


Python中ArcPy实现Excel时序数据读取与反距离加权IDW插值、批量掩膜

1 任务需求
首先,我们来明确一下本文所需实现的需求。
现有一个记录有北京市 部分PM2.5浓度监测站点 在2019年05月18日00时至23时(其中不含19时)等 23个逐小时PM2.5浓度数据 的 Excel 表格文件,我们需要将其中的数据依次读入一个包含北京市 各PM2.5浓度监测站点 的矢量点要素图层中;随后,基于这些站点导入的23个逐小时 PM2.5 浓度数据,逐小时对北京市 PM2.5 浓度加以反距离加权( IDW )方法的插值,即共绘制23幅插值图;最后,基于已有的北京市边界矢量数据,分别对这23幅插值图加以掩膜。
在这里,包含北京市 各PM2.5浓度监测站点 的矢量点要素图层是基于 疯狂学习GIS:Python中ArcPy读取Excel数据创建矢量图层同时自动生成属性表字段及内容 这篇文章得到的,如下图所示。
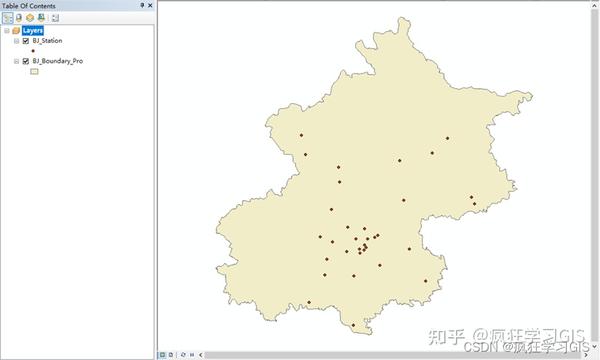
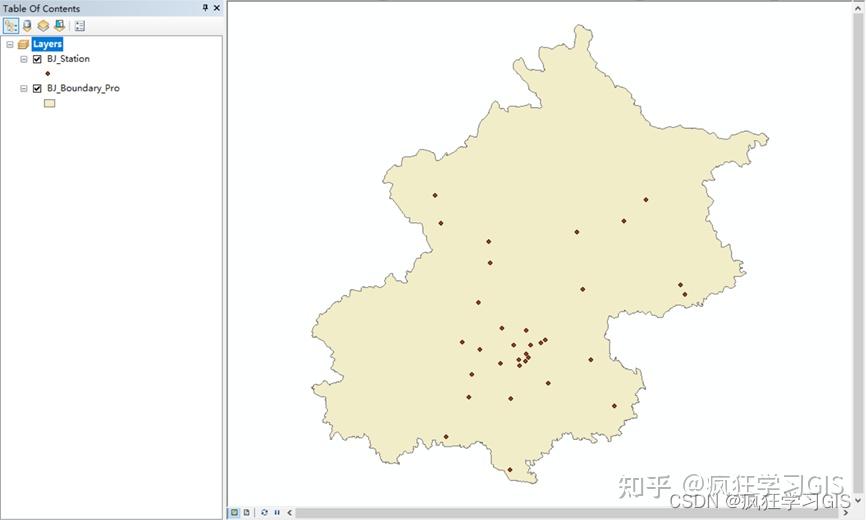
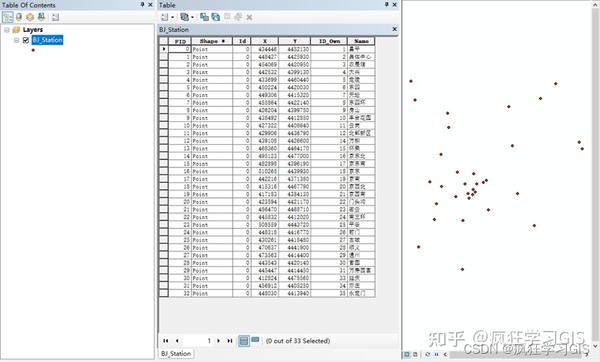
其中,该矢量图层还包括属性表,属性表内容包括每一个站点的编号、地理位置与中文名称,如下图所示。

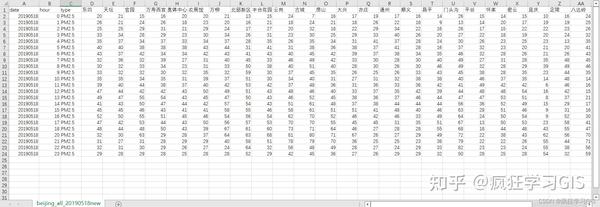
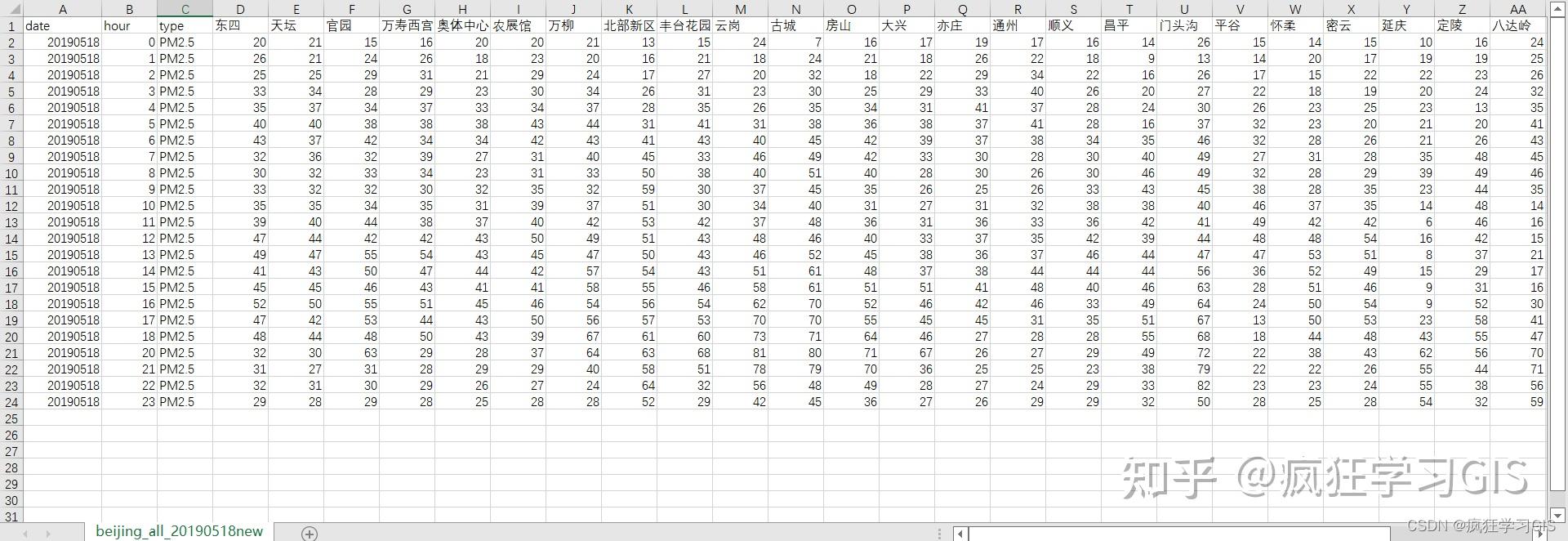
而记录有北京市 部分PM2.5浓度监测站点 在2019年05月18日00时至23时(其中不含19时)等 23个逐小时PM2.5浓度数据 的 Excel 表格文件则如下所示,其中包括各站点在23个整点时所监测到的 PM2.5 浓度。
2 代码实现
了解了需求后,我们就基于
Python
中的
ArcPy
模块,进行详细代码的撰写与介绍。
这里需要说明的是:在编写代码的时候,为了方便执行,所以希望代码后期可以在
ArcMap
中直接通过工具箱运行,即用到
Python程序脚本新建工具箱与自定义工具
的方法;因此,代码中对于一些需要初始定义的变量,都用到了
arcpy.GetParameterAsText()
函数。大家如果只是希望在
IDLE
中运行代码,那么直接对这些变量进行具体赋值即可。关于
Python程序脚本新建工具箱与自定义工具
,大家可以查看
疯狂学习GIS:ArcGIS通过Python程序脚本新建工具箱与自定义工具的方法
这篇文章详细了解。
上面提到需要初始定义的变量一共有十个,其中
arcpy.env.workspace
参数表示当前工作空间,
csv_path
参数表示存储有北京市2019年05月18日00时至23时(其中不含19时)逐小时PM2.5浓度数据的
.csv
文件,
shape_file_path
参数表示站点信息矢量数据文件,
boundary_file_path
参数表示投影后北京市边界矢量数据文件,
spatial_resolution
参数表示
IDW
插值结果栅格图的像元大小,
power
参数表示
IDW
插值时所用距离的幂指数,
look_point
