


饥荒游戏扫雷笔记 系列全文合集

写在前面:由于知乎还不能把文章移动到专栏,因此做成一个合集重新发一下。
新写一篇文章,以纪念在制作和调试饥荒游戏LuaJIT桥接PATCH中探过的雷区。
本文大体已经更新完结,如有新的内容会及时补充。
关于饥荒游戏的介绍,直接看这个答案好了: 你怎样看待 Don't starve 这个游戏?
关于本插件的详细介绍,下载及源码请点击: DontStarveLuaJIT by paintdream
本文所用到的软件:OllyDBG 2.01、Microsoft Visual C++ 2008
-----------------------------------------我是分割线------------------------------------------------
0x00 神船搁浅
我要给饥荒写PATCH,并不是一个刚开始就计划好的事情。饥荒发布于Steam平台并且添加了创意工坊,里面有很多好的、差的、能用的、不能用的、原创的以及抄的Mods,大部分都维护得很好,开游戏时连存档带MOD设置都会被云同步更新,几乎可以是完美了。
然而唯一的美中不足似乎是:这游戏居然很吃配置。N年前买的神船竟然会在玩久了之后就会时不时顿卡,以至于到后来居然越来越卡了。虽然i7-3610QM+GT650M在现在看来也比较渣,但是至少跑跑dota2中配都还很流畅,也不至于在饥荒上惨成这样。
打开任务管理器瞄一眼,发现情况还是很有意思的。在卡顿的时候,CPU只有两个核心满载运行,其余都在打酱油——通过暂停-恢复的办法观察CPU占用率,可以得出结论,CPU0是负责渲染的线程,CPU6是负责脚本逻辑的线程。
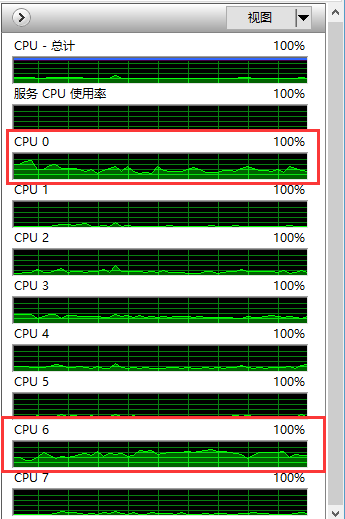
卡顿是来自于两方面的,一方面如果绘制的对象较多,机器就会明显开始变卡。这时CPU0的使用率会明显下降,说明有大量绘制指令阻塞了渲染管线,导致绘制线程长期处于等待渲染完成的阻塞状态。同时用户的输入反馈也会被明显阻滞,推测读取用户输入的相关代码也是在这个线程中执行的(饥荒使用了DirectInput来读取键盘操作)。饥荒本身这种哥特式的画风,使用一些预制的纹理搞搞Billboard贴图就可以做出伪2D的画面效果了,渲染本身压力应该不算大。但是考虑到ES版本低的限制用不了Instanced Draw,很可能是每个对象都对应一个draw call,并且每个对象绘制时都重复提交了大量数据,导致带宽用尽。不过这方面我现在还没有做仔细的研究,仅仅是猜测而已。
另一方面如果脚本的逻辑过于复杂,也会明显变卡。这时CPU6将会被占满,而由于逻辑帧与渲染帧同步的关系,CPU0的占用率会变低。这方面的问题相对来说比较严重,因为为了好玩大家都会加载很多MODs,Shipwrecked DLC新增加的游戏特性也非常吃CPU,导致大家在玩这个DLC时感受到的卡顿远远比原版或者Reign of Giants DLC时要明显得多。因此在很多论坛上大家解决这个卡顿的办法只有——别开那么多MOD,换个好点的电脑。
本文尝试解决的是脚本逻辑引起的卡顿。
0x01 积重难返
好消息是饥荒使用了我比较熟悉的lua 5.1.4作为脚本引擎(但是实际上我更希望看到的是lua 5.3),并且随游戏附送了所有的lua脚本(大约18万行,不算DLC),所有的逻辑都是在脚本中实现的。
研究了几个小时后发现,作者似乎仅仅是把它当作一个工具来用,没有专门在lua特性上下功夫。为了写起来更方便和熟悉,当需要异步操作时,大部分的需求都是通过C层面支持的时钟回调(往往配合全局任务队列)来完成的。这个设计也给我造成了麻烦,因为它会使原本完整的逻辑从中断开,调试时打印调用堆栈就只能看到当前事件触发后的逻辑。
那么,为什么不用coroutine呢?我搜了下源码,有三个地方对coroutine进行了封装,其中两个是有关网络的第三方库,主要负责发邮件之类的工作 ,和游戏逻辑没什么关系。唯一用到的就是调度器添加任务的时候,为每一个新任务创建一个coroutine,然后调度的时候枚举所有任务一个个执行。
然而,这个coroutine似乎仅仅是由来保存一个独立执行栈的——调度器对它的操作仅仅是从队列中取出然后执行完删掉。全部代码中只有9个很少执行到的地方用到了Yield()。个人觉得这个coroutine的用法值得商榷——毕竟coroutine本身还是有一点点开销的,而且绝大多数异步需求还是用回调来完成的。
从lua代码架构上看,这套脚本自己实现了一个简单的类似C++的面向对象框架,模块的封装比较任性,耦合度也有点高,经常会出现在底层框架代码中去加一些代码来控制上层实现逻辑的代码。而它发布的两个DLC并不是在原有代码框架上开发的扩展包,而是直接把代码复制出来进行修改的,估计最初写的时候也没想要有个DLC……
可以看出,游戏本身应该是直接从一个简单的原型一步步迭代上来的,虽然在开发的过程中有过抽象和封装,但是积重难返,大体的结构已经固定,没有什么简单的优化空间了。脚本负责了太重的任务,并行方面做的工作也不多,试图直接优化现有代码对于我来说已经成了死局。
因此把lua引擎替换为LuaJIT已经成了为数不多的可以让程序运行起来不那么卡的选择了。虽然从道理上讲,这也只能算是治标不治本,但是好歹能有的玩啊。
0x02 横生枝节
但是事情远远没有想的那么简单。我最初以为直接把饥荒可能用到的lua51.dll换成luajit.dll就万事大吉了,然而翻遍了安装目录也没看到lua51.dll库的影子。那么次一点的结果就是LUA被封装在了别的DLL里,由dontstarve_steam.exe启动时加载。然而最终发现lua引擎是直接作为静态库或者源码编译进主程序的,这是最糟糕的结果。
这个麻烦在于,我们知道exe通常不需要导出函数(仔细看了下dontstarve_steam.exe确实没导出),那么如何定位lua api在exe中的位置就成了首要解决的问题。
EXE中lua api的布局和DLL中是完全不一样的:编译器可以剪掉那些没被引用到的函数与常量,也可以重排函数的顺序。想要通过公开的或者凑巧的办法定位到这些函数是不可能的。那么就剩下了三条路:直接改EXE,硬编码与特征码搜索。
直接改EXE或者硬编码相应函数的RVA看起来简单粗暴,但是万一饥荒EXE更新了就得新发布个版本,而且为了得到地址还得手工用特征码先搜索并较正一遍。想了想还是用特征码吧,而且还要尽量做成非侵入式的,这样就可以有效地兼容饥荒自己的更新。
0x03 探针计划
特征码搜索需要先找到每个函数对应的特征码。为此我的思路是,先编译一份原汁原味的lua 5.1.4的DLL,把LUA API设置为导出,这样就能得到每个API的地址,进而用函数开头的二进制指令作为特征码在EXE中进行搜索。接下来,只需要把搜索到的源地址和名字一一对应起来,然后加载luajit.dll就可以再通过kernel32.dll!GetProcAddress拿到目标地址,通过inline hook将源地址处的执行流导向目标地址。由于这些hooks不需要执行原函数,计算跳板所保留的原函数头部字节数也就没有必要了。
不同的编译器生成目标代码时的算法都是很不一样的,甚至就算是同一系列的编译器,随着版本更新也会有不同。那么应该用什么来编译原版lua DLL呢?当然是与饥荒主程序保持一致。OllyDBG告诉我们答案:MSVC9,即Microsoft Visual C++ 2008。
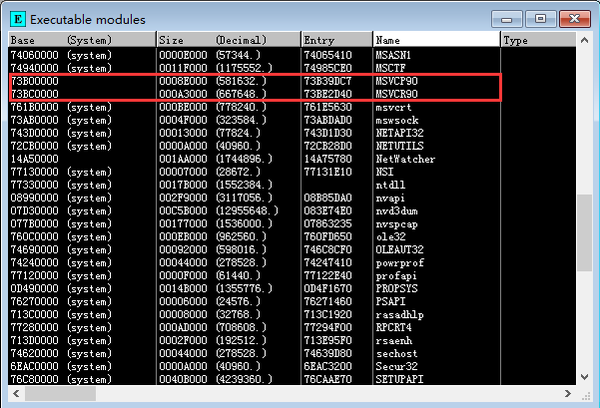
然而在开始编码之前,先要解决的问题是:怎么让我的代码得到执行?
很明显如果想要做非侵入式的Patch,要么额外写一个启动器,要么通过某种技巧让我们的代码在游戏启动时得到执行。官方的MOD机制允许自定义mod在游戏初始化的时候执行lua代码,然而这时候lua引擎已经建立,再替换就晚了,肯定不行。
于是我的目光移动到exe依赖的那些DLL上,看看有什么偷梁换柱的策略。所谓的偷梁换柱就是指,针对目标EXE所依赖的DLL,写一个傀儡DLL,名字和导出函数都和目标DLL一样,然后放在EXE目录中就可以在EXE启动时被加载。加载后再手动用kernel32.dllLoadLibraryA/W加载目标DLL,并把导出的函数都转接到目标DLL中对应的函数里去。早些年一些病毒为了禁用杀毒软件,就在杀毒软件安装目录下放一个假的ws2_32.dll,这样杀毒软件启动时就会崩溃或者被劫持。注意一些系统核心的DLL是不受这个影响的,如kernel32.dll, ntdll.dll等)
饥荒主程序目录下那些DLL大多都是C++写的,导出函数的名字都是经过name decoration的,处理起来会比较麻烦。加之导出函数的数量也很多,有点不划算。
找了半天,最佳的选择是DINPUT8.DLL,这个DLL是DirectInput所需要的。选择它的原因是dontstarve_steam.exe只从其中导入了一个函数DirectInput8Create,用来创建DirectInput的设备对象,由于这个对象是用COM封装的,所以DLL不再需要导出其成员函数,导入表项因此就简洁了很多。还有一个好处,由于它是处于系统目录中的DLL,替换它不需要替换原有的DLL,只需要在EXE目录中放置即可被加载,是完美的非侵入式PATCH的选择。
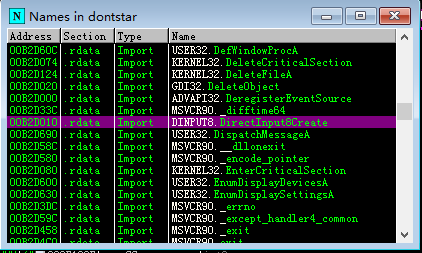
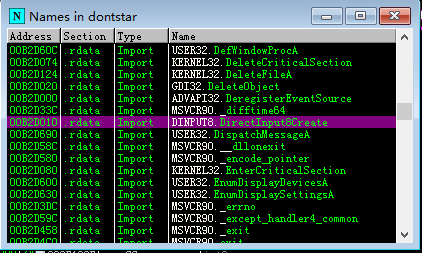
如前文所述,你接管了DINPUT8.DLL,那么也就得实现DirectInput8Create这个函数,否则游戏启动时会找不到入口。这个很容易:
typedef HRESULT(WINAPI *PFNDirectInput8Create)(HINSTANCE hinst, DWORD dwVersion, REFIID riidltf, LPVOID *ppvOut, LPUNKNOWN punkOuter);
static PFNDirectInput8Create pfnDirectInput8Create = NULL;
HRESULT WINAPI DirectInput8Create(HINSTANCE hinst, DWORD dwVersion, REFIID riidltf, LPVOID *ppvOut, LPUNKNOWN punkOuter) {
return pfnDirectInput8Create(hinst, dwVersion, riidltf, ppvOut, punkOuter);
DllMain:
TCHAR systemPath[MAX_PATH];
::GetSystemDirectory(systemPath, MAX_PATH);
HMODULE hInput = ::LoadLibrary(CString(systemPath) + _T("\\DINPUT8.DLL"));
if (hInput != NULL) {
pfnDirectInput8Create = (PFNDirectInput8Create)::GetProcAddress(hInput, "DirectInput8Create");
在上面的代码里,DllMain里需要加载真正的DINPUT8.DLL,然后获取到DirectInput8Create的地址,然后才能在中继代码中CALL。需要注意的是,我们最好不要包含任何有关DirectX SDK的头文件,这些头文件往往会指定API为导入,而我们需要将同名的中继函数导出。
如果遇到了类型没定义的错误也不用急,按照其长度写一个等价的就行了。后文我会介绍一个更简单的制作中继函数跳板的办法。
那么,接下来是怎么搜的问题。我们先来编译原版lua51.dll,编译设置选择Release版本。
如果在用kernel32.dll!LoadLibraryA/W加载了原版的lua51.dll之后,直接拿API函数开始的二进制码去做搜索,只能搜索到一小部分函数。这是由于DLL中的代码需要根据.reloc节的信息进行重定位,需要定位的地方二进制值会变,因此纯粹的memcmp行不通。
在这里我直接采用了一个较简单但是相对耗时的策略:在搜索时利用反汇编引擎XDE32一条条解析指令格式,发现需要重定位的指令,就读取地址处的值代替地址本身充当特征码。
while (target < entry.instr + INSTR_SIZE) {
xde_disasm((BYTE*)c, &instr);
int len = instr.len;
if (len == 0)
break;
if (instr.opcode == 0x68 || instr.addrsize == 4) {
// read memory data
PVOID addr = instr.opcode == 0x68 ? *(PVOID*)(c + 1) : (PVOID)instr.addr_l[0];
char buf[16];
memset(buf, 0, sizeof(buf));
if (addr != NULL && ::ReadProcessMemory(::GetCurrentProcess(), addr, buf, 4, NULL)) {
entry.stringList.push_back(std::make_pair(addr, std::string(buf)));
BYTE temp[16];
if (instr.opcode == 0x68) {
memcpy(temp, c, instr.len);
*(PVOID*)(temp + 1) = *(PVOID*)buf;
} else {
instr.addr_l[0] = *(long*)buf;
xde_asm(temp, &instr);
memcpy(target, temp, len + target > entry.instr + INSTR_SIZE ? entry.instr + INSTR_SIZE - target : len);
} else {
memcpy(target, c, len + target > entry.instr + INSTR_SIZE ? entry.instr + INSTR_SIZE - target : len);
c += len;
target += len;
if (!edge)
validLength += len + target > entry.instr + INSTR_SIZE ? entry.instr + INSTR_SIZE - target : len;
entry.lengthHist[len]++;
if (*c == 0xCC) {
edge = true;
具体到匹配算法,为了避免因微小长度差异而导致整体错位,我没有直接memcmp,而是用了最长公共子串的动态规划算法,时间和空间复杂度都为O(N * N)。对于不太长的特征序列,性能上的损失可以接受。
static int CommonLength(const BYTE* x, int xlen, const BYTE* y, int ylen) {
int opt[INSTR_SIZE + 1][INSTR_SIZE + 1];
memset(opt, 0, sizeof(opt));
for (int i = 1; i <= xlen; i++) {
for (int j = 1; j <= ylen; j++) {
if (x[i - 1] == y[j - 1])
opt[i][j] = opt[i - 1][j - 1] + 1;
opt[i][j] = opt[i - 1][j] > opt[i][j - 1] ? opt[i - 1][j] : opt[i][j - 1];
return opt[xlen][ylen];
搜索的范围只需要设置为dontstarve_steam.exe的.text节所在范围即可,其实我在试了几个版本之后,发现.text + 0x170000之后才会有对应的lua api的函数。因此为了速度快些就直接以.text + 0x170000为地点,.text的末尾为终点了。(当然其实这么做有一定风险,不过一直懒得改。。万一哪天饥荒有大更新很可能会出错)
搜索到目标函数之后,标记下来,并与luajit连接即可。下面是inline hook的代码:
static void Hook(BYTE* from, BYTE* to) {
// prepare inline hook
unsigned char code[5] = { 0xe9, 0x00, 0x00, 0x00, 0x00 };
*(DWORD*)(code + 1) = (DWORD)to - (DWORD)from - 5;
DWORD oldProtect;
::VirtualProtect(from, 5, PAGE_READWRITE, &oldProtect);
::memcpy(from, code, 5);
::VirtualProtect(from, 5, oldProtect, &oldProtect);
(个人比较喜欢0xE8/0xE9这种HOOK,不需要改寄存器,长度也很短。当然也可以用PUSH+RET, FF 15/25 即CALL/JMP DWORD PTR [ADDR]的,各有所需)
0x04 引火烧身
写完代码,编译好DLL,并将其改名为DINPUT8.DLL。同时再编译一份luajit的DLL,重命名为luajit.dll(原来的名字是lua51.dll),再加上直接用VS2008编译lua 5.1.4源码得到的lua51.dll,总共是三个文件。
将这三个文件复制到饥荒的bin目录,启动游戏。(见证奇迹的时候到了!!)
不出意外,BOOM!程序崩溃了!!
客位看官不好意思,前面洋洋洒洒写了一大堆,看起来有极大可能并没有什么用。

不过仔细想想,这也不总是悲剧,至少证明了我们还是具有了利用DINPUT8傀儡来捅篓子的能力。
但是为什么会崩溃呢?总得有个交待啊!!通过仔细的排查(其实就是打了个LOG),发现其实有部分函数就没Hook上。
但是为什么没Hook上呢?前面搜索花了那么大的精力,为什么结果还是不对呢?
0x05 调试器下没有秘密
没办法,只能用OllyDBG调试下试试了。由于饥荒的exe你直接点击是不会启动游戏的,它只会启动STEAM,然后用STEAM再启动游戏,所以我只能在DINPUT8.DLL的DllMain里,强行加一个getchar(),然后在STEAM中启动游戏,使用OllyDBG附加调试。
按ALT+E打开模块列表,点击dontstarve_steam.exe,启动Search for => All inter-modular calls,就可以看到大多数函数已经被成功HOOK了。
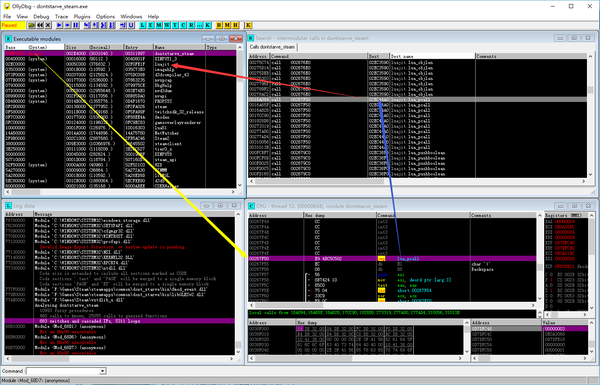
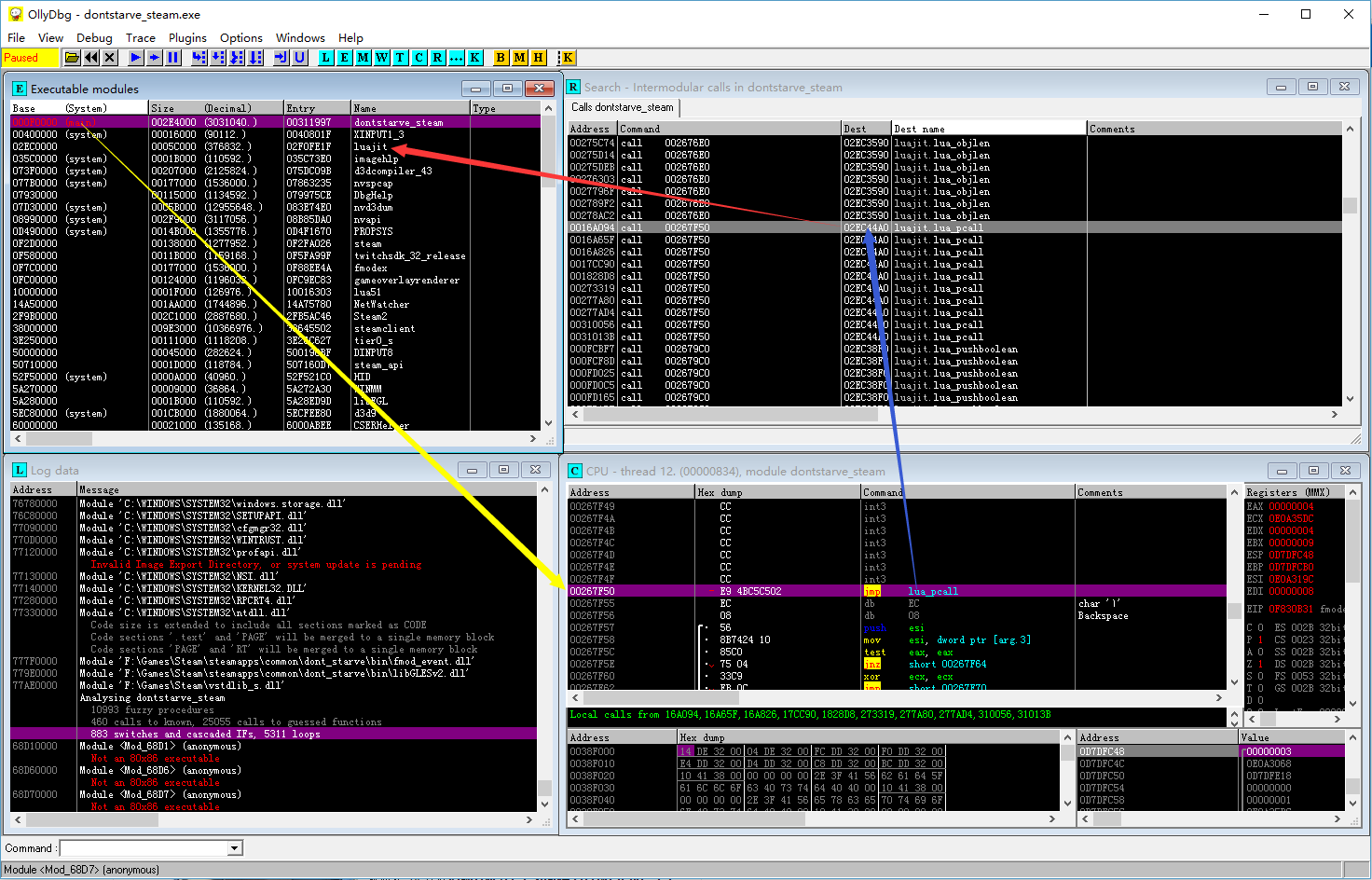
一个个检查HOOK的函数,发现只要是搜索到了目标,基本上就没有什么大问题。问题在于很多函数就没找到,而且吊诡的是,自己手工去用OD强大的Search Command功能去搜,放宽搜索的匹配条件,也是找不到的。

所以……
难道是……
那些函数压根就不存在……吗?

好吧。这个结论竟然对了一半。
确实有些api在exe中是没有的,因为exe没用到它们,编译器在连接的时候把它们抹掉了。我于是在lua51.dll中删除了它们的导出项。
另一部分呢,确实是没搜索到。通过查找字符串引用逐步定位相关指令的办法(具体就不详述了),我发现了一件怪事:
这些API和lua 5.1.4 DLL中的api在二进制层面上差别非常大!
