

一、读取图片
1.1 imshow和WaitKey方法
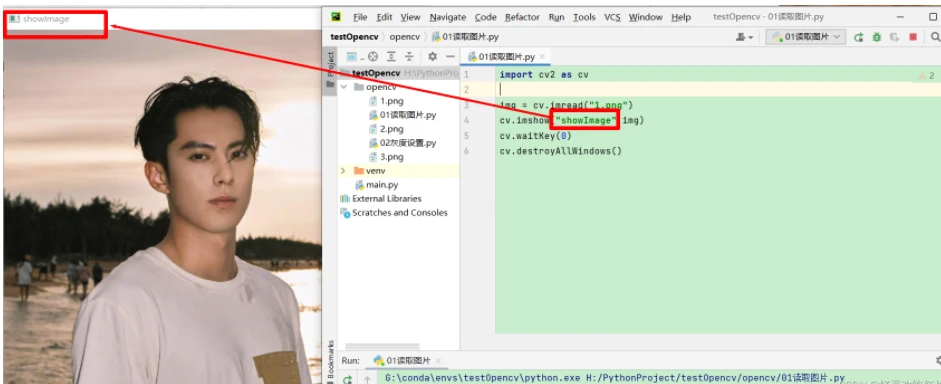
1.2 代码实现
1.3 效果展示
二、图片灰度化
2.1 图片灰度化作用
2.2 所需方法
2.2.1 设置灰度方法
2.2.2 保存图片方法
2.3 代码实现
2.4 效果展示
2.4.1 显示灰度图片
2.4.2 保存灰度图片
三、尺寸转换
3.1 尺寸转换方法
3.2 代码展示
3.3 效果展示
3.3.1 显示修改后的图片
3.3.2 保存图片
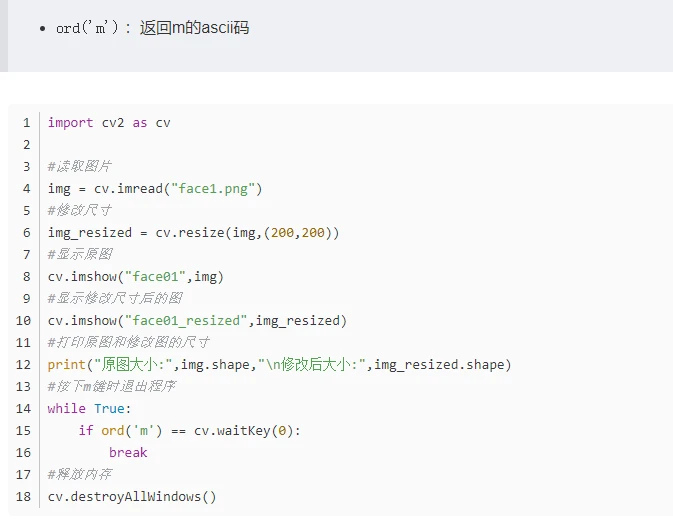
3.3.3 输出图片的大小
3.4 按下英文输入法中的m键后退出程序
四、绘制矩形和圆形框
4.1 绘制矩形
4.2 绘制圆形
4.3 代码实现
4.4 效果展示
五、人脸检测
5.1 OpenCV自带的分类器
5.2 detectMultiScale方法
5.3 代码
5.4 效果展示
六、检测多个人脸
6.1 代码实现
6.2 效果展示
七、对视频的检测
7.1 所需函数
7.1.1 创建读取摄像头/视频对象的函数
7.1.2 读取视频帧函数
7.1.3 释放图像
7.1.4 WaitKey方法
7.2 摄像头捕获识别
7.2.1 代码实现
7.3 视频捕获
八、人脸信息录入
8.1 所需函数
8.2 0xFF的意义
8.3 代码实现
8.4 效果展示
九、 数据训练
9.1 项目目录结构
9.2 运行时出现的问题
9.3 代码
9.4 运行结果
十、人脸识别
十一、网络视频
一、读取图片
1.1 imshow和WaitKey方法
waitKey()–是在一个给定的时间内(单位ms)等待用户按键触发;
waitKey() 函数的功能是不断刷新图像 , 频率时间为delay , 单位为ms
返回值为当前键盘按键值
如果用户没有按下键,则继续等待 (循环)
常见 : 设置 waitKey(0) , 则表示程序会无限制的等待用户的按键事件;一般在 imgshow 的时候 , 如果设置 waitKey(0) , 代表按任意键继续
waitkey控制着imshow的持续时间,当imshow之后不跟waitkey时,相当于没有给imshow提供时间展示图像,所以只有一个空窗口一闪而过。添加了waitkey后,哪怕仅仅是 CV2 .waitkey(1),我们也能截取到一帧的图像。所以 CV2 .imshow后边是必须要跟 CV2 .waitkey的。
1.2 代码实现

1.3 效果展示
二、图片灰度化
2.1 图片灰度化作用
图像处理时为什么灰度化_图像灰度化处理的目的_whaosoft143的博客-CSDN博客
为什么做图片识别要将彩色图像灰度化呢?
