如题,
LDA
(Latent Dirichlet Allocation)是主题模型中极具代表性的一种,常用于文本分类,推测文本(文档)的主题分布。简而言之:LDA算法可以将文档集中的每篇文章所对应的主题以概率分布的形式给出。
-
给定一些文档集,可通过LDA算法获得这些文档的主题分布,后续可根据主题分布做
文本聚类
或
文本分类
;
-
LDA 模型涉及很多数学先验知识,也是LDA晦涩难懂的主要原因,本文不会推导LDA涉及的数学公式,感兴趣的朋友可以参考:
rickjin
的《
LDA数学八卦
》;
http://www.flickering.cn/tag/lda/
-
LDA模型通常需要确定从每篇文章中提取多少个主题(关键词),本文重点介绍通过
折肘法
+
困惑度
法确定
LDA主题模型
的
主题数
。
对于主题模型而言,选定的算法一旦确定, 需要
人为确定的选项
(超参)通常是主题数量,LDA算法也不例外:主题数量通常视不同场景进行调整,简单点儿说,通过评估不同主题数模型的困惑度来选择最优的模型主题数。在本文中,采用
计算困惑度
(
Perplexity
)的方法来衡量选取的主题数量的优劣:
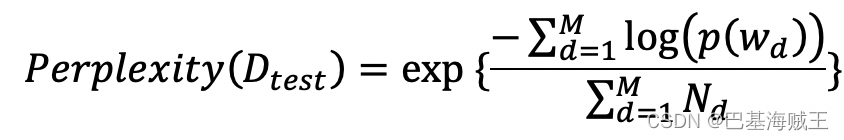
其中,
M
是测试语料的大小(文档的数量),
Nd
是第
d
篇文本大小(
word
或
token
个数)
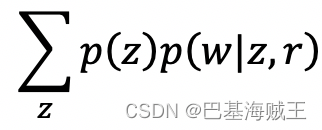
其中,
z
是主题,
w
是文档,
r
是基于训练集学习的
文本-主题分布
,简而言之,
Perplexity
对数函数的分子部分是生成整个文档集的
似然估计
(表示训练集训练出的参数的生成能力)的负数,由于概率取值范围为[0,1],按照对数函数的定义,分子值是一个正值且与文本生成能力正相关;而分母是整个文档集的的单词数目。那么,也就是说,模型生成能力越强,
Perplexity
值越小。
1. 加载第三方
gensim.LdaModel
from gensim import corpora, models
import math
import matplotlib.pyplot as plt
def ldamodel(num_topics, pwd):
cop = open(pwd, 'r', encoding='UTF-8')
train = []
for line in cop.readlines():
line = [word.strip() for word in line.split(' ')]
train.append(line)
dictionary = corpora.Dictionary(train)
corpus = [dictionary.doc2bow(text) for text in train]
corpora.MmCorpus.serialize('corpus.mm', corpus)
lda = models.LdaModel(corpus=corpus, id2word=dictionary, random_state=1,
num_topics=num_topics)
topic_list = lda.print_topics(num_topics, 10)
return lda, dictionary
2. 计算给定文档集的Perplexity
def perplexity(ldamodel, testset, dictionary, size_dictionary, num_topics):
print('the info of this ldamodel: \n')
print('num of topics: %s' % num_topics)
prep = 0.0
prob_doc_sum = 0.0
topic_word_list = []
for topic_id in range(num_topics):
topic_word = ldamodel.show_topic(topic_id, size_dictionary)
dic = {}
for word, probability in topic_word:
dic[word] = probability
topic_word_list.append(dic)
doc_topics_ist = []
for doc in testset:
doc_topics_ist.append(ldamodel.get_document_topics(doc, minimum_probability=0))
testset_word_num = 0
for i in range(len(testset)):
prob_doc = 0.0
doc = testset[i]
doc_word_num = 0
for word_id, num in dict(doc).items():
prob_word = 0.0
doc_word_num += num
word = dictionary[word_id]
for topic_id in range(num_topics):
prob_topic = doc_topics_ist[i][topic_id][1]
prob_topic_word = topic_word_list[topic_id][word]
prob_word += prob_topic * prob_topic_word
prob_doc += math.log(prob_word)
prob_doc_sum += prob_doc
testset_word_num += doc_word_num
prep = math.exp(-prob_doc_sum / testset_word_num)
print("模型困惑度为 : %s" % prep)
return prep
3. 绘制主题数与困惑度的折线图
def graph_draw(topic, perplexity):
x = topic
y = perplexity
plt.plot(x, y, color="red", linewidth=2)
plt.xlabel("Number of Topic")
plt.ylabel("Perplexity")
plt.savefig("Perplexity-Topics")
plt.show()
4. 主函数入口
if __name__ == '__main__':
pwd = '~/*_summary.txt'
for i in range(20,21,1):
print("抽样为"+str(i)+"时的perplexity")
a=range(1,50,1)
p=[]
for num_topics in a:
lda, dictionary = ldamodel(num_topics, pwd)
corpus = corpora.MmCorpus('corpus.mm')
testset = []
for c in range(int(corpus.num_docs/i)):
testset.append(corpus[c*i])
prep = perplexity(lda, testset, dictionary, len(dictionary.keys()), num_topics)
p.append(prep)
graph_draw(a,p)
- 第4步中的pwd,要求将给定的语料集合成一个文本文件。原因是在测试使用LDA模型提取单篇文档时报bug,至今未解决[2022.04.28];
- 不会写latex公式,后面的学习内容;
使用随机抽取语料采用本文方法的结果

-
在上图中,随着K(Number of Topic)值的增大,困惑度(Perplexity)逐渐减小。根据手肘法,并且当K约为5的时候,存在一个显著的拐点:
- 当K属于(1, 5)时,曲线急剧下降;
- 当K属于(5,10)时,曲线基本趋于平稳;
-
故拐点5即为K的最佳值,因此在本文所选定的语料集中,LDA主题的生成数量选定为5。
-
值得注意的是,当K>10时,训练困惑度出现小幅度的上升,这与样本空间和算法本身都有关联,属正常现象。
-
在使用LDA算法提取关键词时,通常会采样如下方案:使用tf-idf对数据集中的每个词进行加权,得到加权后的向量表示,通过词空间构建和向量化方法,得到数据集的主题-词分布,最后计算词的分布和文档的分布的相似度,取相似度最高的keyword num个词作为关键词。具体见下一篇文章:LDA主题模型提取文本中的关键词
完结撒花 🎉🎉
LDA主题建模中主题数的确定——基于困惑度与一致性前言1. 首先是导入包2. 分词3. 复杂性和一致性4. 绘制Perplexity-Coherence-Topic 折线图5. 依据困惑度和一致性评价结果进行主题建模前言最近在《比较》公众号上读到《叙事的经济学与经济学叙事》一文,这篇文章介绍到2013年诺贝尔经济学奖得主,耶鲁大学经济学罗伯特·希勒在2017年发表了一篇论文(Narrat...