0x06 飞轮与链条
如果饥荒的作者修改过这些函数的实现,那么情况就非常僵了——我得在luajit中做等价的修改。不过仔细比对后发现,事情没有那么糟糕。
不一致的地方主要来自于两种原因:
1. 部分API调用内部函数被inline
2. 饥荒作者删除了部分API中关于luaC_checkGC调用
对于1,参考下图:
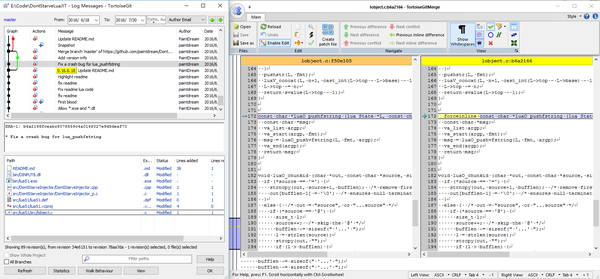
luaO_pushfstring是lua_pushfstring所调用的函数,在饥荒主程序里这个调用是被inline的,导致其与我编译的lua51.dll中lua_pushfstring的二进制码不一致。
对于2,参考下图:
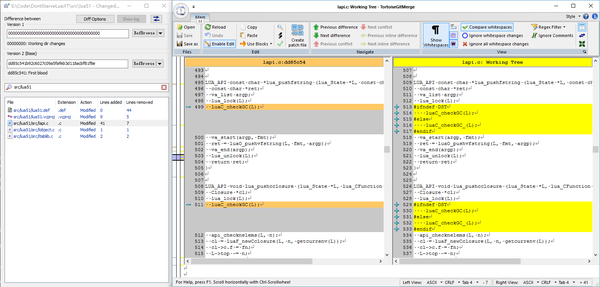
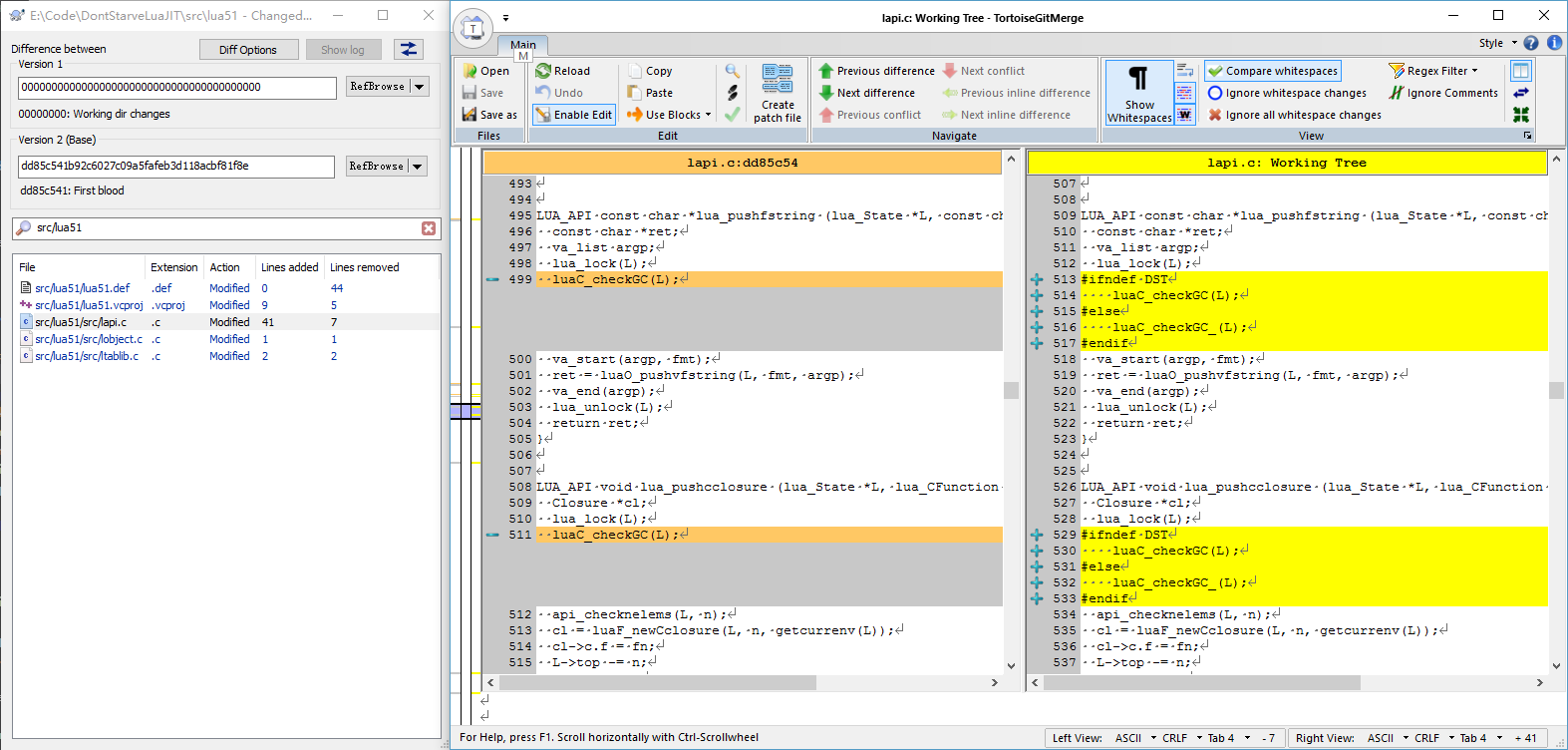
饥荒作者删除了代码中的一些luaC_checkGC的调用,从而使得一些函数不再会触发垃圾收集。这种想法是为了避免某些BUG吗?(比如C层面持有的对象因没有维持引用而失效)还是试图降低卡顿?我不得而知。但是奇怪的是,联机版的饥荒(针对联机版的内容主要参见后文)改动的地点和单机版并不一致。(上图中我添加的luaC_checkGC_是一个空宏,等价于把GC调用删除掉)
经过如上的修改之后重新编译lua51.dll,我们重新制作的链条终于能和饥荒原程序的飞轮啮合在一起了。
0x07 打包炸弹
启动时崩溃,按照OllyDBG的LOG跟踪到是luajit有部分常数的值太小(如函数串最多常量个数,参数列表最多参数个数),改成大一些的值即可,不在此详述了。(饥荒真是内存杀手)
折腾了半天,我们的破补丁总算能勉强跑起来了。顺利度过loading界面,主界面成功启动!久违的背景音乐响起~


先随便试试基本的功能吧,先点下MODS看看会不会挂……
由墨菲定律可知:如果一个地方你感觉会出错,那么它就会出错。。于是有插件崩溃了。

虽然在游戏中按“`”键也可以打开内置的控制台,但是这里LOG显示的行数有限,且不能滚屏。于是直接打开OllyDBG的LOG看看倒底发生了什么:

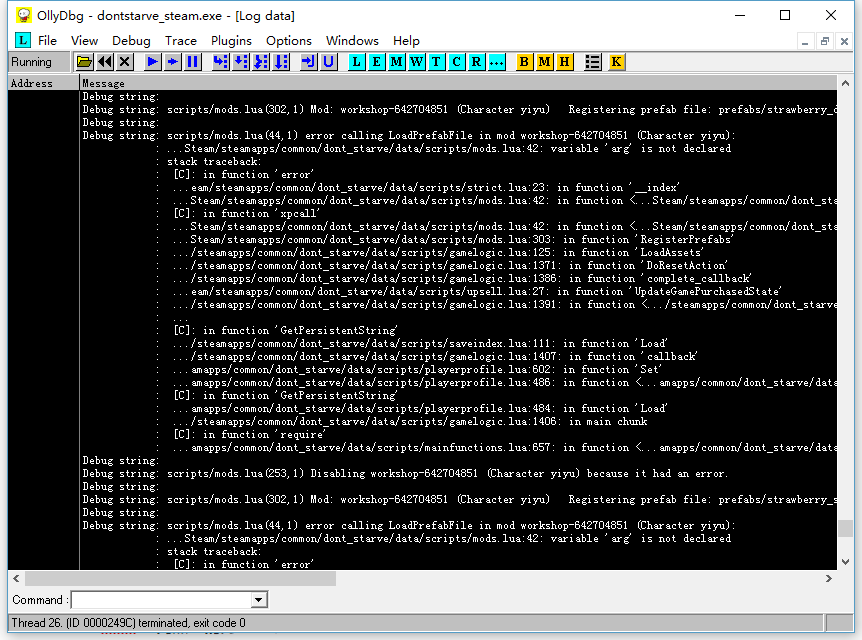
(这些LOG是用OutputDebugString输出的,需要OllyDBG 2.0以上版本才支持在调试器内显示它们。)
从上面的文字中可以看出,在加载翼语MOD的时候,mods.lua第42行报错,提示'arg'这个变量没有被定义。
那么就去看看喽:
local runmodfn = function(fn,mod,modtype)
return (function(...)
if fn then
local status, r = xpcall( function() return fn(unpack(arg)) end, debug.traceback) --<< 42
if not status then
print("error calling "..modtype.." in mod "..ModInfoname(mod.modname)..": \n"..r)
ModManager:RemoveBadMod(mod.modname,r)
ModManager:DisplayBadMods()
return r
end)
问题很明显,饥荒作者使用了旧的表示可变参数表的语法。在5.1以前,你可以使用arg来表示{...}这个表,arg[i]即可用于提取可变参数中的第i项。但是后来这个语法就被默认弃用掉了,仅保留一个宏可以开启这个兼容。LuaJIT则完全不兼容这个写法,通过仔细查看代码,它甚至删除了实现arg兼容所占用的mask bit而将这个bit用在了其他地方。
当时分析到这的时候,我觉得直接要求用户修改这个文件也不是什么难事,毕竟添加如下一行就可以解决问题:
local arg = {...}
于是我写好了详细的说明,将程序及源码发布在了Github上,并且在贴吧开了贴收集用户反馈。
0x08 冒烟的补丁
第一波的反馈喜忧参半,可喜的是有部分用户能成功安装补丁,并且说确实有明显的效果,特别是针对Shipwrecked DLC加上大量Mods,忧的是仍然有大量不能正确启动的bug,报错也是千奇百怪,甚至有大量连游戏本身启动什么也没看到就闪退的问题。
对我冲击比较大的是,修改源代码文件这个要求对于普通用户来说实在是太难了。很多用户找不到文件,不知道用什么工具打开,看不懂英文因而无从下手,打了中文标点也浑然不知。而且很多第三方MOD里也用了这个旧的arg语法,要想举一反三,从我给出的修改mods.lua的方案直接得出修正第三方mod中相应语法问题的玩家非常少——毕竟贴吧以娱乐为主,不像知乎会有很多程序员。这很难办。
怎么办呢,只能自己把这个兼容性补丁做了。
在研究了一下午luajit parser之后,我放弃了按照lua源码中相同的设计添加兼容的思路。一方面如上所述,没有可用的mask bit,想要跑起来需要增加对应FLAG变量的位宽;另一方面lua源码中这个功能是在VM中解释时实现的,而luajit没有解释器,它直接跑的是原生指令。而想看明白JIT COMPILER的实现机制并且从中精准地插入这个功能并非易事。
不过又看了一下午parser之后,发现其实还有一个简单的办法。那就是在检测到当前编译的函数是可变参数的时候,动态插入一句local arg = {...}。这样的话有两种做法:
1、检测源文件文本,作一个简单的处理,定位到函数定义的地方,然后插入一行。
2、直接在AST生成的时候插入语法结点。
方法1的难度是比较低的,但是也需要稍微作一点解析工作,比如把注释,字符串跳过,检测函数定义的语句之类的。比较容易想不周全而出错。
要想想周全,就得搞个简单的parser。直接按方法2借用luajit自己的parser是最好的选择。为了使探索更有目的,我编写了这样的一个函数:
function test(...) local arg = { ... } end然后跑起luajit来看看local arg = { ... }这句话究竟都会走哪些路径来生成AST。调试了一个小时之后,终于搞出来了。
打开lj_parse.c,定位到:
static void parse_chunk(LexState *ls)
int islast = 0;
synlevel_begin(ls);
add_argstmt(ls); // HERE!!!!!
while (!islast && !parse_isend(ls->tok)) {
islast = parse_stmt(ls);
lex_opt(ls, ';');
lua_assert(ls->fs->framesize >= ls->fs->freereg &&
ls->fs->freereg >= ls->fs->nactvar);
ls->fs->freereg = ls->fs->nactvar; /* Free registers after each stmt. */
synlevel_end(ls);
在标记处加一行调用add_argstmt的语句,然后编写这个函数:
static void add_argstmt(LexState* ls)
ExpDesc e;
if (ls->fs->flags & PROTO_VARARG) {
var_new_lit(ls, 0, "arg");
// nexps = expr_list(ls, &e);
synlevel_begin(ls);
// expr_unop(ls, &e);
// expr_simple(ls, v);
// expr_table(ls, v);
ExpDesc key, val;
FuncState *fs = ls->fs;
BCLine line = ls->linenumber;
BCInsLine *ilp;
BCIns *ip;
ExpDesc en;
BCReg base;
GCtab *t = NULL;
int vcall = 0, needarr = 0, fixt = 0;
uint32_t narr = 1; /* First array index. */
uint32_t nhash = 0; /* Number of hash entries. */
BCReg freg = fs->freereg;
BCPos pc = bcemit_AD(fs, BC_TNEW, freg, 0);
expr_init(&e, VNONRELOC, freg);
bcreg_reserve(fs, 1);
freg++;
vcall = 0;
expr_init(&key, VKNUM, 0);
setintV(&key.u.nval, (int)narr);
narr++;
needarr = vcall = 1;
// expr(ls, &val);
checkcond(ls, fs->flags & PROTO_VARARG, LJ_ERR_XDOTS);
bcreg_reserve(fs, 1);
base = fs->freereg-1;
expr_init(&val, VCALL, bcemit_ABC(fs, BC_VARG, base, 2, fs->numparams));
val.u.s.aux = base;
if (expr_isk(&key)) expr_index(fs, &e, &key);
bcemit_store(fs, &e, &val);
fs->freereg = freg;
ilp = &fs->bcbase[fs->pc-1];
expr_init(&en, VKNUM, 0);
en.u.nval.u32.lo = narr-1;
en.u.nval.u32.hi = 0x43300000; /* Biased integer to avoid denormals. */
if (narr > 256) { fs->pc--; ilp--; }
ilp->ins = BCINS_AD(BC_TSETM, freg, const_num(fs, &en));
setbc_b(&ilp[-1].ins, 0);
e.k = VNONRELOC; /* May have been changed by expr_index. */
ip = &fs->bcbase[pc].ins;
if (!needarr) narr = 0;
else if (narr < 3) narr = 3;
else if (narr > 0x7ff) narr = 0x7ff;
setbc_d(ip, narr|(hsize2hbits(nhash)<<11));
synlevel_end(ls);
assign_adjust(ls, 1, 1, &e);
var_add(ls, 1);
上面的代码是按粗略的执行路径搞出来的,可能有些判断不会触发,还可以更简短些。不过影响不大就不深究了。
重新编译luajit,这次启动成功,MOD也能启用了。
这里说个好玩的,其实饥荒代码中这样不经声明直接用arg的地方还真不多。大部分都是直接用了...来传递,少部分呢,其实是这样的(为了提取指定参数,很明显他不知道有select这个函数可以用):(modutil.lua)
env.AddLevel = function(...)
arg = {...}
initprint("AddLevel", arg[1], arg[2].id)
require("map/levels")
AddLevel(...)
env.AddTask = function(...)
arg = {...}
initprint("AddTask", arg[1])
require("map/tasks")
AddTask(...)
env.AddRoom = function(...)
arg = {...}
initprint("AddRoom", arg[1])
require("map/rooms")
AddRoom(...)
end(然后这句arg = { ... } 实际声明/修改了个全局变量arg。)
那为什么mods.lua中不用...来传递呢?原因很可能是,...不能穿过闭包的边界(即调用xpcall时的作为参数的匿名函数)成为upvalue,只有兼容版本的arg可以。开发者没办法只能用了arg,但是忘记声明local arg = { ... }了。
接下来由于兼容模式是开着的,这个小问题不会引起执行异常,所以这样的代码也就保留下来了。(我乱猜的)
0x09 请写规范字
接下来来看玩家反馈的崩溃问题,发现很多都似乎是字符串上的乱子,有的案例会出现饥荒自带的崩溃界面,有的则直接闪退。
有崩溃界面长这个样子:
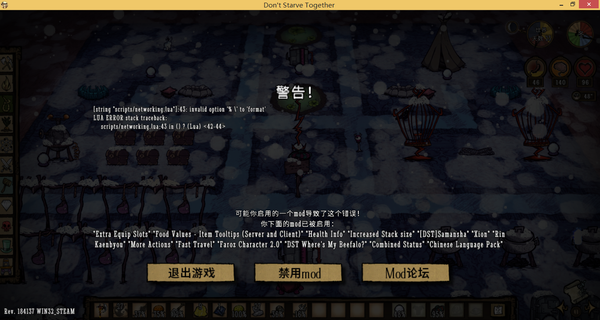
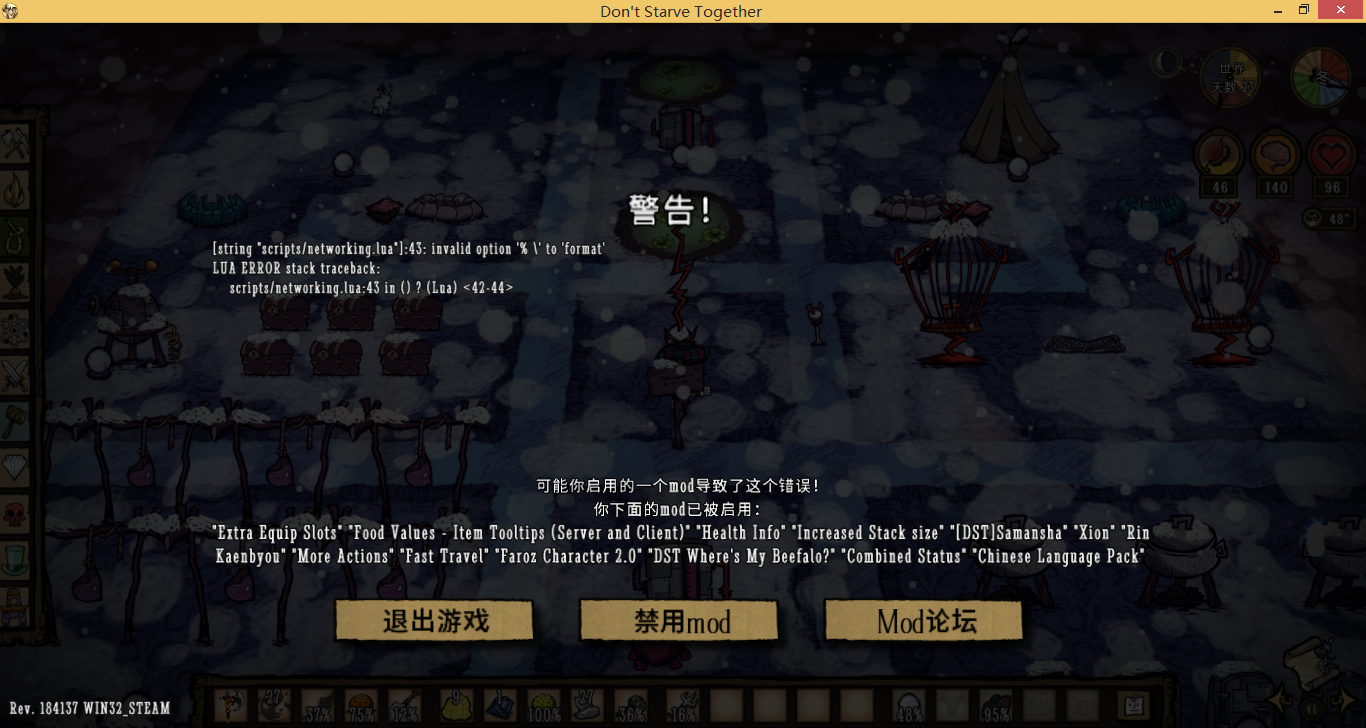
虽然上面显示是在原版的饥荒脚本里出的错,但是实际上,引发出错的是一个旧版的汉化包。它汉化后的字符串是这样的:
#: STRINGS.MODS.VERSIONING.OUT_OF_DATE
msgid "Mod \"%s\" is out of date. The server needs to get the latest version from the Steam Workshop so other users can join."
msgstr "Mod\“% \”有更新,服务器需要从创意工坊获得最新版本,以便其他用户加入。"
虽然lua中字符串的转义符方案和C的基本一致,但是MODs以及汉化的作者往往没有C语言相关的经验,所以容易写错。上面代码中不应该转义的中文引号被加了反斜杠,同时格式占位符的%s中的s也忘记写了。
还有一些MOD中大量用单个反斜杠来表示反斜杠本身而并没有适当的转义。但是原版的lua 5.1.4 编译器会忽略这个错误。从lua官方的文档上来看,并没有规定如果用户提供了不合语法的反斜框组合后具体的行为是什么。
于是LuaJIT就僵掉了:本来是出于严谨的考虑,LuaJIT不允许不合语法的反斜杠,否则就报错。而这个报错正好就挂出了错误界面。
更要命的是,mod中并不是所有的代码都是在正确的Sandbox保护下执行的(后文中会提到一例)。作为数据文件的lua格式的info文件本来就是简单的一个lua表,没什么函数。但是如果其中含有这样的字符串,执行时就会直接挂掉。这时程序内置的错误界面不会弹出而是会闪退。
这算是比较严重的设计问题。甚至,它不需要有问题的mod被激活(因为出问题的代码在info信息里,加载mod cache时就会挂)。由于mod本身的更新是在游戏内部中通过同步steam创创意工坊来完成的,一但mod出这种错误,根本没有机会通过在创意工坊中取消该MOD的订阅来解决问题,只能手工去删除mod的文件。这对普通用户来说是个严峻的挑战。
然而如果我给测试用户们解释这么多原因内容可能并不会有什么用。因为玩家会这样想:本来跑得好好的,用了你的补丁就闪退!一定是你搞坏了!
确实,别人不了解原理,你讲这些话其实与甩锅是等价的。
没办法,再重的锅也得背。改代码来兼容这个问题吧。。。打开lj_cparse.c:244
if (lj_char_isdigit(c)) {
c -= '0';
if (lj_char_isdigit(cp_get(cp))) {
c = c*8 + (cp->c - '0');
} else {
c = '\\';
cp_save(cp, (c & 0xff));
continue;
}只能强行兼容不合法的单个斜杠了。
同时,如果%后面没有合法的格式标记,LuaJIT也会报错。没办法,改成默认%s好了。
打开lj_strfmt.c:70
/* Parse conversion. */
c = (uint32_t)*p - 'A';
if (LJ_LIKELY(c <= (uint32_t)('x' - 'A'))) {
uint32_t sx = strfmt_map[c];
if (sx) {
fs->p = p+1;
return (sf | sx | ((c & 0x20) ? 0 : STRFMT_F_UPPER));
c = 's'-'A'; // 这里的写法突出了我懒的本质。
uint32_t sx = strfmt_map[c];
if (sx) {
fs->p = p+1;
return (sf | sx | ((c & 0x20) ? 0 : STRFMT_F_UPPER));
都已经妥协成这样了!还有问题吗!!
