚类分析;外分析是指在确定好最终的聚类结果后,进行外样本预测,使聚类结果更加稳定。
分析
数据集与环境
本文的实验环境为Windows 7操作系统,R编程环境。同时选取了“B2C电商评论信息数据集”作为实验对象。这个数据集中包含了2370条B2C电商评论信息。
数据文件:

设计
在这里,为了提高算法效率,降低数据的稀疏性,本文首先导入文本数据,对该数据进行文本挖掘。筛选出所有评论中词频最高的前30个词汇,用作实验的聚类属性。
# == 分词+频数统计
words=unlist(lapply(X=data, FUN=segmentCN)); 每个高频词汇和其词频数据如下表所示:
|
word |
freq |
|---|---|
|
漂亮 |
547 |
|
喜欢 |
519 |
|
颜色 |
477 |
|
质量 |
474 |
|
丝巾 |
452 |
|
不错 |
435 |
|
好评 |
425 |
|
谢谢 |
277 |
|
非常 |
273 |
|
解释 |
263 |
|
愉快 |
237 |
|
生活 |
229 |
|
满意 |
226 |
|
继续 |
225 |
|
宝贝 |
222 |
|
美丽 |
217 |
|
一天 |
214 |
|
提供 |
214 |
|
努力 |
213 |
|
祝愿 |
212 |
|
衷心 |
212 |
|
赏赐 |
212 |
|
感恩 |
212 |
|
收到 |
211 |
|
没有 |
187 |
|
色差 |
141 |
|
好看 |
126 |
|
图片 |
120 |
|
可以 |
110 |
通过中文分词Rwordseg词频云软件包可以根据不同的词汇的词频高低来显示文本挖掘的高频词汇的总体结果。通过将词频用字体的大小和颜色的区分,我们可以明显地看到哪些词汇是高频的,哪些词汇的频率是差不多的,从而进行下一步研究。
实验采用上述数据集得到的高频词汇得到每个用户和高频词汇的频率矩阵。
|
记录 |
漂亮 |
喜欢 |
颜色 |
质量 |
丝巾 |
满意 |
|---|---|---|---|---|---|---|
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
2 |
0 |
1 |
0 |
0 |
0 |
0 |
|
3 |
1 |
1 |
0 |
0 |
0 |
0 |
|
4 |
1 |
1 |
0 |
0 |
0 |
0 |
|
5 |
0 |
0 |
0 |
0 |
1 |
0 |
|
6 |
1 |
0 |
0 |
0 |
0 |
0 |
|
7 |
1 |
0 |
0 |
0 |
0 |
0 |
|
8 |
0 |
0 |
1 |
0 |
0 |
0 |
|
9 |
0 |
2 |
0 |
0 |
0 |
0 |
|
10 |
0 |
0 |
0 |
0 |
0 |
1 |
|
11 |
0 |
1 |
1 |
0 |
1 |
0 |
|
12 |
0 |
0 |
0 |
0 |
0 |
0 |
|
13 |
1 |
0 |
0 |
2 |
1 |
1 |
|
14 |
0 |
0 |
0 |
0 |
0 |
0 |
|
15 |
1 |
1 |
0 |
1 |
0 |
0 |
|
16 |
0 |
1 |
0 |
0 |
0 |
0 |
|
17 |
1 |
0 |
1 |
1 |
1 |
0 |
|
18 |
0 |
0 |
0 |
0 |
0 |
0 |
用户词汇频率矩阵表格的一行代表用户的一条评论,列代表高频词汇,表中的数据代表该条评论中出现的词汇频率。
结果及分析
K-均值聚类算法的虚假评论聚类结果
用K-mean进行分析,选定初始类别中心点进行分类。
一般是随机选择数据对象作为初始聚类中心,由于kmeans聚类是无监督学习,因此需要先指定聚类数目。
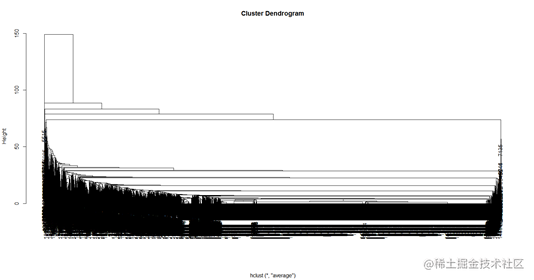
层次聚类是另一种主要的聚类方法,它具有一些十分必要的特性使得它成为广泛应用的聚类方法。它生成一系列嵌套的聚类树来完成聚类。
从树的直观表示来看,当height取80的时候,树的分支可以大概分成2类,分成的类别比较清楚和直观,因此我们去k等于2,分别对应虚假评论和真实评论。
K-means算法得到的聚类中心
#查找虚假评论
#比较典型的识别方式
# 看文字,什么非常好,卖家特别棒,我特满意,以后还会来等等,写一大堆文字,但是没有对产品有实质性描述的,一般是刷的,这一点是主要判断依据,因为刷单的人一般要写很多家的评价,所以他不会对产品本身做任何评论,全都是一些通话套话。
fake1= grep(pattern="非常好" ,data);
fake2= grep(pattern="卖家特
for(j in 1:length(index)){
jj=which(dd[,1]==index[j])
rating[i,colnames(rating)==index[j]]=dd[]]#高频词汇的数量赋值到评价矩阵