图像灰度化的目的是为了简化矩阵,提高运算速度。
彩色图像中的每个像素颜色由R、G、B三个分量来决定,而每个分量的取值范围都在0-255之间,这样对计算机来说,彩色图像的一个像素点就会有256*256*256=16777216种颜色的变化范围!
而灰度图像是R、G、B分量相同的一种特殊彩色图像,对计算机来说,一个像素点的变化范围只有0-255这256种。
彩色图片的信息含量过大,而进行图片识别时,其实只需要使用灰度图像里的信息就足够了,所以图像灰度化的目的就是为了提高运算速度。
当然,有时图片进行了灰度处理后还是很大,也有可能会采用二值化图像(即像素值只能为0或1)。
2.2 所需方法
2.2.1 设置灰度方法
cvtColor()
2.2.2 保存图片方法
imwrite()
2.3 代码实现

2.4 效果展示
2.4.1 显示灰度图片
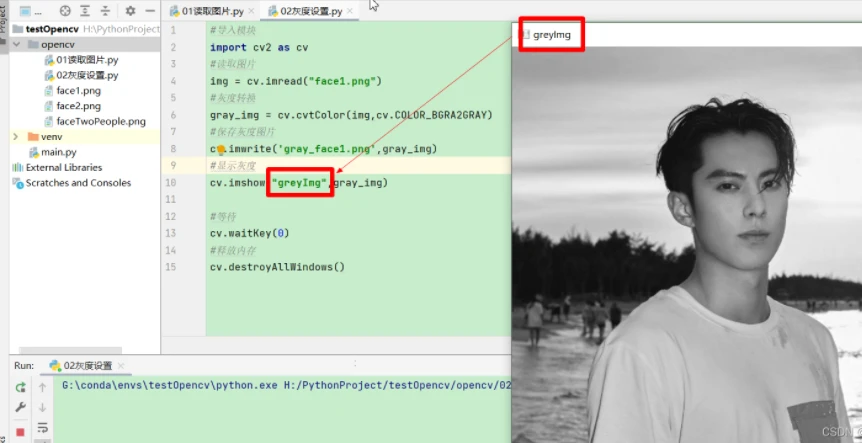
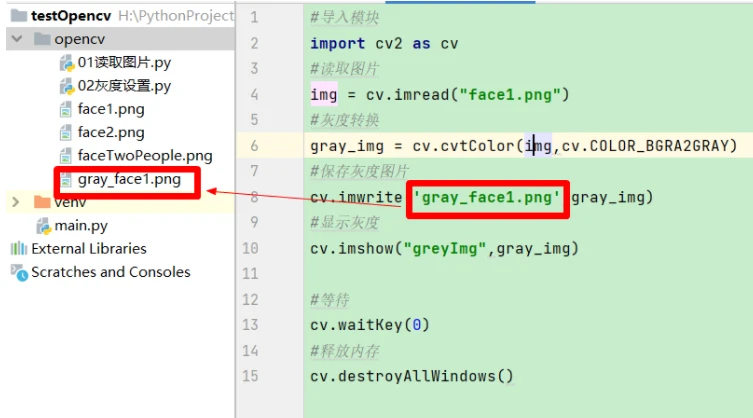
2.4.2 保存灰度图片
在关闭显示的灰度图片后,会将该图片进行保存
三、尺寸转换
3.1 尺寸转换方法
resize()
3.2 代码展示

3.3 效果展示
3.3.1 显示修改后的图片
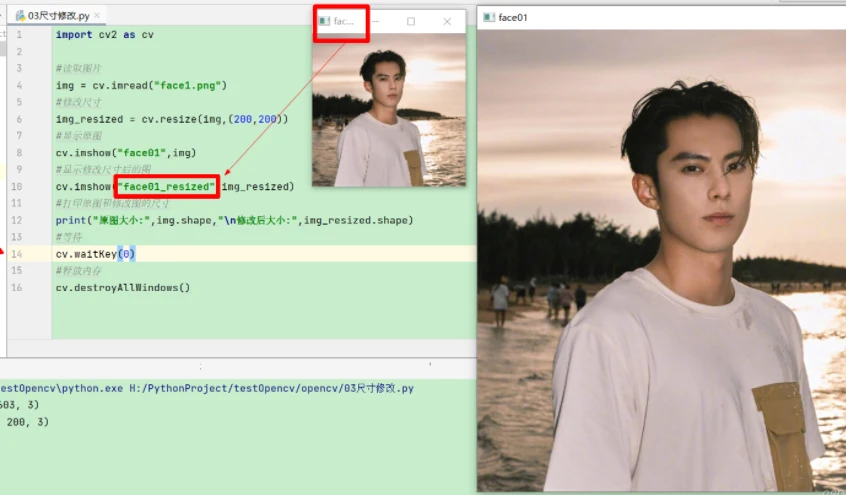
3.3.2 保存图片
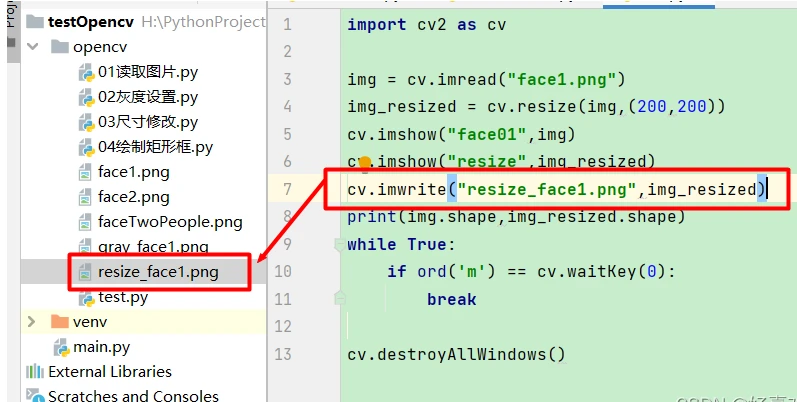
3.3.3 输出图片的大小
3为彩色图片的通道数。

3.4 按下英文输入法中的m键后退出程序
四、绘制矩形和圆形框
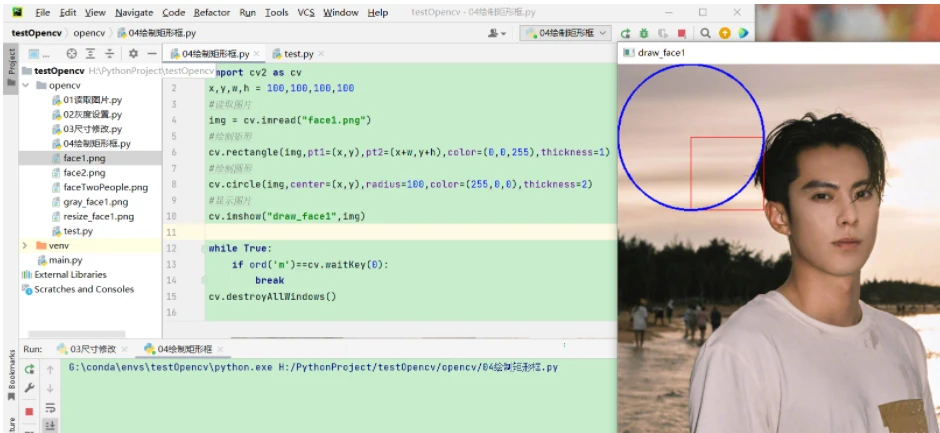
4.1 绘制矩形
CV2 .rectangle(img, pt1, pt2, color, thickness=None, lineType=None, shift=None)
参数介绍:
python版opencv函数学习笔记-cv.rectangle()全参数理解_风一样的夏天001的博客-CSDN博客
作用:根据给定的左上顶点和右下顶点画矩形
参数说明:
img:指定一张图片,在这张图片的基础上进行绘制;
pt1: 矩形的一个顶点;
pt2: 与pt1在对角线上相对的矩形的顶点;
color:指定边框的颜色,由(B,G,R)组成,当为(255,0,0)时为绿色,可以自由设定;
thinkness:线条的粗细值,为正值时代表线条的粗细(以像素为单位),为负值时边框实心;
4.2 绘制圆形