0x0A 冇问题吗
然而事情的诡异程度远远超出了我的想象。。在解决了这个问题很久很久之后,我发现有又mod因为字符串崩了。
崩的原因是它使用了LuaJIT的扩展转义符\u。这个符号在LuaJIT中是由于支持直接UNICODE内码的。然而这个MOD作者的本意是\umbrella之类……
很好,是在下输了。TAT
这次我直接把LuaJIT和原版不一样的转义符扩展整个给砍了。定位到lj_lex.c:216
#if 0
case 'x': /* Hexadecimal escape '\xXX'. */
c = (lex_next(ls) & 15u) << 4;
if (!lj_char_isdigit(ls->c)) {
if (!lj_char_isxdigit(ls->c)) goto err_xesc;
c += 9 << 4;
break;
case 'z': /* Skip whitespace. */
lex_next(ls);
while (lj_char_isspace(ls->c))
if (lex_iseol(ls)) lex_newline(ls); else lex_next(ls);
continue;
#endif
心好累。
0x0B 未雨绸缪的失火
再次发布了新版本之后,大家表示比较满意。只有一些上古版本(至少一年前的)的用户表示游戏启动不了。出于对正版的支持,我就不处理这部分要求了。(正版的游戏是随着steam更新的,除非用户故意取消掉是会一直保持最新的。)
于是我考虑制作饥荒联机版的MOD。联机版饥荒基于Reign of Giants DLC制作,但是是独立发布的,内容上针对多人游戏体验有不少改动。如前文所述,联机版饥荒主程序中嵌入的lua引擎的代码和单机版有一点点的不同(主要是GC调用的地方)。我使用预编译宏DST来区分两个版本,并将生成的lua DLL命名为lua51DST.dll。
万事妥当。把生成的文件复制到联机版安装目录的bin子目录里。运行游戏。
然后就(日常)崩了。
直接闪退,连个界面都没给我剩下。没法子,再次请出OllyDBG加载游戏,看看有什么新的幺蛾子:
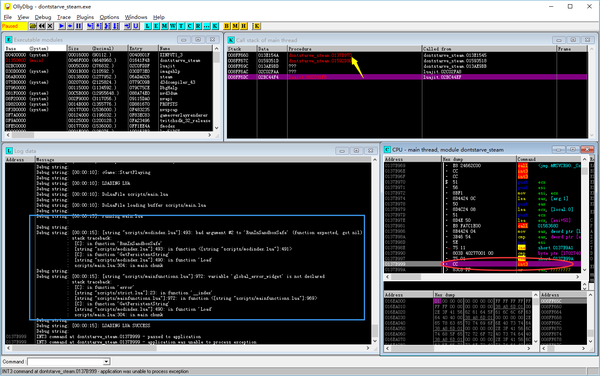
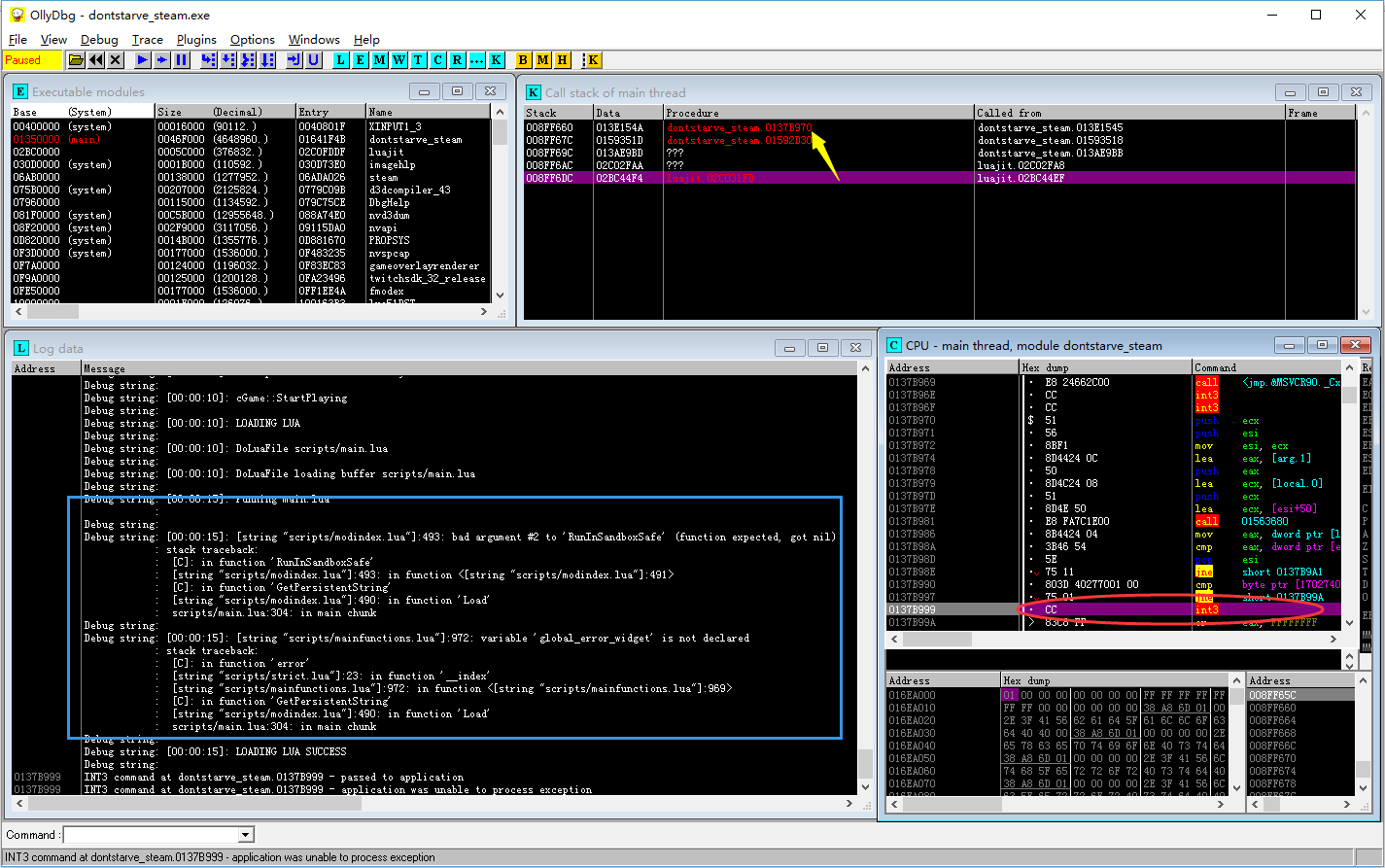
从右下角的圈出的地方可以看到程序是停在了开发人员设置的一个Release中仍然启用的Assert宏上。
右上角的调用堆栈指出这是在luajit回调原程序相关函数时出现的错误。
再看左下角的LOG窗口,提示的信息显示RunInSandboxSafe的第二个参数没有提供正确的值。这在lua中有两种可能,一是提供的参数的值确实是nil空值,另一种可能是调用时没有提供足够的参数。
然后我就搜了下代码中调用RunInSandboxSafe的地方:
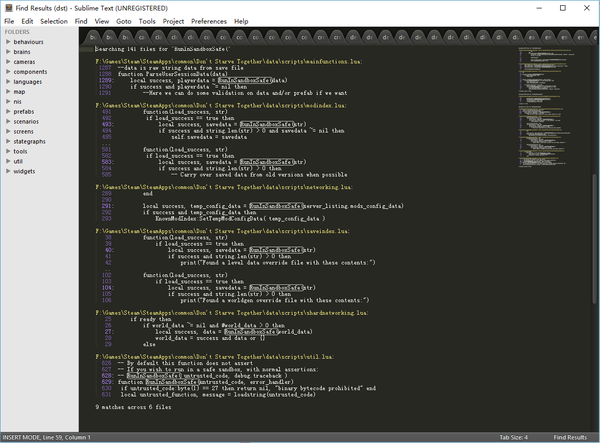
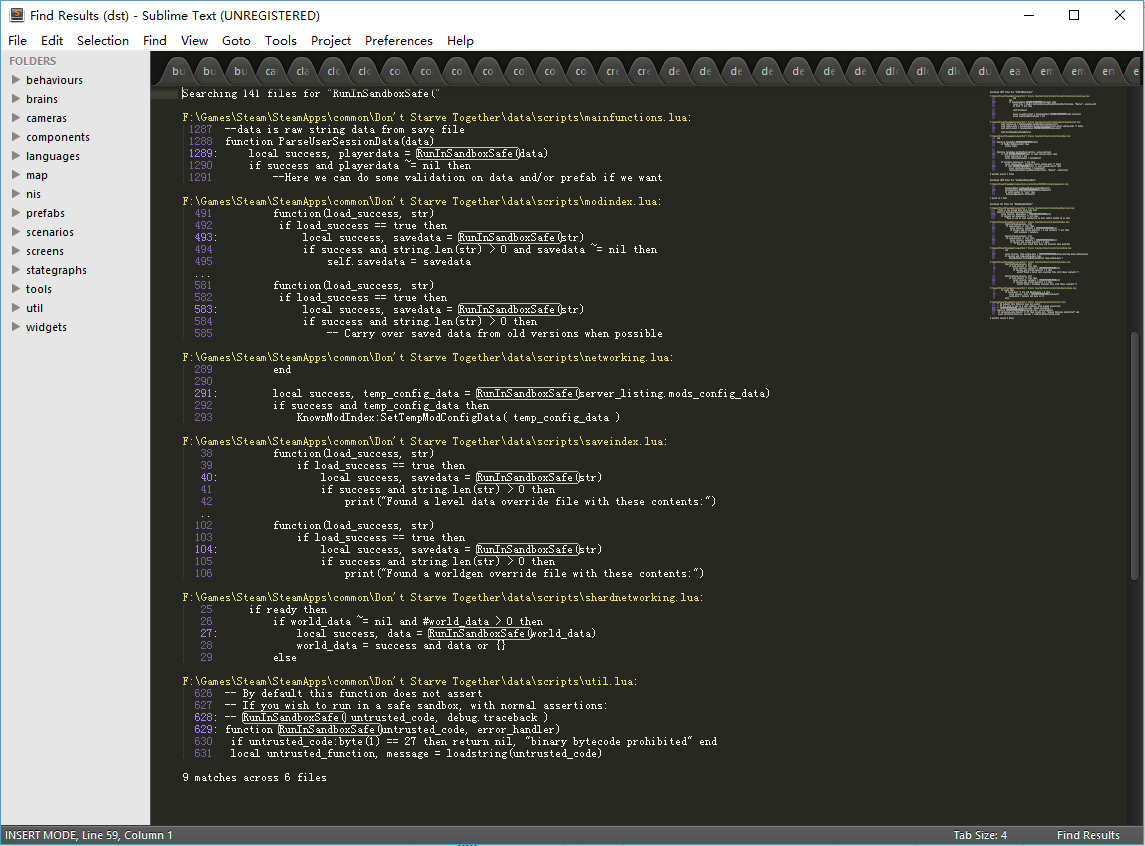
令我大吃一惊的是,只有一处是按照正确用法提供两个参数的,其余全少了。缺失的参数从名字上来看是错误处理例程,它被传入xpcall,一旦有错误发生,就会被调用。
但是看了下RunInSandboxSafe的源码,似乎有点问题:
function RunInSandboxSafe(untrusted_code, error_handler)
if untrusted_code:byte(1) == 27 then return nil, "binary bytecode prohibited" end
local untrusted_function, message = loadstring(untrusted_code)
if not untrusted_function then return nil, message end
setfenv(untrusted_function, {} )
return xpcall(untrusted_function, error_handler )
这里并没有检查error_handler的合法性,那么那句"got nil, function expected"是怎么来的呢?
答案是最后一句xpcall是tail call,即尾调用。尾调用本质上相当于JMP指令,所以这里跳转到xpcall里执行的时候,当前栈仍然显示的是RunInSandboxSafe的。
因此,是xpcall对传入的error_handler为空表示了强烈的不满。有趣的是,在原版lua5.1.4里,没有对这个参数作检查,只有当xpcall所执行的代码中已经出现了错误,才会去尝试调用error_handler,从而出错。而LuaJIT未雨绸缪,直接防患于未然,于是就挂掉了。
好玩的地方在于,这里饥荒的作者使用了ASSERT来断言执行RunInSandboxSafe时lua_call调用的结果。一般来说,只有程序逻辑本身的错误(即程序员自己的锅)才适合用ASSERT来断言,而RunInSandboxSafe执行的可是外部MOD/存档中的字串,这是程序逻辑中的异常处理,应该进入异常处理流程(如显示报错对话框)才对。所以这个地方也是少数MOD导致程序无法启动的原因。
PATCH的早些版本里,我要求用户去修改这个文件,添加一行:
error_handler = error_handler or function (str) print("Klei, you missed this line: " .. str) end
后来由于众所周知的原因,我直接把这个函数的修改版集成到了luajit.dll里面。
0x0C 药引子
不过联机版有些神奇的设定。默认情况下,玩家可以选择自己作主机,让好友连入。在主机玩家的电脑上,所有的游戏过程模拟都是在一个单独的饥荒进程中完成的。但是如果你要启用洞穴的话,就相当于添加了一个平行世界。
在单机版里,玩家只能同时存在于其中一个世界。所以如果玩家跳洞穴,就把地上部分世界暂停并存档,然后把地下世界恢复并同步时间就OK了。
但是联机版不能这么做,因为同一时间要允许有的玩家在地上,有的玩家在地下。由于原来的程序框架是为单机版设计的,这里会变得无比僵硬。
所以游戏作者想了半天提出一个非常完美的思路。反正我们也要建立一些独立服务器来方便玩家联入(因为大部分玩家都没有公网IP,自己建的主往往只能在局域网内可见,所以Klei官方会有一批独立服务器让玩家联入。同时你也可以安装dedicated server这个工具来自己用VPS搭),不如就把洞穴开启时的模式改成独立服务器吧。
具体来说,如果你在创建世界时选择了创建洞穴,则每次主机启动存档的时候,都会额外创建两个进程来分别作为地上世界服务端和地下世界服务端。然后主机和所有局域网内的小伙伴都是连接到这两个服务端上的。最终对于主机而言,同时要跑三个游戏模拟器。因此在添加洞穴的时候,游戏都会先问玩家是否决定让自己的电脑接受三重计算的冲击。
当然了,通过dedicated server,你可以把那两个服务端托管到另一台电脑上(通常是买的VPS),这样本地的压力会小很多。不过由于网络传输的渣渣优化,广域网游戏比局域网要卡得多。
说了这么一大堆,和我们现在在做的有什么关系呢?当然有关系:
启用的那两个服务端虽然和客户端没多大区别,但是作者却为它另创建了一个EXE,命名为dontstarve_steam_nullrenderer.exe。
从名字上来看,为了减轻电脑压力,这是个缩水版的饥荒主程序,没有渲染功能。
另外一点它没写脸上,然而却是结结实实的重击。
它也不需要读取用户输入。
所以它不依赖DINPUT8.DLL。
僵。
所以应该怎么办呢?我们之前那么完美的注入点DINPUT8.DLL没办法用了吗?
是的。如果用户启用了洞穴,或者在专用服务器上用dedicated server,我们的PATCH就加载不了。
真是悲剧。看了半天,联机版似乎也没有什么更好的注入点选择,唯一剩下的就是WS2_32.DLL和WINMM.DLL了。
虽然饥荒主程序从WS2_32.DLL中仅导入了两个函数,但是经过我的观察,仅仅在傀儡中实现两个是远远不够的。原因是Steamapi.dll本身也依赖WS2_32.dll,而且导入了更多函数,你必须都得一一实现掉。
还好winmm.dll依赖关系简单些,唯一 的问题就是函数多了点。不过想了想,其实也没那么麻烦:
#define ENTRY(name) \
static void* pfn##name = NULL; \
__declspec(naked)void name() { \
_asm jmp pfn##name \
#define INIT(name) \
pfn##name = ::GetProcAddress(hOrg, #name);
ENTRY(mciExecute)
ENTRY(CloseDriver)
ENTRY(DefDriverProc)
ENTRY(DriverCallback)
... // 中间略去
ENTRY(waveOutUnprepareHeader)
ENTRY(waveOutWrite)
ENTRY(wid32Message)
ENTRY(wod32Message)
void Init() {
TCHAR sysPath[MAX_PATH * 2];
::GetSystemDirectory(sysPath, MAX_PATH);
_tcscat(sysPath, _T("\\WINMM.DLL"));
HMODULE hOrg = ::LoadLibrary(sysPath);
if (hOrg != NULL) {
INIT(mciExecute)
INIT(CloseDriver)
INIT(DefDriverProc)
INIT(DriverCallback)
INIT(waveOutUnprepareHeader)
INIT(waveOutWrite)
INIT(wid32Message)
INIT(wod32Message)
::LoadLibrary(_T("DINPUT8.DLL"));
BOOL WINAPI DllMain(HINSTANCE hInstance, DWORD ul_reason_for_call, LPVOID reserved) {
switch (ul_reason_for_call) {
case DLL_PROCESS_ATTACH:
Init();
// system("pause");
break;
return TRUE;
其实我们并不需要完完全全按照原先的标准的写法挨个定义跳板函数,既然我们不做处理,直接用一条JMP指令就可以了。参数什么的其实已经由调用者填好了。注意要使用__declspec(naked)这个修饰,避免生成C的框架代码。
新的WINMM.dll就相当对针对服务端的药引子,它唯二的作用就是转发去往winmm.dll的调用,并在初始化的时候加载DINPUT8.DLL。
0x0D 鬼使神差
按理说,联机版饥荒和单机的差别应该不大,该填的坑也填的差不多了(人生三大错觉之一)。在自己机子上玩了独自试验了几次,一切都很正常。
不过一旦有别人连入,问题就又来了。据贴吧吧友反馈,有时客户端人物不能走动;退出的时候会留下黑影,再进就进不来了,除非重启服务端。
于是我翻开饥荒lua脚本的源码,查找相关的服务器逻辑。结果发现其实大部分通信都是通过一个简单的RPC机制来实现的(scripts/networkclientrpc.lua)。每个请求都有一个独立的rpc代号,客户端将代号和参数打包之后发到服务端,由服务端解包后执行。(这里多说一句,由于lua 5.1.4的限制,这个打包过程很低效——根据数据来生成一个表定义的lua代码,解包的时候再执行一次得到数据。在lua 5.3中有string.dump这个神器可以完美地以二进制方式打包,为此我结合LZ系列压缩算法的思路,写了个简单的模块,代码在这里(Core.Encode): https://github.com/paintdream/PaintsNow/blob/master/App/BootQuery/Core.lua )
这看起来也没有什么问题,那么为什么客户端人物不能走动?没办法只能开两个游戏调试下了。
我在工作电脑上跑起游戏作服务端,Surface Pro 3上跑客户端。看看出了什么鬼。
吧友所指的问题果然得到复现,另外我发现即使能成功进入主机,各种行为也很不正常,甚至不能走路(会被弹回去)。那么这就很奇怪了。
于是我改了些RPC Handler的代码,添加了一些LOG语句,看看有什么异常。结果发现:
有些调用的参数明显是在调另外一个函数!
举个例子:
RPC_HANDLERS.DoWidgetButtonAction = function(player, action, target, mod_name)
if not (checknumber(action) and
optentity(target) and
optstring(mod_name)) then
print("Current RPC CODE = " .. CURRENT_RPC_CODE)
printinvalid("DoWidgetButtonAction", player)
return
local playercontroller = player.components.playercontroller
if playercontroller ~= nil and playercontroller:IsEnabled() and not player.sg:HasStateTag("busy") then
if mod_name ~= nil then
action = ACTION_MOD_IDS[mod_name] ~= nil and ACTION_MOD_IDS[mod_name][action] ~= nil and ACTIONS[ACTION_MOD_IDS[mod_name][action]] or nil
action = ACTION_IDS[action] ~= nil and ACTIONS[ACTION_IDS[action]] or nil
if action ~= nil then
local container = target ~= nil and target.components.container or nil
if container == nil or container.opener == player then
BufferedAction(player, target, action):Do()
end,
这里我加了点print,结果发现神奇的东西来了。player是正确的player table,但是mod_name却是nil,而且action和target居然是两个数字(大约200,300的样子)!
往上找找,还发现一个函数:
DragWalking = function(player, x, z)
if not (checknumber(x) and
checknumber(z)) then
printinvalid("DragWalking", player)
return
local playercontroller = player.components.playercontroller
if playercontroller ~= nil then
playercontroller:OnRemoteDragWalking(x, z)
end,
很明显,这个调用真的串线了。从它的参数上来看更可能调用的是DragWalking这个函数,那两个数字其实是x和z,即人物坐标。当然也有可能是参数与DragWalking类似的其他函数。
所以问题应该就出在那个调用代号上。往下看看调用代号是怎么生成的,果然发现了问题:
RPC = {}
--Generate RPC codes from table of handlers
local i = 1
for k, v in pairs(RPC_HANDLERS) do
RPC[k] = i
i = i + 1
i = nil
--Switch handler keys from code name to code value
for k, v in pairs(RPC) do
RPC_HANDLERS[v] = RPC_HANDLERS[k]
RPC_HANDLERS[k] = nil
还好我在很早之前看到云风写的有关lua字符串Hash算法为了防DDOS的变动,一眼直接就看出了问题(终于不用走弯路了):这样生成RPC代号的方法在新版lua中是错误的。
原因在于新版lua的字符串hash算法中,包含了一个随机种子,它避免了因算法固定而导致被黑客构造大量具有相同HASH值的不同字符串招至的DDOS攻击。因此每次启动时,针对相同字符串的HASH结果都不总是相同。
然而pairs内部依赖于next来做表遍历,next的遍历顺序则与key的hash值相关( lua会将key的hash值对表长度的进行一个modpow2的取余,将结果作为hashpart的index,感谢ms2008指出 )。这里的key明显就是RPC_HANDLERS的key,也就是RPC处理例程的名字。因此,这种依赖于遍历顺序而生成调用代号的方法会导致服务器和客户端用的代号完全错位,结果导致了串线故障。
那么怎么改呢。要么改HASH算法,要么改lua代码。
为了世界和平,我们要保护服务器不被DDOS!!
于是我机智(chun)地选择了让用户改lua代码!(这里说一句,本文是按BUG顺序整理的,所以在时间顺序上会不一致,在当时发布这个版本的时候,前几处代码还需要用户手工来改,所以当时觉得再多改些也不是问题)
定位到722行,改成这样:
local temp = {}
for k, v in pairs(RPC_HANDLERS) do
table.insert(temp, k)
table.sort(temp)
for k, v in ipairs(temp) do
RPC[v] = k
local i = 1
for k, v in pairs(RPC_HANDLERS) do
RPC[k] = i
i = i + 1
i = nil
]]
0x0E 拆包炸弹
改了之后,人物是可以动了,但是客户端退出时还是有黑影,再进就进不来了。
这很诡异,第一感觉也许是某个任务没有执行完导致的。但是又没有报错信息,去哪去找是哪个任务没完成呢?
一路从玩家消失时的消息跟踪过来,发现问题出在scripts/components/playerspawner.lua:79
local function PlayerRemove(player, deletesession, migrationdata, readytoremove)
if readytoremove then
player:OnDespawn()
if deletesession then
DeleteUserSession(player)
player.migration = migrationdata ~= nil and {
worldid = TheShard:GetShardId(),
portalid = migrationdata.portalid,
sessionid = TheWorld.meta.session_identifier,
} or nil
SerializeUserSession(player)
player:Remove()
if migrationdata ~= nil then
TheShard:StartMigration(migrationdata.player.userid, migrationdata.worldid)
player:DoTaskInTime(0, PlayerRemove, deletesession, migrationdata, true)
这里DoTaskInTime是一个延迟调用的API,它回调了PlayerRemove自己,于是形成了死循环。(真的很想吐槽这里的代码)
可这怎么可能是死循环呢?明明延迟调用时就指定了readytoremove肯定是true了,下次就不会进else分支了,怎么可能呢?
然而我print了一下,确实是死循环,但是一直在打印的readytoremove值既不是所期待的true,也不是false。
而是nil。
所以,发生的事情经过就是PlayerRemove一直在死循环,后续的处理得不到执行,服务端认为要退出的玩家还在线,所以这个玩家再想登录进来就会被拒。
好了,为什么是nil呢?通过查看DoTaskInTime的内部实现可知,这是它有一个打包变长参数的过程(scheduler.lua:286)
function Scheduler:ExecutePeriodic(period, fn, limit, initialdelay, id, ...)
local list, nexttick = self:GetListForTimeFromNow(initialdelay or period)
local periodic = Periodic(fn, period, limit, id, nexttick, ...)
list[periodic] = true
periodic.list = list
return periodic
而Periodic又做了什么呢?看37行:
Periodic = Class(function(self, fn, period, limit, id, nexttick, ...)
self.fn = fn
self.id = id
self.period = period
self.limit = limit
self.nexttick = nexttick
self.list = nil
self.onfinish = nil
self.arg = toarrayornil(...)
其中toarrayornil是C方面实现的函数,相当于{...},但是当...为空时返回nil。
那么,是toarrayornil出了问题吗?在探索这个函数之前,我忽然想到,lua中table的数组部分有个非常奇怪的性质,其长度是从1到第一个nil为止(不包括nil),那么如果打包中的参数含有nil值,会不会nil值后面东西就被忽略了呢?
恭喜我又猜对了!
编写一个这样的脚本,存为test.lua:
function foo(...)
return {...}
print(unpack(foo(1, 2, 3, nil, 5)))
在lua 5.1.4官方版的执行结果如下:
1 2 3 nil 5在luajit 2.1.0版的执行结果如下:
1 2 3这里官方的结果比较有意思,居然能把nil后的值读出来,但是luajit就不行了。而lua文档里也没明确这种情况下lua的行为,所以只能说是实现不同吧。
在这个例子里,PlayerRemove被调用时只有player这个参数不是nil,其余全是nil,所以在调用DoTaskInTime时,虽然readytoremove被指定了true,但是它前面两个参数的值是nil,所以就触发了LuaJIT的这个问题。
打开lib_base.c:220
LJLIB_CF(unpack)
GCtab *t = lj_lib_checktab(L, 1);
int32_t n, i = lj_lib_optint(L, 2, 1);
int32_t e = (L->base+3-1 < L->top && !tvisnil(L->base+3-1)) ?
lj_lib_checkint(L, 3) : (int32_t)lj_tab_arraylen(t); // <---
if (i > e) return 0;
n = e - i + 1;
if (n <= 0 || !lua_checkstack(L, n))
lj_err_caller(L, LJ_ERR_UNPACK);
do {
cTValue *tv = lj_tab_getint(t, i);
if (tv) {
copyTV(L, L->top++, tv);
} else {
setnilV(L->top++);
} while (i++ < e);
return n;
注意在<----处我用一个新的lj_tab_arraylen代替了原有的lj_tab_len调用,它的实现如下:
MSize LJ_FASTCALL lj_tab_arraylen(GCtab *t)
MSize j = (MSize)t->asize;
while (j > 1 && tvisnil(arrayslot(t, j - 1))) {
j--;
if (j) --j;
return j;
重新编译luajit并应用,问题解决。
0x0F 人间蒸发的海盗鹦鹉
新的版本持续用了很久,新的BUG反馈与很少了,而且基本上都是已经使用了旧的patch或者自己不会按要求改代码导致的。
安逸的日子一直持续到有用户开始报告说:陷阱类物品使用鼠标点击后捕捉到的动物消失,并且物品的耐久没有减少。
这看起来很难理解,这个bug是如此的精致,精致到不像是脚本引擎更换时引起的bug,反而更像是lua代码本身的bug。若是PATCH引起的bug,为什么游戏中的其他逻辑能精确地运行,唯独陷阱不行呢?这是怎么做到的呢?
