


python绘图-seaborn绘图的基本使用

Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
本文用到的数据集均为seaborn内置数据集,若需要下载可以从下面链接下载。
1.seaborn设置整体风格 mwaskom/seaborn-data 1.seaborn设置整体风格
Seaborn共提供5种主题风格,分别为darkgrid、whitegrid、dark、 white以及ticks。利用set()和set_style()两个函数对整体风格进行控制。
定义一个绘图函数:
import seaborn as sns
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
# 定义一个绘图函数
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 7):
plt.plot(x, np.sin(x + i*.5)*(7-i)*flip)
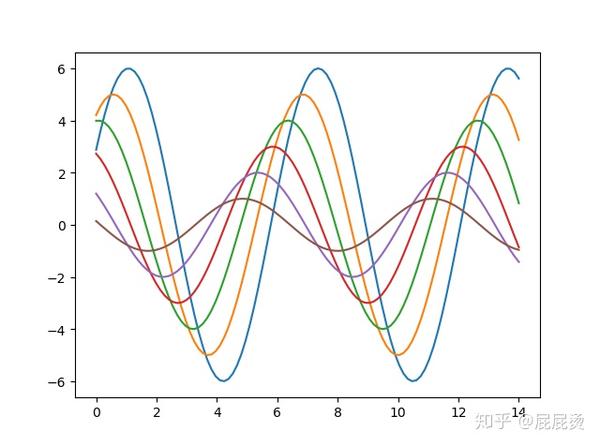
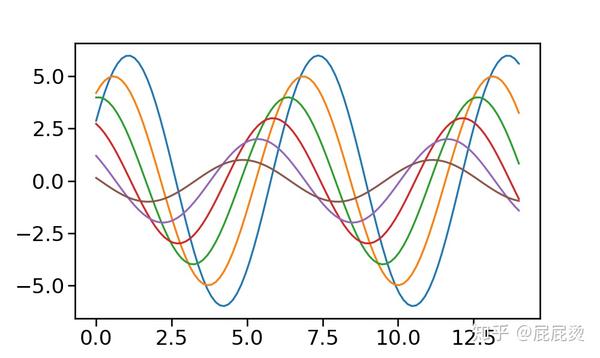
选择风格,默认情况下为darkgrid风格。
# 默认设置
sns.set() # 使用seaborn的默认设置
sinplot()
plt.show()输出为:

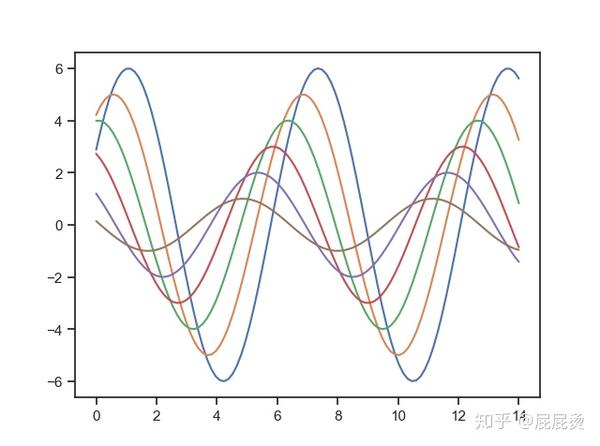
选择风格为ticks
# 设置风格为ticks
# 可以直接通过参数名传参,也可以通过set_style()传参
# 效果同:set_style('ticks')
sns.set(style='ticks')
sinplot()
plt.show()输出为:
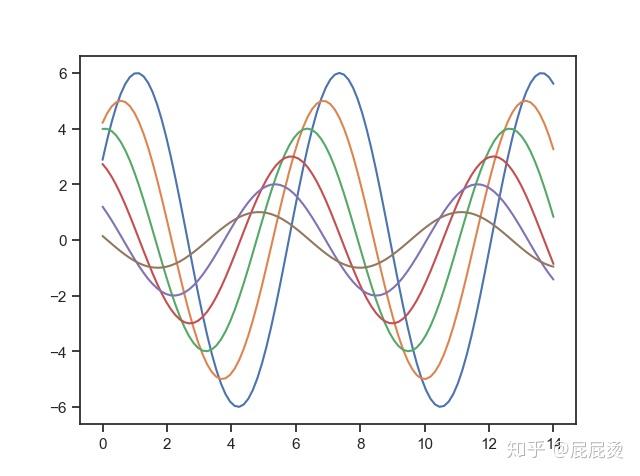
选择风格为whitegrid
sns.set_style('whitegrid')
sinplot()
plt.show()输出为:
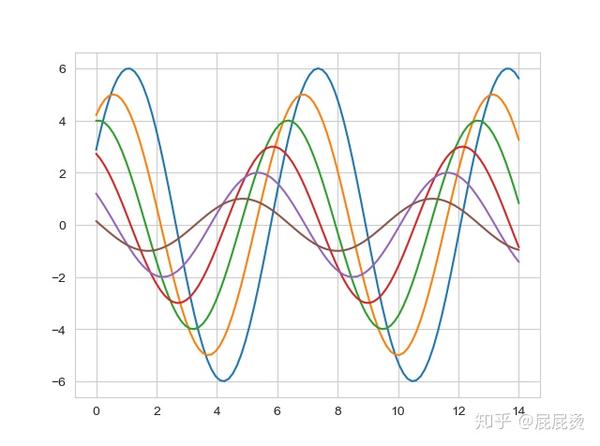
其他主题设置风格类似, 可通过set(style=" ")方式,也可以通过set_style( " " )的方式设置。 具体可使用 print(help(sns.set)) 函数查看帮助文档。
2.seaborn设置细节风格
设置边框:
# 边框设置
sinplot()
sns.despine() # 去掉边框,默认去掉上边框和右边框
plt.show()输出:
也可以通过参数名传参,来决定哪个边框不显示。
sinplot()
sns.despine(bottom=True, right=True) # True代表不显示
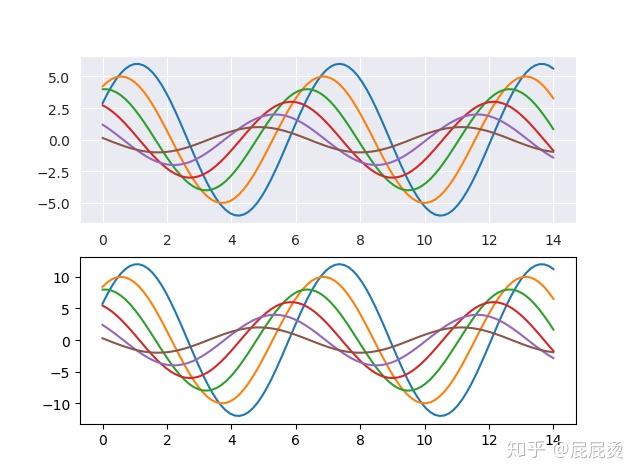
plt.show()设置子图风格
# 对子图设置不同风格
with sns.axes_style('darkgrid'):
plt.subplot(211) # 对第一个子图设置风格darkgrid
sinplot()
plt.subplot(212)
sinplot(2)
plt.show()
# 通过关键字with,对不同子图设置风格输出:
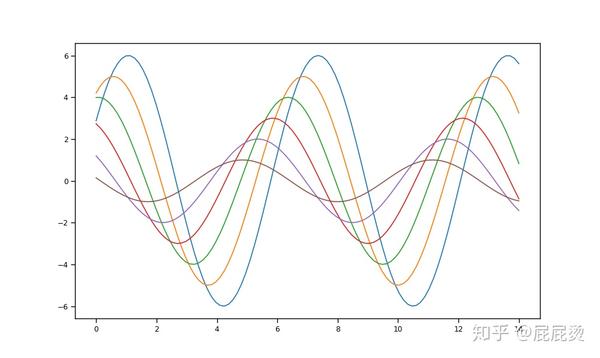
设置内容
# 对图中内容进行设置,包括线条颜色,粗细和刻度等
sns.set_context("paper") # 使用paper风格
plt.figure(figsize=(10, 6))
sinplot()
plt.show()输出:
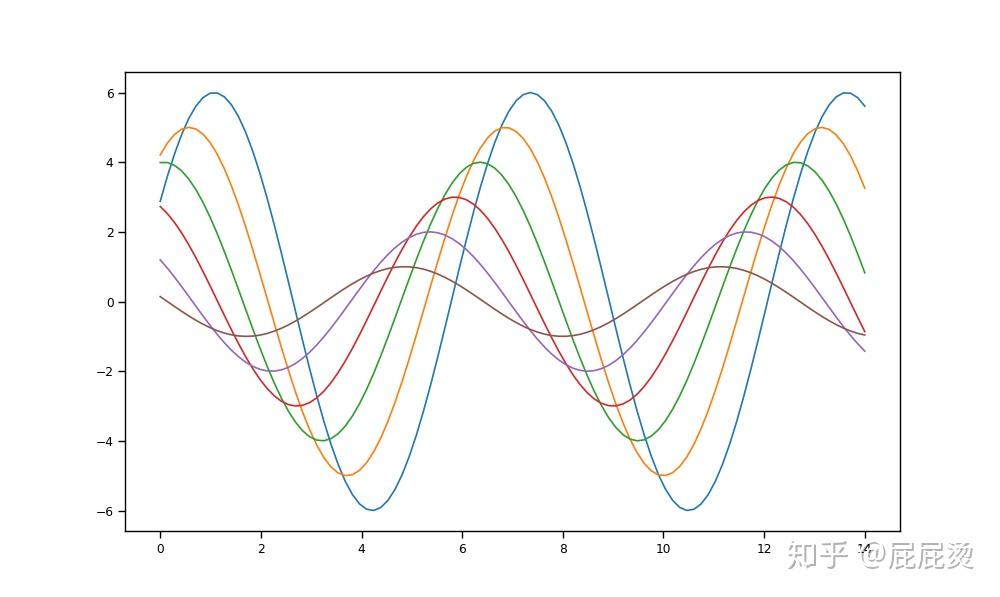
字体、线宽设置
