


应用双重机器学习(Double Machine Learning)计算额度-响应弹性系数

前言
额度-响应弹性系数能够指导我们,为了提升信贷收益,针对不同的客群应该提额还是降额,以及提多少,降多少。本文手把手教你如何使用双重机器学习进行因果推断解决业务问题。
1
问题的提出
弹性是经济学非常重要的一个概念,例如需求的价格弹性,描述的是商品价格变动所带来的需求数量的变动的比例关系,即弹性系数= 需求的变动比例/价格的变动比例。
在信贷风控领域,贷中管理有两大主题:
「一是优化资产结构」
,如通过负向权益调整、用信准入、劣化客户清退,实施风险排查、预警和处置。
「二是增加客户价值」
,如通过正向权益调整,满足客户需求、提升客户体验。
额度管理是贷中管理的主要手段:为了优化资产结构,我们会对高风险存量客户进行降额或者冻结额度,为了增加客户价值,我们会通过提额来激活存量客户的借款需求。
显然,额度的变动会导致客户的借款意愿的变化——提额会提升客户的借款意愿,降额会降低客户的借款意愿。
我们需要
「量化」
额度变化对借款意愿的影响,这就是我们今天所讨论的额度-响应弹性系数,即额度的变动幅度所带来的借款响应的变动幅度。
2
为什么给客户提额反而降低了收益呢?
我们进行额度管理的目标是提升收益,但额度管理的结果极有可能导致收益下降。我们要知道,客户特征和质量差异很大、需求也是多样化的,有些客户对额度敏感,有些客户对额度不敏感。
「提升客户信用额度」
,也增加了风险敞口。在当前额度下,客户的违约率低,并不意味着其额度的大幅度增加后,其违约率依然很低。另外,提额操作可能会使得对额度敏感的客户响应高,额度不敏感的客户响应率低。由于逆向选择(好客户取所需,提升额度,不改变其借款需求;坏客户取所有,提多少用多少),提额的最终结果极有可能是借款需求增加了,但风险上升了更多,从而导致总体利润下降。
「降低客户信用额度」
,会导致客户不满而流失。虽然大多数情况下,是给高风险的客户降低额度,但在大数据风控场景下,我们所谈论的好坏客户、风险高低,都是基于概率层面,所谓高风险客户中,大部分都是未来能正常还款的客户。因此,我们不会轻易降低客户的信用额度,最多只降影子额度,实在要降额,也不会大幅度降低,以免让客户不满,降低借款需求或流失,从而导致总体利润下降。
额度-响应弹性系数能够指导我们,为了提升收益,针对不同的客群应该提额还是降额,以及提多少,降多少。
3
额度-响应的弹性系数的因果推断难题
如果我们想要知道某个客群的额度-响应的弹性系数,最好的方式,当然是直接进行随机测试。通过随机给额,我们可以得到由不同额度变动所带来的借款需求的变动。
但这个测试成本太高了,另外,由于额度是信贷产品最重要的属性,随机给客户不同的额度会导致客户体验极差。
我们也无法直接使用历史数据来计算,因为额度和响应受到非常多的混杂因素的影响,无法使用历史数据进行因果推断。例如,风险是一个非常重要的confounder, 对额度有影响,对响应也有影响。
有没有一种方法,让我们无须反复测试,即可计算额度-响应弹性系数呢?
4
双重机器学习(DML)简介
我们可以使用DML(Double Machine Learning) 方法进行因果推断。
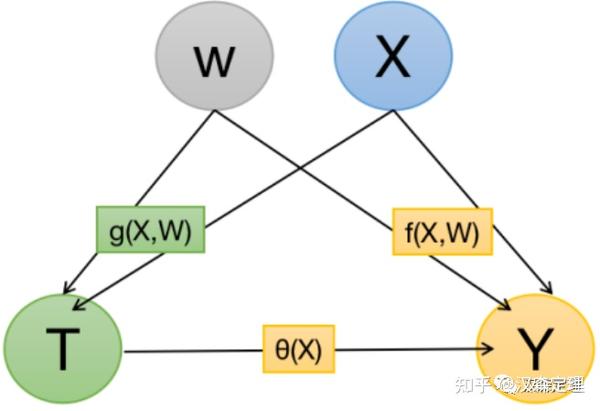
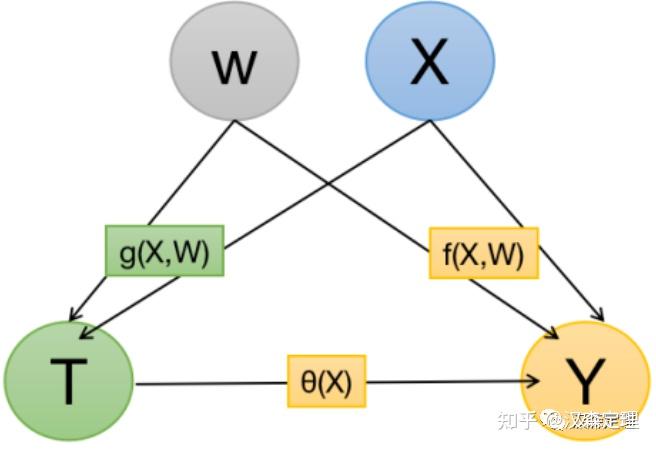
DML的核心思想很简单,分别用机器学习算法基于X预测T和Y,然后使用T的残差回归Y的残差,所得参数即为无偏的平均因果效应。
具体而言,Y是我们关系的结果变量(如额度使用率),T是干预变量(Treatment,如提额幅度),X是混杂因子(Confounder),可以简单理解为未被实验干预过的用户特征、状态或行为。
如果我们关心T对Y的影响,首先使用任意机器学习算法,通过X拟合T,得到一个T的残差(实际T-预测T),然后通过X再拟合Y,得到一个Y的残差(实际Y-预测Y),最后通过线性回归,用T的残差拟合Y的残差,回归的系数即我们想要的无偏因果效应。
为什么能够使用DML进行因果推断呢?关键在于,基于X拟合的,对Treatment实施了去偏。T的残差可以看作将X对T的作用从T中去除后剩下的量,此时T的残差与X正交。而通过X拟合的的作用在于将X引起的Y的方差从Y中去除。
5
DML训练过程
- 利用任意机器学习模型,通过混杂变量X拟合处理变量T,得到E(T|X), 利用任意机器学习模型,通过混杂变量X拟合结果变量Y,得到E(Y|X)
- 计算残差,得到不受混杂因素X影响的T_hat和Y_hat
- 将 T_hat和Y_hat,进行log-log回归,得到弹性系数。
- 通过Cross-fitting来降低对的估计偏差。把样本分成两份,用样本1估计残差,样本2估计,用样本2估计残差,样本1估计,最后 。如果样本比较多的话,也可以使用K折交叉验证,让估计更加稳健。
6
案例和代码
假如我们一个月前对客户实施了提额促活,并且也做了提额响应的随机对照实验,即随机分配一部分客户.....
更多内容 关注公号:汉森定理 获取。