(前方高能提醒:这个是制作此Patch时遇到的最诡异,逻辑链最长,但同时也最好玩的一个)
为此我打开游戏(启用PATCH),建了个新档,用控制台刷出一个捕鸟器和一只海盗鹦鹉。拾取后果然鹦鹉没了,捕鸟器耐久也没掉。
那么,问题出在哪里呢?通过仔细比对启用PATCH前后的画面,发现一件怪事:
(启用前)
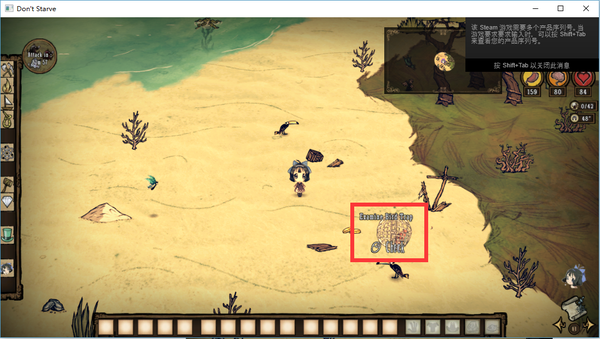
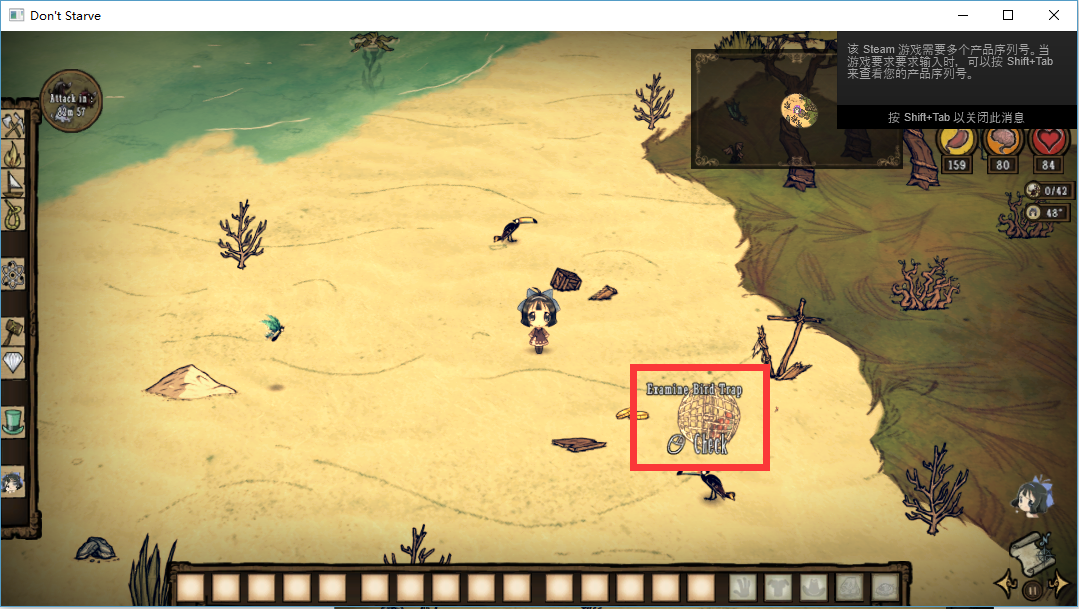
(启用后)
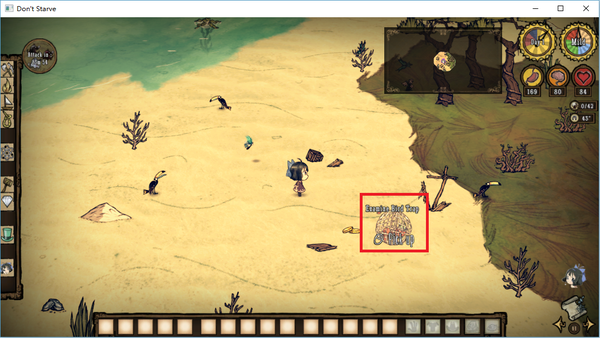
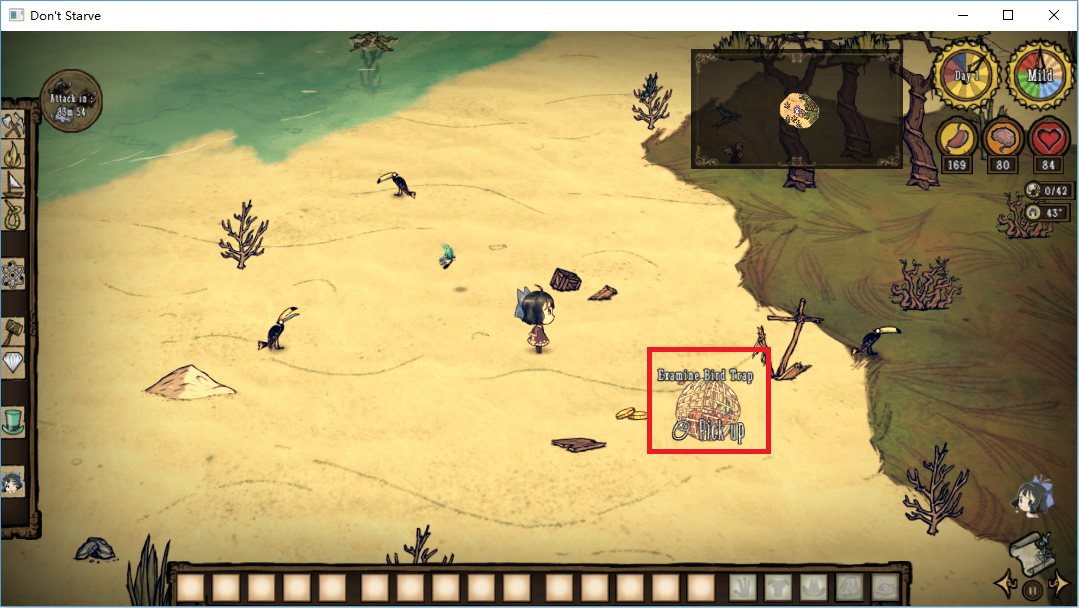
所以问题应该是出在原本应该是Check的操作变成了Pick up,导致玩家捡起了捕鸟器而不是收获捕到的鸟。但是如果使用空格捡的话,则会正确地执行Check操作。
接下来目标就很明确了:这个Pick up是哪里来的?
通过检索lua源码中"Pick up",可以发现在strings.lua中有其定义:
STRINGS = { --ACTION MOUSEOVER TEXT
ACTIONS =
REPAIR = "Repair",
REPAIRBOAT = "Repair",
PICKUP = "Pick up",
CHOP = "Chop",
FERTILIZE = "Fertilize",
SMOTHER = "Extinguish",
再看看哪些地方引用了STRINGS.ACTIONS.PICKUP这个值,并没有找到,再找ACTIONS.PICKUP,发现一处有价值的线索:
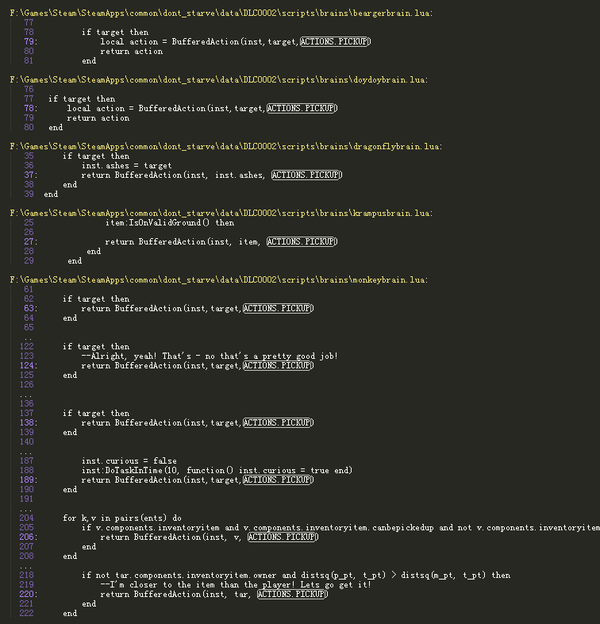
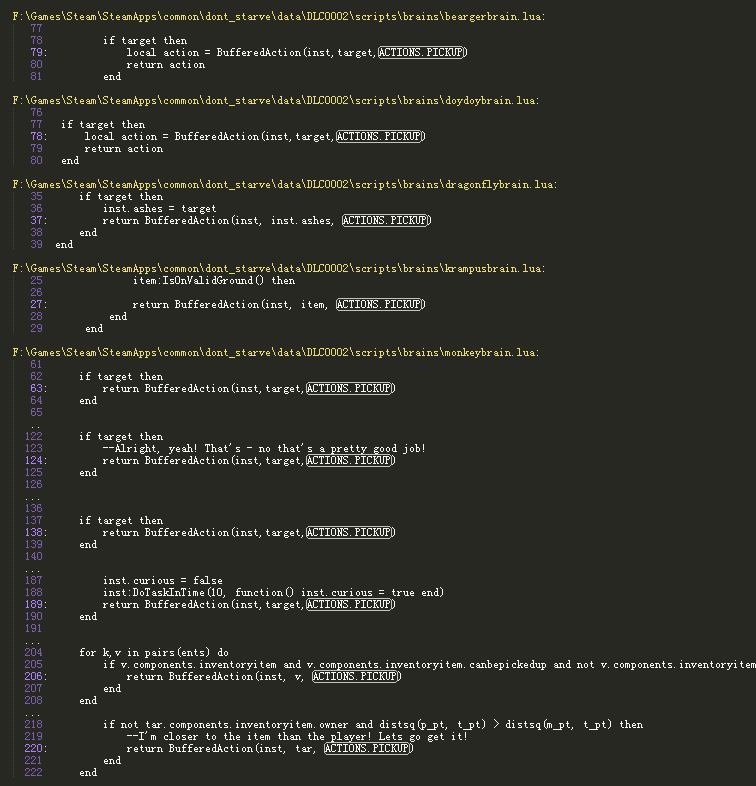
也就是说,所有操作都是通过构造一个BufferedAction来封装的,从名字上来看既然是Buffered,应该会有一个队列之类的来存储Actions,继续找"BufferedAction"可以发现在scripts/components/playeractionpicker.lua里有些奇怪的东西:
function PlayerActionPicker:SortActionList(actions, target, useitem)
if #actions > 0 then
table.sort(actions, function(l, r) return l.priority > r.priority end)
local ret = {}
for k,v in ipairs(actions) do
if not target then
table.insert(ret, BufferedAction(self.inst, nil, v, useitem))
elseif target:is_a(EntityScript) then
table.insert(ret, BufferedAction(self.inst, target, v, useitem))
elseif target:is_a(Vector3) then
local quantizedTarget = target
local distance = nil
--If we're deploying something it might snap to a grid, if so we want to use the quantized position as the target pos
if v == ACTIONS.DEPLOY and useitem.components.deployable then
distance = useitem.components.deployable.deploydistance
quantizedTarget = useitem.components.deployable:GetQuantizedPosition(target)
local ba = BufferedAction(self.inst, nil, v, useitem, quantizedTarget)
if distance then
ba.action.distance = distance
table.insert(ret, ba)
return ret
function PlayerActionPicker:GetSceneActions(targetobject, right)
local actions = {}
for k,v in pairs(targetobject.components) do
if v.CollectSceneActions then
v:CollectSceneActions(self.inst, actions, right)
if targetobject.inherentsceneaction and not right then
table.insert(actions, targetobject.inherentsceneaction)
if targetobject.inherentscenealtaction and right then
table.insert(actions, targetobject.inherentscenealtaction)
if #actions == 0 and targetobject.components.inspectable then
table.insert(actions, ACTIONS.WALKTO)
return self:SortActionList(actions, targetobject)
仔细看了半天,这里似乎是一个比较关键的地方。所有的BufferedAction在这里通过table.sort按priority排了个序。我猜想游戏逻辑应该是先收集各种可选的操作选项,然后把操作们按优先级排个序,顶端的即为优胜者,将会被选作默认的操作(亲,你直接选个最大值不就得了吗)。
因此,要么是排序前的actions有已经有问题了,要么是排序本身出的问题。通过这里我们应该可以缩小检查的范围。
0x10 不稳定天平
为了验证我的想法,在SortSceneActions里写点LOG。看看好不好玩:
local mapActionToName = {}
for k, v in pairs(STRINGS.ACTIONS) do
local m = ACTIONS[k]
if (m) then
mapActionToName[m] = k
local function PrintList(actions)
for i, v in ipairs(actions) do
print("ACTION [" .. i .. "] = " .. (mapActionToName[v] or "NULL"))
function PlayerActionPicker:SortActionList(actions, target, useitem)
if #actions > 0 then
print("-----------------------")
print("Before sorting ... ")
PrintList(actions)
table.sort(actions, function(l, r) return l.priority > r.priority end)
print("After sorting ... ")
PrintList(actions)
local ret = {}
for k,v in ipairs(actions) do
if not target then
table.insert(ret, BufferedAction(self.inst, nil, v, useitem))
elseif target:is_a(EntityScript) then
table.insert(ret, BufferedAction(self.inst, target, v, useitem))
elseif target:is_a(Vector3) then
local quantizedTarget = target
local distance = nil
--If we're deploying something it might snap to a grid, if so we want to use the quantized position as the target pos
if v == ACTIONS.DEPLOY and useitem.components.deployable then
distance = useitem.components.deployable.deploydistance
quantizedTarget = useitem.components.deployable:GetQuantizedPosition(target)
local ba = BufferedAction(self.inst, nil, v, useitem, quantizedTarget)
if distance then
ba.action.distance = distance
table.insert(ret, ba)
return ret
在排序前后我都把actions数组中的值打印出来,看看这个排序做了什么:
(启用PATCH前)
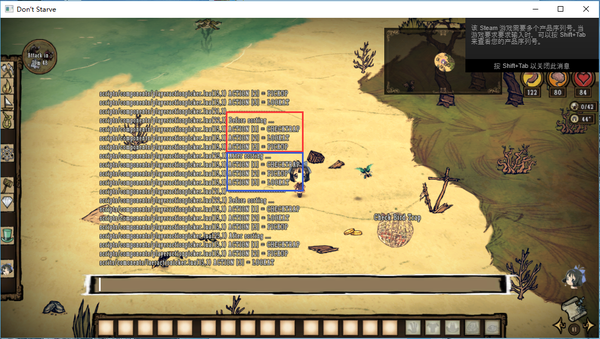
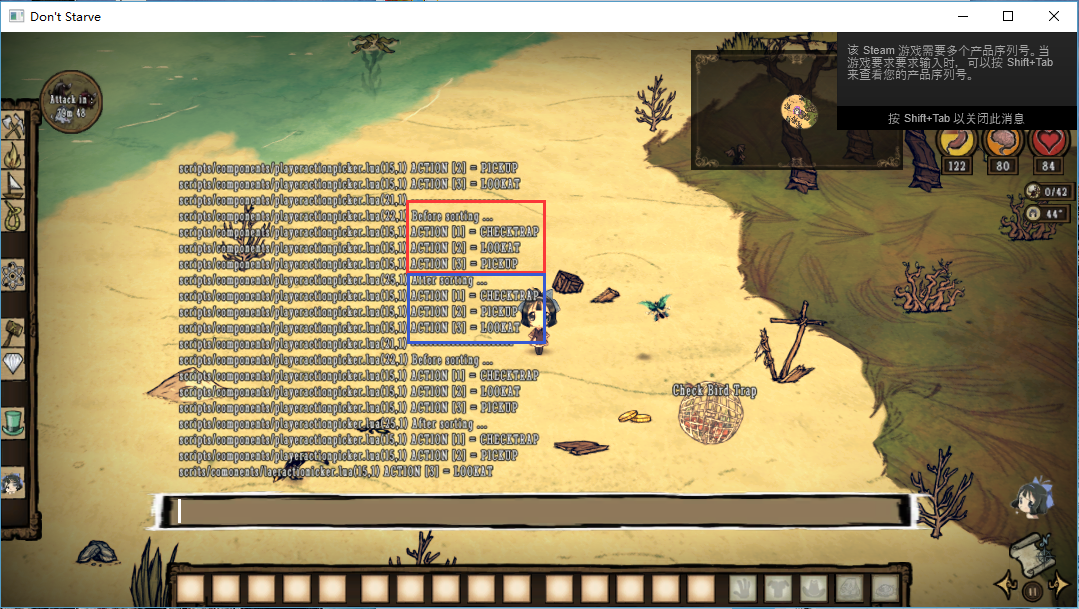
(启用PATCH后)
注意看图中蓝框的部分,排序后的结果果然变成PICKUP第一了。于是一个直接的想法就是,饥荒作者并不知道table.sort排序是不稳定的,LuaJIT中的快排算法很可能和原版的不一样,在最大元素不唯一的情况下,二者的结果就会有差异!!
于是我打开actions.lua,一切都似乎明白了:
Action = Class(function(self, priority, instant, rmb, distance, crosseswaterboundary)
self.priority = priority or 0
self.fn = function() return false end
self.strfn = nil
self.testfn = nil
self.instant = instant or false
self.rmb = rmb or nil
self.distance = distance or nil
self.crosseswaterboundary = crosseswaterboundary or false
end)
ACTIONS=
REPAIR = Action(),
PICKUP = Action(2),
CHECKTRAP = Action(2),
BUILD = Action(),
PLANT = Action(),
非常明显,PICKUP和CHECKTRAP的优先级都是2,那么排序就有可能出现PICKUP在CHECKTRAP前面的情况。
想要解决也很容易,把CHECKTRAP的优先级调大些(如2.5),就好了。事实证明调整后,bug也确实消失了。
然而问题就到这里完结了吗?
0x11 依赖于错误的正确
这个bug的神奇之处在于,并不仅仅如此。
在发布了修补办法之后,吧友表示问题解决了,但是还有其他的类似问题,比如船只不能Inspect,MOD人物翼语的莲花台不能右键拾取,烤箱MOD异常等等。
确实,这些都是原版饥荒Actions优先级设置导致的,那么有两种可能:
1. 作者们修改了排序算法,使之变成稳定的(如冒泡排序),所以在优先级相同的时候,原序列中排前面的排序后也排前面。
2. 作者们压根就不知道快排还有不稳定一说,出现结果异常的时候就调调优先级,结果要是符合预期,就不管了。lua5.1.4中快排实现和LuaJIT中不一样导致了这个问题。
最初我以为是1的问题,于是手写了个稳定排序,挂入后果然解决了陷阱的问题(即使优先级都是2)。但是其余的bug不能都解决,此路不通。
那么如果按2来说,快排实现不一样,那么我换一个lua5.1.4原版的DLL试试呢?
于是我把lua51.dll改名成luajit.dll,运行游戏,果然一切正常。看来就是排序算法的问题了。
于是我打开lua5.1.4的源码,对比luajit的源码,却发现了神奇的事情:排序算法除了报错部分有点区别以外,竟然是一模一样!!
那这个就奇怪了,排序算法也是一样的,为什么结果不一样呢?我漏掉了什么东西吗?
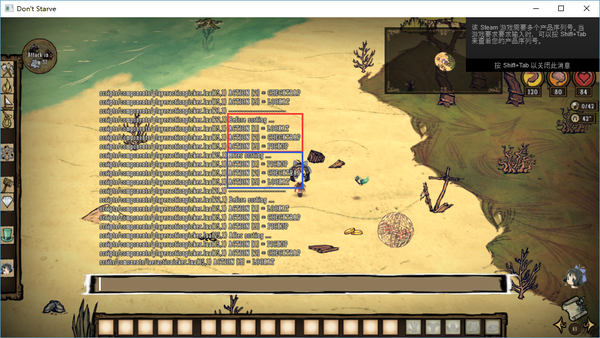
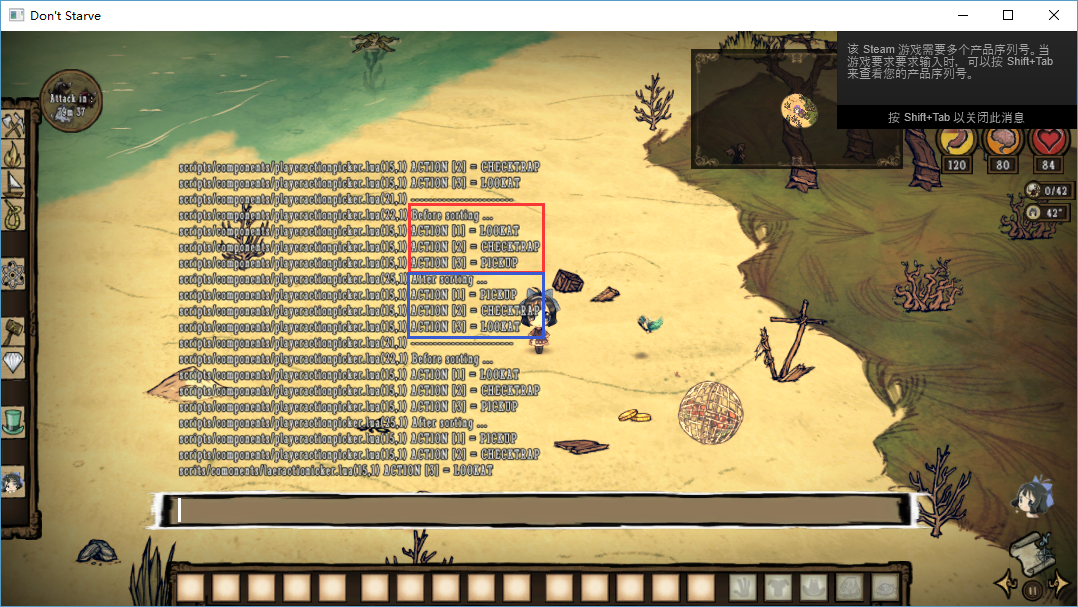
再仔细检查这两张图,终于发现了问题所在:
(启用PATCH前)
(启用PATCH后)
之前我一直关注排序后的结果,却没发现排序前的数据顺序也是不一样的(红框所示)。也就是说,问题本身与排序算法没有关系,与错误的priority虽有关系,但不是致命的。
致命的是排序前数据的顺序是为何不同的!