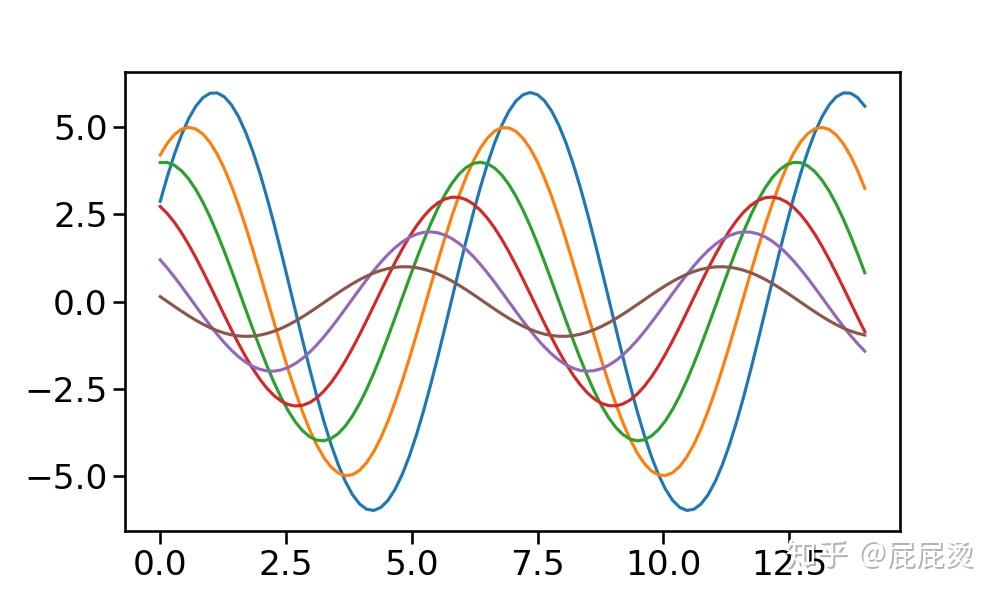
sns.set_context("talk", font_scale=1.5, rc={'line.linewidth':2.5}) # 使用talk风格
plt.figure(figsize=(10, 6))
sinplot()
plt.show()输出:
3.调色板的使用
seaborn主要提供分类色板、颜色空间、连续色板和xkcd等操作,对图像颜色进行设置。
分类色板
主要涉及以下函数:
- color_palette() 能传入任何Matplotlib所支持的颜色
- color_palette() 不传入参数则为默认颜色
- set_palette() 设置所有图的颜色
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(rc={'figure.figsize': (6, 6)}) # 设置画板大小
# 分类色板
current_palette = sns.color_palette() #默认是deep,深色风
sns.palplot(current_palette)
sns.palplot(sns.color_palette("muted")) #柔和风
sns.palplot(sns.color_palette("pastel",9)) #粉蜡笔风
sns.palplot(sns.color_palette("bright",10)) #明亮风
sns.palplot(sns.color_palette("dark",11)) #黑暗风
sns.palplot(sns.color_palette("colorblind",12)) # 色盲风
# 6个默认的颜色循环主题: deep, muted, pastel, bright, dark, colorblind
plt.show()










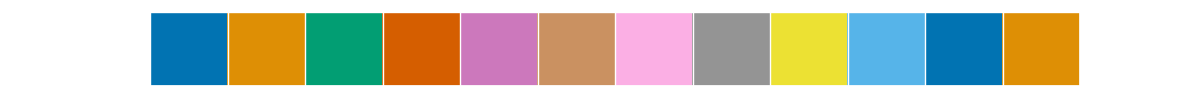
颜色空间
颜色空间主要通过hls_palette()函数来控制颜色的色调、亮度和饱和
- h-色调 hue
- l-亮度 lightness
- s-饱和 saturation
sns.palplot(sns.hls_palette(8,h=.8, l=.7, s=.9))
sns.palplot(sns.hls_palette(8,h=0.1, l=.3, s=.6))
#sns.hls_palette设置得到HLS的色彩空间中的颜色,颜色个数,
# h设置色调,
# l设置亮度,
# s设置饱和度,
# 取值范围均在(0,1)
plt.show()输出:




# 设置成对的,相近颜色
sns.palplot(sns.color_palette("Paired",10))
# 按对分组,每一对之间属同一色系中的差异较大的两个颜色
# 对于对之间属于不同色系的颜色
plt.show()

xkcd颜色
xkcd包含了一套针对随机RGB色的命名。产生了954个可以通过xdcd_rgb字典中调用的命名颜色。
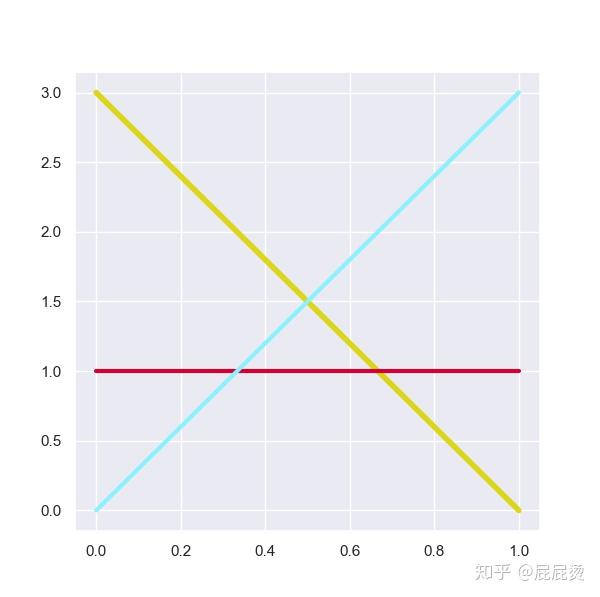
# xkcd通过skcd_rgb设置颜色
plt.plot([0, 1], [3, 0], sns.xkcd_rgb["piss yellow"], lw=4)
plt.plot([0, 1], [1, 1], sns.xkcd_rgb["cherry"], lw=3)
plt.plot([0, 1], [0, 3], sns.xkcd_rgb["robin egg blue"], lw=3)
# 通过颜色名字来调用颜色,
# 也可以通过颜色的16进制编码调用颜色
# lw : linewidth设置
plt.show()输出:

