


用一个案例来掌握 Pandas数据可视化 之 双变量可视化!

在上一小结中,介绍了使用Pandas绘图,理解单个变量在数据中的互相关系,本小节会考察两个变量如何进行可视化
数据分析时,我们需要找到变量之间的相互关系,比如一个变量的增加是否与另一个变量有关,数据可视化是找到两个变量的关系的最佳方法
1 散点图
最简单的两个变量可视化图形是散点图,散点图中的一个点,可以表示两个变量
reviews[reviews['price'] < 100].sample(100).plot.scatter(x='price', y='points')显示结果:
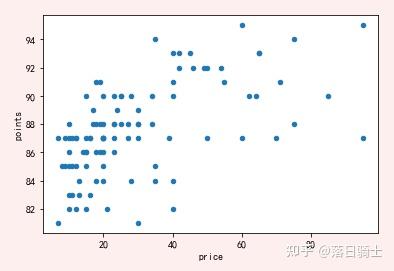
调整图形大小,字体大小,由于pandas的绘图功能是对Matplotlib绘图功能的封装,所以很多参数pandas 和 matplotlib都一样
reviews[reviews['price'] < 100].sample(100).plot.scatter(x='price', y='points',figsize=(14,8),fontsize = 16)修改x轴 y轴标签字体
# 创建绘图区域和坐标轴
fig, axes = plt.subplots(ncols=1, figsize = (20,10))
# 使用pandas 在指定坐标轴内绘图
reviews[reviews['price'] < 100].sample(100).plot.scatter(x='price', y='points',figsize=(14,8),fontsize = 16,ax = axes)
# 通过坐标轴修改x y 标签内容和字体大小
axes.set_xlabel('price',fontdict={'fontsize':16})显示结果:
