最近需要把Camera内存使用的详细数据统计出来,找到峰值内存。目前正直新型冠状高发期,找到2015年的小米Note(Android M)实验了一把,脚本中有把数据导入到csv文件中。Android M的系统cameraservice还在mediaserver中,所以脚本中直接就统计mediaserver的内存数据,这里就做演示了。
操作手法:打开小米相机,拍照5次,统计cameraservice的内存使用量。
import re
import subprocess
import sys
import time
import csv
APP_NAME = "mediaserver"
dict = {'Java Heap': 0,
'Native Heap': 0,
'Code': 0,
'Stack': 0,
'Graphics': 0,
'Private Other': 0,
'System': 0,
'TOTAL': 0,
'TOTAL SWAP \(KB\)': 0
def get_process_pid(str) :
cmd2 = ('adb shell ps')
process2 = subprocess.Popen(cmd2.split(), stdout=subprocess.PIPE)
cmd_ret2 = process2.stdout.read()
cmd_list = []
cmd_list = cmd_ret2.split('\n');
for cam in cmd_list :
if (str in cam) :
cam = cam.split()
return cam[1]
def main():
pid = get_process_pid(APP_NAME)
print("pid:%s" %pid)
with open("default1.csv", 'wb') as csvfile:
csvwriter = csv.writer(csvfile)
header = dict.keys()
csvwriter.writerow(header)
while (1) :
cmd_dump = ('adb shell dumpsys meminfo %s' % pid)
process2 = subprocess.Popen(cmd_dump.split(), stdout=subprocess.PIPE)
cmd_result = process2.stdout.read()
for key in dict.keys():
pattern = ('%s: +([0-9]*)' % key)
match = re.search(pattern.__str__(), cmd_result)
if match is not None :
dict[key] = match.group(1)
print(dict.values())
csvwriter.writerow(dict.values())
if __name__ == '__main__':
main()
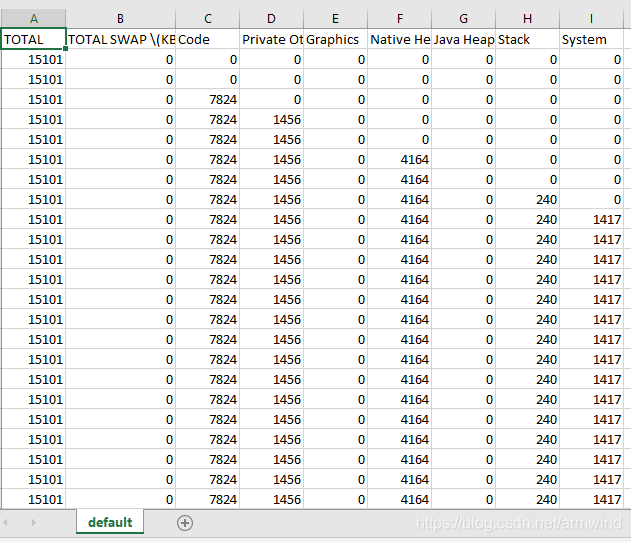
运行后生成的csv文件如预期,实际数据如下:
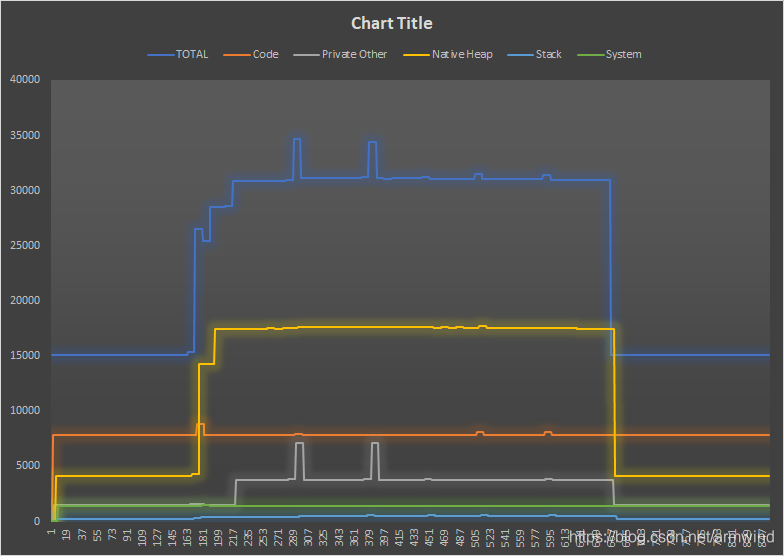
如下是统计cameraservice使用的内存图形,可以发现有5次内存使用量的高峰,如预期操作那样。明天尝试用python画图。
python代码中将数据写入CSV表格有两种办法:pandas和CSV。
下面我将介绍什么时候适合使用pandas,什么时候适合使用CSV库。主要区别是一个按行存储方便,一个按列存取方便。
1.按列存数据(使用pandas)
假设第一列为[1,1,1,1],第二列为[2,2,2,2],第三列的值为[3,3,3],列名(表头名字)为column1,column2,column3。代码如下:
import pandas as pd
c1= [1,1,1,1]
c2 = [2,2,2,2]
c3= [3,3,3,
import csv
item = {'title': '穆斯林的葬礼', 'asin': '', 'url': '', 'brand': ''}