参数表示
IDW
插值时所用最邻近输入采样点数量的整数值,
max_distance
参数表示
IDW
插值时对最邻近输入采样点的限制距离,单位依据地图坐标系确定;
idw_result_dir
参数表示
IDW
插值结果图层保存路径,
mask_result_dir
参数表示
IDW
插值结果图层经掩膜后保存路径。
代码的整体思路为:首先利用
pd.read_csv
函数读取记录有北京市
部分PM2.5浓度监测站点
在2019年05月18日00时至23时(其中不含19时)等
23个逐小时PM2.5浓度数据
的
Excel
表格文件数据,随后在北京市
各PM2.5浓度监测站点
的矢量点要素图层的属性表中新建
23
个列,每一个列表示该监测站点在某一时刻的浓度数据(共有
23
个时刻,因此共有
23
个列);其次,由于矢量要素图层中的部分站点在
Excel
文件中并没有数据,因此需要将这些站点从矢量要素图层中删除;最后,分别利用
Idw
函数与
ExtractByMask
函数进行
IDW
插值与掩膜。
具体代码如下。
# -*- coding: utf-8 -*-
# @author: ChuTianjia
import copy
import arcpy
import pandas as pd
from arcpy.sa import *
arcpy.env.workspace=arcpy.GetParameterAsText(0)
csv_path=arcpy.GetParameterAsText(1)
shape_file_path=arcpy.GetParameterAsText(2)
idw_result_dir=arcpy.GetParameterAsText(8)
boundary_file_path=arcpy.GetParameterAsText(3)
mask_result_dir=arcpy.GetParameterAsText(9)
spatial_resolution=arcpy.GetParameterAsText(4)
power=arcpy.GetParameterAsText(5)
look_point=arcpy.GetParameterAsText(6)
max_distance=arcpy.GetParameterAsText(7)
csv_data=pd.read_csv(csv_path,header=0,encoding="gbk")
column_name_list=list(csv_data)
hour_column=csv_data["hour"]
pm_25_list=[[0]*len(csv_data) for i in range(csv_data.shape[1]-3)]
for i in range(3,csv_data.shape[1]):
for index,data in csv_data.iterrows():
pm_25_list[i-3][index]=data[i]
field_list=["hour_00","hour_01","hour_02","hour_03","hour_04","hour_05",\