# xkcd 通过颜色名称设置颜色
colors = ["windows blue", "amber", "greyish", "faded green", "dusty purple"]
sns.palplot(sns.xkcd_palette(colors))
plt.show()输出:


连续色板
色彩随数据变换,比如数据越来越重要则颜色越来越深。
# 设置渐变色
sns.palplot(sns.color_palette("Blues")) #设置某种颜色的一系列渐变色
sns.palplot(sns.color_palette("Blues_r",8)) # blues_r 反向
plt.show()输出:




# 设置light风格的渐变色
#使用函数light_palette函数,设置连续色板的风格
sns.palplot(sns.light_palette("green")) # 设置light风格的绿色渐变
# 设置dark风格的渐变色
# 使用dark_palette函数设置dark风格的渐变
sns.palplot(sns.dark_palette("purple")) # 设置dark风格的紫色
# 设置渐变的颜色排列顺序
# reverse参数设置渐变的排列顺序
sns.palplot(sns.light_palette("navy", reverse=True)) #reverse可以设置颜色排列顺序
plt.show()输出:






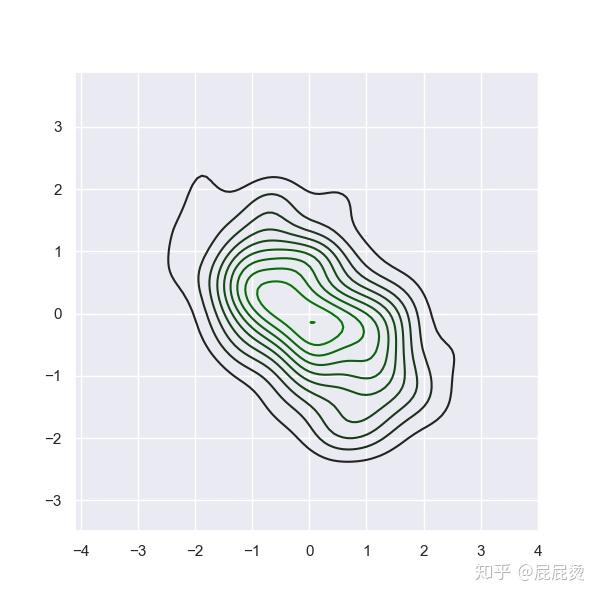
渐变色简单应用
# 渐变色简单易用
# 生成一个多元正态分布矩阵
# 参数mean : 均值
# 参数cov : 协方差, array类型
# 参数size: 个数
x, y = np.random.multivariate_normal(mean=[0, 0], cov=[[1, -.5], [-.5, 1]], size=300).T
pal = sns.dark_palette("green",as_cmap=True)
# as_cmap=True,返回一个colormap对象
sns.kdeplot(x, y, cmap=pal)
# kdeplot : 核密度估计图,
# cmap=pal,以colormap方式来设置颜色
plt.show()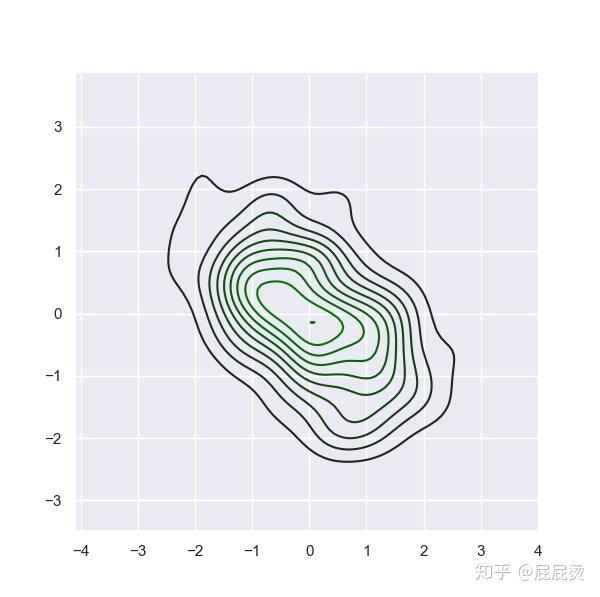
4.单变量分析图
import numpy as np
import pandas as pd
from scipy import stats, integrate
import matplotlib.pyplot as plt
import seaborn as sns
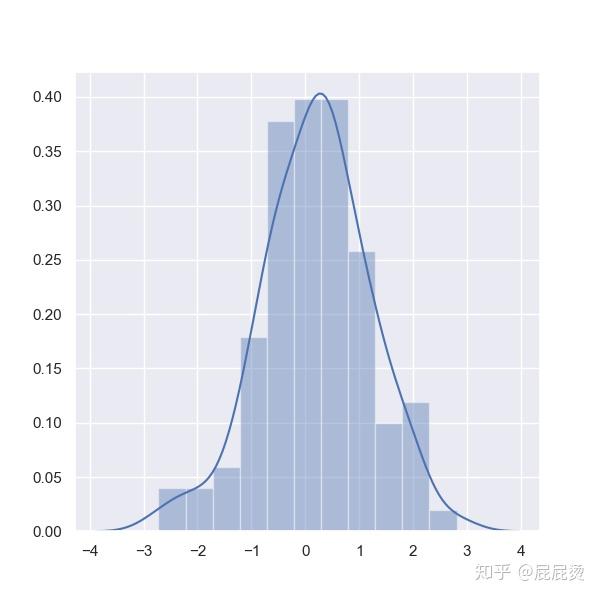
# 频数直方图
# 生成100个成标准正态分布的随机数
x = np.random.normal(size=100)
# sns.distplot画频数直方图
# kde=True,进行核密度估计
sns.distplot(x,kde=True)
plt.show()输出:
设置频数直方图的bins
sns.distplot(x, bins=20, kde=False)
plt.show()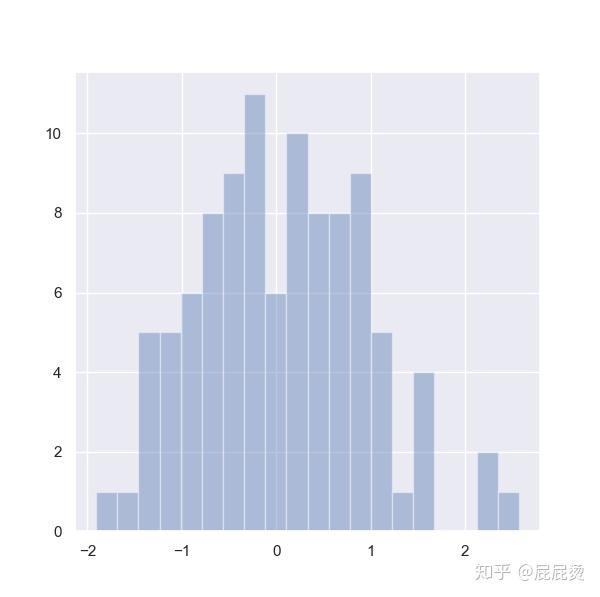
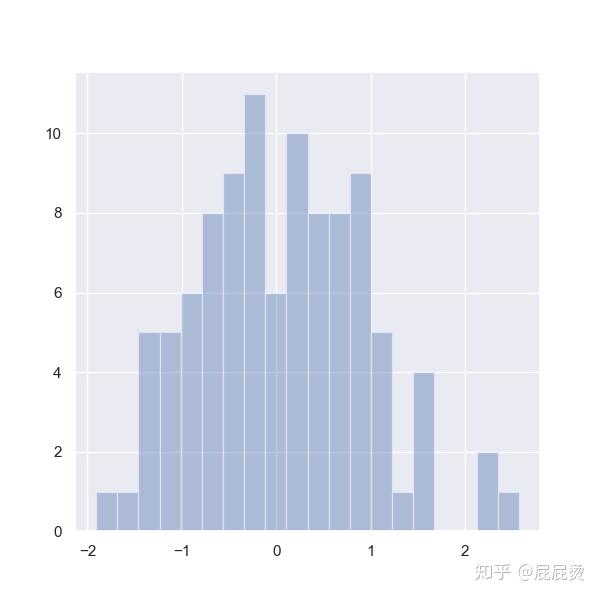
分析数据分布情况
# 数据分布情况
# kde核密度估计,
# fit拟合参数(黑色线条)
# 蓝色线条为核密度估计线条
sns.distplot(x, kde=True, fit=stats.alpha)
plt.shoe()输出:
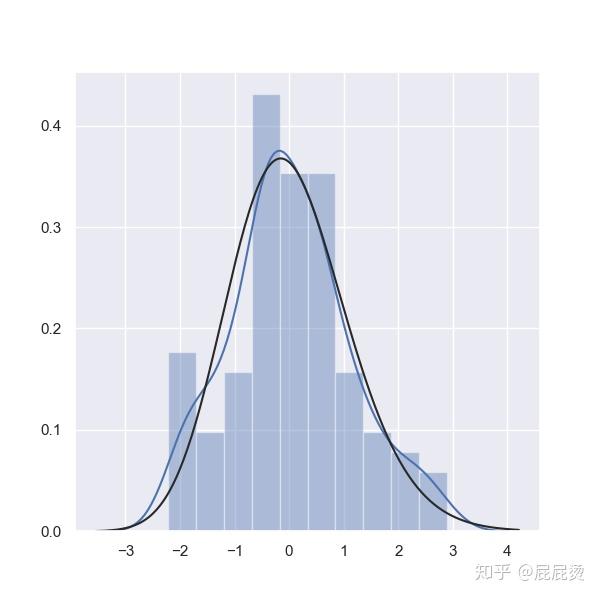
