

用python实现多文档查询

问题背景
小皮同学最近很苦恼。
小皮同学所在的科室最近承接了一个大工程的咨询项目,小皮同学和同事们都很开心,因为这意味着大家从画图的一跃变成了审图的,以前那种“专家一句话,改图头改大”的日子一去不返。因此大家在提出图审意见的时候,想必都是结合了自己丰富的绘图经验,最终的图审意见做到了内容详实,成果丰富。这些意见就像东风导弹一样,一枚枚的砸向设计单位,足足有200多发。
然而有时候搬起石头砸自己的脚就是这么容易,小皮同学碰上了难缠的业主。业主要求对每条图审意见按照降低施工风险、节约投资、设计优化、设计质量提升、提高施工可操作性进行分类,最终分成对应的五个word文档,每个文档里面包含提出的具体意见,意见对应的图册、图纸名称,图纸编号等信息。
那么问题来了,如果知道一条意见的具体内容,如何快速判定它属于哪一类呢?一般的做法是依次打开这五个word文档进行查询,对小皮同学来说,如果200多条意见挨个查下来,工作量太大而且容易出错,那么有没有工具可以快速做到多文档查询呢?
小皮同学上网做了一会功课,发现类似的需求还真不少,有人是想给案宗进行归类整理,有人是想在多个合同里面查询有没有出现相应关键字,还有人想批量替换多个word文档中的相应字符串等等。但是小皮同学发现,网上给出的解决方法却还比较初级,列举如下:
- 利用windows自带的文件搜索功能,但是只能查到关键字所在的文档,而且速度比较坑爹。
- 把文档合并成一个文件进行搜素,尽管操作上稍微有所简化,但是丢失了文档标题信息,而且也没法进行替换操作
- 也有人推荐了一些软件,比如DocFetcher,Wordpipe,Search And Replace等等,但是一通使用下来发现,有些软件付费且功能繁琐,有些则完全没用,成本高且效果不太好。
代码实现
其实这个问题并不是很难解决,相反可以用来作为Python入门的案例。
首先需要在电脑上安装好Python环境,主要用到自带的OS模块以及python-docx模块。安装并配置环境这一块可能会难倒很多新手小朋友,有不懂的可以在评论区留言,人数多的话我会在专栏中专门写一篇文章来讲讲我自己的一些方法。
在配置好环境后,废话不多说,直接上代码。因为本人职业是一只设计汪,Python只是兴趣,代码写的不好的地方也欢迎各位程序员大神对代码批评指正。
import os
from docx import Document
path = r"D:\帅妹\01施工总承包\目录7-总包合同\附件"
str_to_search = input("请输入要搜索的字段:")
def search_str_in_paragraph(str_to_search, paragraph):
本函数旨在特定段落中搜索指定字符串,并返回字符串索引位置。
str_index = paragraph.text.index(str_to_search)
return str_index
for root, dirs, files in os.walk(path, topdown=False):
for file in files:
filename = file.split(".")[0]
ext = file.split(".")[1]
if ext == "docx":
doc = Document(os.path.join(root, file))
for paragraph in doc.paragraphs:
if str_to_search in paragraph.text:
str_index = search_str_in_paragraph(str_to_search, paragraph)
print(paragraph.text[str_index-10:str_index+10], "-----", filename, "-----", os.path.join(root, file))以上代码就能实现在多个文档中查询相关字符串,在使用的时候只需要把path后面的字符串替换成查询的word文档所在的路径即可,由于os.walk的特殊属性,此代码可以实现文件夹的遍历,意思是文件夹中的文件夹,文件夹中的文件夹的文件夹等等都能够做到刨根问底,刨个稀烂。
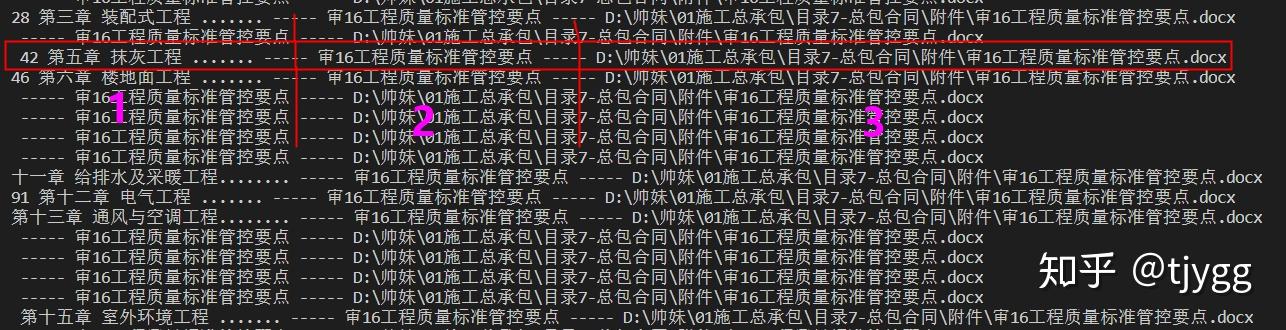
运行以后,会要求你输入需要搜索的字段,这里我输入的字符串为“工程”。


以一条典型的结果为例,输出的结果包含以下三部分内容:
- 文件中查询字符串前后的文本内容,这条信息用来判断查询的字符串前后大致是讲什么的。
- 查询到的字符串所在的文档名称,这条信息就是为了显示查询的字符串是在哪个word文件中。
- word文档所在的绝对路径。

但是以上代码也有缺陷,那就是python中的docx库并不能处理后缀名为.doc的文件,但是如果文件数量很多的话,一个个手动变为.docx文件又太过于繁琐,因此又有下面的代码可以实现批量将.doc文件转化为.docx文件。
import os
import sys
import pickle
import re
import codecs
import string
import shutil
from win32com import client as wc
import docx
path = r"D:\帅妹\01施工总承包\目录7-总包合同\附件"
def doSaveAas(path_convert):
word = wc.Dispatch('Word.Application')
doc = word.Documents.Open(path_convert) # 目标路径下的文件
doc.SaveAs(f"{path_convert}_convert.docx", 12, False, "", True, "", False, False, False, False) # 转化后路径下的文件
doc.Close()
word.Quit()