CV2 .circle(img, center, radius, color, thickness=None, lineType=None, shift=None):
作用:根据给定的圆心和半径等画圆
参数说明:
img:输入的图片data
center:圆心位置
radius:圆的半径
color:圆的颜色
thickness:圆形轮廓的粗细(如果为正)。负厚度表示要绘制实心圆。
4.3 代码实现

4.4 效果展示
五、人脸检测
5.1 OpenCV自带的分类器
在下图的路径中,我们可以看到需要xml文件,这些都是OpenCV中自带的分类器,根据文件名我们可以看到有识别眼睛的,身体的,脸的,等等。
使用cv.CascadeClassifier(参数:分类器所在路径)方法定义一个分类器对象。
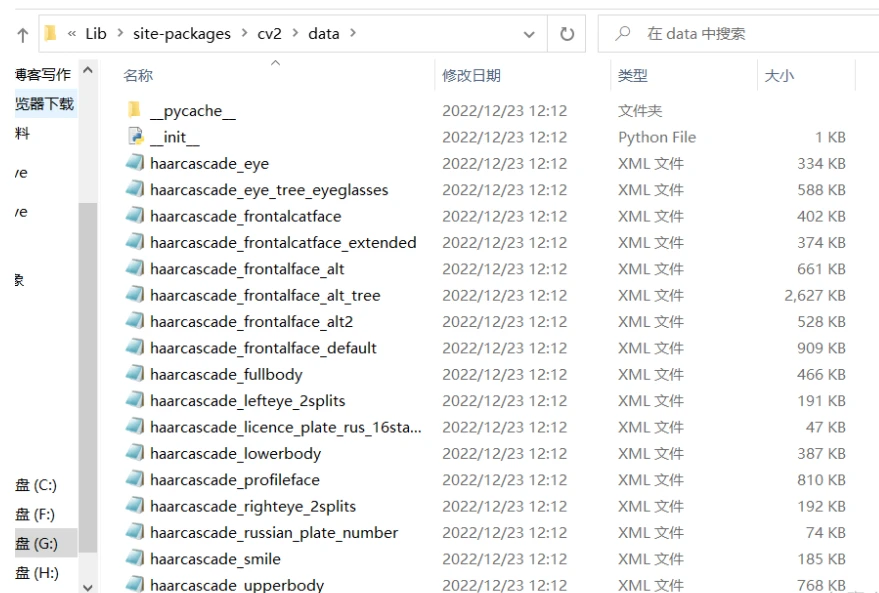
我的分类器所在位置:
OpenCV分类器路径:G:\conda\envs\testOpencv\Lib\site-packages\ CV2 \data
本次使用的分类器文件名:haarcascade_frontalface_alt2.xml
在代码中输入的完整路径(需要把右下划线改为左下划线): G:/conda/envs/testOpencv/Lib/site-packages/ CV2 /data/haarcascade_frontalface_alt2.xml
5.2 detectMultiScale方法
opencv人脸检测--detectMultiScale函数_walker lee的博客-CSDN博客_detectmultiscale
detectMultiScale
(self,
image: Any,
scaleFactor: Any = None,
minNeighbors: Any = None,
flags: Any = None,
minSize: Any = None,
maxSize: Any = None)
作用:
它可以检测出图片中所有的人脸,并将人脸用vector保存各个人脸的坐标、大小,用矩形Rect类表示,函数由分类器对象调用。
参数介绍:
image: 待检测图片,一般为灰度图像加快检测速度;
scaleFactor:表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1,即每次搜索窗口依次扩大10%; scale_factor参数可以决定两个不同大小的窗口扫描之间有多大的跳跃,这个参数设置的大,则意味着计算会变快,但如果窗口错过了某个大小的人脸,则可能丢失物体
