|
|
|


在相同业务场景下,架构设计和库表索引设计会影响查询性能,良好的设计可以提高查询性能,反之会出现很多慢SQL(执行时间很长的SQL语句)。本文介绍导致慢SQL的原因和解决方案。
查看慢SQL
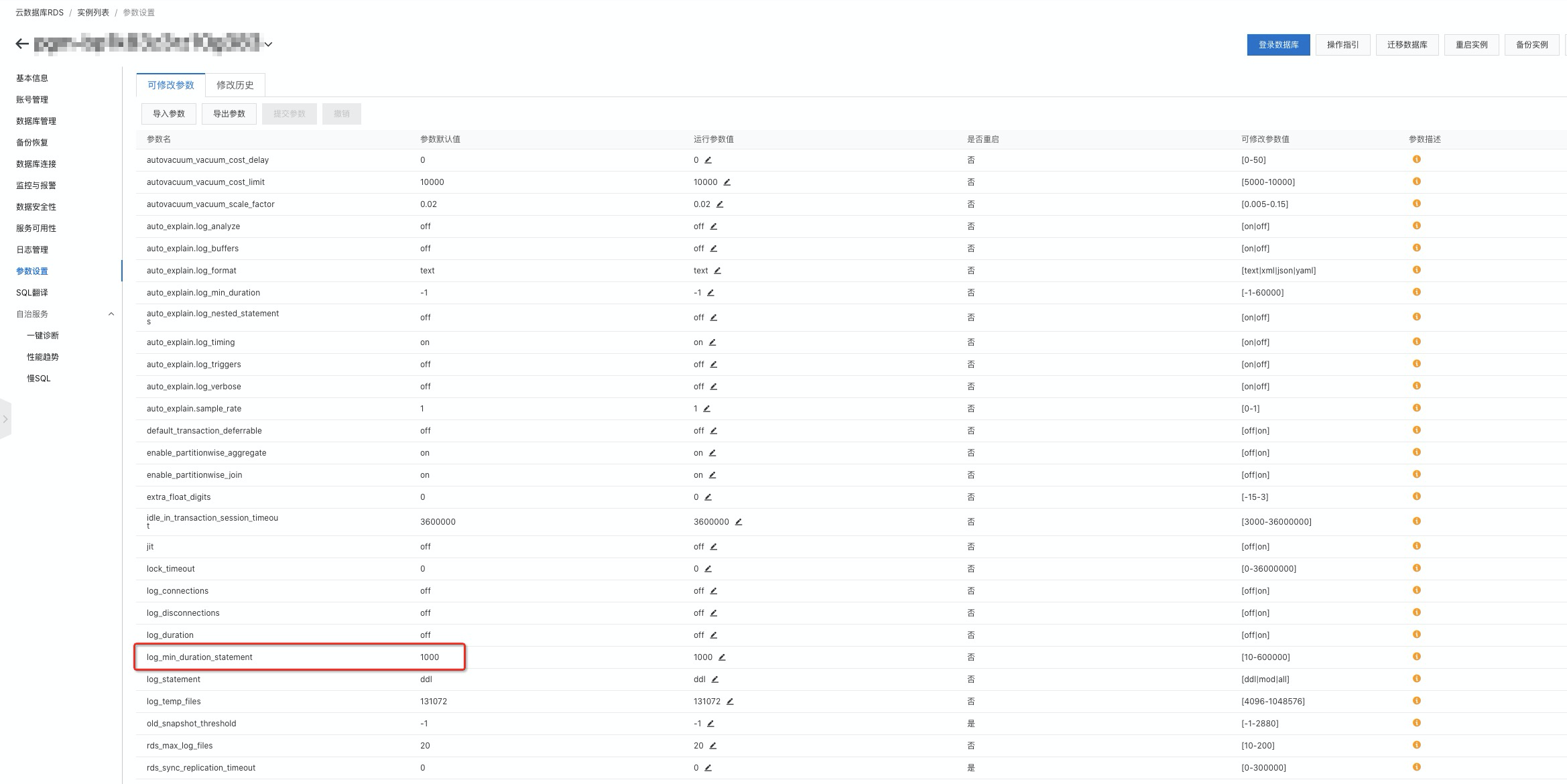
控制台的 参数设置 中,可以找到名为 log_min_duration_statement 的参数,该参数的作用是设置慢日志判定的阈值,单位为ms。默认值为1000,即响应时间超过1秒的SQL会被记录到慢SQL日志中。
 通过查看控制台的
日志管理
中的
慢日志明细
页签,可以查看当前系统中存在的慢SQL。
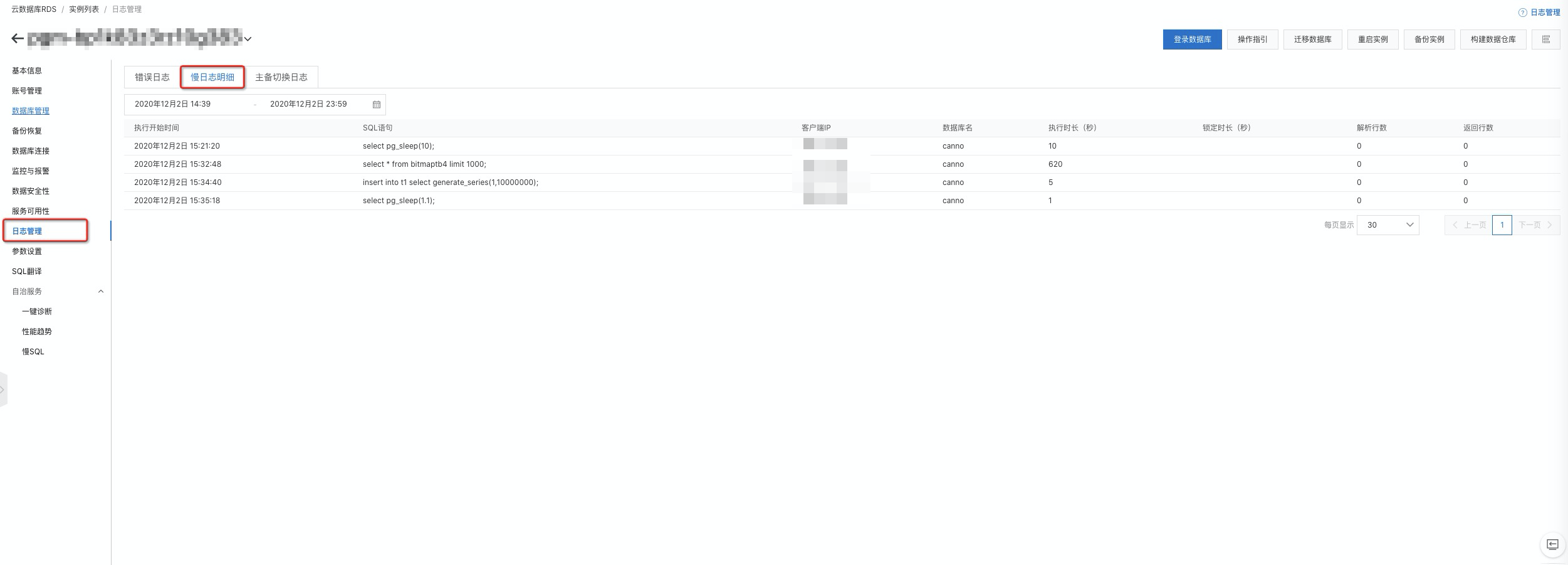
通过查看控制台的
日志管理
中的
慢日志明细
页签,可以查看当前系统中存在的慢SQL。
 您只需在
参数设置
中开启
auto_explain.log_analyze
、
auto_explain.log_buffers
、
auto_explain.log_min_duration
三个参数,即可在
慢日志明细
中查看慢SQL的执行计划。
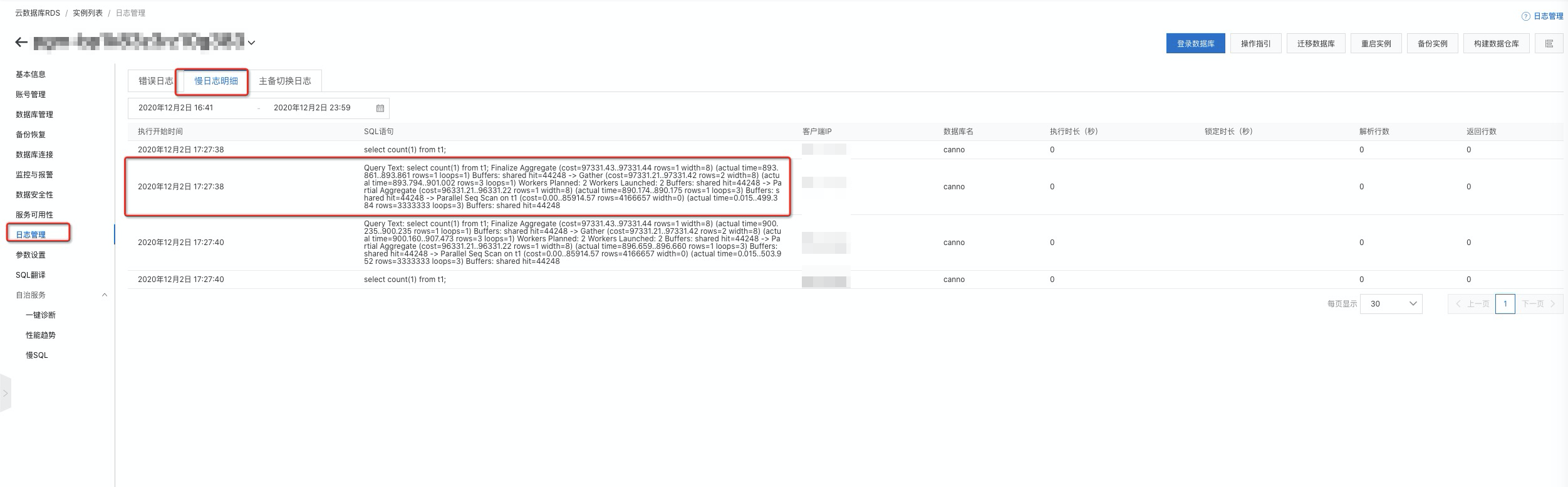
您只需在
参数设置
中开启
auto_explain.log_analyze
、
auto_explain.log_buffers
、
auto_explain.log_min_duration
三个参数,即可在
慢日志明细
中查看慢SQL的执行计划。
EXPLAIN命令
定位到慢SQL之后,可以通过EXPLAIN命令查询该SQL的执行计划,帮助您深入了解目标SQL的启动代价。
EXPLAIN [ ( option [, ...] ) ] statement上面EXPLAIN命令中的option可选参数的说明如下:
-
ANALYZE [ boolean ]:执行SQL语句并返回实际运行时间。默认值:
FALSE。 -
VERBOSE [ boolean ]:显示关于计划的额外信息。默认值:
FALSE。 -
COST [ boolean ]:显示执行计划中每一个计划节点的启动时间、总执行代价、预估行数以及每行的宽度。默认值:
TRUE。 -
BUFFERS [ boolean ]:缓冲区使用的信息。例如:共享块命中、读取、标记为脏和写入的次数、本地块命中、读取、标记为脏和写入的次数、临时块读取和写入的次数。默认值:
FALSE。 -
TIMING [ boolean ]:显示实际启动时间以及在每个计划节点中花费的时间。仅当ANALYZE为
TRUE时可用。默认值:TRUE。 -
SUMMARY [ boolean ]:在查询计划后面包含摘要信息(例如共计花费多长时间)。当ANALYZE为
TRUE时自动开启。默认值:FALSE。 -
FORMAT { TEXT | XML | JSON | YAML }:指定输出格式。默认值:
TEXT。
例如,执行
EXPLAIN SELECT * from test;
返回的结果如下:
QUERY PLAN
----------------------------------------------------
Seq Scan on test (cost=0.00..1.01 rows=1 width=4)
(1 row)
上面的返回结果中,
cost=0.00..1.01 rows=1 width=4
为估算出的SQL预计执行代价,其中
0.00
为启动SQL语句到返回第一行数据所需的启动代价,
1.01
为返回所有行所需的总代价。
EXPLAIN (ANALYZE) DML-SQL 注意事项