fieldnames = ['title', 'asin', 'url', 'brand']
with open('数据.csv', mode='a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=fiel
##保存csv文件1
dataframe = pd.DataFrame({‘ID’:test_index,‘PRICE’: y_pred})
dataframe = pd.DataFrame({‘PRICE’: test_index})
dataframe.to_csv(“test12.csv”,index=False,sep=’\n’)
##保存csv文件2
dataframe = pd.DataFrame({‘data’:DATA, ‘score’: score})
dataframe = pd.Dat
接着就可以对文件使用.writerow方法进行写入了
个人习惯先添加一行单独的表头,在做爬虫时比较方便
csv_writer.writerow(["标题","购买人数","价格"])#可省略
CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件。python自带了csv模块,专门用于处理csv文件的读取
数据保存为csv格式csv文件python的csv模块从csv文件读取内容写入csv文件运用实例数据准备将数据存为字典的形式存储到csv文件
csv文件
一种用逗号分割来实现存储表格数据的文本文件。
python的csv模块
python遍历代码:
arr = [12, 5, 33, 4, 1]
#遍历输出1
for i in range(0, len(arr)):
item = arr[i]
print(item)
#遍历输出2
for item in arr:
print(it
本篇我们介绍如何使用 Python 内置的 csv 模块将数据写入 CSV 文件。csv.writer() 函数和 DictWriter 类都可以将数据写入 CSV 文件。
data = pd.read_csv(r'D:\代码\05 \rankingcard.csv',index_col=0)
读取文件要在文件路径前面加上r,该csv文件中的第一列是索引,故index_col=0。这一句代码执行下来直接就可以得到一个dataframe.如图:
pd.read_csv()
Python提供了一个标准的类库CSV文件。这个类库中的reader()函数用来导入CSV文件。使用这个函数处理的数据没有文件头,并且所有的数据结构都是一样的,也就是说,数据类型是一样的。这篇文章主要介绍了Python 中导入csv数据的三种方法,内容比较简单,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下。这个函数的返回值是DataFrame,可以很方便的进行下一步的处理,实际操作过程中推荐使用这种方法。以上所述是小编给大家介绍的Python 中导入csv数据的三种方法,希望对大家有所帮助。
lat=["始终没明白游戏起到的正向作用和价值是什么","建议关闭游戏大人孩子都不玩"]
f = open('data.csv', 'w', encoding='utf-8', newline="")
# 2.基于文件对象构建csv写入对象
csv_write = csv.writer(f)
# 3.构建列表头
csv_write.writerow(['title'])
# 4.写入csv文件
for data in lat:
csv_write.writerow
文章目录问题描述方法一: csv方法二: pandas
在深度学习相关任务的训练时,需要在训练的每个 epoch 记录当前 epoch 的准确率(如下图所示),那么在 python 中要怎么将内容写入 csv 文件呢,学习发现可以使用 csv 或者 pandas 实现,在这里做个简单记录。
这里示例的代码为以追加模式写,每次写入一行
方法一: csv
import csv
log_path = 'log/temp.csv'
file = open(log_path, 'a+', encoding