minNeighbors:默认值为3,表示每一个目标至少要被检测到3次才算是真的目标(因为周围的像素和不同的窗口大小都可以检测到人脸),
flags:一般使用默认值0;
minSize和maxSize用来限制得到的目标区域的最大/最小尺寸。
5.3 代码

5.4 效果展示
此时为没有设定参数,可以看到图片识别人脸出现了失误,把背景中的海浪也识别为了人脸。
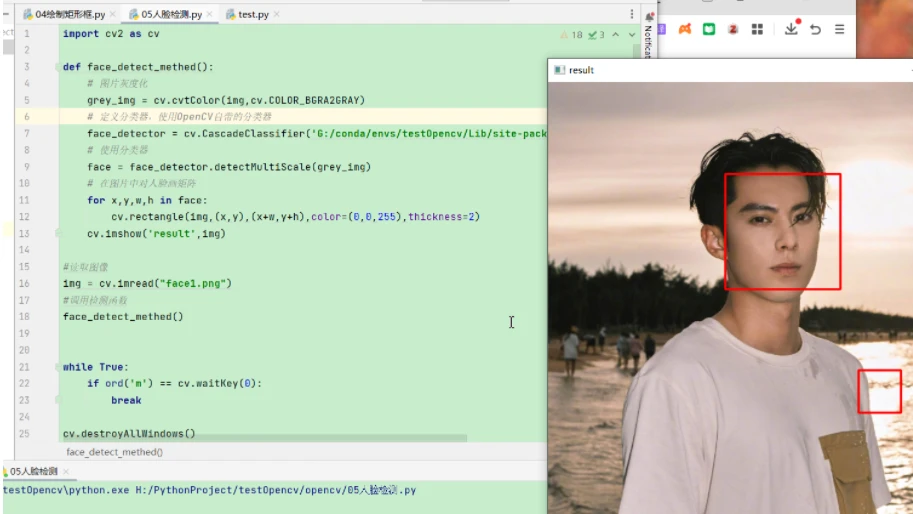
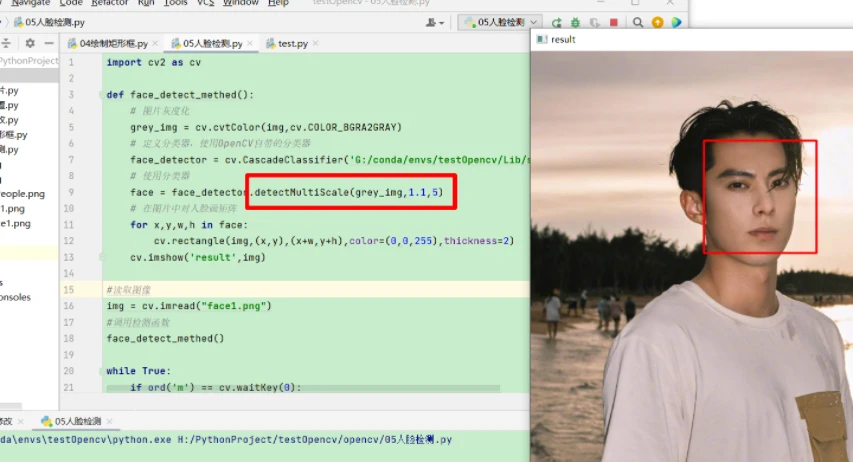
在调整了参数后可以看到,人脸识别正确,识别出了一个人脸
六、检测多个人脸
此次可以识别多个人脸,与识别一个人脸的代码基本相同,这次换了一个分类器,即OpenCV自带的默认人脸识别分类器,调整了一下detectMultiScale的参数,识别结果较为准确,但是有一个人脸未识别出来。
6.1 代码实现

6.2 效果展示
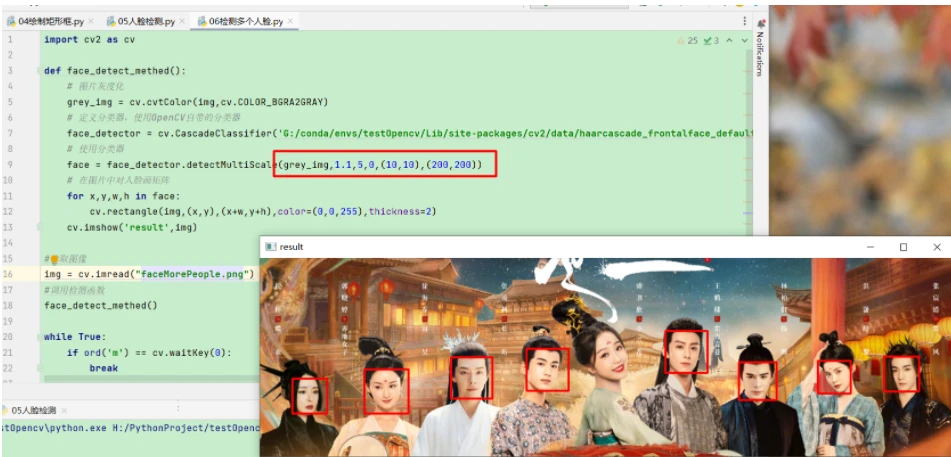
可以看到识别的不算准确,c位的人脸没有被识别出来,我挑了很多次参数也换了分类器还是不行,就这样吧那~

换了一张有两个人脸的照片,可以检测出来。

七、对视频的检测
7.1 所需函数
7.1.1 创建读取摄像头/视频对象的函数
cap = CV2 .VideoCapture(filepath)
cap为读取摄像头或视频的对象。
CV2 .VideoCapture可以捕获摄像头,用数字来控制不同的设备,例如cv.VideoCapture(0)为电脑自带摄像头,1为外接摄像头。
如果是视频文件,直接指定好路径即可,如 cv.VideoCapture('G:/1.mp4'),即读取在G盘中名为1的MP4视频文件。
7.1.2 读取视频帧函数
flag, frame = cap.read()
第一个参数flag为True或者False,代表有没有读取到图片
第二个参数frame表示截取到一帧的图片
在这里我们需要使用一个循环判断是否捕获到图像:
如果flag==false,说明视频结束,退出循环
否则则继续将视频中捕获到的帧图像放入检测函数face_detect_method中进行检测。
while True:
flag,frame = cap.read()
if not flag:
break
face_detect_method(frame)
if ord('c')==cv.waitKey(1):
break
7.1.3 释放图像
cap.release()
使用结束后释放摄像头资源。