"hour_06","hour_07","hour_08","hour_09","hour_10",\
"hour_11","hour_12","hour_13","hour_14","hour_15",\
"hour_16","hour_17","hour_18","hour_20",\
"hour_21","hour_22","hour_23"]
field_list_use=copy.deepcopy(field_list)
field_list_use.insert(0,"Name")
# Update the columns in the attribute table
for i in range(len(field_list)):
arcpy.AddField_management(shape_file_path,field_list[i],"SHORT")
delete_num=0
delete_name=[]
with arcpy.da.UpdateCursor(shape_file_path,field_list_use) as cursor:
for row in cursor:
for column_name in column_name_list:
if column_name==row[0]:
for i in range(len(csv_data[column_name])):
row[i+1]=csv_data[column_name][i]
cursor.updateRow(row)
# Find stations that without any data
if row[0] not in column_name_list:
cursor.deleteRow()
delete_num+=1
delete_name.append(row[0])
arcpy.AddWarning("Delete {0} site(s) that do not contain any data, and the site(s) name is(are):".format(delete_num))
for i in delete_name:
arcpy.AddMessage(i)
arcpy.AddMessage("\n")
# Perform IDW interpolation
arcpy.env.extent=boundary_file_path
for i in range(len(field_list)):
idw_result=Idw(shape_file_path,field_list[i],spatial_resolution,power,RadiusVariable(look_point,max_distance))
idw_result_path=idw_result_dir+"\\"+"BJ_"+field_list[i]+".tif"
idw_result.save(idw_result_path)
arcpy.AddMessage("{0} has completed IDW interpolation.".format(field_list[i]))
# Perform mask