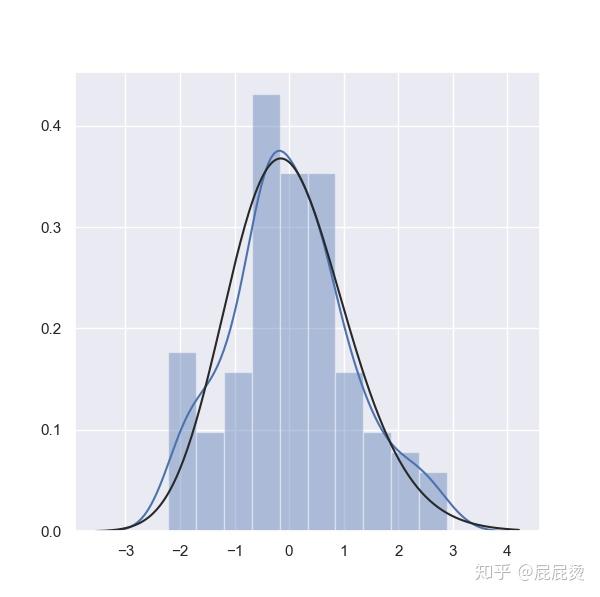
5.双变量分析图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
mean, cov = [0, 1], [(1, .5), (.5, 1)]
# 二维多正态分数的数据
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"]) #将array结构转换为dataframe结构,添加列名散点图
# 散点图
# 一般用散点图展示两个变量间的关系
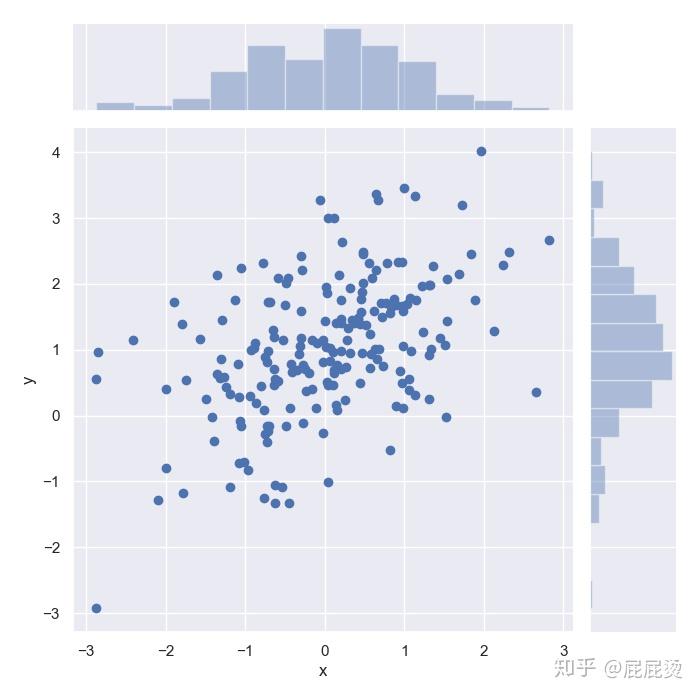
sns.jointplot(x='x', y='y', data=df, size=7) # x,y参数也可以用x=df['x'], y=df['y'] 的形式传入
# sns.jointplot画双变量关系图,
# data传入dataframe,x,y设置两个变量数据,
# size设置图的大小
plt.show()输出:
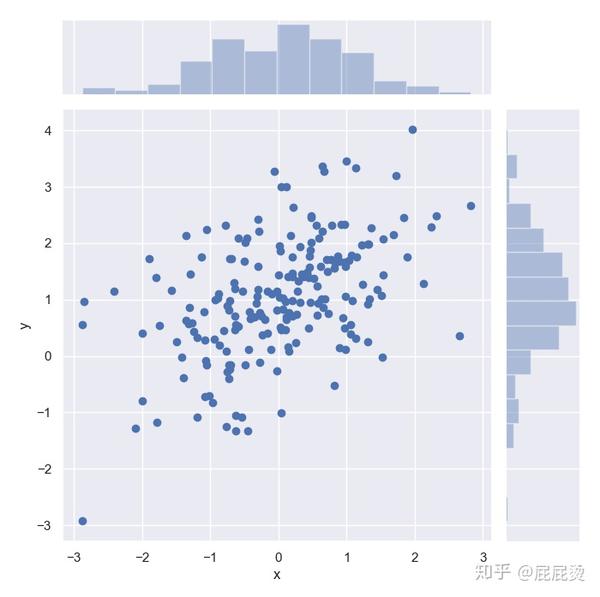
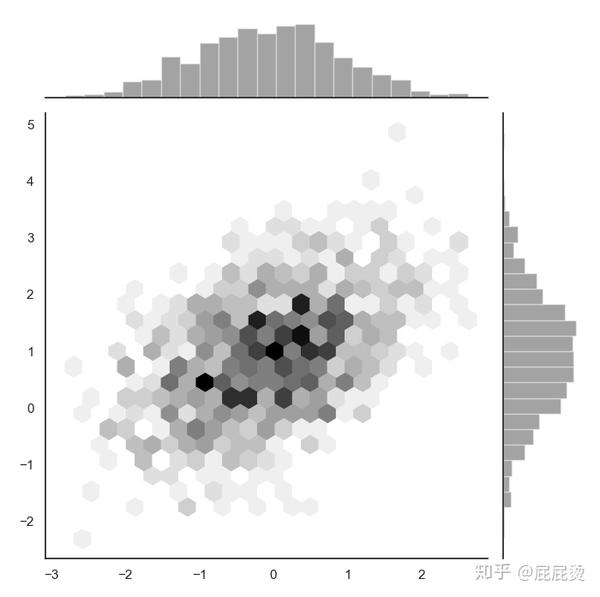
六角图
# 六角图
x, y = np.random.multivariate_normal(mean, cov, 1000).T
# 设置画图风格
with sns.axes_style("white"):
sns.jointplot(x=x, y=y, kind="hex", color="k", size = 7)
# kind='hex' 画出六角图
# 六角图中颜色越深的区域表示该区域的点越密集,数据越多
plt.show()输出:
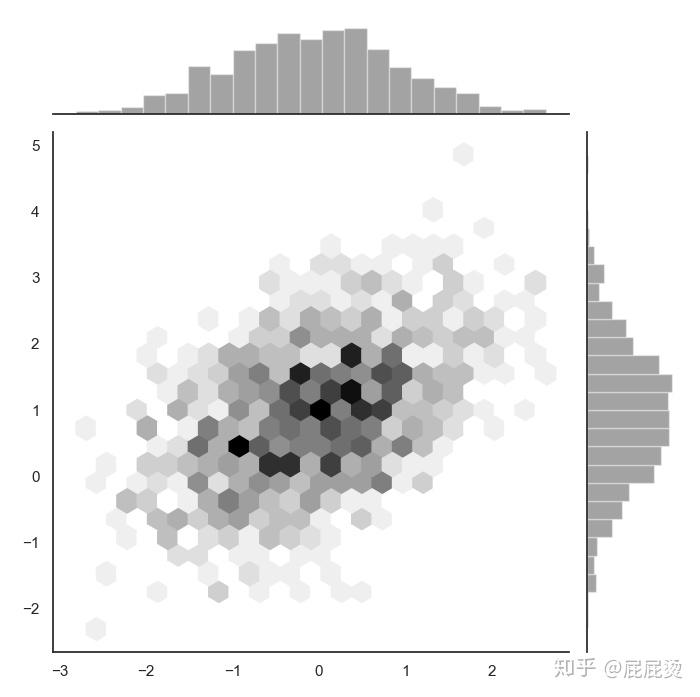
pairplot函数
# pairplot函数
# 分析多个变量间,每两个变量间的关系
# 不同变量间用散点图表示
# 同一变量用直方图表示
iris=pd.read_csv(r'..\iris.csv')
数据时以逗号为分隔符的,
但是这个数据没有列的名字,
所以先给每个列取个名字,
直接使用数据说明中的描述
iris.columns = ['sepal_len', 'sepal_width', 'petal_len', 'petal_width', 'class']
print (iris.head())
sns.pairplot(iris)
plt.show()输出:
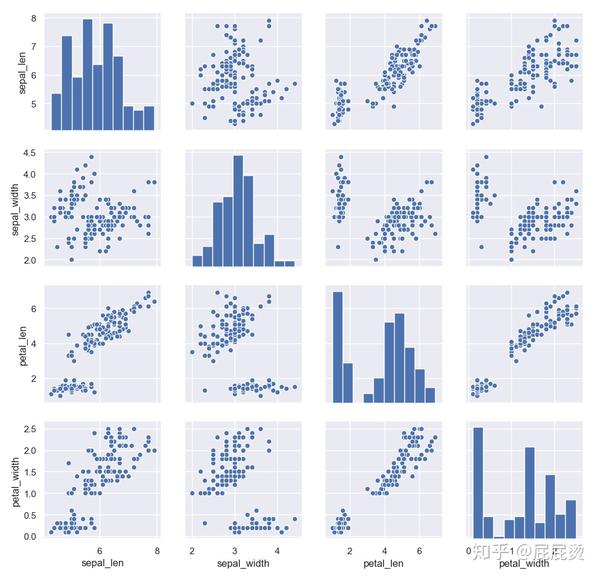
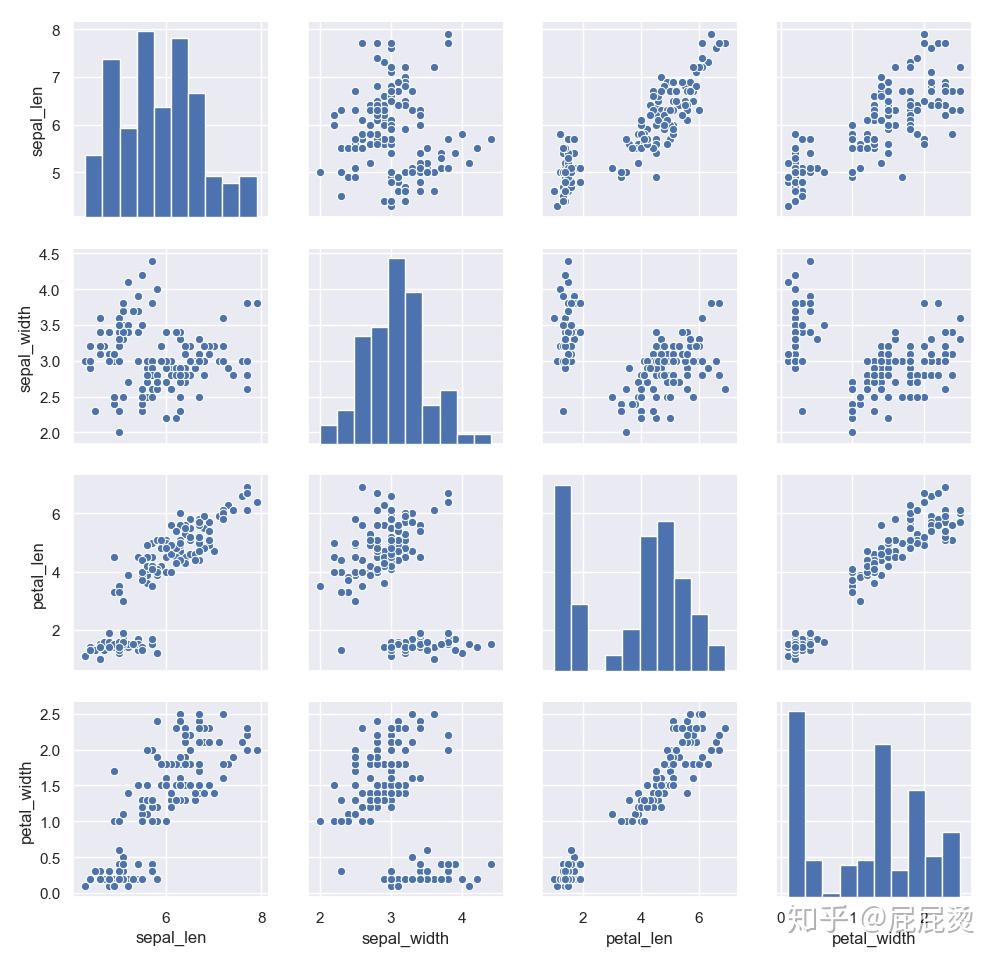
6.双变量回归分析图
两变量回归关系regplot实现
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
# 内置数据集tips小费
tips = pd.read_csv(r'..\tips.csv')
tips.head()
# 两变量画回归关系图(regplot函数)
# regplot()和lmplot()都可以绘制回归关系,推荐regplot()
plt.figure(figsize = (7,7))
sns.regplot(x="total_bill", y="tip", data=tips)
# sns.regplot画数据散点和线性拟合的图,
# 设置x坐标,y坐标,data传入dataframe
plt.show()输出:
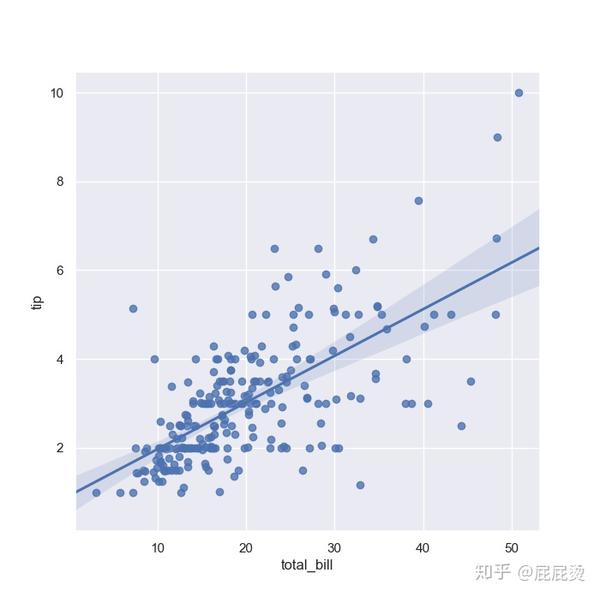
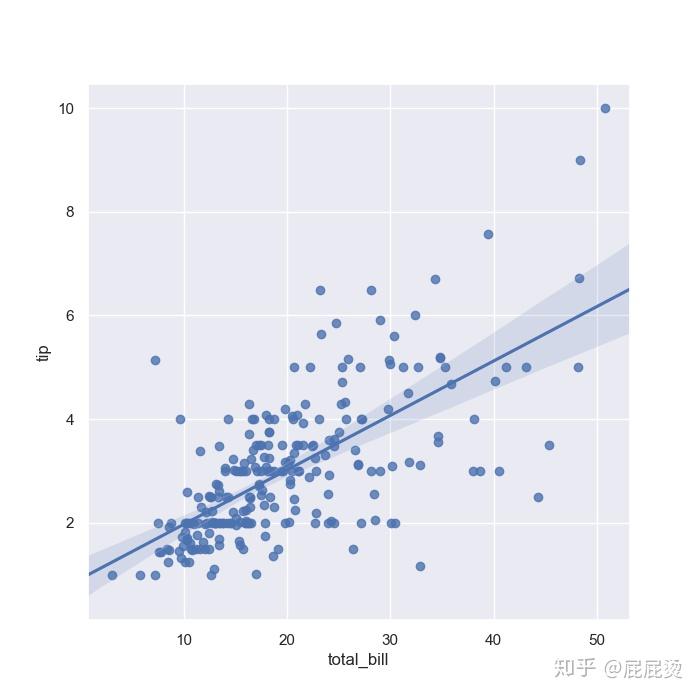
两变量回归关系图lmplot实现