7.1.4 WaitKey方法
需要设置WaitKey方法的参数为1,如果为0的话则只能捕获到视频的第一帧,不能播放视频。
7.2 摄像头捕获识别
7.2.1 代码实现
可以看到
import CV2 as cv
# 检测方法定义
def face_detect_method(img):
grey_img = cv.cvtColor(img,cv.COLOR_BGRA2GRAY)
face_detector = cv.CascadeClassifier("G:/conda/envs/testOpencv/Lib/site-packages/ CV2 /data/haarcascade_frontalface_default.xml")
face = face_detector.detectMultiScale(grey_img,1.02,4)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
cv.imshow("result",img)
#读取摄像头
cap = cv.VideoCapture(0)
#读取视频
#cap = cv.VideoCapture('G:/1.mp4')
# 循环判断
while True:
flag,frame = cap.read()
if not flag:
break
face_detect_method(frame)
if ord('c')==cv.waitKey(1):
break
cv.destroyAllWindows()
cap.release()
可以看到打开摄像头后成功识别到了我的脸,两个人的也可以识别。
7.3 视频捕获
使用如下语句读取存储的视频:
cap = cv.VideoCapture('G:/1.mp4')
import CV2 as cv
# 检测方法定义
def face_detect_method(img):
grey_img = cv.cvtColor(img,cv.COLOR_BGRA2GRAY)
face_detector = cv.CascadeClassifier("G:/conda/envs/testOpencv/Lib/site-packages/ CV2 /data/haarcascade_frontalface_default.xml")
face = face_detector.detectMultiScale(grey_img,1.02,4)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