为了计算LDA 的困惑度,费劲千辛万苦,终于有所收获,以此记录。
本篇文章主要介绍perplexity的计算方式,并未涉及过多的困惑度原理,想了解更多原理部分,请移步perplexity介绍
本文主要是对Perplexity per word进行困惑度计算,公式:
确定LDA模型的最佳主题数是一个挑战性问题,有多种方法可以尝试。其中一个流行的方法是使用一种称为Perplexity的指标,它可以度量模型生成观察数据的能力。但是,Perplexity可能并不总是最可靠的指标,因为它可能会受到模型的复杂性和其他因素的影响。
另一个流行的方法是使用一种称为coherence score的指标,它可以测量模型生成主题的质量和连贯性。一些库如Gensim就提供了计算co...
LDA 是一种常用的文本主题模型,可以自动从文本中发现主题。在使用 LDA 进行文本主题建模时,需要确定主题数量。有几种常用的方法可以确定 LDA 模型中主题的数量:
使用交叉验证法,即将文本分成训练集和测试集,然后使用不同的主题数量分别训练 LDA 模型,并使用测试集评估每个模型的表现。通常,当主题数量增加时,模型的表现会有所提升,但是到一定程度后会达到饱和,表现开始下降。可以选择表现最佳的主...
主题数确定:困惑度计算,画出曲线,选择拐点,避免信息丢失和主题冗余
https://blog.csdn.net/u014449866/article/details/80218054
参数调节:
方法一:
alpha 是 选择为 50/ k, 其中k是你选择的topic数,beta一般选为0.01吧,,这都是经验值,貌似效果比较好,收敛比较快一点;
转载于:https://www....
在上一篇文章的最后,我们生成了15个模型(主题数分别从1到15),然鹅,问题来了,到底多少个主题,才是最好的主题模型呢?到底有没有可以评价一个模型好坏的标准呢?答案肯定是有的,而且还不止一个呢! 先说一个,我最开始做实验的时候用的,肉眼观察法。即通过经验来判断选择几个主题(靠猜),显然这是一个不错的方法。我当时和老大说完,老大一直夸我聪明,并打了我一顿,不说了,医院的WiFi不大好用。 目前比较...
LDA中topic个数的确定是一个困难的问题。
当各个topic之间的相似度的最小的时候,就可以算是找到了合适的topic个数。
参考一种基于密度的自适应最优LDA模型选择方法 ,简略过程如下:
选取初始K值,得到初始模型,计算各topic之间的相似度
增加或减少K的值,重新...
3贝叶斯统计标准方法
参考文献:Griffiths T L, Steyvers M. Finding Scientific Topics[J]. Proceedings of the National Academy of Sciences of the Unit...
主题建模作为一种基于机器学习的文本内容分析技术,一般用于推断文本文档中隐藏主题的技术。很多研究使用了基于Latent Dirichlet Allocation (LDA)的主题建模算法来处理大规模文档并识别潜在主题。LDA主题模型已经在多个研究领域得到应用,且都有着不俗表现。
LDA作为一种无监督机器学习技术,利用词袋方法识别隐藏在大规模文档集或语料库中的主题信息。LDA模型可挖掘出文档集或语料库中的潜在主题信息,并采用词 袋构建模型,在不考虑词汇出现顺序的情况下,构成“文档-主题分布”和“主题-词分布”
训练好LDA主题模型后,如何评价模型的好坏?能否直接将训练好的模型拿去应用?这是一个比较重要的问题,在对模型精度要求比较高的项目或科研中,需要对模型进行评价。一般来说,LDA模型的主题数量都是需要需要根据具体任务进行调整的,即要评价不同主题数的模型的困惑度来选择最优的那个模型。...
def ldamodel(num_topics):
cop = open(r'C:\Users\N\Desktop\senti_data (负) .csv',encoding='gb18030')
train = []
for line in cop.readlines():
line = [word.strip() for word in line.split(' ')]