# 两变量画回归关系图(lmplot函数)
sns.lmplot(x="total_bill", y="tip", data=tips,size = 7)输出:
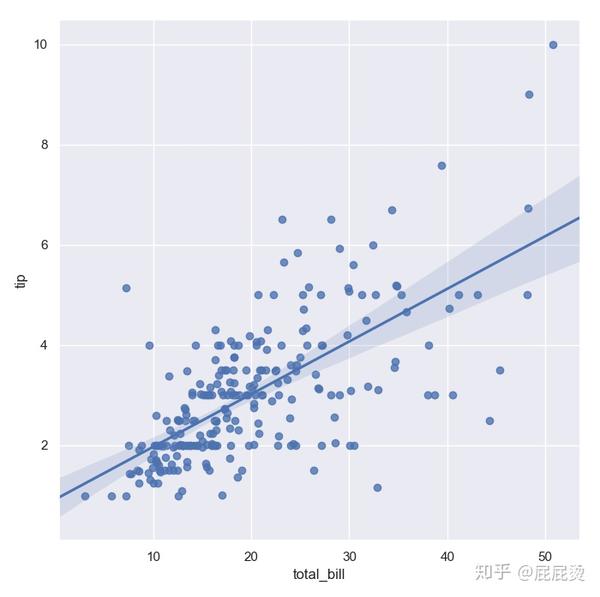
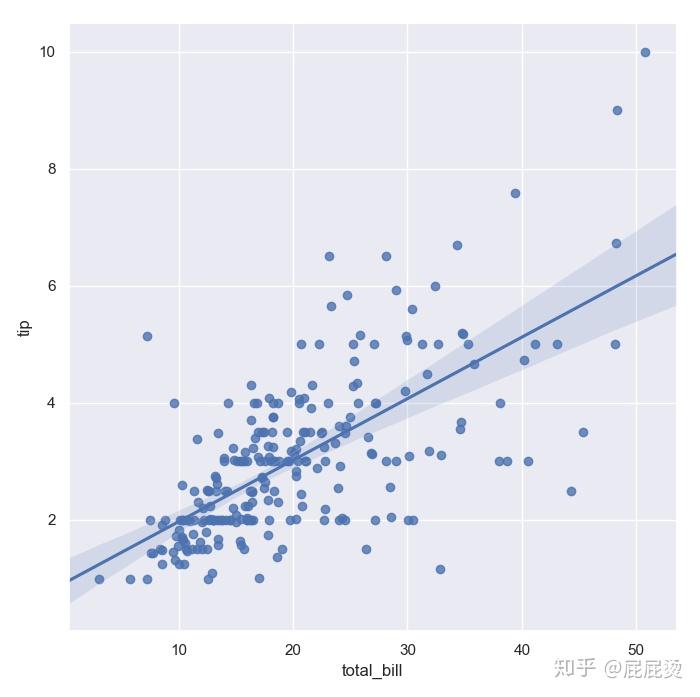
抖动设置
# 设置横向抖动
# x_jitter参数设置点横向抖动量。
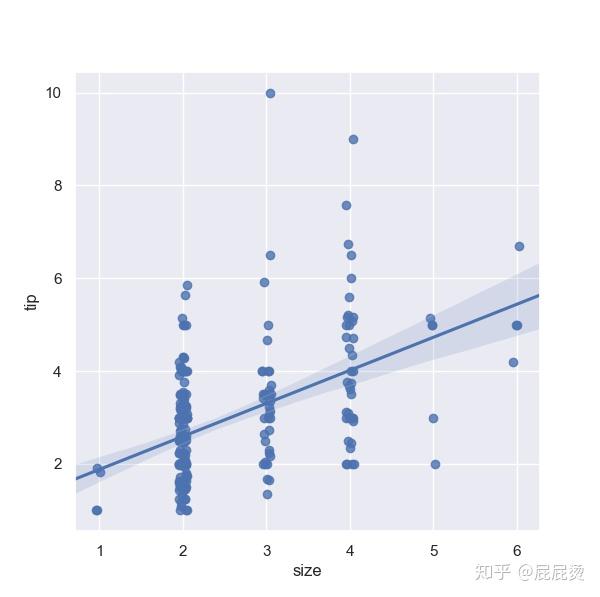
sns.regplot(x="size", y="tip", data=tips, x_jitter=.05)
# 部分数据重叠,因此设置抖动,减少覆盖点,便于观察点的分布输出:

7.多变量回归分析图
# 数据读取
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
# 设置风格
sns.set(style="whitegrid")
# 数据加载
titanic = sns.load_dataset("titanic")
tips = sns.load_dataset("tips")
iris = sns.load_dataset("iris")分类散点图stripplot()实现(两变量)
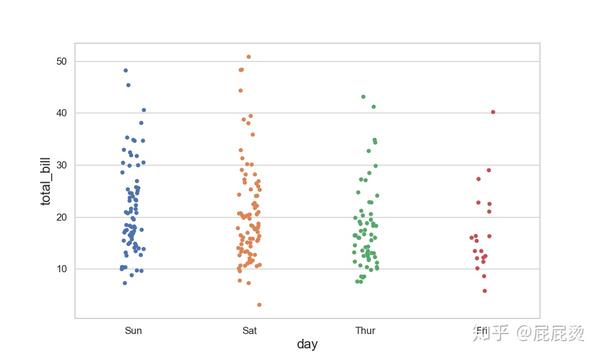
# 分类散点图(两变量:day,total_bill)
# sns.stripplot()和sns.swarmplot()均能实现分类散点图
plt.figure(figsize=(10,6))
# 图型基本设置
plt.xticks(size=12)
plt.yticks(size=12)
plt.xlabel('day',size=16)
plt.ylabel( 'total_bill',size=16)
# 分析day与total_bill间的关系
sns.stripplot(x="day", y="total_bill", data=tips)
plt.show()输出:

分类散点图三变量实现
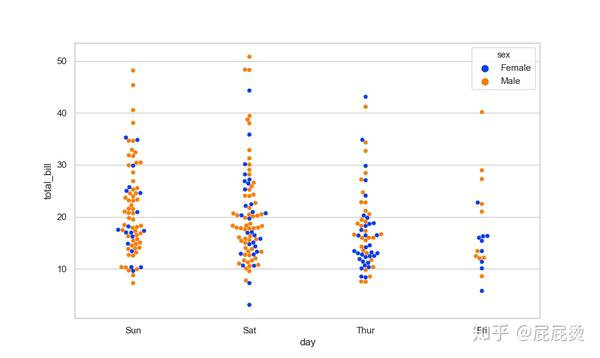
# 分类散点图(三变量:day, total_bill, sex)
# 传入的第三个变量,通过颜色区分
plt.figure(figsize=(10,6))
palette1=sns.color_palette("bright")
# hue设置第三个变量,palette设置调色板颜色
sns.swarmplot(x="day", y="total_bill", hue="sex",palette = palette1,data=tips)
plt.show()输出:
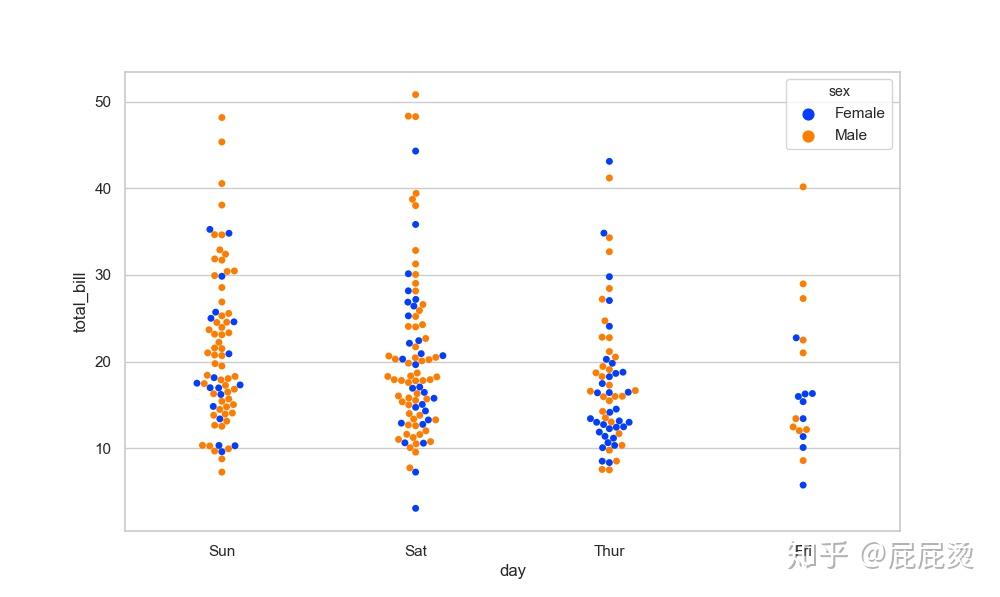
# 分类散点图(三变量:day, total_bill, time)
plt.figure(figsize=(10,6))
# hue接收第三个变量
sns.swarmplot(x="total_bill", y="day", hue="time", data=tips)
plt.show()输出:
盒图(三变量)
盒图是显示数据离散度的一种图形。它对于显示数据的离散的分布情况效果不错。
IQR = Q3-Q1,即上四分位数与下四分位数之间的差,也就是盒子的长度。
N = 1.5IQR 如果一个值>Q3+N或 < Q1-N,则为离群点
盒图特点:
通过盒图,在分析数据的时候,盒图能够有效地帮助我们识别数据的特征:
直观地识别数据集中的异常值(查看离群点)。
判断数据集的数据离散程度和偏向(观察盒子的长度,上下隔间的形状,以及胡须的长度)。
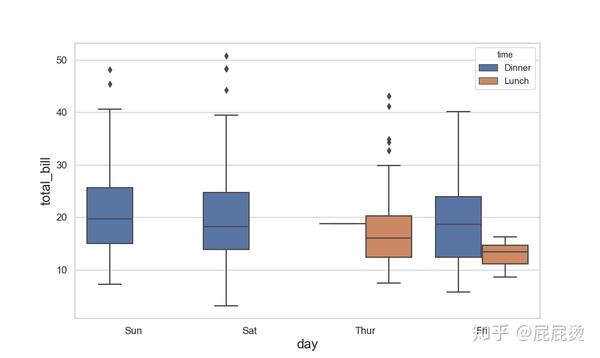