cv.imshow("result",img)
#读取摄像头
#cap = cv.VideoCapture(0)
#读取视频
cap = cv.VideoCapture('G:/1.mp4')
# 循环判断
while True:
flag,frame = cap.read()
if not flag:
break
face_detect_method(frame)
if ord('c')==cv.waitKey(1):
break
cv.destroyAllWindows()
cap.release()
试了一段去青岛旅游的时候拍的视频,效果还是可以的,大部分的人脸都能识别出来。
八、人脸信息录入
8.1 所需函数
cap.isOpened()
判断视频对象是否成功读取,成功读取视频对象返回True。
8.2 0xFF的意义
CV2 .waitKey(1000) & 0xFF == ord(‘q’) 是什么意思
CV2 .waitKey(1000):在1000ms内根据键盘输入返回一个值
0xFF :一个十六进制数
ord('q') :返回q的ascii码
0xFF是一个十六进制数,转换为二进制是11111111。waitKey返回值的范围为(0-255),刚好也是8个二进制位。那么我们将 CV2 .waitKey(1) & 0xFF计算一下(不知怎么计算的可以百度位与运算)发现结果仍然是waitKey的返回值,那为何要多次一举呢?直接 CV2 .waitKey(1) == ord('q')不就好了吗。
实际上在linux上使用waitkey有时会出现waitkey返回值超过了(0-255)的范围的现象。通过 CV2 .waitKey(1) & 0xFF运算,当waitkey返回值正常时 CV2 .waitKey(1) = CV2 .waitKey(1000) & 0xFF,当返回值不正常时, CV2 .waitKey(1000) & 0xFF的范围仍不超过(0-255),就避免了一些奇奇怪怪的BUG。
8.3 代码实现
我们使用电脑自带的摄像头进行人脸的信息捕获,使用num对保存图片进行计数。
使用cap.isOpened()方法来判断摄像头是否开启。
使用frame保存视频中捕获到的帧图像,k获取键盘按键,s代表保存图像,空格代表退出程序。
当按下s键时,使用 CV2 .imwrite方法对图片进行保存,图片的保存路径和命名方法按自己的习惯来;我的保存路径是H盘的face_detect_save文件夹,命名格式为People(num).face.jpg。
计数器+1,表示保存图片张数+1,继续保存下一张。
