|
|
|


Postgresql的json性能到底如何?
关注者
21
被浏览
59,549
4 个回答

关于PostgreSQL 的 Json/Jsonb性能,之前博客有介绍基于Json字段数据的Key值检索效率,在笔记本上的虚机上300万数据的表中测试,查询结果为小于1毫秒,供参考,详见: PostgreSQL9.4: Jsonb 性能测试 , 基于json字段数据的key值排序没做相关测试。
关于JSON的功能之前总结了三篇文章,供参考,如下:
PostgreSQL 12: 支持 SQL/JSON path 特性


让您的结果快很多倍
在过去的一年里,我学到了很多关于如何优化 PostgreSQL 性能的知识,在这篇文章中,我想分享一些关于如何充分利用我们的数据库的关键知识。
您是否曾收到您的团队或客户关于产品应用程序运行缓慢的问题?很可能你有 。
在我的经验中,
数据库性能 == 应用程序性能#1 问题是缺少索引
导致数据库性能问题的最常见错误是 (1) 查询缺少索引或 (2) 未使用为查询创建的索引。
让我们考虑一个存储有关艺术家、他们的曲目和他们各自专辑的数据的数据库。
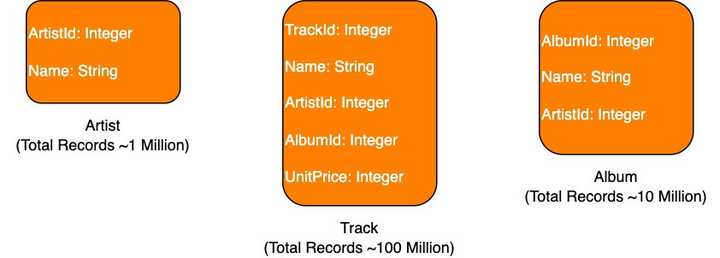
如果我想用 查询曲目
Name = Levitating
,我将使用以下查询:
SELECT * FROM Track WHERE Name='Levitating';数据库中的数据以数据页的形式存储在磁盘上。这些页面的结构类似于链表,因为它们包含一个数据部分和另一个部分用于指向下一个块的指针。这些块不需要以连续的顺序存储。
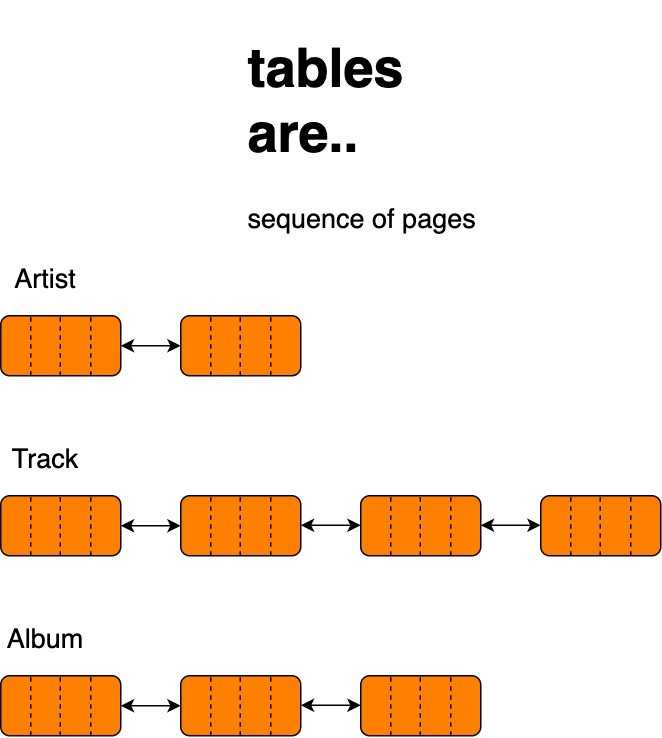
表格是一系列页面
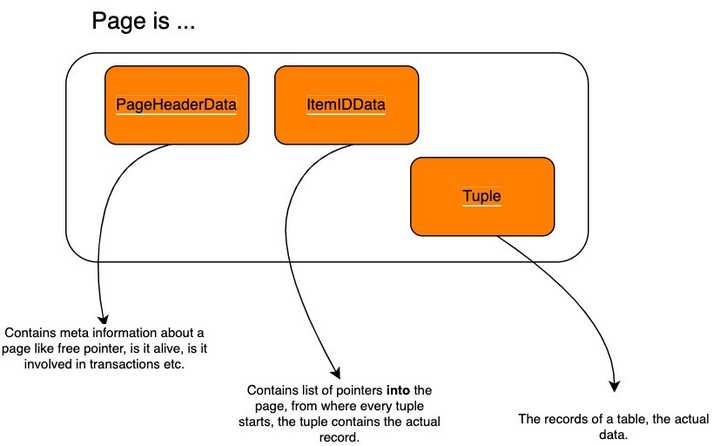
页面构成
当一条记录变得太大而无法存储在一个块中时,PostgreSQL 会将其存储在一张
TOAST
表中。记录将被分割成块,因此主表也称为堆将包含一个指向
TOAST
表中正确块的指针。
根据
Track
表的模式,一个块的
Track
数据部分将包含多个字段。记录只能在一个字段中排序这一事实,在这样的字段上搜索
Name
不是主键,因为
Name
它是一个非唯一字段,因此默认情况下不排序,搜索
Name
将需要全表扫描。
这意味着要使用上述查询找到轨道,
Name=’Levitating’
必须扫描所有约 1 亿行。那太疯狂了。需要几秒钟才能得到结果,这是对计算资源的不良使用和对环境的不良影响
如何提高上述查询的性能?输入索引。
索引是一种数据结构,通过向数据库客户端提供指向所请求记录的指针,可以更快地查询数据。一旦知道记录的位置,就可以通过查找确切的内存地址来快速获取数据。
底层查询协议允许数据库客户端批量获取结果,而不是一次全部获取。
让我们通过执行以下查询在表的
Name
字段上创建索引:
Track
使用 btree(名称)在轨道上同时创建索引;索引被实现为 B 树。在剖析上述查询之前,我先让你深入了解一下 B-Trees。
B 树是为在磁盘上存储数据而创建的结构,其中访问内存位置大约需要 5 毫秒,因此,数据局部性是其设计的一个关键方面,它允许将多个值存储到每个树节点中。
由于 B 树的高分支因子,只需很少的磁盘读取即可到达存储数据的所需位置。
具有值的 B-Tree 节点
m
将最多具有
m+1
指向子节点的指针。每个指针都指向包含其两个父级之间的值的子树。
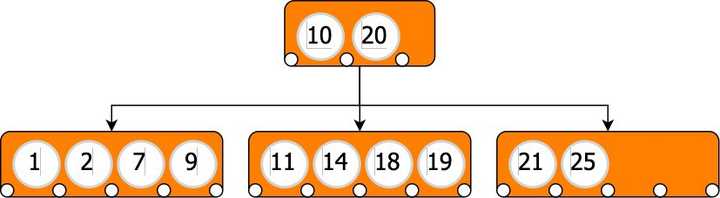
具有分支因子 3 的 B 树
在上面的 B 树中:
- 第一个指针指向一个值小于 10 的子节点
- 第二个指针指向值在 (10,20) 之间的子节点
- 第三个指针指向一个值大于 20 的子节点
如果我想为
5