# 盒图(三变量:day,total_bill, time)
# sns.boxplot()
# 盒图是显示数据离散度的一种图形。它对于显示数据的离散的分布情况效果不错。
# IQR = Q3-Q1,即上四分位数与下四分位数之间的差,也就是盒子的长度。
# N = 1.5IQR 如果一个值>Q3+N或 < Q1-N,则为离群点
# 盒图特点:
# 通过盒图,在分析数据的时候,盒图能够有效地帮助我们识别数据的特征:
# 直观地识别数据集中的异常值(查看离群点)。
# 判断数据集的数据离散程度和偏向(观察盒子的长度,上下隔间的形状,以及胡须的长度)。
# 基本设置
plt.figure(figsize=(10,6))
plt.xticks(size=12)
plt.yticks(size=12)
plt.xlabel('day',size=16)
plt.ylabel( 'total_bill',size=16)
sns.boxplot(x="day", y="total_bill", hue="time", data=tips)
plt.show()输出:
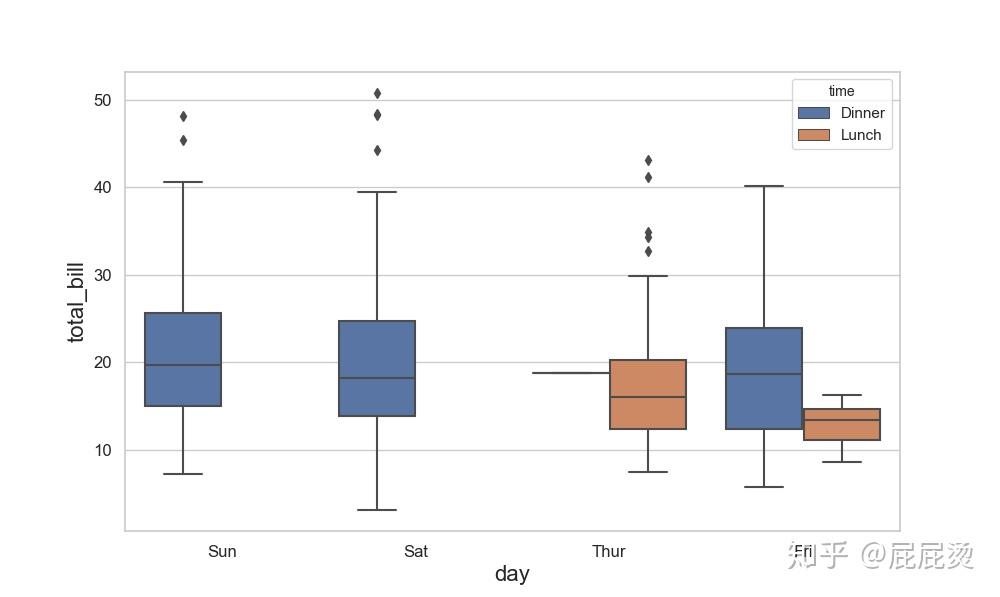
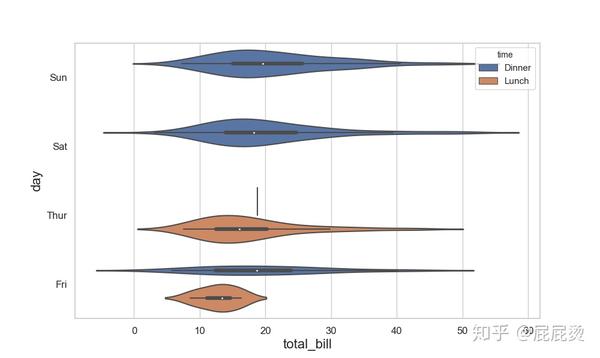
小提琴图(三变量)
# 小提琴图(三变量:day, total_bill, time)
# sns.violinplot()函数实现
plt.figure(figsize=(10,6))
plt.xticks(size=12)
plt.yticks(size=12)
plt.xlabel('total_bill',size=16)
plt.ylabel( 'day',size=16)
# sns.violinplot()画小提琴图
sns.violinplot(x="total_bill", y="day", hue="time", data=tips)
# 图中白点是中位数,
# 中间黑色盒形是上四分位点和下四分位点,
# 黑色的线条表示离群点的离群程度,越长表示离群点越远
plt.show()输出:
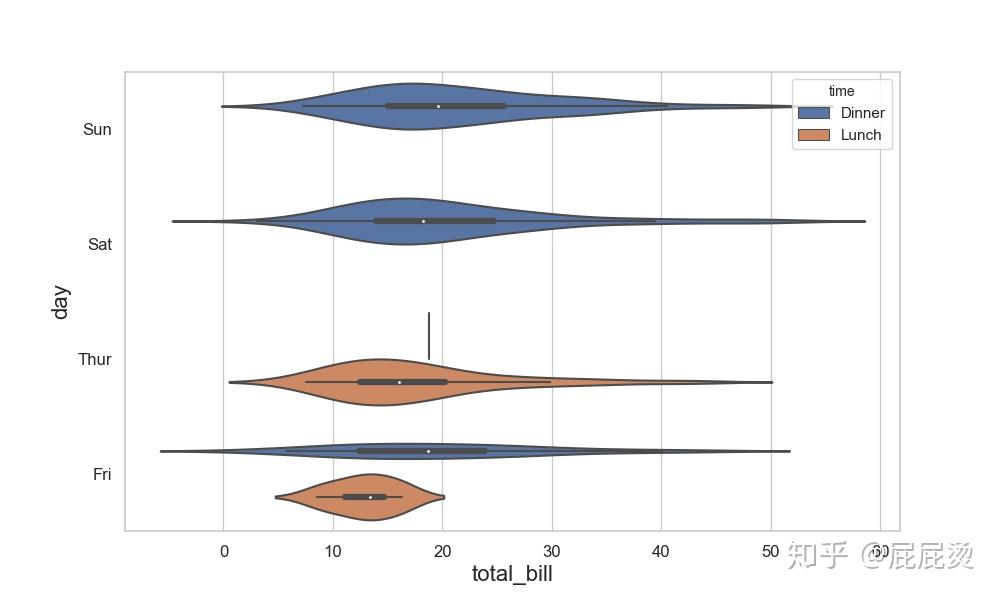
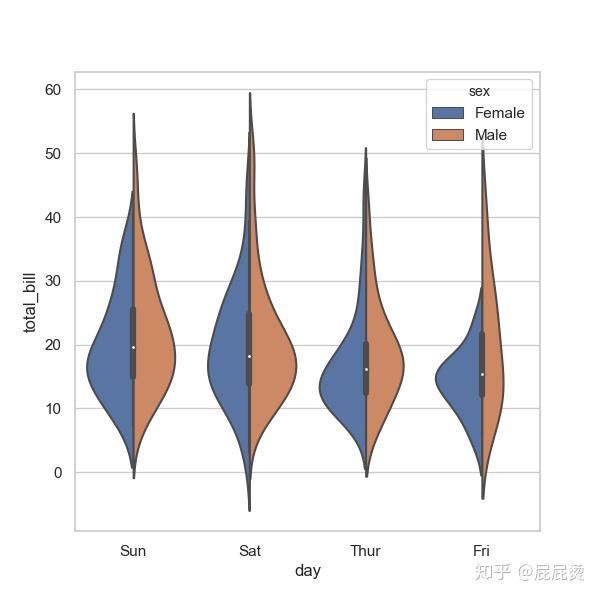
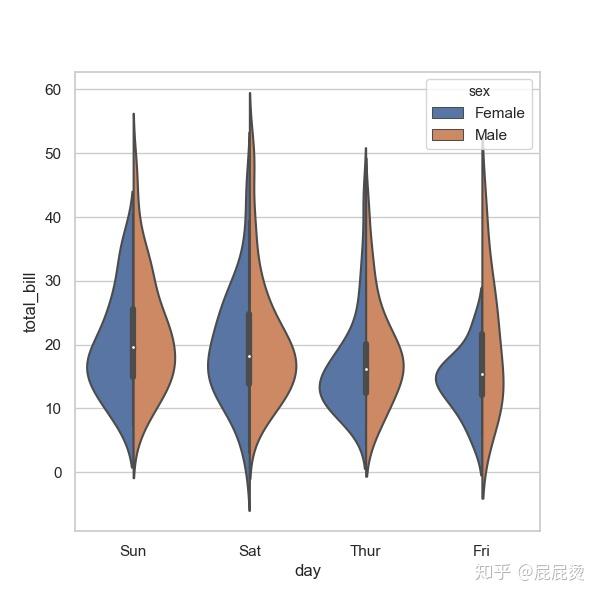
# 小提琴图设置(三变量:day, total_bill, sex)
# split设置左右区分
sns.violinplot(x="day", y="total_bill", hue="sex", data=tips, split=True)
plt.show()输出:
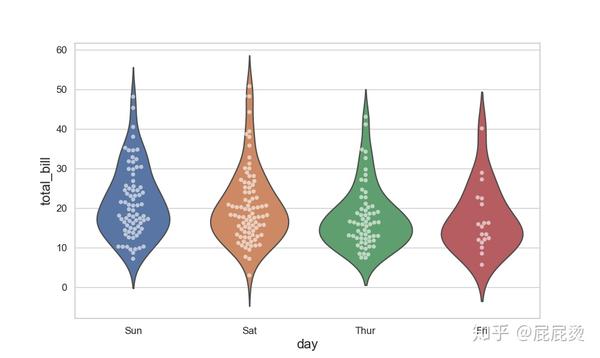
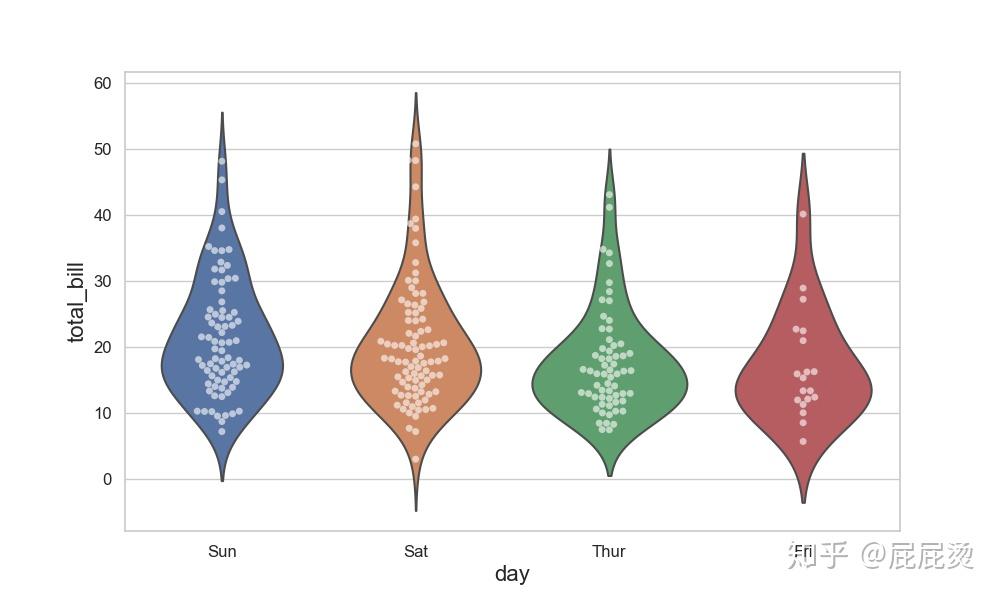
小提琴图和分类散点图组合
# 小提琴图和分类散点图组合
# 基本设置
plt.figure(figsize=(10,6))
plt.xticks(size=12)
plt.yticks(size=12)
plt.xlabel('total_bill',size=16)
plt.ylabel( 'day',size=16)
# inner设置是否显示中间的盒形和线条
sns.violinplot(x="day", y="total_bill", data=tips, inner=None)
# alpha设置透明度
sns.swarmplot(x="day", y="total_bill", data=tips, color="w", alpha=.6)
plt.show()输出:
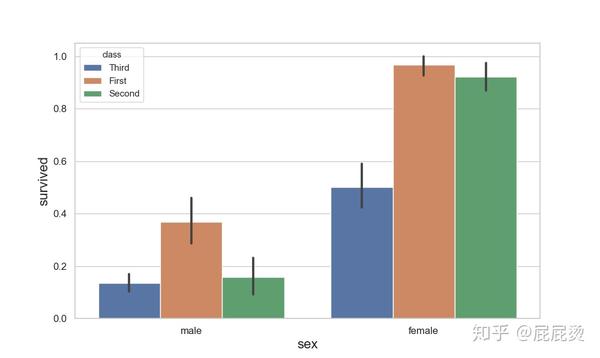
平均数条形图(三变量)