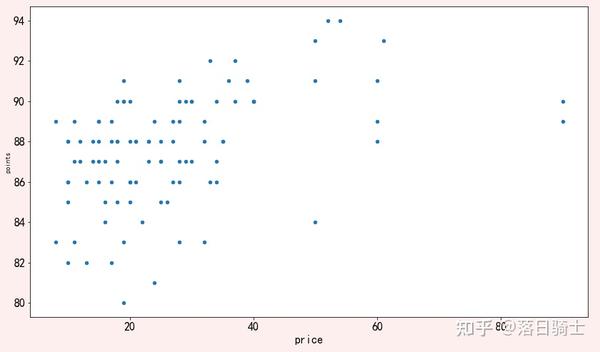
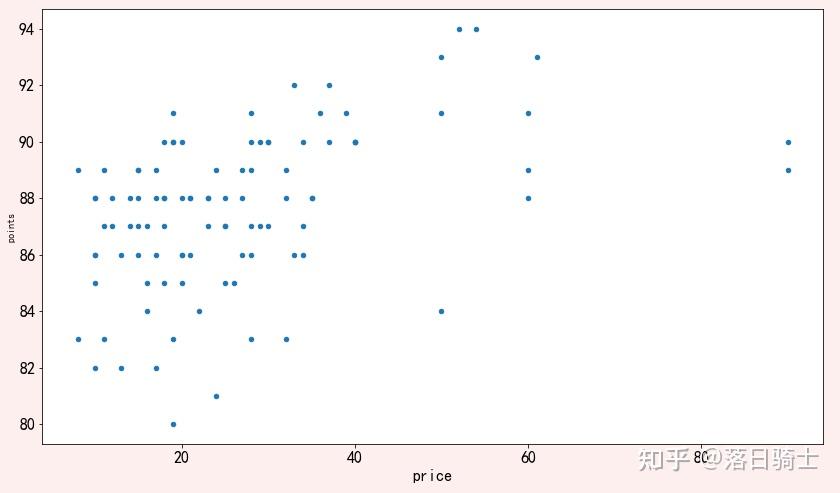
上图显示了价格和评分之间有一定的相关性:也就是说,价格较高的葡萄酒通常得分更高。
- 请注意,我们必须对数据进行采样,从所有数据中抽取100条数据,如果将全部数据(15万条)都绘制到散点图上,会有很多点重叠在一起,不方便观察
reviews[reviews['price'] < 100].plot.scatter(x='price', y='points',figsize=(12,8))显示结果:
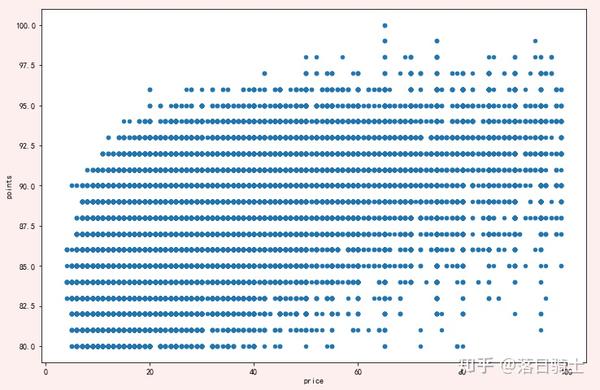
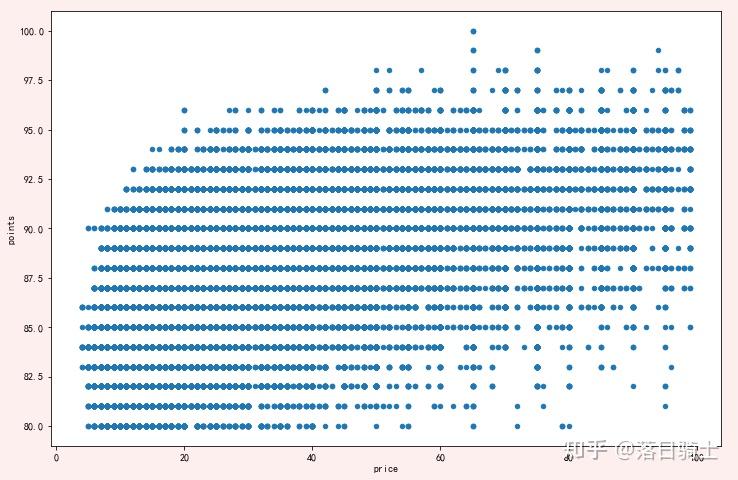
- 由于散点图的缺点,因此散点图最适合使用相对较小的数据集以及具有大量唯一值的变量。
- 有几种方法可以处理过度绘图。 一:对数据进行采样 二:hexplot(蜂巢图)
2 hexplot
hexplot将数据点聚合为六边形,然后根据其内的值为这些六边形上色:
reviews[reviews['price'] < 100].plot.hexbin(x='price', y='points', gridsize=15,figsize=(16,8))显示结果:
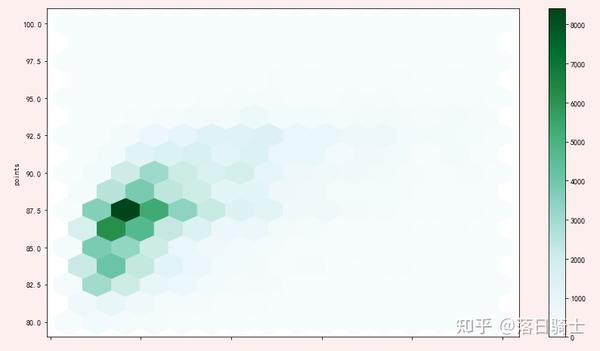
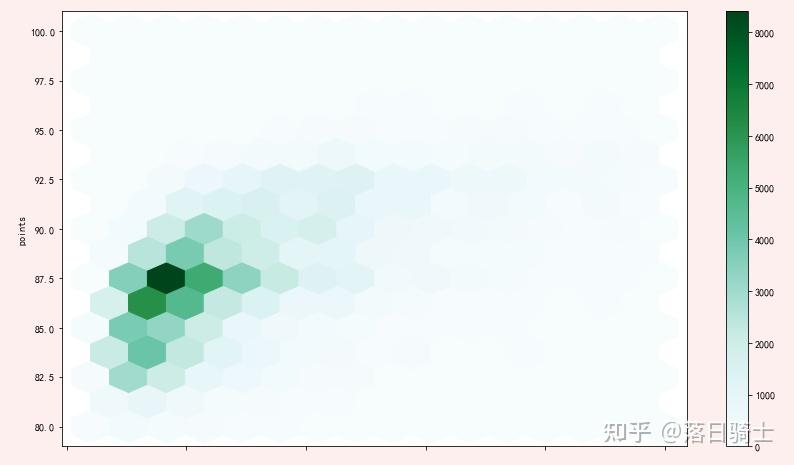
上图x轴坐标缺失,属于bug,可以通过调用matplotlib的api添加x坐标