B-Tree 添加值,根节点的第一个子节点将发生拆分,结果树将转换为以下树:
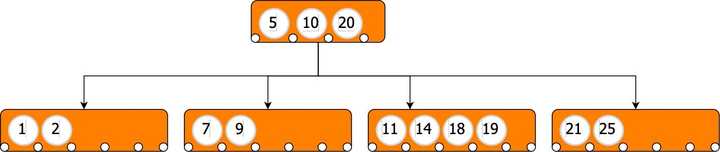
具有分支因子 4 的 B 树
分裂将孩子的中位数插入到父母中。这意味着分裂也会重新平衡树。
在上面的 B-Tree 中,插入
5
会导致拆分,将子节点的中值移动到父节点中,并且重新平衡会引入新的子节点。
这确保了二叉树的最大深度为
log(m/2)n
,其中
m
是分支因子,
n
是树中值的数量。
关于 B-Tree 需要注意的要点是:
- 搜索、插入和删除等操作具有对数时间复杂度。
- B 树是高度浅层的数据结构。具有数千个分支因子的 B 树意味着它们可以仅在两到三层中存储数百万个元素。
创建列上的索引后,如果索引的 包含与查询中的列一起使用的运算符,则查询计划器将使用
查询计划
器使用该索引列对表的任何查询,以创建最佳查询执行计划。
operator class
执行相同的查询,得到一个轨道,
Name=’Levitating’
再次以毫秒为单位产生结果,因为查询计划器将使用索引,并且能够通过两到三个磁盘读取找到所需数据的位置。此方案中使用的扫描将是索引扫描。
就像生活中所有美好的事物一样,索引是有代价的。虽然它们提供了速度,但需要空间来存储索引。这个空间的范围可以从兆字节到甚至千兆字节,有时取决于被索引的数据量。
您可以在多个字段上创建索引,也称为复合索引,并且您可以在同一个表上拥有多个索引,具体取决于该表所需的各种类型的查询。
因此,需要特别注意了解查询是如何在数据库上执行的,以及我们创建的索引是否被使用。
创建索引时需要考虑的几个非常重要的点:
-
当且仅当
WHERE查询的子句中至少包含索引的最左侧列时,查询才会使用复合索引。 - 不必为表的所有行创建索引,可以为行的子集创建索引。这在空间和时间复杂性方面具有真正的好处。
-
CREATE INDEX CONCURRENTLY ON Track Using btree (Name) WHERE ArtistId In (ArtistId1, ArtistId2, ...);使用上面的命令,我们告诉 PostgreSQL 只为其中ArtistId之一的行创建索引(ArtistId1, ArtistId2, ...)
命令中
CONCURRENTLY
使用的注意事项
CREATE INDEX
当一个表被索引时,PostgreSQL 锁定表以防止写入。仍然可以执行读取操作,但写入、更新或删除操作被阻止。在大型表可能需要数小时才能建立索引的生产环境中,这可能是不希望的。
使用时
CONCURRENTLY
,不会阻塞写操作,PostgreSQL 将等待此类事务完成。由于允许继续正常操作,因此建立索引的时间也会随着数据库服务器的 CPU 和内存利用率而增加。
#2 问题是不知道数据库中发生了什么
假设我们想要找出在数据库上运行的前三个慢查询。我们怎么能这样做呢?
1.查找昂贵的查询
从 pg_stat_statements
ORDER BY total_time DESC LIMIT 3中选择 queryid、调用、mean_time、子字符串(查询 100) ;这将为我们提供前三个昂贵查询的列表:
| 查询ID | 来电 | 平均时间 | 子串 |
|------------|-------|------------|-----------|
| 1819595255 | 18000 | 500.12 | 查询 1 |
| 10013512 | 100 | 273.25 | 查询 2 |
| 50123753 | 3000 | 252.37 | 查询 3 |2.分析昂贵的查询
下一步是分析昂贵的查询并了解查询计划器是如何执行它们的。
EXPLAIN SELECT * FROM Album WHERE Name = 'Favourite Worst Nightmare';