# 平均数条形图(三变量:sex, survived, class)
# sns.barplot()函数实现平均数条形图
# 基本设置
plt.figure(figsize=(10,6))
plt.xticks(size=12)
plt.yticks(size=12)
plt.xlabel('sex',size=16)
plt.ylabel( 'survived',size=16)
sns.barplot(x="sex", y="survived", hue="class", data=titanic,ci=95)
#黑色线条表示置信度,
# ci 设置黑色线条的大小,范围在[0,100]
plt.show()输出:
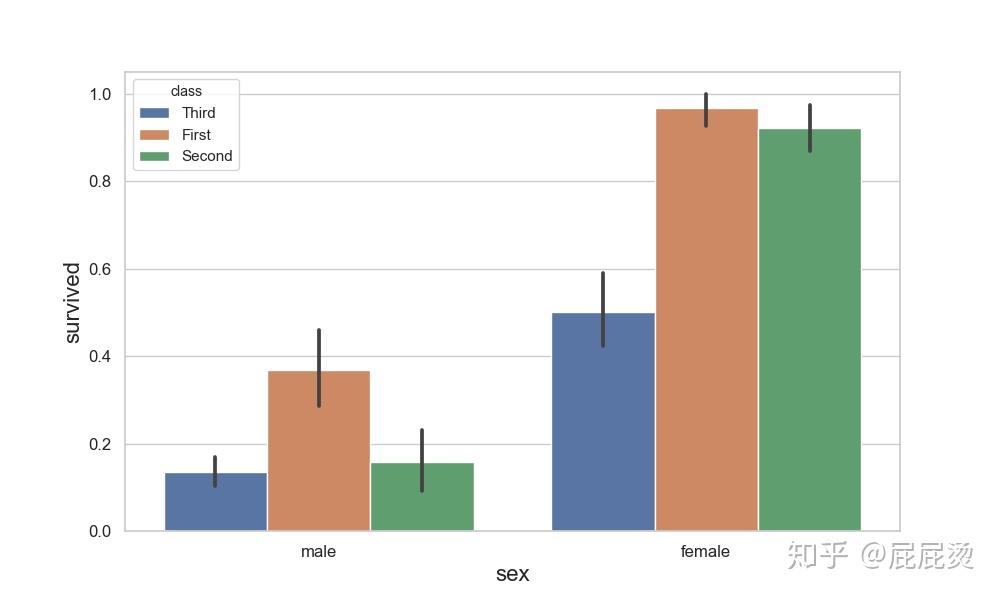
点图(三变量)
# 点图(三变量:sex, survived, class)
# sns.pointplot()绘制点图
plt.figure(figsize=(10,6))
plt.xticks(size=12)
plt.yticks(size=12)
plt.xlabel('sex',size=16)
plt.ylabel( 'survived',size=16)
# 反映变化趋势
sns.pointplot(x="sex", y="survived", hue="class", data=titanic,ci=70)
# ci=70 设置执行度
plt.show()输出:
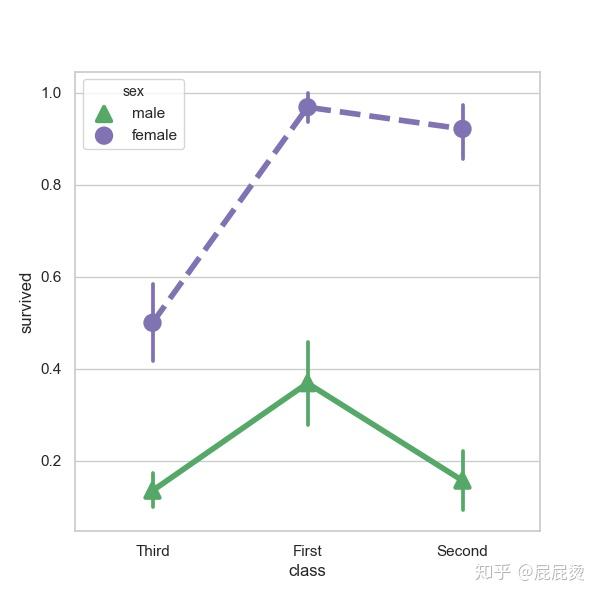
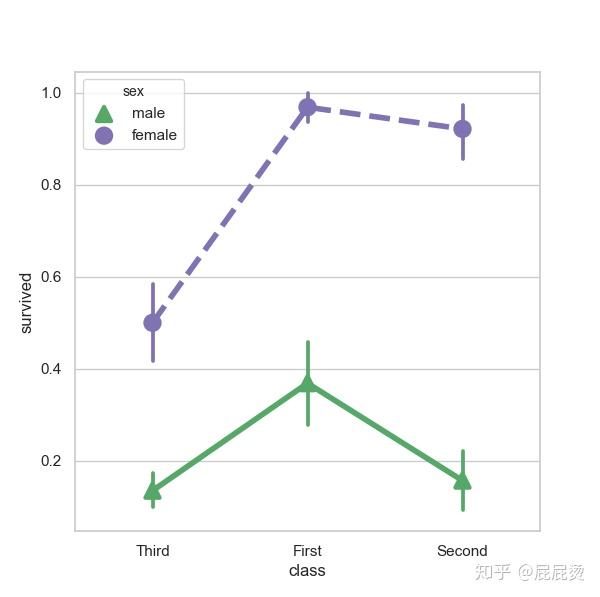
点图细节设置
# 点图细节设置
sns.pointplot(x="class", y="survived", hue="sex", data=titanic,
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
scale=1.5)
# palette 通过调色板来设置颜色,
# markers设置点的形状,
# linestyles设置显的风格,
# scale设置线条的粗细
plt.show()输出:
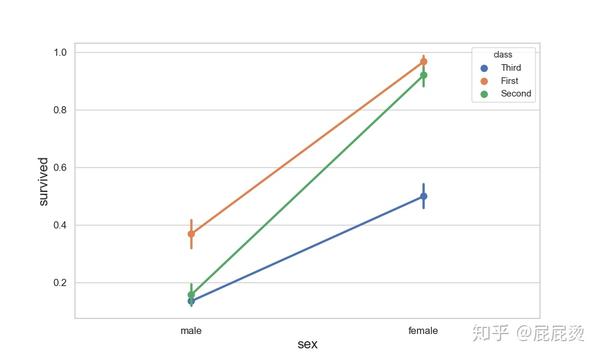
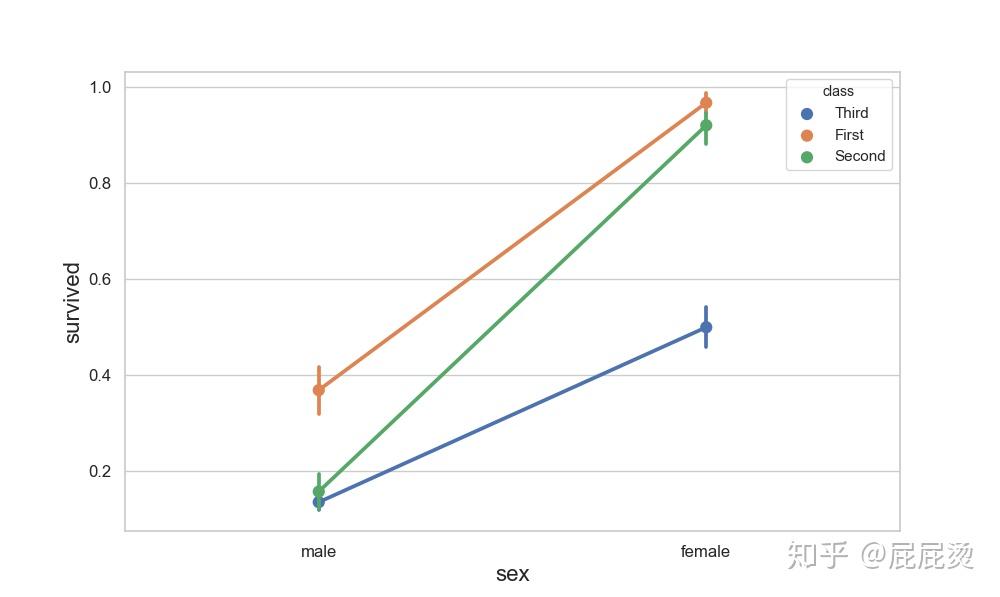
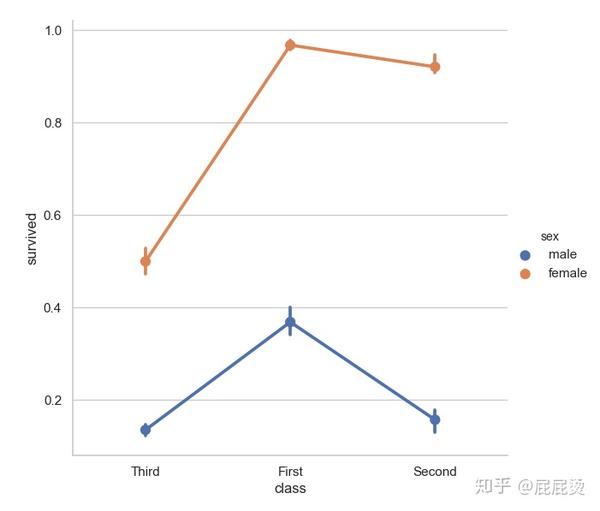
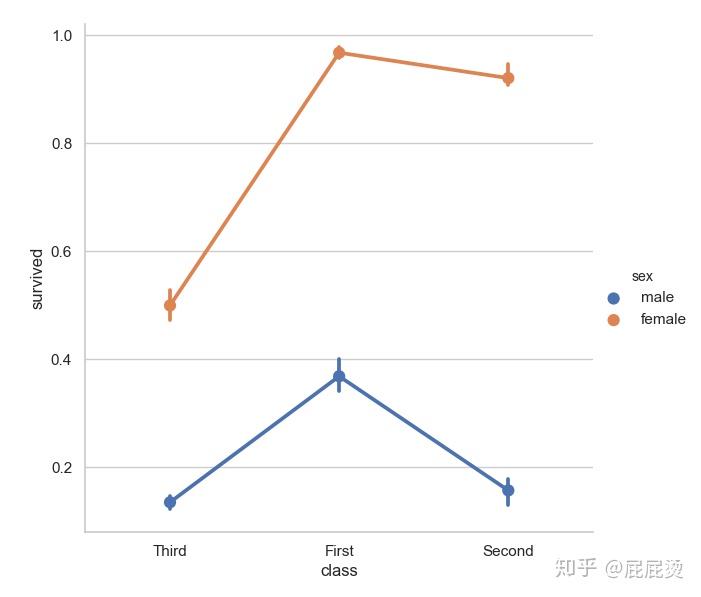
多层面板分类图
# 多层面板分类图
# sns.factorplot() 实现多层面板分类图
# x,y,hue设置要画在一个图中的数据集变量名
sns.factorplot(x="class", y="survived", hue="sex", data=titanic, size=6,ci=50)
plt.show()输出:
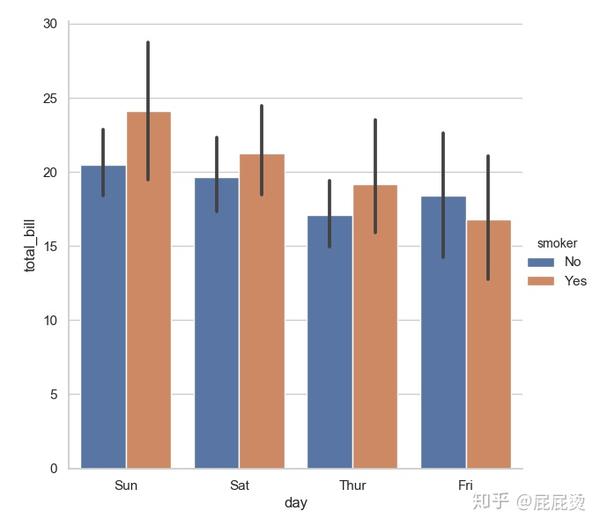
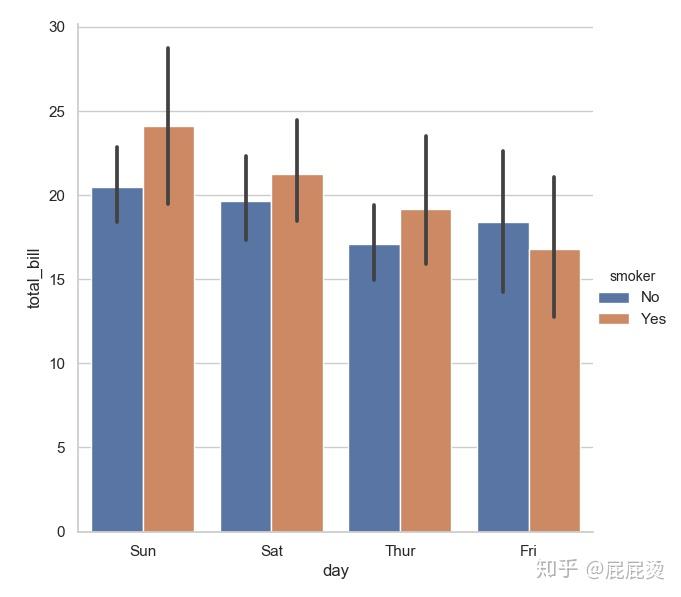
# 通过kind参数指定图的类型
sns.factorplot(x="day", y="total_bill", hue="smoker", data=tips, kind="bar", size=6)
plt.show()输出:
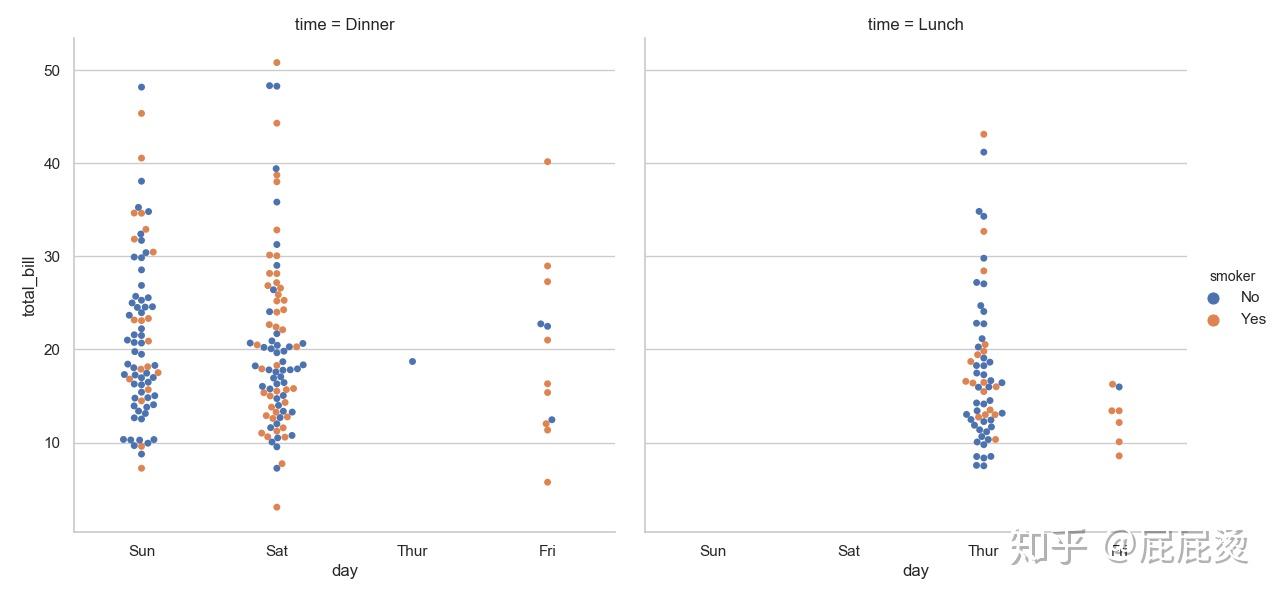
四个变量下的分类散点图
# 四个变量下的分类散点图
# kind参数指定图类型
# loc参数接收第四个参数
sns.factorplot(x="day", y="total_bill", hue="smoker",col="time", data=tips, kind="swarm", size=6)