按下空格键,退出循环,释放摄像头资源和内存空间。
import CV2 as cv
#创建摄像头对象
cap = cv.VideoCapture(0)
#记录保存图片的数目
num = 1
# 当摄像头开启时
while(cap.isOpened()):
ret,frame = cap.read()
cv.imshow("show",frame)
# 获取按键
k = cv.waitKey(1)&0xFF
#按下s保存图像
if k ==ord('s'):
cv.imwrite("H:/face_detect_save/"+"People"+str(num)+".face"+".jpg",frame)
print("sucessfully saved"+str(num)+".jpg")
print("---------------")
#计数加一
num+=1
#按下空格退出
elif k==ord(' '):
break
cap.release()
cv.destroyAllWindows()
8.4 效果展示
程序开始运行时,摄像头会自动打开,按下s键后可以保存图片到对应的路径中。
我保存了两张图片,可以看到对应的文件夹中已经进行了显示。
九、 使用数据训练识别器
用图片训练一个LBPH的识别器,这里使用15张
9.1 项目目录结构
提前创建好data和trainer两个文件夹
trainer为空文件夹
data文件夹下继续创建jm文件夹,在jm其中放置训练的图片,图片命名方式为:序号.姓名 ,这里我用17张王鹤棣人脸图片进行训练图片。
9.2 主要步骤介绍
9.2.1 采集图片文件夹中的所有文件
os.listdir可以获取path中的所有图像文件名,然后使用os.path.join方法把文件夹路径和图片名进行拼接,存储在imagePaths列表中,此时列表中存储的就是图片的完整路径,方便下一步open该图片。
9.3 运行时出现的问题
识别不到 CV2 模块中的face属性
解决方法:使用pip install命令安装opencv-库
对于“module ‘ CV2 . CV2 ‘ has no attribute ‘face‘与module ‘ CV2 ‘ has no attribute ‘gapi_wip_gst_GStr 的解决方法。_羁旅少年的博客-CSDN博客
问题:File can't be opened for writing! in function 'cv::face::FaceRecognizer::write'
解决:需要提前手动在项目目录下创建好trainer文件夹