fig, axes = plt.subplots(ncols=1, figsize = (16,8))
reviews[reviews['price'] < 100].plot.hexbin(x='price', y='points', gridsize=15,ax = axes)
axes.set_xticks([0,20,40,60,80,100])显示结果:
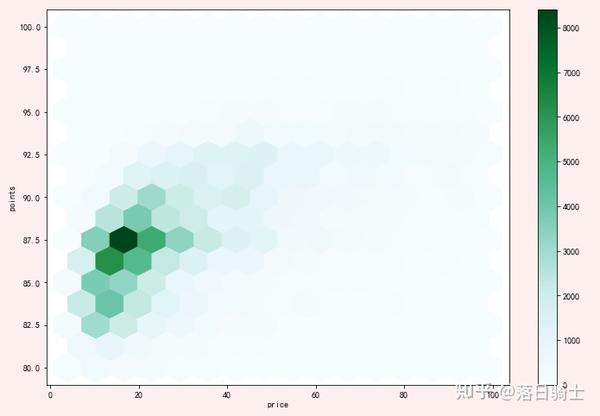
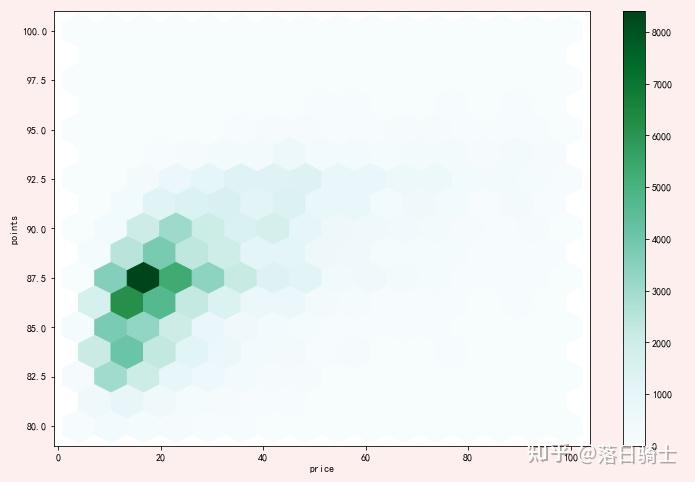
- 该图中的数据可以和散点图中的数据进行比较,但是hexplot能展示的信息更多
- 从hexplot中,可以看到《葡萄酒杂志》(Wine Magazine)评论的葡萄酒瓶大多数是87.5分,价格20美元
- Hexplot和散点图可以应用于区间变量和/或有序分类变量的组合。
3 堆叠图(Stacked plots)
- 展示两个变量,除了使用散点图,也可以使用堆叠图
- 堆叠图是将一个变量绘制在另一个变量顶部的图表
- 接下来通过堆叠图来展示最常见的五种葡萄酒
# 将葡萄酒种类分组,找到最常见的五种葡萄酒
reviews.groupby(['variety'])['country'].count().sort_values(ascending = False)显示结果:
variety
Chardonnay 14482
Pinot Noir 14288
Cabernet Sauvignon 12800
Red Blend 10061
Bordeaux-style Red Blend 7347
Chinuri 1
Petit Meslier 1
Espadeiro 1
Parraleta 1