沿着SortActionList往上找,果然,刚刚就在眼皮底下错过了:
function PlayerActionPicker:GetSceneActions(targetobject, right)
local actions = {}
for k,v in pairs(targetobject.components) do
if v.CollectSceneActions then
v:CollectSceneActions(self.inst, actions, right)
if targetobject.inherentsceneaction and not right then
table.insert(actions, targetobject.inherentsceneaction)
if targetobject.inherentscenealtaction and right then
table.insert(actions, targetobject.inherentscenealtaction)
if #actions == 0 and targetobject.components.inspectable then
table.insert(actions, ACTIONS.WALKTO)
return self:SortActionList(actions, targetobject)
不管你信不信,问题就出在这个函数里的for循环上。
如果您看过前文的话,就能明白我的意思——for循环的枚举顺序是与string HASH算法有关的!而v:CollectSceneActions是顺序往actions中添加ACTION的,那么,不同的枚举顺序就会导致ACTION在actions里的顺序不一致。
而LuaJIT的string HASH算法和原版lua的并不一样,这也是前文联机版RPC出bug的原因。
那么,我们把逻辑整理一下,完整的bug触发流程是:
string HASH算法不一致 => table里key的遍历顺序不一致 => actions里的ACTION顺序不一致 + 排序算法不稳定且待排序数组中存在键相等(priority相等)的问题 => 排序结果不一致 => 选中的操作不一致。
事已至此,所有的谜团都已经解开了。回头来看,如果饥荒作者在发现actions排序后顺序奇怪的时候能想到这是排序算法的稳定性,那么就绝不会只调整个别ACTION的priority来解决,而是会重新为所有的ACTION明确不同的priority。如果他们这么做了,整个问题就完全不会出现。
而现在,程序能够正确运行完全依赖于特定排序算法对特定数据的排序结果。试想如果有一个mod手工添加了一个ACTION;或者随着版本更新,作者又在targetobject.components里添加了一个默认components,都会导致排序的结果与预期的不一致,而且这种不一致会导致大面积的逻辑错误,极难排除。
更麻烦的在于,已经有不少第三方MOD使用了ACTION。如果随便改掉默认ACTION的priority值可能会导致这些MOD出错。
因此这个bug就慢慢地变成了feature,且无人敢动。
那么怎么解决呢?我没办法,只能把lua5.1.4的string HASH算法复制出来,替换掉luajit的那份实现了。这个同时也解决了之前RPC的问题,不用再修改代码了。我其实不想这么改,因为这样的设计将会面临更高的安全风险。但是没办法,将错就错吧。
0x12 瓶颈
根据吧友的反馈,我发现了一处LuaJIT自身的限制:在加载存档时,如果存档太大,常数个数超过65536,LuaJIT初始化表的时候会出错。出错时表大小达到了惊人的0x65000000多,经过简单的跟踪,表结构已经被破坏。再仔细看时发现LUAJIT指令中BCMAX_D这个常数不能随便加大,否则32位指令会放不下。看了下luajit的BBS,发现Mike回答过这个问题:
LuaJIT has different limits and different design constraints.
For a single table that consists only of constants there's
effectively no limit (memory is the limit).
But your test case has lots of small, nested tables. Every
individual table only occupies a single constant slot (and not one
for each of its keys/values). But there are too many of these
tables to keep them in a single function.
The short term solution is to split the table construction into
smaller pieces, wrapped into individual functions. The long term
solution would be to add a workaround for these limits to LuaJIT.
But I'm not sure about the best way, yet.
> [2] The Lua bug it exposed has since been fixed
> http://www. lua.org/bugs.html# 5.1.4-6
This problem is not present in LuaJIT 2.0.
(实际上luajit 2.0还是有这个问题。)
原因很简单,就是饥荒存档的时候使用了很烂的策略,把表序列化成了lua 代码。然后就含有了巨量的表、常数。从而在load时超出了LuaJIT的限制。如果想要解决,最简单的办法似乎是重写load的代码,为存档专门分块加载。彻底点的办法是修改存档格式,但是这样就会无法兼容旧存档。
但是仔细看了Mike的话后我发现其实只需要把数据表分层用function 包起来,就可以缓解这个问题。只要每层的function常量不超过65536个,就可以正确加载。
于是打开lib_base.c:
void filter(lua_State* L) {
char ch, check = 0;
int level = 0;
int t = lua_type(L, 1);
int happen = 0;
int quote = 0;
int slash = 0;
const char* p = lua_tostring(L, 1);
long size = lua_objlen(L, 1);
char levelMasks[1024];
memset(levelMasks, 0, sizeof(levelMasks));
if (t == LUA_TSTRING) {
char* target = (char*)malloc(size * 2);
char* q = target;
while (size-- > 0) {
ch = *p++;
if (ch == '"' && !slash) {
quote = !quote;
if (!quote) {
if (ch == '{') {
level++;
if (check) {
const char* ts = "(function () return {";
--q;
memcpy(q, ts, strlen(ts));
q += strlen(ts);
levelMasks[level - 2] = 1;
check = 0;
happen = 1;
check = 1;
*q++ = (char)ch;
} else {
*q++ = (char)ch;
if (level > 0 && ch == '}') {
level--;
if (levelMasks[level] != 0) {
const char* ts = "end)()";
memcpy(q, ts, strlen(ts));
q += strlen(ts);
levelMasks[level] = 0;
check = 0;
} else {
if (ch == '\\') {
slash = !slash;
} else {
slash = 0;
*q++ = (char)ch;
check = 0;
if (happen) {
*q = 0;
/* printf("TARGET: %s\n", target); */
FILE* tg = fopen("modified.lua", "wb");
fwrite(target, q-target, 1, tg);
fclose(tg);*/
lua_pushlstring(L, target, q - target);
lua_replace(L, 1);
free(target);
LJLIB_CF(loadstring)
filter(L);
return lj_cf_load(L);
当检测到有连续的两个{时(没办法,只能为DS作这个兼容了)。就在这个子表外插入一个function 边界。重新编译后,问题解决。
0x13 半程小结
经过将近一个半月的努力,我的PATCH终于成功地解决了绝大多数的bug,正式发布了。同时,为了减轻用户的压力,我通过各种办法集成了对原版饥荒lua代码的修改,使得用户只需要把发布的文件复制到饥荒bin目录即可启用。
当初真的没有想到会遇到如此之多的问题,但是通过解决这些BUG,我阅读了相当数量的源码,用OllyDBG+WinDBG调试和分析了很多的崩溃报告。虽然大多数猜想和试验由于与最终结果不符没有放上来,但是谁又能保证一下子就找到bug呢~
同时,通过阅读他人的代码,我也在思考着设计和编码的问题。这个地方的实现好不好,为什么?作者当时应该是怎么想的?为什么要有这样的设定或者限制?如果这个让我来写,我应该怎么设计?能不能实现得更好?
另外,编码其实只是游戏体验中的一部分,游戏的世界观设定,元素设定,数值设计,画风选择,音乐的制作等等都构成了这个游戏不可分割的一部分。在我看来,饥荒为什么这么火,和它这些方面的努力是分不开的。或许在编程角度来看,饥荒本身的实现槽点很多,但是这并不妨碍它成为一款优秀的沙盒游戏。
附:
在本文写作的时候,仍然有bug没有得到解决:
在启用了PATCH之后,上下洞穴有一定概率会导致季节错乱。这个BUG我在PATCH的早些版本曾经自己玩出来过,但是最新版本都没有成功复现。据吧友反馈这个问题仍然存在,但是所有说问题存在的吧友只有一位按我的要求提供了存档和MODS,但是仍然没能在我的机器上重现。其余的两三位吧友在提问之后就消失了,再也没有反馈。我在查阅了吧里旧的帖子后发现这个问题原版应该也会出现,但是那个帖子是很久以前发的,作者是否尝试“修复”过,并不得而知。
其实写这个PATCH最大的阻力并非来自程序代码本身,而是在众多的反馈之中,很少能有人能够有效地按要求描述出bug的具体经过,细节,以及如何重现。很多bug的解决都是通过简单的描述猜出来的,因此浪费了大量时间在不确切的猜测上。
0x14 火山结界(番外)
(这一部分解决的是一个原版饥荒中自火山开放以来一直存在的bug,即在Shipwrecked DLC中进出火山时日期会错乱。8月10号我收到了Klei官方的回复,应该会在下一个版本中修复这个问题!)
(再次强调下,这个BUG的触发与是否启用了我的PATCH没有关系)
饥荒的作者在日期设计上有点奇怪,他不是采用统一的时间,而是每个世界(包括洞穴,火山)都有一一个独立的时间,只有当前世界的表会走。这样跳世界的时候时间会不一致。
按理说用跳之前世界的时间盖掉新世界的时间不就简单了吗?可是作者想允许不同世界的时间不一样,所以要用player_age(即玩家年龄)来同步两个世界(ROG和SW跳除外)。(这个设计真的是无力吐槽)
然后呢,当检测到用户是从一个世界跳到另一个世界的时候,它就触发这个同步的代码。跳世界(travel)的方式总共有:"ascend""descend"(上下洞穴)"shipwrecked"(跳ROG和SW)"ascend_volcano""descend_volcano"(进出火山)这几种。
下面打开data\DLC0002\scripts\gamelogic.lua文件,定位到:
if travel_direction == "ascend" or travel_direction == "descend" then
print ("Catching up world", catch_up, "(", player_age,"/",world_age,")" )
当上下洞穴和进出火山的时候都需要同步时间(跳ROG和SW不需要),所以要在加载世界的时候需要检测下是不是要同步。
所以BUG的源头就是,作者在这里漏掉了"descend_volcano"和"ascend_volcano"这两条。一旦你在火山里呆的时间超过一天,这个时间就应该要同步,但是由于作者的大意,这个同步永远不可能发生。。。
0x15 再遇精致BUG
如果你是一位饥荒老玩家,那么制作“高温”陷阱几乎是黄金必备技能。Shipwrecked DLC中,玩家可以使用天然形成的双帽贝岩或者手工移植两丛咖啡,配合雪球发射机(即我们俗称的“灭火器”),来制作“高温”陷阱。相关教程可以参考深辰S的饥荒视频: 饥荒游戏 船难DLC 新手向专辑 第5期 制冰机与陷阱 深辰解说 ,40分钟开始。
为什么我要把“高温”两个字加上引号呢?这是因为,在这篇文章里,我将详细地介绍这个陷阱的原理。在这里提前剧透一下——这种陷阱和高温其实没有什么关系,只不过说成高温大家理解比较方便~
为什么“高温”陷阱如此受欢迎呢?这是因为你只需要找到合适的帽贝岩组,在旁边不远处造个灭火器就大功告成了。只要雪球发射机开着,它就会不停地向其中一个帽贝岩发射雪球,这个雪球可以在发射路径以及目标点一小片周围造成范围冰冻效果,配合猴子陷阱/猪人陷阱可以在较短时间内刷出香蕉等资源。猎狗和坎普斯来袭的时候也能将其冻住逐个击杀。饥荒里雪球发射机只要处于开启状态就会以恒定速度消耗燃料,发射雪球的速率再快消耗速度也是恒定的。用的时候开启,刷完后关掉,没有额外的开销。
在前一篇的专栏文章( 饥荒游戏LuaJIT扫雷笔记 - paintsnow的文章 - 知乎专栏 )里,我介绍了将饥荒原版lua引擎替换为LuaJIT引擎的种种奇遇。本篇是前篇的续作,纪录一个关于“高温”陷阱的BUG。
如果说之前的捕鸟器BUG(原篇0x0F 人间蒸发的海盗鹦鹉)比较精致的话,这个BUG就精致得匪夷所思了——在使用了我的LuaJIT补丁之后,“高温”陷阱中的雪球发射机变得萎靡不振,开始偷懒——原本处于连发状态的雪球,变成了2~3秒一发。
所以麻烦在于,如果是LuaJIT补丁引起的BUG,按常理破坏了某些机制后,雪球应该一个也不发才对。但是间隔变长了是什么鬼啊?我的第一感是os.clock()之类的API返回的时间单位可能有差异,然而检查了一下LuaJIT,发现它确实是按标准实现的,没什么问题。
没办法一点点打LOG来查吧。绕了几个小时的路,终于摸清了连发雪球的原理。
在必要的地方添加了print语句后,挂入OllyDBG可以看到连发状态下的状态日志:
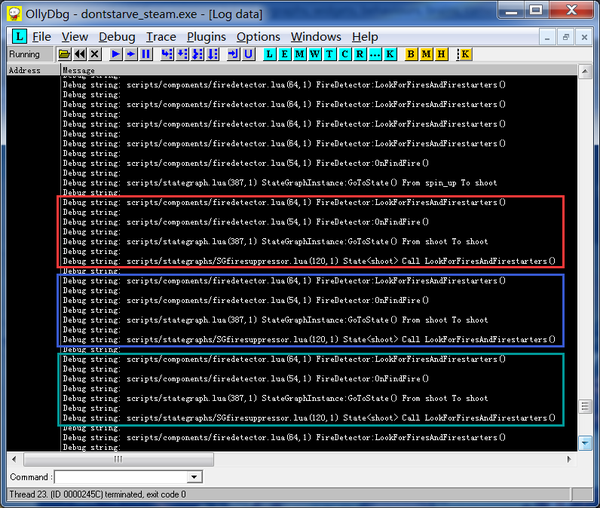
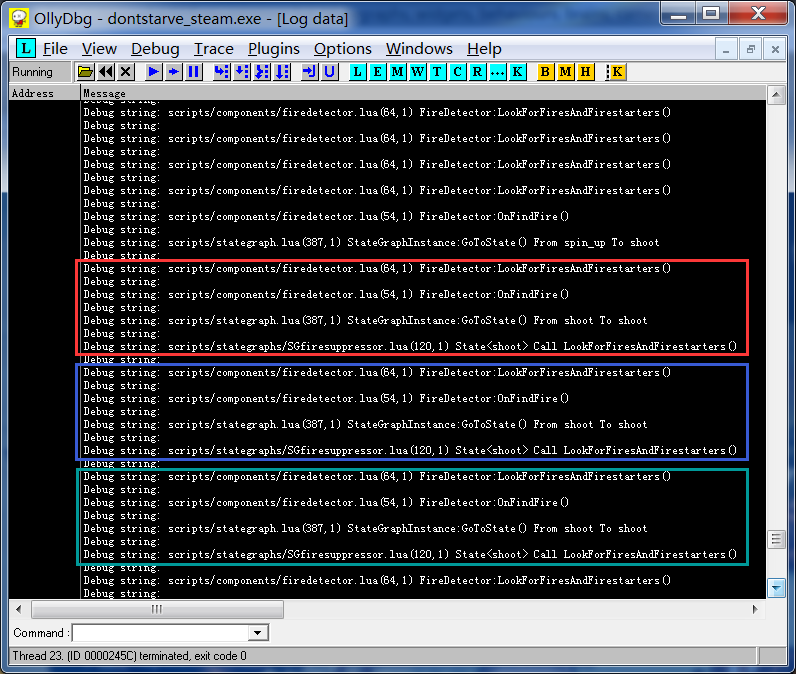
刚开始我一直试图去找出是什么东西触发了雪球连发,然而跟踪了半天却发现一环套着一环的函数调用似乎都没有什么问题。最早的触发源是一个处于FireDetector中的间隔为1s的定时器来调用LookForFireAndFirestarters。但是奇怪的是雪球发射的速度是远远快于1s的(实际为0.3s左右),在安装LuaJIT补丁之后,这个1s定时器也是正常工作的。可见问题并不在这里。
0x16 永动机
这个图中隐含了一个比较重要的信息,那就是每个框里的动作其实并不是单独触发的,下一个框中的LookForFireAndFirestarters其实是上一个框结尾时调用的,也就是说,雪球机连射其实是一个间接的逻辑递归。
LookForFireAndFirestarters的触发点不止一个,而且最初我以为是顺序流程就没在GoToState()进入shoot状态之后跟进代码了。哪知shoot完后下一个状态机被调度的时候,状态机会根据shoot状态再去调用一次LookForFireAndFirestarters()从而形成递归。游戏中雪球之间0.3s的间隔也由此而来。这时栈里不会有形式上递归的痕迹,更不会造成爆栈。并且这个逻辑流程和最初FireDetector那个1s间隔的触发流程交织在一起,大大增加了调试的难度。
那么为什么应用了LuaJIT补丁之后,雪球的连发就没有了呢?我们来看看启用补丁后LOG:
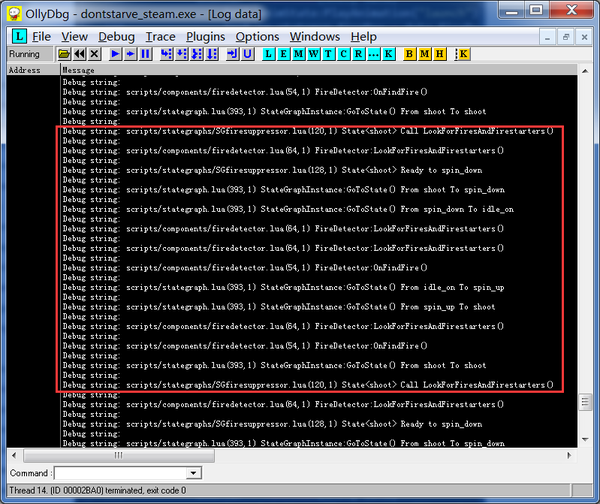
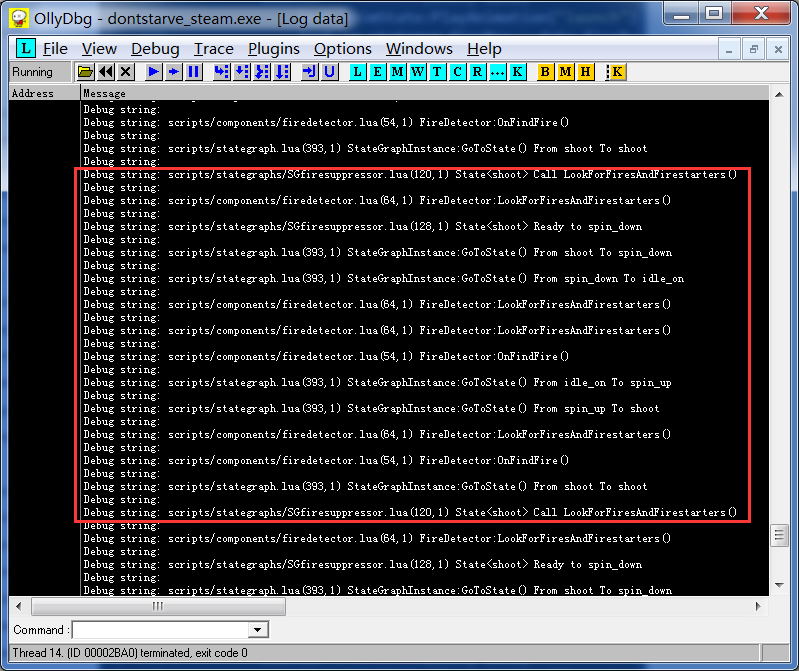
图中红框整个部分才相当于原版LOG图的一个框。可以看出,State<shoot>这个状态莫名其妙走向了spin_down而不是维持在shoot状态,这直接对应着雪球机打一炮休息一下的情况。但是为什么它不维持在shoot状态呢?按照之前的理解,一但通过火情进入了shoot状态,便会驱动递归形成永动机。但是这里明显断气了。
0x17 越狱
从日常生活逻辑推测,雪球机在成功扑灭火焰或者灌溉了作物之后,应该会智能判断下需不需要停止工作。怎么判断呢?自然是判断还有没有火焰或者枯萎的作物:LookForFireAndFirestarters():
function FireDetector:LookForFiresAndFirestarters()
local x,y,z = self.inst:GetPosition():Get()
local priority = 1
local ents = {}
while priority <= #self.YESTAGS and #ents == 0 do
ents = TheSim:FindEntities(x,y,z, self.range, self.YESTAGS[priority], self.NOTAGS)
if #ents > 0 then
local toRemove = {}
for k,v in pairs(ents) do
if self.detectedItems[v] then
table.insert(toRemove, k)
toRemove = table.reverse(toRemove)
for k,v in pairs(toRemove) do
table.remove(ents, v)
--dumptable(ents)
priority = priority + 1
-- ...
end其中YESTAGS是这么定义的:
self.YESTAGS = { --in priority order
{"fire"},
{"smolder"},
{"withered"},
{"witherable"},
{"wildfirestarter"},
{"burnable"},
那么这里的逻辑就很清楚了,通过TheSim:FindEntities这个API按tag查询雪球发射机附近的对象,其中tag是有优先级的,最紧急的当然是正在燃烧的对象,接着是燃烧前闷烧的小火焰,接着的东西就比较重要了,是“已经枯萎的对象”,和“可以枯萎的对象”。
之所以雪球机会对帽贝岩有反应,是因为帽贝岩在一定延迟之后会含有witherable的tag,相关代码在DLC0002\scripts\prefabs\impetrock.lua:129
local variance = math.random() * 4 - 2
inst.makewitherabletask = inst:DoTaskInTime(TUNING.WITHER_BUFFER_TIME + variance, function(inst) inst.components.pickable:MakeWitherable() end)
看到这里大家应该知道了,所谓的“高温”陷阱其实和高温没有关系。只不过是帽贝岩是可枯萎的对象罢了。但是这里许多玩家也许会有人问,如果不是一个岩石比另一块温度高的话,那为什么雪球机只喷其中一个,而不理另外那个呢?
这才是问题的核心。如上面代码所示,在FindEntities之后,会对获取到的列表进行一次筛选,去掉刚刚检测(浇灌)过的对象(.detectedItems)。每个对象在被浇灌过后,就会进入之个detectedItems的列表2秒钟,避免下次被浇灌。
function FireDetector:AddDetectedItem(item)
if self.detectedItems[item] then
return
self.detectedItems[item] = item
self.inst:DoTaskInTime(2, function(inst) self.detectedItems[item] = nil end)
这样的好处是一旦出现大面积火情,雪球就会分配得比较均匀。
所以按理说,只有一个对象需要扑灭或者浇灌的时候,是无论如何也不会引起雪球发射机的连发的。这么一说应用了LuaJIT补丁之后得到的结果才是正确的。
但是为什么在原版里两个都在雪球发射机范围内的帽贝岩会引起连发BUG呢?原因在于,上面LookForFireAndFirestarters中过滤对象的代码有问题:
local toRemove = {}
for k,v in pairs(ents) do
if self.detectedItems[v] then
table.insert(toRemove, k)
toRemove = table.reverse(toRemove)
for k,v in pairs(toRemove) do
table.remove(ents, v)
end起初我觉得这个代码虽然有点蠢但是其实还说得过去。但是搞不好就是这里的问题呢?于是我写了一个正常蠢的代码:
local idx = 1
for k, v in ipairs(ents)
if (not self.detectedItems[v]) then
ents[idx] = v
idx = idx + 1
ents[idx] = nil
功能上讲是等价的。然而替换掉原来的代码之后——原版的连发不见了!
看来问题就在这里。但是按理说reverse过后开始删,k是递减的,应该不会有问题吧……咦,不对,这个table.reverse是哪来的?
突然有点眼生,查了一眼lua api中根本没这个函数。搜下源码,找到了util.lua:100
-- only for indexed tables!
function table.reverse ( tab )
local size = #tab
local newTable = {}
for i,v in ipairs ( tab ) do
newTable[size-i] = v
return newTable
原作者煞有介事地写了一行only for indexed tables的注释。不过很可惜的是,这个代码在原版lua中返回的数组是有问题的。
让我们作个实验。打开lua,输入下面的代码:
t = {};t[1] = 1;t[0] = 0
for k, v in pairs(t) do print(v) end
for k, v in ipairs(t) do print(v) end
输出:
1 0
1再试试下面的代码:
t = {};t[2] = 1;t[1] = 0
for k, v in pairs(t) do print(v) end
for k, v in ipairs(t) do print(v) end
输出:
0 1
0 1所以结论是,在原版lua中,0这个下标是处于hash区域而非array区域的。
然而同样的代码让LuaJIT来跑又不一样:在LuaJIT中,0这个下标处于array区域。
因此,这个代码中newtable[size-i] = v中的size-i导致了问题。如果作者写成size+1-i就不会出错了。这可能是C语言留下来的习惯。(然而为什么要写这么复杂的代码来过滤数组呢……)
真相就在毫厘之间。
这里出错怎么会影响后续的结果呢?还是那段代码,我们接着看:
toRemove = table.reverse(toRemove)
for k,v in pairs(toRemove) do
table.remove(ents, v)
如果遍历toRemove得到的顺序是k = 1, 0的话,那么v的顺序就是1, 2,那么删除ents第一个元素之后,第二个元素就会落到第一个元素的位置。因为2这个下标的元素已经移走,接着的table.remove(ents, 2)其实就没有做任何事情。最后的数组里就会剩下原数组中第二个元素。
所以到这里真相大白。应该被标记为已经浇灌的对象在下次审查中占拒2号位逃过一劫,从而次次被浇灌,雪球发射机也就停不下来了。而LuaJIT的实现恰好能让这个在原版下有BUG的代码跑出正确的结果,从而造成了“高温”陷阱失效的BUG。
那怎么“修复”呢?为了让大家感受到来自BUG的幸福,我在luajit的代码中加了一行,把table.reverse改成了在luajit有同样BUG的版本。
这次可是名副其实的BUG变FEATURE了。
注:哪个对象占2号位是FindEntities返回结果顺序决定的,而FindEntities的结果顺序可能会在存一次档之后发生变动。因此做这个陷阱之后,最好先存个档再读进来,看看是在浇灌哪一个帽贝岩,再在这块岩石上做其他陷阱。
0x18 绘制上的问题
如前文所述,饥荒游戏的性能问题主要是由两方面原因造成的:
1. 脚本逻辑过于冗长复杂
2. 绘制过程低效
替换为LuaJIT引擎主要缓解了问题1,但是要想彻底解决需要修改大量游戏代码,这不是我一个小小的补丁就能解决问题的。在实际的测试当中,虽然脚本引擎卡顿现象得到明显缓解,但是当屏幕上有较多动画对象时,界面依然会非常卡。这是由于问题2所导致的渲染时间变长,逻辑帧必须等待渲染帧导致的。
从现在开始,我将逐步分析和实现问题2的解决方案,以做一个彻底的优化。与前面文章所不同的是,本文的写作和相关代码的编写将是同步进行的,而不是像之前补丁都测试了一个多月才开始总结——因此,我探索的过程可能会走不少弯路,加之要找工作和做毕设,总体完成时间也可能会非常长,所以不要催更哈~
你没看错,饥荒虽然脚本是开源的,但是shaders并没有开源:
这些.ksh都是二进制文件,网上找了半天没有相关的资料,应该是自定义格式的。不过这并不是问题,在glCompileShader调用的时候,不是得乖乖得给咱看原文吗?