9.3 代码
import os
import CV2 as cv
from PIL import Image
import numpy as np
def getImageAndLabels(path):
#存储人脸数据
faceSamples = []
#存储姓名数据
ids=[]
#储存图片信息
imagePaths = [os.path.join(path,f) for f in os.listdir(path)]
#人脸检测分类器
face_detecter = cv.CascadeClassifier('G:/conda/envs/testOpencv/Lib/site-packages/ CV2 /data/haarcascade_frontalface_default.xml')
#遍历列表中的图片
for imagePath in imagePaths:
#打开图片,灰度化
PIL_img = Image.open(imagePath).convert('L')
#把图像转换为数组,
img_numpy = np.array(PIL_img,'uint8')
#获取图片人脸特征
faces = face_detecter.detectMultiScale(img_numpy)
#获取每张图片的id和姓名
id = int(os.path.split(imagePath)[1].split('.')[0])
#预防无面容照片
for x,y,w,h in faces:
ids.append(id)
faceSamples.append(img_numpy[y:y+h,x:x+w])
#打印脸部特征和id
print('id:',id)
print('fs:',faceSamples)
return faceSamples,ids
if __name__ == '__main__':
#图片路径
path = './data/jm/'
#获取图像数组和id标签数组
faces,ids = getImageAndLabels(path)
#加载识别器
recognizer = cv.face.LBPHFaceRecognizer_create()
#训练
recognizer.train(faces,np.array(ids))
#保存文件
recognizer.write('trainer/trainer.yml')
9.4 运行结果
trainer文件夹中产生了对应的trainer.yml文件。
十、人脸识别
十一、网络视频
需要更多的python项目 点赞+评论学习