


Stata小白系列之二:数据拆分与合并

作者:谢作翰 | 连玉君 | ( 知乎 | 简书 | 码云 )
连享会 - Stata 暑期班 :直播 (不必舟车劳顿了)
时间: 2020.7.28-8.7
主讲嘉宾 :连玉君 (中山大学) | 江艇 (中国人民大学)
课程主页 : https:// gitee.com/arlionn/PX | 微信版
http:// qr32.cn/FJvyx9 (二维码自动识别)
编者按: 从本期开始,Stata 连享会将推出「Stata小白系列」推文,介绍数据导入、命令语法等 Stata 入门知识,以帮助各位尽快掌握 Stata 的基本操作。
连享会 最新专题 直播

三 数据拆分与合并
- 数据拆分
-
数据横向拆分——
keep&drop -
数据纵向拆分——
keep&drop -
一步到位保存数据子集——
savesome
- 数据合并
-
数据的横向合并——
merge -
数据的纵向合并——
append -
对多个
csv文件纵向合并——csvconvert
四 长宽数据转换—— `reshape`命令
- 宽数据转为长数据
- 长数据转为宽数据
数据文件下载:链接: https:// pan.baidu.com/s/1qXRh9E G 密码: 5ltw
数据拆分
如果把内存中的数据集视为一个矩阵,则我们对数据的基本操作包括两类:删除
列
或删除
行
。对于 Stata 而言,命令的主要操作对象是变量 (矩阵的
列
),而有些时候我们也需要删除特定的观察值 (矩阵的
行
)。这些操作都可以配合使用
drop
和
keep
命令来实现。
删除\保留变量:数据的横向拆分
原始数据有时包含过多的变量,但在实际应用中可能根据需要将原始数据拆分为不同的数据表,这时就要实现数据的横向拆分。数据的横向拆分用到的两个命令为
drop
和
keep
。
Stata 范例:
sysuse "auto.dta", clear
drop weight length
save "d:\data\auto_sim01.dta", replace
我们调入数据后,使用
drop
命令删除了两个变量,进而把处理后的数据文件另存到
D:\data
文件夹中。若该文件夹下已经存在一个名称为
auto_sim01.dta
则自动覆盖之,这是
replace
选项的作用。
按照上述思路,也就不难理解如下命令的含义了:
sysuse "auto.dta", clear
keep make price mpg rep78 foreign
save "d:\data\auto_sim02.dta", replace
特别说明: 一般而言,除非数据文件非常大导致每次调入耗时较长,我们很少另存数据文件。我们会将主要的修改动作都保留于 dofile 中。每次分析时,只需修改 dofile 或执行 dofile 中的特定语句即可实现对子样本的处理。毕竟, dofile 本质上是文本文件,文件大小通常不过几十 k。
删除\保留观察值:数据的纵向拆分
原始数据有时包含过多的样本观测值,但在实际应用中可能根据需要将其按某种特征拆分为不同的数据表,这是就要实现数据的纵向拆分。此时,仍然可以使用
drop
和
keep
命令。
例如将
auto.dta
数据文件拆分为两个数据文件:
auto_domestic.dta
和
auto_foreign.dta
,操作如下:
sysuse "auto.dta", clear
keep if foreign==0
save auto_domestic.dta, replace
sysuse "auto.dta", clear
keep= if foreign==1
save auto_foreign.dta, replace
连享会 最新专题 直播
一步到位保存数据子集: `savesome` 命令
通过上述范例可以看出,使用 Stata 自带的
keep
和
drop
命令可以快捷地删除变量或观察值,但在命令写法上较为繁琐。我们可以使用外部命令
savesome
来提高效率 (该命令是 Stata 官方命令
save
的扩展版):
- 安装程序文件:
ssc install savesome, replace
在命令窗口中输入
help savesome
可以查看该命令的帮助文件,其语法格式如下:
savesome [varlist] [if exp] [in range] using filename [, old save_options]其中,
-
using filename表示要保存的子集文件名及文件路径; -
old是较为重要的选项,可以将数据保存为较低版本的文件格式,如 stata15 用户可以将数据另存为在 stata14 或以下版本中的打开的数据文件。类似的命令还有 Stata 官方命令saveold。
Stata 范例 1:
对于前文提到的例子,我们可以使用
savesome
来实现相同的功能:
sysuse "auto.dta", clear
keep make price mpg rep78 foreign
save "d:\data\auto_sim02.dta", replace等价于
sysuse "auto.dta", clear
savesome make price mpg rep78 foreign ///
using "d:\data\auto_sim02.dta", replace评论: 凭心而论,笔者更喜欢前一种方式。虽然多写了一行命令,但思路清晰,也便于记忆。
Stata 范例 2:
sysuse "auto.dta", clear
keep if foreign==0
save auto_domestic.dta, replace 等价于:
sysuse "auto.dta", clear
savesome if foreign==0 using auto_domestic.dta, replace 数据合并
数据的横向合并
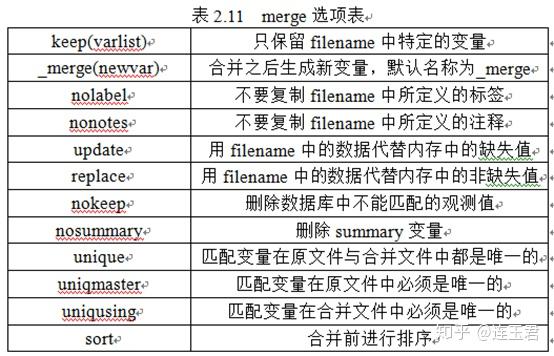
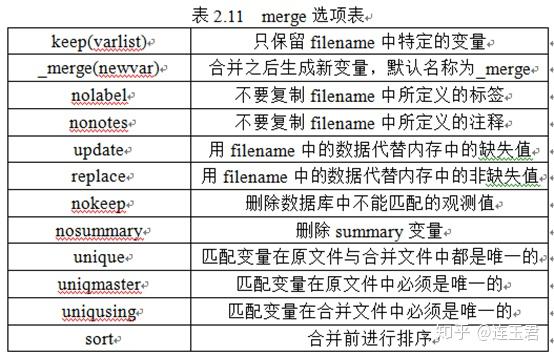
数据的横向合并是横向拆分的逆操作,但是其要比拆分复杂。对于时间序列资料而言,要保证同一时点的两个变量的观察值对接到同一行;而对于界面个体资料而言,要保证同一个人的年龄数据与该人的收入数据在同一行。而对于面板数据资料,则需数据中有两个变量能够唯一标示每一行观察值,以保证 A 数据文件中的 “张三疯-2016” 与 B 数据文件中的 “张三疯-2016” 处于同一行。合并所使用的命令语句为
merge
,具体语句如下所示:
merge [varlist] using filename [filename ...] [, options]
merge
为合并的命令语句,
[varlist]
代表合并进去的新变量,
using filename
指的是所要与原文件合并的文件路径,
options
包含较多的功能,表 2.11 显示了其具体内容。
举例
:利用横向拆分实验中生成的数据文件
waterinput
和
wateroutput
实现数据的横向合并,匹配变量为
year
,生成新的数据文件命名为
waternew
。这个操作的命令为:
use c:\data\wateroutput, clear
sort year
save c:\data\wateroutput, replace