于是打开OllyDBG,搜索字符串"anim.ksh",找到一处引用。
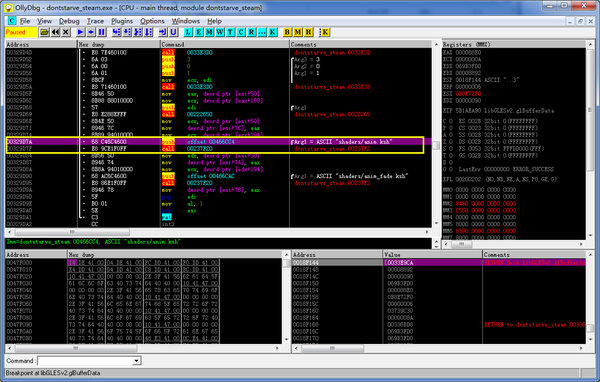
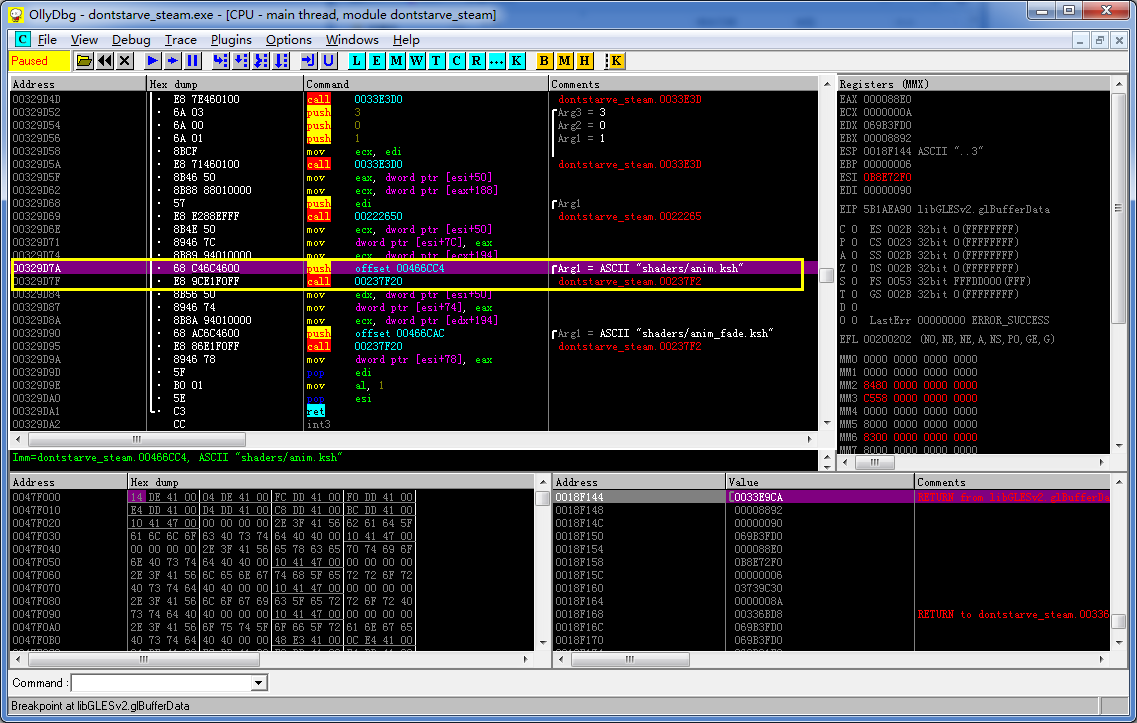
至于怎么解码的其实没有必要关心,我只需要这里下个断点就好了。
运行,命中。然后接着在libGLESv2.dll!glCompileShader上下断点。一般情况,程序是加载一个SHADER文本然后编译一个的,因此这时断在这里就可以看到anim.ksh的明文了~
再运行,命中两次(一次VS,一次FS)。
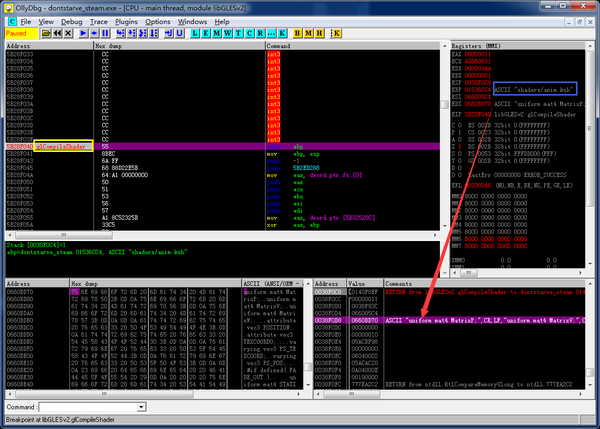
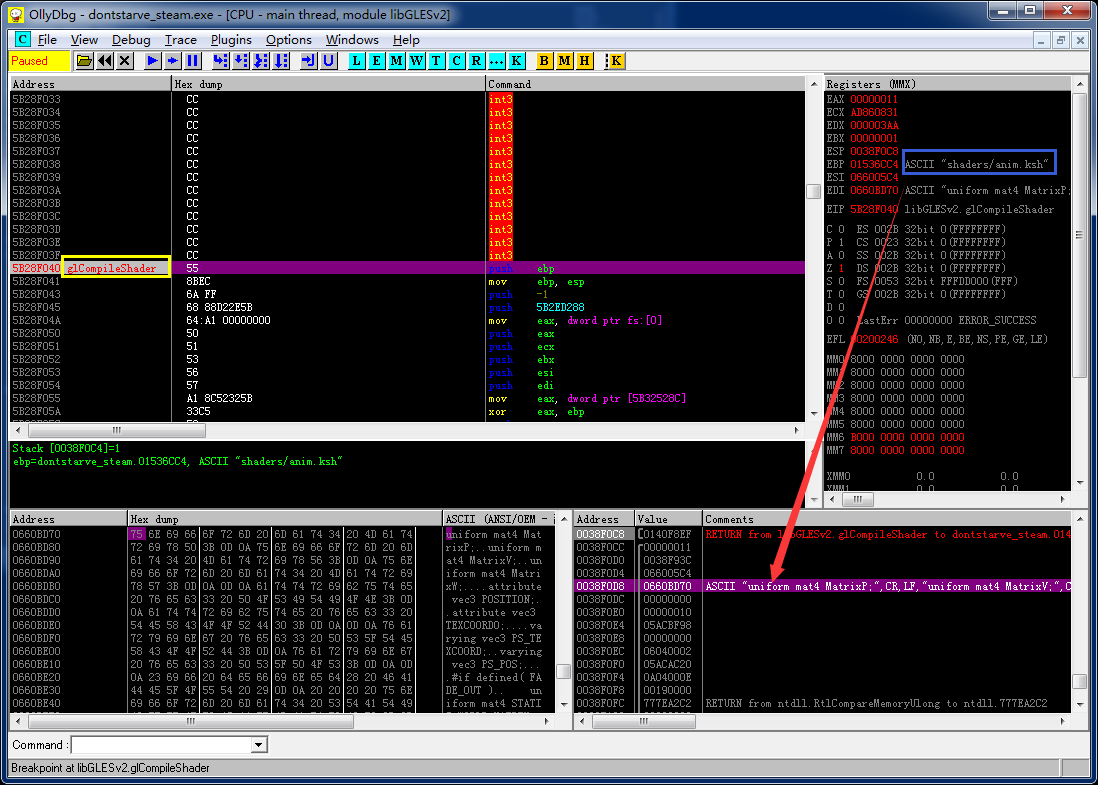
一切顺利,我们顺利导出了shader的文本:
vertex shader:
uniform mat4 MatrixP;
uniform mat4 MatrixV;
uniform mat4 MatrixW;
attribute vec3 POSITION;
attribute vec3 TEXCOORD0;
varying vec3 PS_TEXCOORD;
varying vec3 PS_POS;
#if defined( FADE_OUT )
uniform mat4 STATIC_WORLD_MATRIX;
varying vec2 FADE_UV;
#endif
void main()
mat4 mtxPVW = MatrixP * MatrixV * MatrixW;
gl_Position = mtxPVW * vec4( POSITION.xyz, 1.0 );
vec4 world_pos = MatrixW * vec4( POSITION.xyz, 1.0 );
PS_TEXCOORD = TEXCOORD0;
PS_POS = world_pos.xyz;
#if defined( FADE_OUT )
vec4 static_world_pos = STATIC_WORLD_MATRIX * vec4( POSITION.xyz, 1.0 );
vec3 forward = normalize( vec3( MatrixV[2][0], 0.0, MatrixV[2][2] ) );
float d = dot( static_world_pos.xyz, forward );
vec3 pos = static_world_pos.xyz + ( forward * -d );
vec3 left = cross( forward, vec3( 0.0, 1.0, 0.0 ) );
FADE_UV = vec2( dot( pos, left ) / 4.0, static_world_pos.y / 8.0 );
#endif
可以看到,这里实现得中规中矩:世界坐标是三维的,通过MVP变换得到屏幕坐标。注意Model-View矩阵这里是分开的两个矩阵MatrixV和MatrixW的积,其中MatrixW是模型本身的变换矩阵,MatrixV则是视图矩阵。这样世界坐标就可以直接用MatrixV乘以输入位置而得到,接着传入Fragment Shader。
fragment shader:
#if defined( GL_ES )
precision mediump float;
#endif
uniform sampler2D SAMPLER[4];
#ifndef LIGHTING_H
#define LIGHTING_H
// Lighting
varying vec3 PS_POS;
uniform vec3 AMBIENT;
// xy = min, zw = max
uniform vec4 LIGHTMAP_WORLD_EXTENTS;
#define LIGHTMAP_TEXTURE SAMPLER[3]
#ifndef LIGHTMAP_TEXTURE
#error If you use lighting, you must #define the sampler that the lightmap belongs to
#endif
vec3 CalculateLightingContribution()
vec2 uv = ( PS_POS.xz - LIGHTMAP_WORLD_EXTENTS.xy ) * LIGHTMAP_WORLD_EXTENTS.zw;
vec3 colour = texture2D( LIGHTMAP_TEXTURE, uv.xy ).rgb + AMBIENT.rgb;
return clamp( colour.rgb, vec3( 0, 0, 0 ), vec3( 1, 1, 1 ) );
vec3 CalculateLightingContribution( vec3 normal )
return vec3( 1, 1, 1 );
#endif //LIGHTING.h
varying vec3 PS_TEXCOORD;
uniform vec4 TINT_ADD;
uniform vec4 TINT_MULT;
uniform vec2 PARAMS;
#define ALPHA_TEST PARAMS.x
#define LIGHT_OVERRIDE PARAMS.y
#if defined( FADE_OUT )
uniform vec3 EROSION_PARAMS;
varying vec2 FADE_UV;
#define ERODE_SAMPLER SAMPLER[2]
#define EROSION_MIN EROSION_PARAMS.x
#define EROSION_RANGE EROSION_PARAMS.y
#define EROSION_LERP EROSION_PARAMS.z
#endif
void main()
vec4 colour;
if( PS_TEXCOORD.z < 0.5 )
colour.rgba = texture2D( SAMPLER[0], PS_TEXCOORD.xy );
colour.rgba = texture2D( SAMPLER[1], PS_TEXCOORD.xy );
if( colour.a >= ALPHA_TEST )
gl_FragColor.rgba = colour.rgba;
gl_FragColor.rgba *= TINT_MULT.rgba;
gl_FragColor.rgb += vec3( TINT_ADD.rgb * colour.a );
#if defined( FADE_OUT )
float height = texture2D( ERODE_SAMPLER, FADE_UV.xy ).a;
float erode_val = clamp( ( height - EROSION_MIN ) / EROSION_RANGE, 0.0, 1.0 );
gl_FragColor.rgba = mix( gl_FragColor.rgba, gl_FragColor.rgba * erode_val, EROSION_LERP );
#endif
vec3 light = CalculateLightingContribution();
gl_FragColor.rgb *= max( light.rgb, vec3( LIGHT_OVERRIDE, LIGHT_OVERRIDE, LIGHT_OVERRIDE ) );
discard;
这里手动实现了一个Alpha testing,并且根据PS_TEXCOORD.z来选择是第一张还是第二张纹理。光照部分使用lightmap,但是lightmap的纹理似乎经过颜色下采样处理,在光照强度低的情况下会在游戏里出现比较明显的阶梯状效果。
单单看这里的实现,应该可以排除是shader逻辑复杂导致的卡顿(不过这样一个2D风格的游戏shader能复杂到哪里去呢)。
0x19 马儿要吃草
那还可能会在哪里卡呢?我猜想问题很大程度上没有出在GPU,而在于向显卡传输数据的这一过程中。太多太多的游戏有这样的问题了——比如当年Minecraft的VBO惨案。
那么下一步就很明确了,在glVertexAttribPointer下断点:
还好试了几次,第六个参数pointer的值都是NULL。这说明饥荒还是绑定了VBO的,不像某游戏那样在渲染时一个一个地指定。
但是为什么还是慢呢?我把目光投向了另外两个事故高发区:
glBufferData/glBufferSubData:

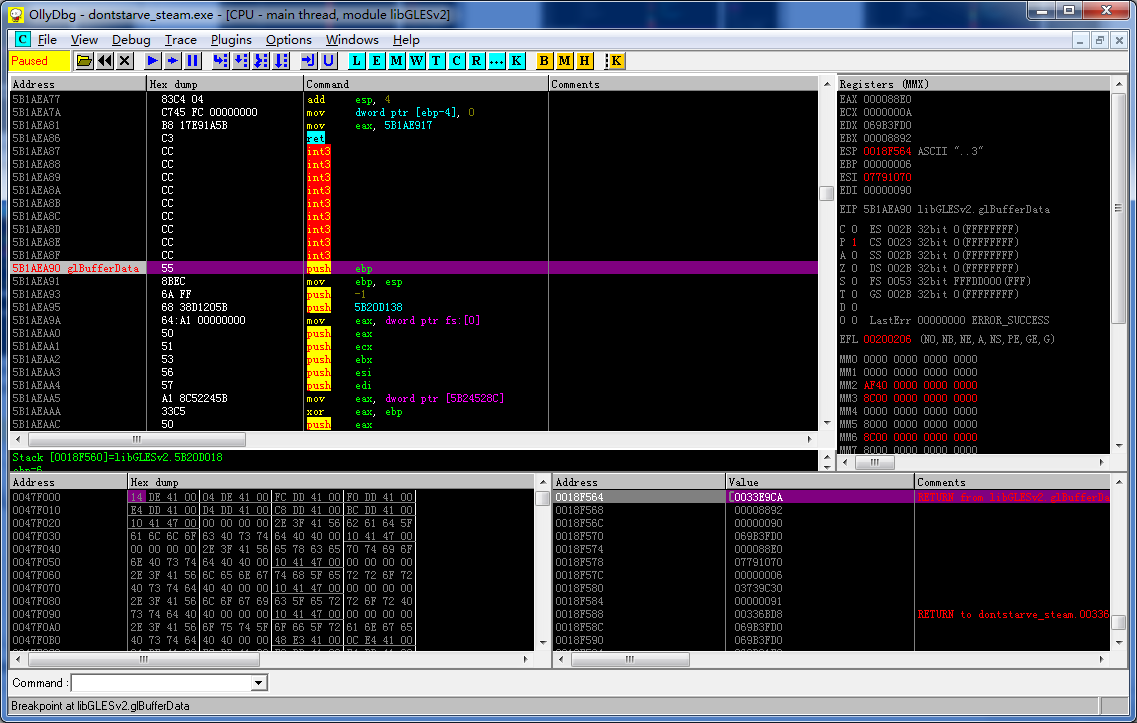
问题终于浮出了水面。原来,即使是在游戏刚开始的没有任何动态元素的MODS界面,这个glBufferData仍然会不断地命中。这充分说明饥荒游戏就算画个固定不变的窗口,其所用的窗口坐标缓冲区也是每一帧的时候重新填充的……
而且他们用的是glBufferData而不是glBufferSubData……后者从始至终一次也没命中过……
我们可以设想一个情景,当屏幕上有几千个活动对象的时候,每一帧都会有几千次的glBufferData的调用重建缓冲区,而绘图指令需要等待数据传输完毕之后才能开始渲染。而进一步的跟踪表明,glBufferData和glDrawArrays的调用是交替进行的。
那么,是不是每个对象在绘制的时候,都对应单独的一条glDrawArrays呢?答案是否定的。调用glDrawArrays所指定的大小有几百之多,而且每次都不尽相同。但是有大量对象都是拥有相同的大小的,这说明每个对象也是分开绘制的。
因此我们的优化就可以从这个地方入手了——尝试解析glBufferData中数据的规律,看看是否能够减少直接的glBufferData调用,以起到缓解总线压力、减少同步状态的作用。另外如果可能的话减少glDrawArrays的使用(不过没有instanced draw的情况下太难了)。
使用API HOOK挂上glGenBuffers, glDeleteBuffers, glBufferData之后,我发现问题比我想的还要糟糕——所有的buffer连同ID在渲染的时候都是即时分配的,用完就删。这能快起来才有鬼呢==(虽然glGenBuffers的实际操作也就是分配个数字而已)
那怎么办呢?看来比较有希望的办法就是自己做一个中间层,把Buffer ID的分配,回收都接管起来。我们希望某些buffer在删除的时候不作OpenGL层的删除,仅仅在我们的bitmap表里将其删除。下一次这个buffer再用的时候直接用OpenGL层中内容相同的buffer即可,这样可以避免重新传数据。
但是这里有个麻烦事:
需要复用缓冲的时候,怎么才能知道是哪一个buffer里的数据和当前要传输的数据是相同的从而复用它呢?
这就是我说的“糟糕”的地方。如果原来的游戏程序里Buffer ID是事先分配好并绑定到具体对象的,这个映射关系就不需要我们来维护了。而现在每一帧的Buffer ID都是重新分配的,从逻辑上讲前后两帧的ID之间并无实际联系,那我们怎么才能迅速定位到需要的buffer呢?更进一步,由于我们不知道一份数据是否会被之后的访问用到,所以每个opengl buffer都需要一段时间无访问后及时释放,以避免对象泄漏。
0x1A 有简单的复用办法吗?
目前的结论比较杯具,但是也得慢慢来。
一个简单的想法是,所有的buffers都不删除,然后模仿OpenGL的Buffer ID分配策略(看了下在我的机子上是栈式的回收策略)制作一个中间层。这样,如果渲染流程比较理想和稳定,前后两帧之间相同的对象应该差不多能分配到相同ID的buffers,这时候只需要比较下新来的数据和原本buffer里存的是否相同就可以决定是否要提交更改:
void _stdcall Proxy_glBufferData(int target, int size, const void *data, int usage) {
if (currentBufferID >= bufferData.size()) {
bufferData.resize(currentBufferID * 2 + 1);
CachedBuffer& buffer = bufferData[currentBufferID];
int orgTarget = buffer.target;
std::string& lastData = buffer.data;
int lastSize = lastData.size();
bool canCache = orgTarget == target && data != NULL && size == lastSize && memcmp(data, lastData.c_str(), size) == 0;
// printf("%s\n", canCache ? "CACHE!" : "LOAD!");
if (!canCache) {
((PFNGLBUFFERDATAARBPROC)(PROC)hook_glBufferData)(target, size, data, usage);
buffer.target = target;
if (data == NULL) {
lastData.clear();
} else {
lastData.assign((const char*)data, size);
但是简单试了下发现问题非常大。实际的情况是相同的对象在两次渲染之中基本不可能分配到相同的buffer id,跑了一下cache命中率只有5%-10%,这就没什么搞头了。
0x1B 重新实现ID分配器
那么,既然buffer生成的顺序不固定,那么根据数据HASH而不是固有的buffer id来区分不同的buffer成了唯一的路。这个想法更复杂也更容易实现得比较低效,反而有可能还不如什么都不做。不过总得试试看吧。
首先要实现一个自己的中间层ID分配器,对于游戏程序而言,中间层ID可以当作是OpenGL Buffer ID来使用,但是我们内部还需要管理中间层ID到真正OpenGL Buffer ID:
struct BufferID {
BufferID() : glBufferID(0), nextFreeIndex(0) {}
int glBufferID;
int nextFreeIndex;
unsigned int currentFreeIndex = 0; // 0 is reserved
void _stdcall Proxy_glGenBuffers(int n, unsigned int* buffers) {
while (n-- > 0) {
if (currentFreeIndex != 0) {
unsigned int p = currentFreeIndex;
*buffers++ = p;
currentFreeIndex = bufferIDs[p].nextFreeIndex;
bufferIDs[p].nextFreeIndex = 0;
} else {
// generate new one
*buffers++ = bufferIDs.size();
bufferIDs.push_back(BufferID());
void _stdcall Proxy_glDeleteBuffers(int n, const unsigned int* buffers) {
for (int i = 0; i < n; i++) {
unsigned int id = buffers[i];
bufferIDs[id].nextFreeIndex = currentFreeIndex;
currentFreeIndex = id;
// ((PFNGLDELETEBUFFERSARBPROC)(PROC)hook_glDeleteBuffers)(n, buffers);
delete buffers的时候通过nextFreeIndex这个域形成一个链表,可以方便下一次的分配。glBufferID是对应于关联底层OPENGL BUFFER ID的,在这里我们不在GenBuffers的时候就直接生成OpenGL BufferID,以便于我们在glBufferData时从缓存中选择一个选择的OpenGL BufferID与之关联。
0x1C 缓存的实现
unsigned int currentBufferID = 0;
struct BufferRef {
BufferRef() : ref(0), nextFreeIndex(0) {}
int ref;
int nextFreeIndex;
std::tr1::unordered_map<std::string, unsigned int>::iterator iterator;
std::vector<BufferRef> bufferRefs;
unsigned int currentFreeBufferRef = 0;
std::tr1::unordered_map<std::string, unsigned int> mapDataToBufferID;
void _stdcall Proxy_glBindBuffer(int target, unsigned int buffer) {
currentBufferID = buffer;
((PFNGLBINDBUFFERARBPROC)(PROC)hook_glBindBuffer)(target, bufferIDs[currentBufferID].glBufferID);
void _stdcall Proxy_glBufferData(int target, int size, const void *data, int usage) {
std::string content((const char*)data, size);
content.append(std::string((const char*)&target, sizeof(target)));
std::tr1::unordered_map<std::string, unsigned int>::iterator p = mapDataToBufferID.find(content);
if (p != mapDataToBufferID.end()) {
unsigned int id = p->second;
((PFNGLBINDBUFFERARBPROC)(PROC)hook_glBindBuffer)(target, id);
CheckRef(id);
// printf("REUSE!!!! %d\n", id);
} else {
// Allocate gl buffer id
unsigned int id = 0;
if (currentFreeBufferRef != 0) {
id = currentFreeBufferRef;
currentFreeBufferRef = bufferRefs[id].nextFreeIndex;
} else {
((PFNGLGENBUFFERSARBPROC)(PROC)hook_glGenBuffers)(1, &id);
if (bufferRefs.size() <= id) {
bufferRefs.resize(id + 1);
((PFNGLBINDBUFFERARBPROC)(PROC)hook_glBindBuffer)(target, id);
((PFNGLBUFFERDATAARBPROC)(PROC)hook_glBufferData)(target, size, data, usage);
// connect
CheckRef(id);
bufferRefs[id].iterator = mapDataToBufferID.insert(std::make_pair(content, id)).first;
// printf("ALLOCATE!!!! %d\n", id);
glBufferData需要实现两种情形,一种是我们所请求的数据正好在缓存中可以找到,那么一切就简单了,直接将找到的OpenGL bufferID关联到中间层ID上。
如果缓存中没有,则需要新选一个OpenGL BufferID绑定到中间层ID,并且调用原始的glBufferData更新数据,这里有两个问题需要解决:
1. 如何选择OpenGL BufferID
在我的实现里,OpenGL BufferID和中间层ID一样,也是可回收的。先看看回收池中有没有剩余的ID可用,有则顶上;没有的话就用原始的glGenBuffers新生成一个。
2. 如何避免选中正在使用的OpenGL BufferID
哪些OpenGL BufferID会被收进回收池呢?自然是应用程序不再使用的。但是游戏本身用的是中间层ID,我们需要其他办法来记录使用情况。在这里我直接为每个OpenGL BufferID的数据结构BufferRef添加了ref这个域用于记录其被中间层ID引用的引用计数,如果计数归零就链入通过nextFreeIndex连接的链表中。
目前的实现中,我没有使用glDeleteBuffers删除过已经创建的缓冲。在饥荒游戏这个特殊的情况下,这样做比较省事,因为实际的OpenGL Buffer ID是有限的,并不会无限涨下去,因此在程序退出时让RenderContext自己处理掉好了~
0x1D 测试计划
我采用Visual Studio 2015自带的Performance Profiler来跟踪饥荒游戏的运行情况。游戏配置如下:
1. 存档:一个Shipwrecked DLC的存档,季节为飓风季,测试时间从游戏时间的入夜到第二天天亮,伴有狂风、大雨和高频率的闪电。之所以选择这样的设定,是因为在我的正常游戏体验中,这种情况下是最卡的。以前我往往通过控制台在屏幕上刷出大量生物来制造卡顿,但是这种卡顿瓶颈单一,不能有效检测出其他卡顿的原因,而且这种卡也一般不是正常游戏过程中所能遇到的。
2. 游戏版本:新下载的某网站盗版饥荒游戏172748版(大约是2016年6月份左右的版本)。选用这个版本也是没有办法,因为我的Steam正版饥荒在启动时,如果不是由Steam启动的,将会退出并通知Steam来启动自己。这样Visual Studio 2015的Profiler就没办法测到游戏运行过程中的数据了。由于正版饥荒在运行时还会和Steam之间有通信(比如ALT+TAB打开的界面),因此通过hack的办法让它无视父进程而进入游戏可能会有问题。
3. MODS:一般的常用mods,包括几何学、行为队列、智能锅、小地图、建筑标记等。
4. 测试计划:分为四种情况进行测试:
1) 不开启luajit以及gl优化
2) 只开启gl优化
3) 只开启luajit
4) 开启luajit以及gl优化
5. 为了有效对比lua和luajit的性能,在测试原版lua的时候,我也像luajit那样进行了hook,只不过把lua51.dll重命名为luajit.dll,这样所有的lua请求就可以重定向到原版lua里了。
6. Visual Studio 2015 Performance Profiler: CPU sampling
0x1E 小地图要坏大事情
在最初的测试中,我发现一个比较奇怪的情况,那就是dontstarve_steam.exe的占用有点异常地高,而gles和luajit的占比较低,只有个位数。经检查发现:
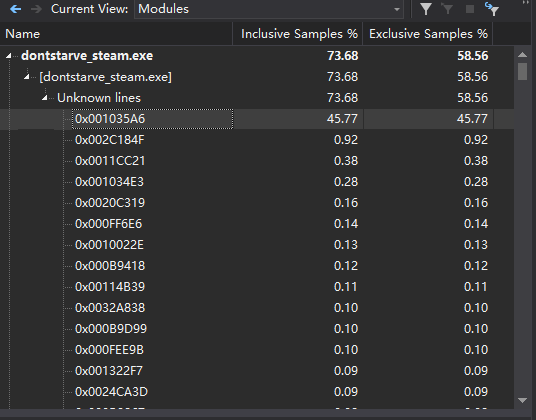
dontstarve_steam.exe有个名字为0x1035A6的函数居然占用了总CPU采样的45.77%!这个函数是做什么的呢?