# 共四个变量了
# col和row设置更多的变量名,进行平铺显示(以不同的图进行区分)
plt.show()输出:


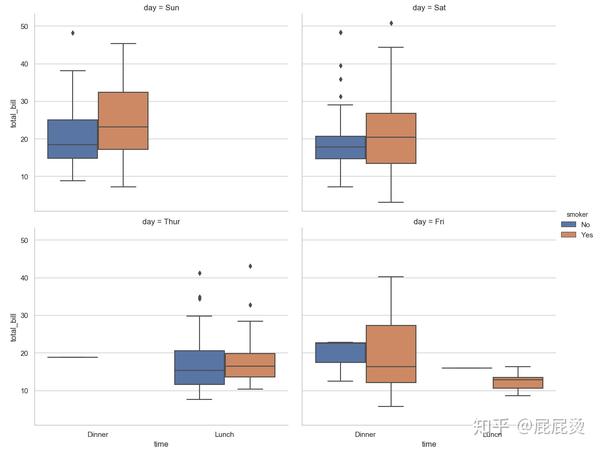
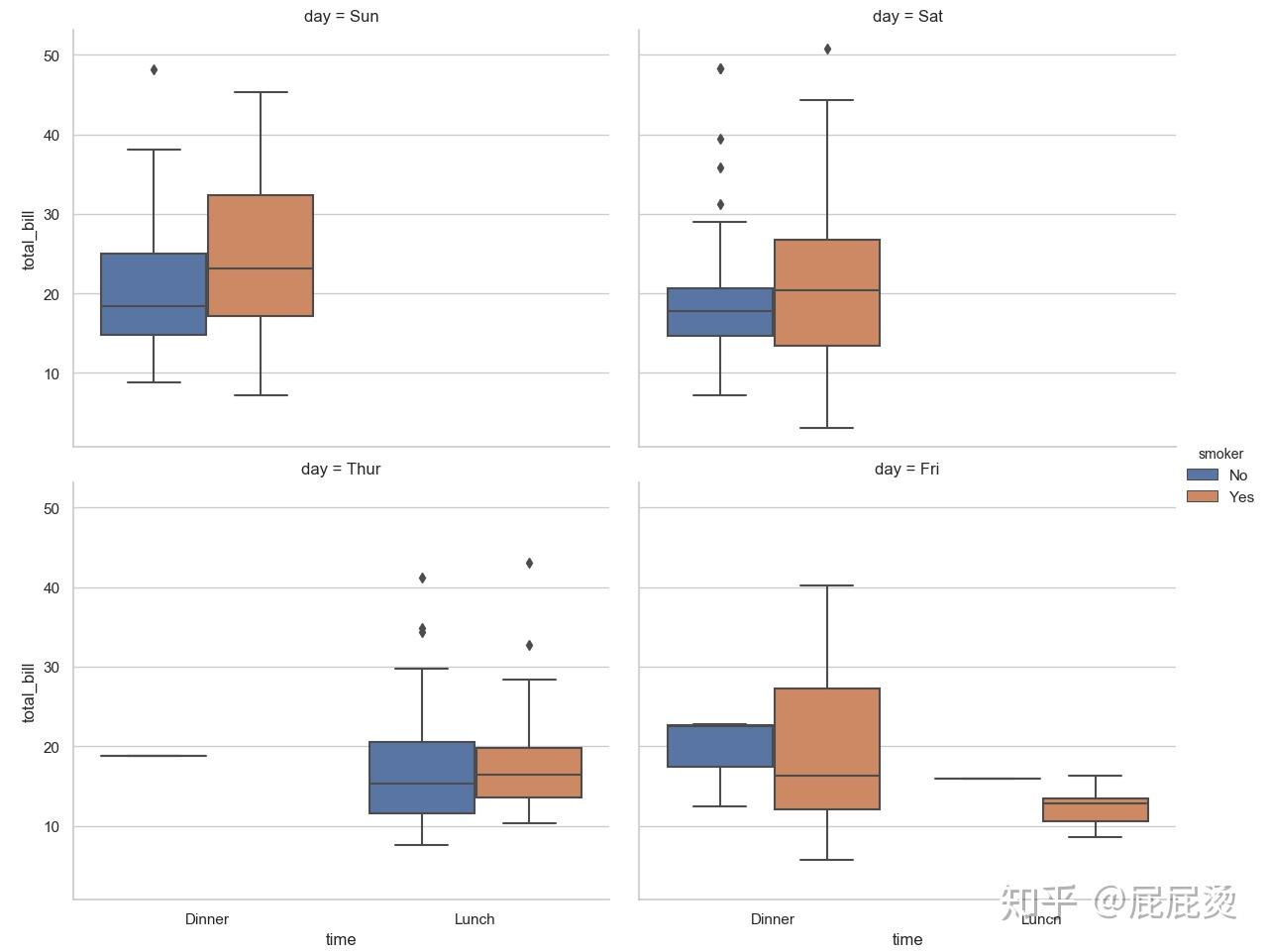
四变量下的盒图
# 四变量下的盒图
sns.factorplot(x="time", y="total_bill", hue="smoker",
col="day", data=tips, kind="box", size=6, aspect=1,col_wrap=2)
plt.show()输出:
多变量分析图其他参数
Parameters:
- x,y,hue 数据集变量 变量名
- date 数据集 数据集名
- row,col 更多分类变量进行平铺显示 变量名
- col_wrap 每行的最高平铺数 整数
- estimator 在每个分类中进行矢量到标量的映射 矢量
- ci 置信区间 浮点数或None
- n_boot 计算置信区间时使用的引导迭代次数 整数
- units 采样单元的标识符,用于执行多级引导和重复测量设计 数据变量或向量数据
- order, hue_order 对应排序列表 字符串列表
- row_order, col_order 对应排序列表 字符串列表
- kind : 可选:point 默认, bar 柱形图, count 频次, box 箱体, violin 提琴, strip 散点,swarm 分散点 size 每个面的高度(英寸) 标量 aspect 纵横比 标量 orient 方向 "v"/"h" color 颜色 matplotlib颜色 palette 调色板 seaborn颜色色板或字典 legend hue的信息面板 True/False legend_out 是否扩展图形,并将信息框绘制在中心右边 True/False share{x,y} 共享轴线 True/False
8.热度图(heatmap)
一般图形
# 数据读取
import matplotlib.pyplot as plt
import numpy as np;
np.random.seed(0)
import seaborn as sns;
sns.set()
# 热度图
uniform_data = np.random.rand(3, 3)
# print (uniform_data)
heatmap = sns.heatmap(uniform_data)
# 通过颜色的变化反映数字大小
plt.show()输出:
pivot()重塑数据
一般图形
# 数据读取
flights = pd.read_csv(r'..\flights.csv')
# flights.head()
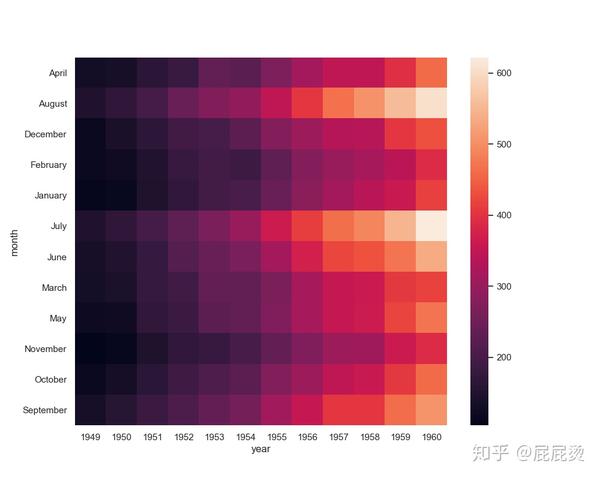
# pivot重塑数据,产生一个“pivot”表格,形成dataframe结果
flights1 = flights.pivot("month", "year", "passengers")
# print (flights1)
plt.figure(figsize=(10,8))
ax = sns.heatmap(flights1)
plt.show()输出:
添加数值
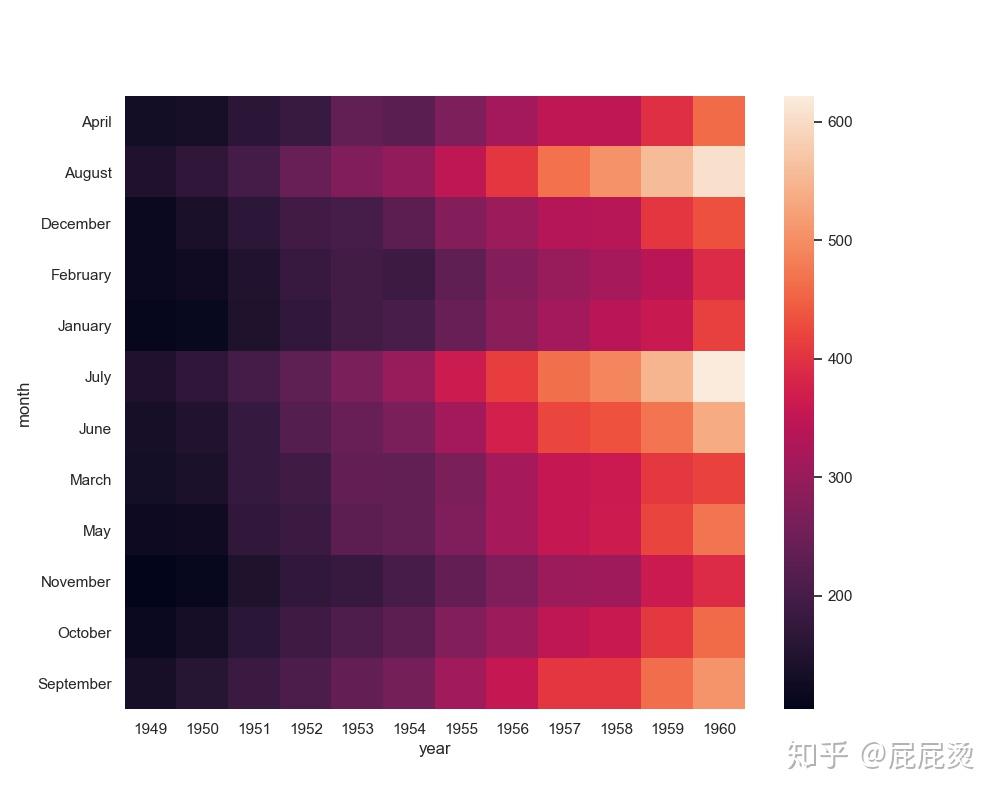
# 添加数值
plt.figure(figsize=(10,8))
# annot显示注释,
# fmt设置注释的形式
ax = sns.heatmap(flights1, annot=True,fmt="d")
# fmt='d': 十进制的整数显示
# fmt='f' : float小数