EXPLAIN (ANALYZE) 语句的工作方式类似于 EXPLAIN ,主要区别在于 EXPLAIN (ANALYZE) 语句实际会执行SQL。如果SQL涉及数据变更,即DML SQL( UPDATE 、 INSERT 或 DELETE ),务必在事务中执行 EXPLAIN (ANALYZE) ,查看完成后再进行回滚。
命令示例:
BEGIN;
EXPLAIN (ANALYZE) <DML(UPDATE/INSERT/DELETE) SQL>;
ROLLBACK;如何阅读执行计划
EXPLAIN命令的输出可以看作是一个树状结构,即查询计划树。树的每一个节点包含节点类型、作用对象及其他属性信息。其中节点类型分如下几大类:
-
控制节点(Control Node)
-
扫描节点(ScanNode)
-
物化节点(Materialization Node)
-
连接节点(Join Node)
其中扫描节点又包含多种扫描方式,本文列举常用的几个进行详细介绍:
-
Seq Scan:
顺序扫描全表,一般用在查询没有索引的表,例如
explain(ANALYZE,VERBOSE,BUFFERS) select * from class where st_no=2;命令的返回结果如下:QUERY PLAN -------------------------------------------------------------------------------------------------- Seq Scan on public.class (cost=0.00..26.00 rows=1 width=35) (actual time=0.136..0.141 rows=1 loops=1) //Seq Scan on public.class表示这个节点的类型和作用对象,即在class表上进行全表扫描。 //(cost=0.00..26.00 rows=1 width=35)表示该节点的代价估计,0.00是节点启动成本,26.00为该节点的代价,rows是该节点输出行的估计值,width是该节点输出行的平均宽度。 //(actual time=0.136..0.141 rows=1 loops=1) 表示该节点的真实执行信息,0.136表示该节点启动时间,单位为ms。0.141表示该节点耗时,单位为ms。rows代表实际输出行。loops代表节点循环次数。 Output: st_no, name //代表SQL输出结果集的各个列,仅在EXPLAIN命令中的VERBOSE选项为on时才会显示。 Filter: (class.st_no = 2) //表示Seq Scan节点中Filter操作,即全表扫描时对每行记录进行过滤操作,过滤条件为class.st_no = 2。 Rows Removed by Filter: 1199 //表示过滤了多少行记录,属于Seq Scan节点的VERBOSE信息,仅在EXPLAIN命令中的VERBOSE选项为on时才会显示。 Buffers: shared hit=11 //表示在共享缓存中命中了11个数据块,属于Seq Scan节点的BUFFERS信息,仅在EXPLAIN命令中的BUFFERS选项为on时才会显示。 Planning time: 0.066 ms //表示生成查询计划的用时。 Execution time: 0.160 ms //表示实际的SQL执行用时,不包括生成查询计划的用时。 -
Index Scan:
索引扫描,主要用在WHERE条件中存在索引列的情况,例如,假设