打开OllyDBG看一下:
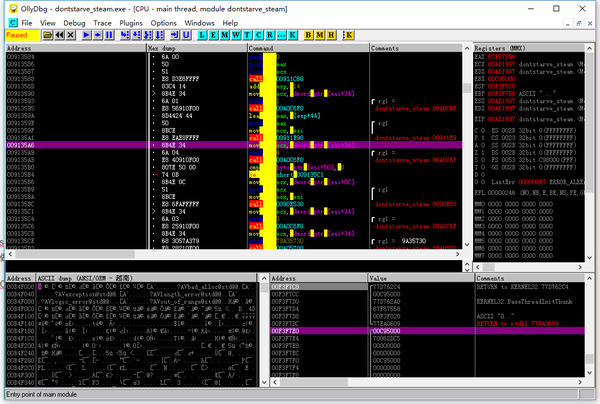
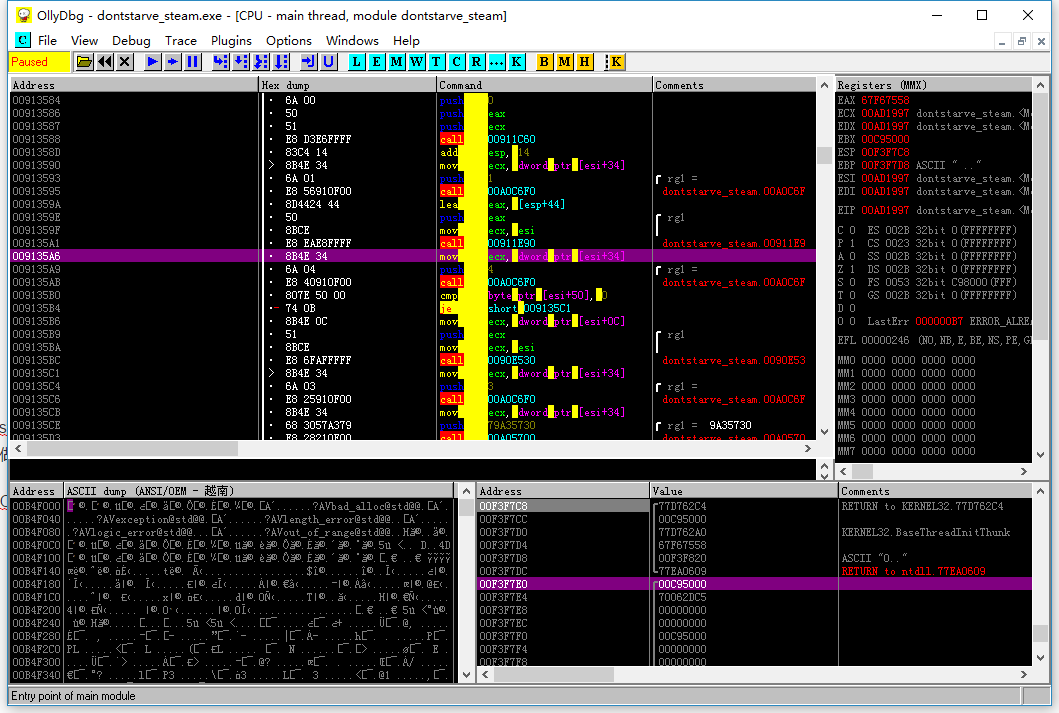
(由于每次dontstarve_steam.exe加载的基地址不一样,所以0x1035A6得先加上基地址差才能得到本次的地址)
这并不是一个函数的开头,但是却像是一个返回地址。我们知道函数首地址在堆栈中是不存的,存的是调用时的返回地址。因此这个0x1035A6(0x9135A6)实际上代表的是上一行call指令调用的函数。
那么进入这个函数看看:
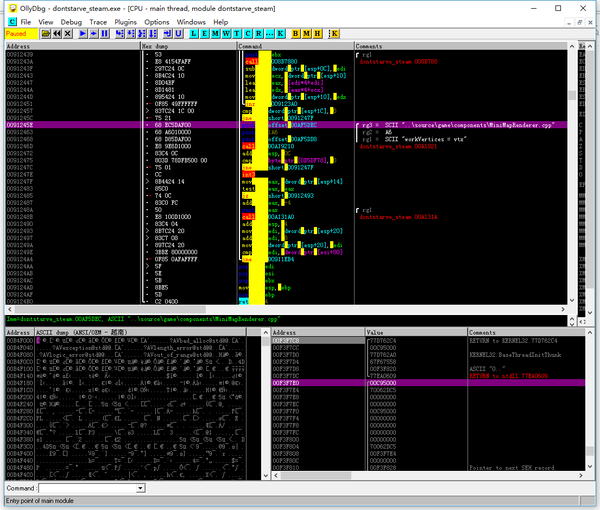
这个函数比较长,而且充斥着大量浮点和循环指令。从这点推测应该是一个比较复杂的CPU端的计算函数。果然在函数的最后,一条用于打印调试信息的字符串透露出这个函数所在的源文件名叫MiniMapRenderer.cpp。也就是说,这个负责在CPU上渲染小地图的函数占去了大量CPU时间。
在原版饥荒中,按TAB键可以呼出小地图。但是按道理它不应该这么频繁地被调用,唯一的可能就是小地图MOD使用了这个函数来频繁渲染Minimap(因为要实时更新地图上的单位变化情况),并且以HUD的方式常显在了游戏界面。
进入游戏后关掉小地图显示,果然再测时这个函数就不占用那么高的CPU了。以后会考虑优化这个函数,毕竟Minimap MOD还是非常方便好用的~
0x1F 性能报告
重新测试并输出报告如下:
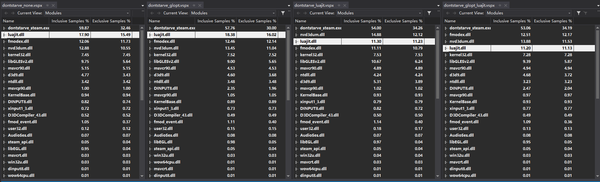
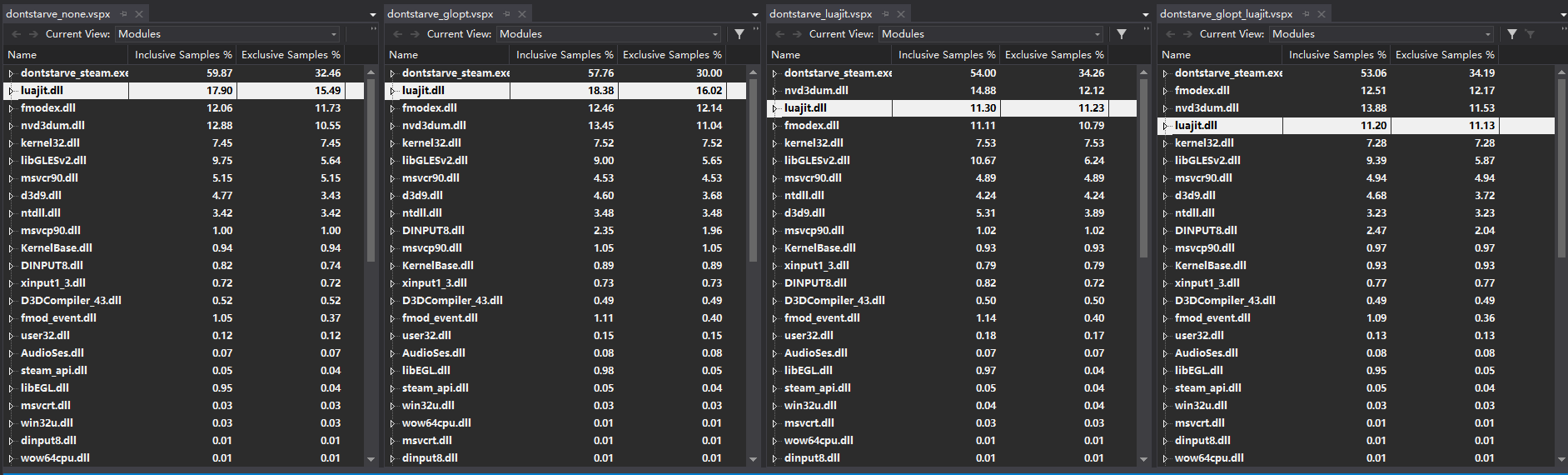
(从左到右分别为不启用luajit及gl优化、只启用gl优化、只启用luajit、启用luajit及gl优化)
可以看出,在启用luajit之前,脚本引擎部分使用的样本数为15.7%左右,启用后为11.2%左右,也就是脚本部分的性能提升约40%。当然在我的测试场景为了能检测到尽可能多的性能问题,活动脚本所占用的比例并不高。
GL的优化在这张图上似乎看不到效果。因为我只优化了buffer数据的传输,没有实质地减少glDrawArrays的调用,因此nvd3dum的占用还是非常高。
比较意外的是fmodex.dll居然占用了12%的采样。fmodex.dll是 FMOD 音效引擎的模块,用于播放和实时混缩fsb格式的音乐。测试场景中的雨声和雷声不断,导致此模块被频繁调用。虽然fmodex在非雷雨场景中CPU比例几乎为0,但是在雷雨中能占到12%的CPU采样比重还是比较神奇的,有空再研究。
dontstarve_steam.exe中指向的入口地址为0x8B4560函数占用了其几乎全部的采样,用OllyDBG看了一眼,这个就是饥荒游戏的主消息循环。
这次的性能测试发现了很多以前没注意到的细节,就目前而止,性能问题主要有以下几个:
1. glDrawArrays等GL函数频繁调用,使得nvd3dum.dll的使用率很高。
2. Minimap MOD在绘制小地图HUD时频繁调用饥荒的DrawMinimap函数,导致性能急剧下降。我后来专门针对它测试了几次,它占用的时间甚至是luajit的1.5倍,和lua引擎本身的耗时都差不多。
3. FMODEX音效模块在雷雨天气时非常吃CPU。
4. Lua代码自身的性能问题。
0x20 暗号
当我刚开始制作DST版本的饥荒LuaJIT补丁时,为了保证最大限度的兼容,要求用户在服务器和客户端上都启用补丁。但是实际的情况往往是,很多服务器并不在玩家的控制之中(如一些联机平台提供的服务器),而且大量服务器使用了linux版的饥荒。因此为了扩宽补丁的适用范围,需要对原版饥荒进行兼容,使得服务器不使用LuaJIT补丁时,使用了补丁的客户端也能够正常和服务器通讯。
按照之前文章的描述,Lua和LuaJIT不兼容的地方已经被修复了很多,然而在这些修复都完成之后,带有LuaJIT补丁的客户端仍然不能正确和服务器通讯,具体的表现是,非服务器的一方将不能正确通过鼠标拾取物品或者采集资源(键盘可以)、吃食物、调整物品栏物品的顺序、扔下物品、将物品给予他人等。
之前我曾经在 饥荒游戏扫雷笔记(一)|脚本引擎篇——LuaJIT的救赎(合集) - paintsnow的文章 - 知乎专栏 (0x0D 鬼使神差) 一文中提到过因为对象成员遍历顺序不一致导致RPC code不一致的问题。然而当我再次查看RPC列表时,却发现即使我把string hash的算法改成一样的,LuaJIT和Lua所生成的RPC列表也是有一点点不同的:
启用了LuaJIT补丁后的饥荒:

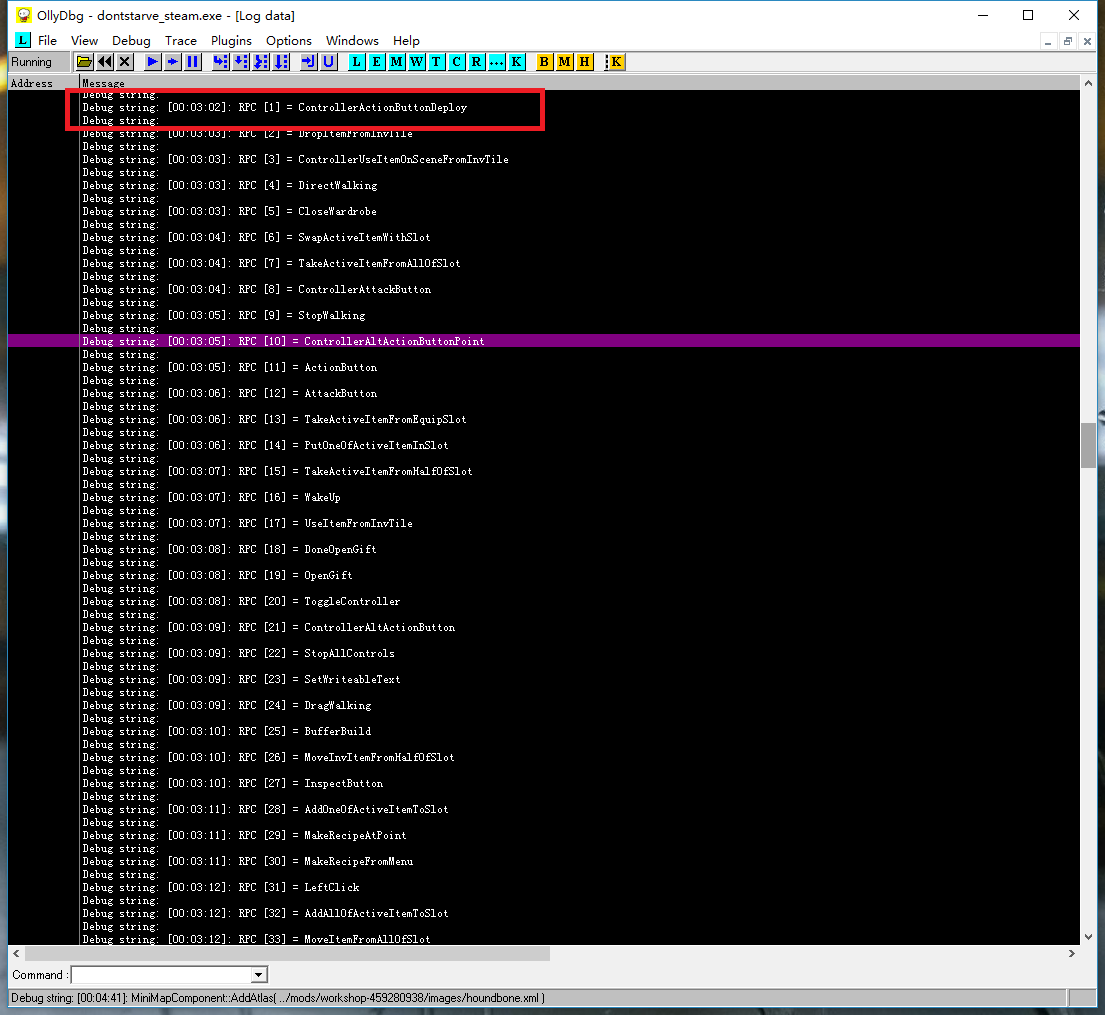
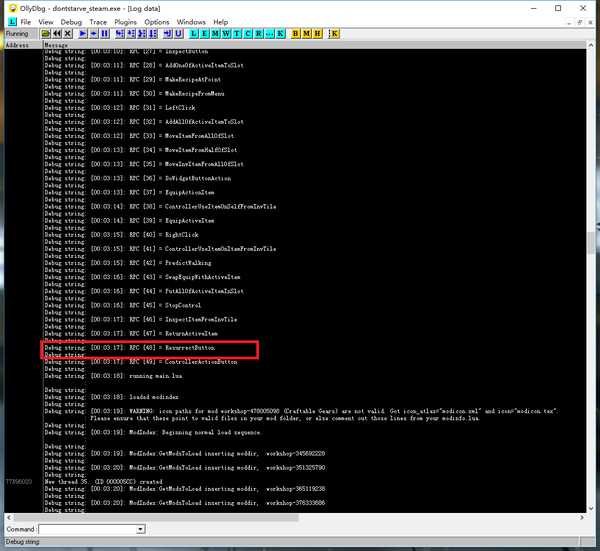
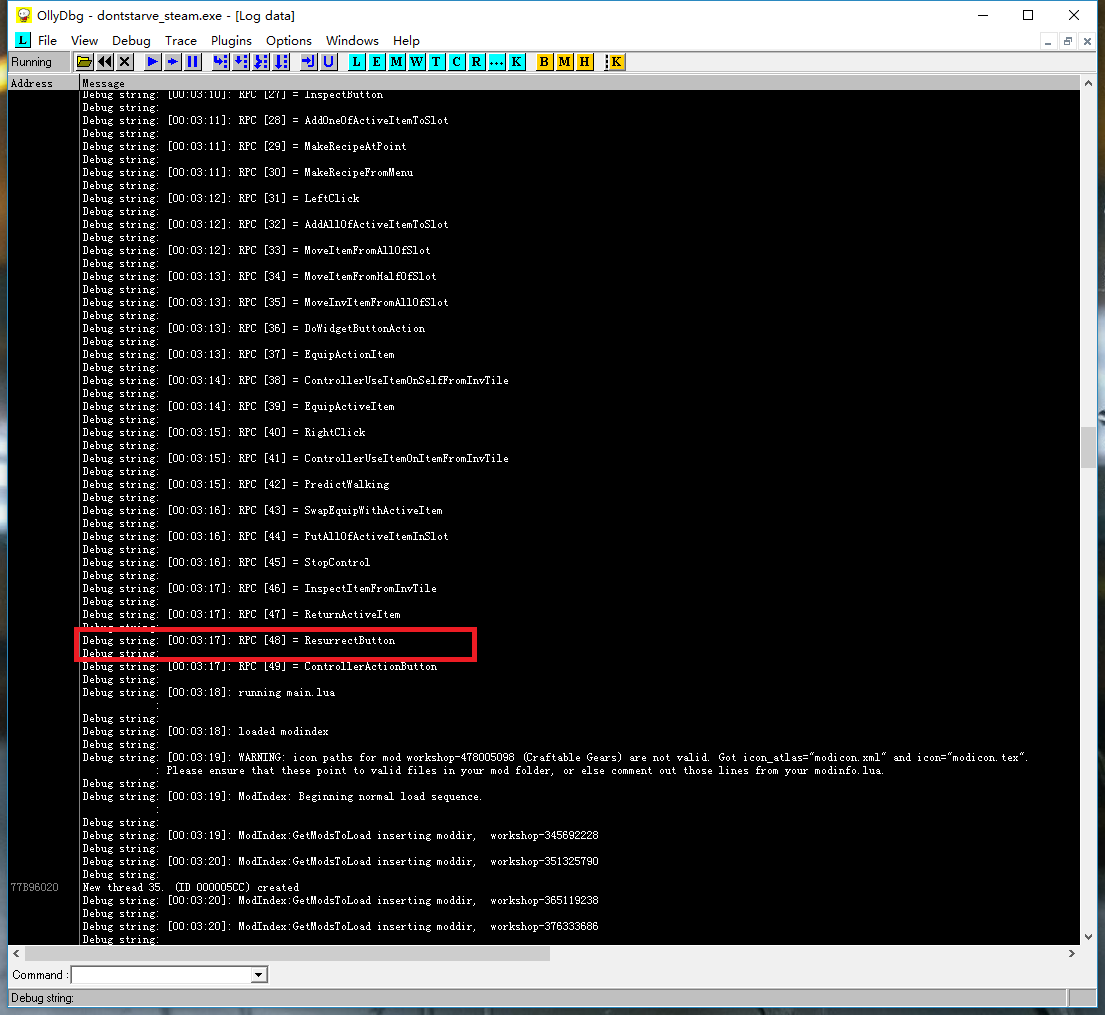
原版饥荒:
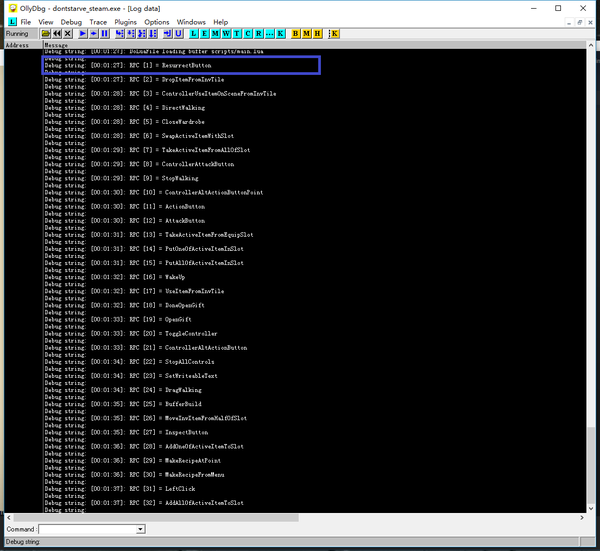
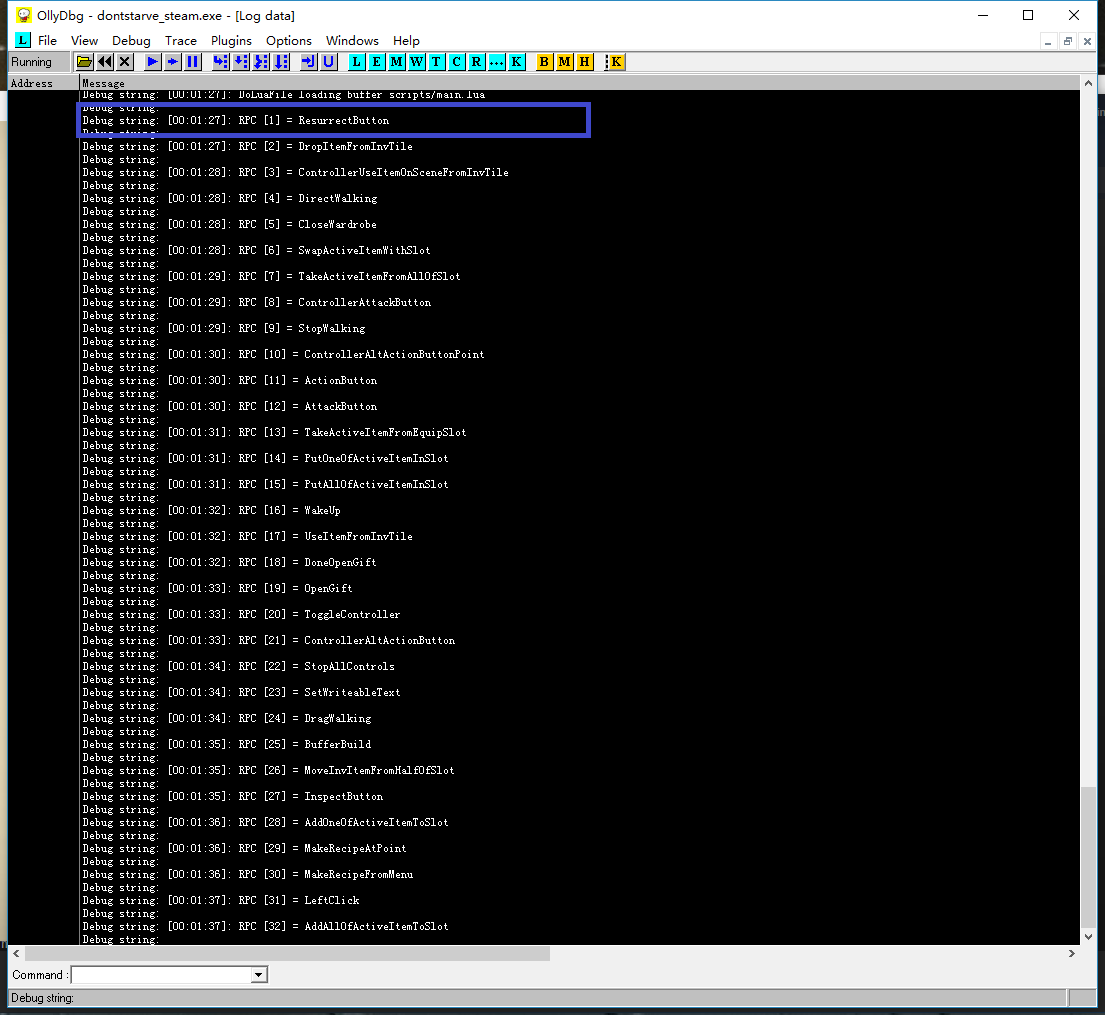
全部49个RPC调用中,绝大多数都是匹配的,惟独第1和第48号所对应的服务函数在LuaJIT和Lua中正好对调了一下。是不是就因为这两个函数导致了如前所述的问题呢?
