

3.12.4 自然语言文本预处理

说明:本文是《Python数据分析与数据化运营》中的“3.12.4 自然语言文本预处理”。
-----------------------------下面是正文内容--------------------------
与数据库中的结构化数据相比,文本具有有限的结构,某些类型的数据源甚至没有数据结构。因此,预处理就是要对半结构化或非结构化的文本进行格式和结构的转换、分解和预处理等,以得到能够用于进一步处理的基础文本。不同环境下,文本所需的预处理工作内容有所差异,大体上分为以下几个部分:
基本处理
根据不同的文本数据来源,可能涉及到的基本文本处理包括去除无效标签、编码转换、文档切分、基本纠错、去除空白、大小写统一、去标点符号、去停用词、保留特殊字符等。
- 去除无效标签:例如从网页源代码获取的文本信息中包含HTML标签,此时要提取特定标签内容并去掉标签。
- 编码转换:不同编码不同对于中文处理具有较大影响,例如UTF-8、UTF-16、GBK、GB2312等之间的转换。
- 文档切分:如果获得的单个文档中包含多个文件,此时需要进行单独切分以将不同的文档拆分出来。
- 基本纠错:对于文本中明显的人名、地名等常用语和特定场景用语的错误进行纠正。
- 去除空白:文本中可能包含的大量空格、空行等需要去除。
- 大小写统一:将文本中的英文统一为大写或小写。
- 去标点符号:去除句子中的标点符号、特殊符号等。
- 去停用词:常见的体用词包括the、a、an、and、this、those、over、under、above、on等。
- 保留特殊字符:某些场景下可能需要只针对汉字、英文或数字进行处理,其他字符都需要过滤掉。
分词
分词是将一系列连续的字符串按照一定逻辑分割成单独的词。在英文中,单词之间是以空格作为自然分界符的;而中文只有字、句和段能通过明显的分界符来简单划界,而作为词是没有形式上的分界符。因此,中文分词要比英语等语种分词困难和复杂的多。对于复杂的中文分词而言,常用的分词方法包括最大匹配法、逆向最大匹配法、双向匹配法、最佳匹配法、联想-回溯法等。
文本转向量(word to vector)
人们通常采用向量空间模型来描述文本向量,即将文档作为行,将分词后得到的单词(单词会在向量空间模型里面被成为向量,也被称为特征、维度或维)作为列,而矩阵的值则是通过词频统计算法得到的值。这种空间向量模型也称为文档特征矩阵。其表示方法如表3-4:
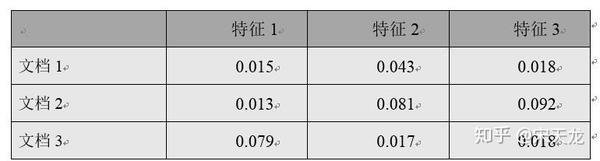

本示例中,将仅对自然语言文本做分词和word to vector处理,有关更多文本分析的内容,例如词性标注、关键字提取、词频统计、文本聚类、相似关键字分析等会在第4章中介绍。数据源文件text.txt位于“附件-chapter3”中,默认工作目录为“附件-chapter3”(如果不是,请cd切换到该目录下,否则会报“IOError: File text.txt does not exist”)。完整代码如下:
# 导入库
import pandas as pd
import jieba # 结巴分词
from sklearn.feature_extraction.text import TfidfVectorizer # 基于TF-IDF的词频转向量库
# 分词函数
def jieba_cut(string):
word_list = [] # 建立空列表用于存储分词结果
seg_list = jieba.cut(string) # 精确模式分词
for word in seg_list: # 循环读取每个分词
word_list.append(word) # 分词追加到列表
return word_list
# 读取自然语言文件
fn = open('text.txt')
string_lines = fn.readlines()
fn.close()
# 中文分词
seg_list = [] # 建立空列表,用于存储所有分词结果
for string_line in string_lines: # 读取每行数据
each_list = jieba_cut(string_line) # 返回每行的分词结果
seg_list.append(each_list) # 分词结果添加到结果列表
for i in range(5): # 打印输出第一行的前5条数据
print (seg_list[1][i])
# word to vector
stop_words = [u'\n', u'/', u'“', u'“', u'”', u'的', u',', u'和', u'是', u'随着', u'对于', u'对', u'等', u'能', u'都', u'。', u'、',
u'中', u'与', u'在', u'其'] # 自定义要去除的无用词
vectorizer = TfidfVectorizer(stop_words=stop_words, tokenizer=jieba_cut) # 创建词向量模型