st_no列中存在索引,则explain(ANALYZE,VERBOSE,BUFFERS) select * from class where st_no=2;命令的返回结果如下:QUERY PLAN -------------------------------------------------------------------------------------------------- Index Scan using no_index on public.class (cost=0.28..8.29 rows=1 width=35) (actual time=0.022..0.023 rows=1 loops=1) //表示使用public.class表的no_index索引对表进行索引扫描。 Output: st_no, name Index Cond: (class.st_no = 2) //表示索引扫描的条件为class.st_no = 2。 Buffers: shared hit=3 Planning time: 0.119 ms Execution time: 0.060 ms (6 rows)从上述结果可以看出,使用索引之后,在相同条件下对同一张表的扫描速度变快了。需要扫描的数据块少了之后,需要的代价变小了,速度也更快了。
-
Index Only Scan:
覆盖索引扫描,仅返回指定的索引列,例如
explain(ANALYZE,VERBOSE,BUFFERS) select st_no from class where st_no=2;命令的返回结果如下:QUERY PLAN -------------------------------------------------------------------------------------------------- Index Only Scan using no_index on public.class (cost=0.28..4.29 rows=1 width=4) (actual time=0.015..0.016 rows=1 loops=1) //表示使用public.class表的no_index索引对表进行覆盖索引扫描。 Output: st_no Index Cond: (class.st_no = 2) Heap Fetches: 0 //表示需要扫描的数据块的个数。 Buffers: shared hit=3 Planning time: 0.058 ms Execution time: 0.036 ms (7 rows) -
Bitmap Index Scan:
利用Bitmap结构扫描。Bitmap Index Scan与Index Scan都是基于索引的扫描,但Bitmap Index Scan节点返回的是一个位图而不是一个元组,位图中每位代表了一个扫描到的数据块。
-
Bitmap Heap Scan:
Bitmap Heap Scan一般作为Bitmap Index Scan的父节点,将Bitmap Index Scan返回的位图转换为对应的元组。相比Index Scan,Bitmap Index Scan将随机读转换成了按照数据块的物理顺序读取,这在数据量比较大的时候会极大地提升扫描性能。例如