答案是否定的,即使我用硬编码把两者的顺序强行指定一下,上面的问题一个也不会少。仔细研究了下出问题的这两个函数恰好是不重要的两个函数,和问题中所提到的那些操作都是没有关系的。难道传递这些操作还需要核对什么隐藏的暗号吗?
0x21 表象
那么,既然连相同的string hash算法都没有办法得到相同的表,那么很可能有其他地方也用到了类似的ID分配策略。研究了一阵,发现两处问题所在:
一个是在scripts\actions.lua中:
ACTIONS =
REPAIR = Action({ encumbered_valid=true }),
READ = Action({ mount_valid=true }),
DROP = Action({ priority=-1, mount_valid=true, encumbered_valid=true }),
TRAVEL = Action(),
... 中间省略
SADDLE = Action({ priority=1 }),
UNSADDLE = Action({ priority=3, rmb=false }),
BRUSH = Action({ priority=3, rmb=false }),
ACTION_IDS = {}
for k, v in pairs(ACTIONS) do
v.str = STRINGS.ACTIONS[k] or "ACTION"
v.id = k
table.insert(ACTION_IDS, k)
v.code = #ACTION_IDS
end另一处在scripts\componentactions.lua
local COMPONENT_ACTIONS =
... 省略
POINT = --args: inst, doer, pos, actions, right
blinkstaff = function(inst, doer, pos, actions, right)
if right and TheWorld.Map:IsAboveGroundAtPoint(pos:Get()) then
table.insert(actions, ACTIONS.BLINK)
end,
complexprojectile = function(inst, doer, target, actions, right)
if right then
table.insert(actions, ACTIONS.TOSS)
end,
EQUIPPED = --args: inst, doer, target, actions, right
brush = function(inst, doer, target, actions, right)
if not right and target:HasTag("brushable") then
table.insert(actions, ACTIONS.BRUSH)
end,
INVENTORY = --args: inst, doer, actions, right
balloonmaker = function(inst, doer, actions)
if doer:HasTag("balloonomancer") then
table.insert(actions, ACTIONS.MAKEBALLOON)
end,
book = function(inst, doer, actions)
if doer:HasTag("reader") then
table.insert(actions, ACTIONS.READ)
end,
ISVALID = --args: inst, action, right
workable = function(inst, action, right)
return (right or action ~= ACTIONS.HAMMER) and
inst:HasTag(action.id.."_workable")
end,
local ACTION_COMPONENT_NAMES = {}
local ACTION_COMPONENT_IDS = {}
local function RemapComponentActions()
for k, v in pairs(COMPONENT_ACTIONS) do
for cmp, fn in pairs(v) do
if ACTION_COMPONENT_IDS[cmp] == nil then
table.insert(ACTION_COMPONENT_NAMES, cmp)
ACTION_COMPONENT_IDS[cmp] = #ACTION_COMPONENT_NAMES
RemapComponentActions()
RPC ID不是唯一的区分不同操作的ID,有些RPC请求中会有部分数据要依赖于刚才这两个表中的动作ID。而经过测试这两个表里面ID乱得是比较严重的——LuaJIT和Lua的遍历结果差得十万八千里。而且从其内容来看,也与有问题的操作相关。看到这里心里差不多就能肯定它就是我们要找的目标了。
那么怎么改呢?硬编码这些数据并且在luajit加载对应模块时作替换吗?全局表或许可以,但是local定义的局部表是比较麻烦的。一方面,局部表只作为upvalue被函数引用,从加载后的模块中找到这个表比较困难。另一方面,lua/luajit的parser在加载代码的时候不会把整个文件读进来,而是由On Demand方式的loader进行加载的,这样试图从中截取到local xxxx = {}这样的定义并修改是很难做得比较健壮的。
还有一个问题,我们即使能够通过hack的办法让这两个表拥有正确的哈希顺序,也不能根本性地解决这个问题。毕竟其他现有代码也有可能触发这个问题,而随着游戏更新和MOD的加入,也不保证新的代码能绕过这些坑。
看来只有从源头上解决这个问题了。
0x22 根源
那么排除了string hash算法的影响之后,还有哪些因素会影响到遍历表的顺序呢?
1. 对hash取的模/掩码
由于hash值通常是一个较大的整数,那么往哈希表中放的时候需要先对一个数(通常是表大小)取模。Lua和LuaJIT取的模都是2^n,实现完全一样。
2. 初始表的哈希部分大小
某些情况下初始表LuaJIT要大一些(256),但是改成相同的值并不能解决问题
3. 哈希表的冲突解决方案
两者采用的方案都是维护一个从尾开始的“空余项指针”,在冲突之后优先从这里分配。所有HASH相同的项都会通过链表串起来。
4. 重哈希的策略
重哈希都是扩展为原来两倍大小,并且按hash顺序装填原有元素。所不同的是Lua是hash逆序遍历原有元素,而LuaJIT是顺序遍历的。但是把LuaJIT也改成逆序之后,LuaJIT的结果和上次不同了,但是和Lua的结果还是不一样。
5. 删除键值的策略
出现问题的表是直接用初始化列表构造的,不存在删除的问题。因而也不会是这个原因。
6. 用初始化列表构造时的策略
在排除了以上5种可能之后,我终于发现了线索。线索的发现过程非常漫长(花了一天多),也走了很多弯路,为了节约笔墨就不写是怎么发现的了。为了便于说明这种情况,我举个例子,这样的代码:
local RPC_HANDLERS =
LeftClick = function()
end,
RightClick = function()
end,
ActionButton = function()
end,
AttackButton = function()
end,
InspectButton = function()
end,
ResurrectButton = function()
end,
ControllerActionButton = function()
end,
ControllerActionButtonDeploy = function()
end,
ControllerAltActionButton = function()
end,
local i = 1
for k, v in pairs(RPC_HANDLERS) do
print("RPC [" .. i .. "] = " .. k)
i = i + 1
i = nil
print("-----------------------------------")
local RPC_HANDLERS2 =
RPC_HANDLERS2.LeftClick = function()
RPC_HANDLERS2.RightClick = function()
RPC_HANDLERS2.ActionButton = function()
RPC_HANDLERS2.AttackButton = function()
RPC_HANDLERS2.InspectButton = function()
RPC_HANDLERS2.ResurrectButton = function()
RPC_HANDLERS2.ControllerActionButton = function()
RPC_HANDLERS2.ControllerActionButtonDeploy = function()
RPC_HANDLERS2.ControllerAltActionButton = function()
local i = 1
for k, v in pairs(RPC_HANDLERS2) do
print("RPC [" .. i .. "] = " .. k)
i = i + 1
i = nil
在lua5.1.4下的输出为:
RPC [1] = AttackButton
RPC [2] = ControllerActionButtonDeploy
RPC [3] = ControllerActionButton
RPC [4] = ResurrectButton
RPC [5] = RightClick
RPC [6] = ControllerAltActionButton
RPC [7] = LeftClick
RPC [8] = InspectButton
RPC [9] = ActionButton
-----------------------------------
RPC [1] = AttackButton
RPC [2] = ControllerActionButtonDeploy
RPC [3] = ControllerActionButton
RPC [4] = ResurrectButton
RPC [5] = ActionButton
RPC [6] = ControllerAltActionButton
RPC [7] = LeftClick
RPC [8] = RightClick
RPC [9] = InspectButton
而LuaJIT 2.0的输出为:
RPC [1] = ControllerAltActionButton
RPC [2] = ActionButton
RPC [3] = ControllerActionButtonDeploy
RPC [4] = RightClick
RPC [5] = InspectButton
RPC [6] = AttackButton
RPC [7] = LeftClick
RPC [8] = ResurrectButton
RPC [9] = ControllerActionButton
-----------------------------------
RPC [1] = ControllerAltActionButton
RPC [2] = ActionButton
RPC [3] = ControllerActionButtonDeploy
RPC [4] = RightClick
RPC [5] = InspectButton
RPC [6] = AttackButton
RPC [7] = LeftClick
RPC [8] = ResurrectButton
RPC [9] = ControllerActionButton
可以看出,除了lua 5.1.4在面对初始化列表构造以外,其余的三个结果都是相同的。这说明lua 5.1.4在面对初始化列表构造时的策略和先构造一张表,再一个个添加项目时的处理是不一样的。而LuaJIT无论是哪种构造,都是先构造一张表,再一个个添加项目的。
lua 5.1.4作了什么处理呢?我们来看代码:
lparser.c:
static void constructor (LexState *ls, expdesc *t) {
/* constructor -> ?? */
FuncState *fs = ls->fs;
int line = ls->linenumber;
int pc = luaK_codeABC(fs, OP_NEWTABLE, 0, 0, 0);
struct ConsControl cc;
cc.na = cc.nh = cc.tostore = 0;
cc.t = t;
init_exp(t, VRELOCABLE, pc);
init_exp(&cc.v, VVOID, 0); /* no value (yet) */
luaK_exp2nextreg(ls->fs, t); /* fix it at stack top (for gc) */
checknext(ls, '{');
do {
lua_assert(cc.v.k == VVOID || cc.tostore > 0);
if (ls->t.token == '}') break;
closelistfield(fs, &cc);
switch(ls->t.token) {
case TK_NAME: { /* may be listfields or recfields */
luaX_lookahead(ls);
if (ls->lookahead.token != '=') /* expression? */
listfield(ls, &cc);
recfield(ls, &cc);
break;
case '[': { /* constructor_item -> recfield */
recfield(ls, &cc);
break;
default: { /* constructor_part -> listfield */
listfield(ls, &cc);
break;
} while (testnext(ls, ',') || testnext(ls, ';'));
check_match(ls, '}', '{', line);
lastlistfield(fs, &cc);
SETARG_B(fs->f->code[pc], luaO_int2fb(cc.na)); /* set initial array size */
SETARG_C(fs->f->code[pc], luaO_int2fb(cc.nh)); /* set initial table size */
注意cc.na和cc.nh这两个变量,它分别记录了表在构造过程中数组部分和哈希部分的数量。并在所有数据都读入后才去构造最终的表。也就是说,这个表的构造只经过了一次一步到位的哈希空间的分配。而如果先构造一个表,再一条条加的话,会经历多次重哈希。由于后者重哈希时重插入的顺序与最初的构造顺序不一致(重插入是按当时的哈希值取模后的顺序来排的,和最初的构造顺序不一样),因此最终的哈希表的构造并不相同!
0x04 药方
与此同时,让我们来看看LuaJIT中的处理是怎么样的:
static void expr_table(LexState *ls, ExpDesc *e)
FuncState *fs = ls->fs;
BCLine line = ls->linenumber;
GCtab *t = NULL;
int vcall = 0, needarr = 0, fixt = 0;
uint32_t narr = 1; /* First array index. */
uint32_t nhash = 0; /* Number of hash entries. */
BCReg freg = fs->freereg;
BCPos pc = bcemit_AD(fs, BC_TNEW, freg, 0);
expr_init(e, VNONRELOC, freg);
bcreg_reserve(fs, 1);
freg++;
lex_check(ls, '{');
while (ls->tok != '}') {
ExpDesc key, val;
vcall = 0;
if (ls->tok == '[') {
expr_bracket(ls, &key); /* Already calls expr_toval. */
if (!expr_isk(&key)) expr_index(fs, e, &key);
if (expr_isnumk(&key) && expr_numiszero(&key)) needarr = 1; else nhash++;
lex_check(ls, '=');
} else if ((ls->tok == TK_name || (!LJ_52 && ls->tok == TK_goto)) &&
lj_lex_lookahead(ls) == '=') {
expr_str(ls, &key);
lex_check(ls, '=');
nhash++;
} else {
expr_init(&key, VKNUM, 0);
setintV(&key.u.nval, (int)narr);
narr++;
needarr = vcall = 1;
expr(ls, &val);
if (expr_isk(&key) && key.k != VKNIL &&
(key.k == VKSTR || expr_isk_nojump(&val))) {
TValue k, *v;
if (!t) { /* Create template table on demand. */
BCReg kidx;
t = lj_tab_new(fs->L, needarr ? narr : 0, hsize2hbits(nhash));
kidx = const_gc(fs, obj2gco(t), LJ_TTAB);
fs->bcbase[pc].ins = BCINS_AD(BC_TDUP, freg-1, kidx);
vcall = 0;
expr_kvalue(&k, &key);
v = lj_tab_set(fs->L, t, &k);
lj_gc_anybarriert(fs->L, t);
if (expr_isk_nojump(&val)) { /* Add const key/value to template table. */
expr_kvalue(v, &val);
} else { /* Otherwise create dummy string key (avoids lj_tab_newkey). */
settabV(fs->L, v, t); /* Preserve key with table itself as value. */
fixt = 1; /* Fix this later, after all resizes. */
goto nonconst;
} else {
nonconst:
if (val.k != VCALL) { expr_toanyreg(fs, &val); vcall = 0; }
if (expr_isk(&key)) expr_index(fs, e, &key);
bcemit_store(fs, e, &val);
fs->freereg = freg;
if (!lex_opt(ls, ',') && !lex_opt(ls, ';')) break;
lex_match(ls, '}', '{', line);
...nhash虽然也是记录哈希项的数量的,但是由于t在第一条key-value时就已经被构造出来了,因此这时nhash并不是最终哈希项的数量,这个表在构造过程中将不可避免地面临重哈希。从而产生不同于lua的结果。
那么怎么改呢?比较麻烦。由于整个parser是one-pass的,LexState和FuncState是同步向下走的,所以想到推迟表的构造时间并不是那么现实。我起初想把LexState的值缓存出来,在整个表解析完后再构造t(这时已经有正确的nhash了)。然而试了好久都没有成功,原因是中间那个expr调用还可能再遇到一张初始化列表,一些依赖于LexState的值的缓存会失效,从而造成子表的值出错。
最后我想到一个简单的办法:表呢,按要求构造,expr_table也按要求执行,但是把所有插入值的操作在低层拦下来,然后统一commit的时候进行重哈希,就不会干扰到LexState,也解决了问题。
具体了方案如下:
修改table结构(lj_obj.h):
typedef struct {
Node head;
MRef current;
uint32_t size;
} Cache;
typedef struct GCtab {
GCHeader;
uint8_t nomm; /* Negative cache for fast metamethods. */
int8_t colo; /* Array colocation. */
MRef array; /* Array part. */
GCRef gclist;
GCRef metatable; /* Must be at same offset in GCudata. */
Cache* cache;
MRef node; /* Hash part. */
uint32_t asize; /* Size of array part (keys [0, asize-1]). */
uint32_t hmask; /* Hash part mask (size of hash part - 1). */
#if LJ_GC64
MRef freetop; /* Top of free elements. */
#endif
} GCtab;
添加了一个用于缓存的结构Cache指针。
再写两个函数(lj_tab.c):
void lj_tab_prepare_cache(lua_State* L, GCtab* t) {
Cache* cache = (Cache*)malloc(sizeof(Cache));
cache->size = 0;
setmref(cache->head.next, NULL);
setmref(cache->current, &cache->head);
lua_assert(t->cache == NULL);
lua_assert(t->cacheHead == NULL);
t->cache = cache;
#define maxval(a, b) ((a) > (b) ? (a) : (b))
void lj_tab_commit_cache(lua_State* L, GCtab* t) {
Cache* cache = t->cache;
Node* head;
lua_assert(cache != NULL);
t->cache = NULL;
lj_tab_resize(L, t, t->asize, hsize2hbits(maxval(cache->size, t->hmask + 1)));
head = noderef(cache->head.next);
printf("START COMMIT!!\n");
while (head != NULL) {
Node* p = noderef(head->next);
TValue* v = lj_tab_newkey(L, t, &head->key);
printf("COMMIT!!\n");
if (tvisstr(&head->key)) {
printf("COMMIT VALUE: %s\n", strdata(strV(&head->key)));
*v = head->val;
free(head);
head = p;
free(cache);
配合lj_tab_newkey前加一些语句用于拦截:
/* Insert new key. Use Brent's variation to optimize the chain length. */
TValue *lj_tab_newkey(lua_State *L, GCtab *t, cTValue *key)
Node* n;
if (t->cache != NULL) {
Node* p = (Node*)malloc(sizeof(Node));
setmref(p->next, NULL);
setmref(noderef(t->cache->current)->next, p);
setmref(t->cache->current, p);
setnilV(&p->val);
p->key = *key;
t->cache->size++;
if (tvisstr(key)) {
printf("CACHED VALUE: %s\n", strdata(strV(key)));
return &p->val;
}最后,修改expr_table,使得在解析表时启用我们的缓存:
/* Parse table constructor expression. */
static void expr_table(LexState *ls, ExpDesc *e)
FuncState *fs = ls->fs;
BCLine line = ls->linenumber;
GCtab *t = NULL;
int vcall = 0, needarr = 0, fixt = 0;
uint32_t narr = 1; /* First array index. */
uint32_t nhash = 0; /* Number of hash entries. */
BCReg freg = fs->freereg;
BCPos pc = bcemit_AD(fs, BC_TNEW, freg, 0);
expr_init(e, VNONRELOC, freg);
bcreg_reserve(fs, 1);
freg++;
lex_check(ls, '{');
while (ls->tok != '}') {
ExpDesc key, val;
vcall = 0;
if (ls->tok == '[') {
expr_bracket(ls, &key); /* Already calls expr_toval. */
if (!expr_isk(&key)) expr_index(fs, e, &key);
if (expr_isnumk(&key) && expr_numiszero(&key)) needarr = 1; else nhash++;
lex_check(ls, '=');
} else if ((ls->tok == TK_name || (!LJ_52 && ls->tok == TK_goto)) &&
lj_lex_lookahead(ls) == '=') {
expr_str(ls, &key);
lex_check(ls, '=');
nhash++;
} else {
expr_init(&key, VKNUM, 0);
setintV(&key.u.nval, (int)narr);
narr++;
needarr = vcall = 1;
expr(ls, &val);
if (expr_isk(&key) && key.k != VKNIL &&
(key.k == VKSTR || expr_isk_nojump(&val))) {
TValue k, *v;
if (!t) { /* Create template table on demand. */
BCReg kidx;
t = lj_tab_new(fs->L, needarr ? narr : 0, hsize2hbits(nhash));
kidx = const_gc(fs, obj2gco(t), LJ_TTAB);
fs->bcbase[pc].ins = BCINS_AD(BC_TDUP, freg-1, kidx);
lj_tab_prepare_cache(fs->L, t);
vcall = 0;
expr_kvalue(&k, &key);
v = lj_tab_set(fs->L, t, &k);
lj_gc_anybarriert(fs->L, t);
if (expr_isk_nojump(&val)) { /* Add const key/value to template table. */
expr_kvalue(v, &val);
} else { /* Otherwise create dummy string key (avoids lj_tab_newkey). */
settabV(fs->L, v, t); /* Preserve key with table itself as value. */
fixt = 1; /* Fix this later, after all resizes. */
goto nonconst;
} else {
nonconst:
if (val.k != VCALL) { expr_toanyreg(fs, &val); vcall = 0; }
if (expr_isk(&key)) expr_index(fs, e, &key);
bcemit_store(fs, e, &val);
fs->freereg = freg;
if (!lex_opt(ls, ',') && !lex_opt(ls, ';')) break;
if (t) {
lj_tab_commit_cache(fs->L, t);
lex_match(ls, '}', '{', line);
if (vcall) {
BCInsLine *ilp = &fs->bcbase[fs->pc-1];
ExpDesc en;
lua_assert(bc_a(ilp->ins) == freg &&
bc_op(ilp->ins) == (narr > 256 ? BC_TSETV : BC_TSETB));
expr_init(&en, VKNUM, 0);
en.u.nval.u32.lo = narr-1;
en.u.nval.u32.hi = 0x43300000; /* Biased integer to avoid denormals. */
if (narr > 256) { fs->pc--; ilp--; }
ilp->ins = BCINS_AD(BC_TSETM, freg, const_num(fs, &en));
setbc_b(&ilp[-1].ins, 0);
if (pc == fs->pc-1) { /* Make expr relocable if possible. */
e->u.s.info = pc;
fs->freereg--;
e->k = VRELOCABLE;
} else {
e->k = VNONRELOC; /* May have been changed by expr_index. */
if (!t) { /* Construct TNEW RD: hhhhhaaaaaaaaaaa. */
BCIns *ip = &fs->bcbase[pc].ins;
if (!needarr) narr = 0;
else if (narr < 3) narr = 3;
else if (narr > 0x7ff) narr = 0x7ff;
setbc_d(ip, narr|(hsize2hbits(nhash)<<11));
} else {
if (needarr && t->asize < narr)
lj_tab_reasize(fs->L, t, narr-1);
if (fixt) { /* Fix value for dummy keys in template table. */
Node *node = noderef(t->node);
uint32_t i, hmask = t->hmask;
for (i = 0; i <= hmask; i++) {
Node *n = &node[i];
if (tvistab(&n->val)) {
lua_assert(tabV(&n->val) == t);
setnilV(&n->val); /* Turn value into nil. */