explain(ANALYZE,VERBOSE,BUFFERS) select * from class where st_no=2;命令的返回结果如下:QUERY PLAN -------------------------------------------------------------------------------------------------- Bitmap Heap Scan on public.class (cost=4.29..8.30 rows=1 width=35) (actual time=0.025..0.025 rows=1 loops=1) Output: st_no, name //表示对public.class表进行Bitmap Heap扫描。 Recheck Cond: (class.st_no = 2) //表示Bitmap Heap Scan的Recheck操作的条件是class.st_no = 2。 Heap Blocks: exact=1 //表示准确扫描到的数据块个数是1。 Buffers: shared hit=3 -> Bitmap Index Scan on no_index (cost=0.00..4.29 rows=1 width=0) (actual time=0.019..0.019 rows=1 loops=1) //表示使用no_index索引进行位图索引扫描。 Index Cond: (class.st_no = 2) //表示位图索引的条件为class.st_no = 2。 Buffers: shared hit=2 Planning time: 0.088 ms Execution time: 0.063 ms (10 rows)说明-
在大多数情况下,Index Scan要比Seq Scan快。
-
如果获取的结果集在所有数据中占比很大时,Index Scan因为要先扫描索引再读表数据,所以反而会比Seq Scan慢。
-
如果获取的结果集的占比比较小,但是元组数很多时,Bitmap Index Scan的性能要比Index Scan好。
-
如果获取的结果集能够被索引覆盖,则Index Only Scan因为仅需扫描索引,正常情况下性能最好。如果存在可见性映射表(Virtual Map)未生成等特殊情况,性能则会下降。
-
SQL优化示例
本节列举两个示例,分别使用EXPLAIN命令对SQL优化前后的表进行分析,对比一下前后的差距。
无索引表的优化
-
SQL优化前:对无索引的表T1执行
explain analyze select * from t1 where id =1;命令的返回结果如下。QUERY PLAN ------------------------------------------------------------------------------------------------------------------- Gather (cost=1000.00..97331.31 rows=1 width=4) (actual time=0.217..302.316 rows=1 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on t1 (cost=0.00..96331.21 rows=1 width=4) (actual time=191.208..289.240 rows=0 loops=3) Filter: (id = 1) Rows Removed by Filter: 3333333 Planning Time: 0.030 ms Execution Time: 302.381 ms (8 rows)通过计划可以看出,
SELECT针对T1表进行了全表扫描,过滤条件为id=1,总执行时间为302.381ms,效率不是很理想。 -
SQL优化后:通过
create index on t1(id)给T1表中的id列创建索引,重新执行explain analyze select * from t1 where id =1;命令,返回结果如下。QUERY PLAN ------------------------------------------------------------------------------------------------------------------- Index Only Scan using t1_id_idx on t1 (cost=0.43..2.45 rows=1 width=4) (actual time=0.035..0.036 rows=1 loops=1) Index Cond: (id = 1) Heap Fetches: 1 Planning Time: 0.134 ms Execution Time: 0.052 ms (5 rows)总执行时间缩短至
0.052ms,相比优化前的302.381ms提升了数千倍。
非最佳索引表的优化
创建一张名为T2的表,插入100万条随机数据,并对
id
列创建索引。
create table t2(id int,name int);
insert into t2 select random()*(id/100),random()*(id/100) from generate_series(1,1000000) t(id);
create index on t2(id)-
SQL优化前:执行
explain analyze select * from t2 where id=10 and name=13;命令的返回结果如下。QUERY PLAN ---------------------------------------------------------------------------------------------------------------- Index Scan using t2_id_idx on t2 (cost=0.42..12.12 rows=1 width=8) (actual time=0.098..2.631 rows=88 loops=1) Index Cond: (id = 10) Filter: (name = 13) Rows Removed by Filter: 4461 Planning Time: 0.081 ms Execution Time: 2.655 ms (6 rows)通过计划可以看出已经做了索引扫描,但是还存在
name列的条件过滤,还有优化的空间。 -
SQL优化后:通过
create index on t2(id,name);给T2表中的id列和name列各增加一个索引。重新执行explain analyze select * from t2 where id=10 and name=13;命令,返回结果如下。QUERY PLAN --------------------------------------------------------------------------------------------------------------------------- Index Only Scan using t2_id_name_idx on t2 (cost=0.42..15.48 rows=18 width=8) (actual time=0.028..0.134 rows=88 loops=1) Index Cond: ((id = 10) AND (name = 13)) Heap Fetches: 88 Planning Time: 0.198 ms Execution Time: 0.157 ms (5 rows)总执行时间缩短至
0.157ms,优化成功。