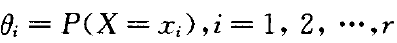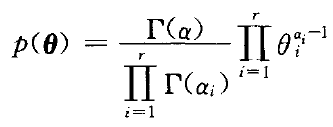7 Bayes Network(
贝叶斯网络)
本文Github仓
库已经同步文章与代码https://github.com/Gary-code/Machine-Learning-Park/tree/main/7%20Bayes%20Network
代码说明:
现在不少人使用贝叶斯网络进行数据预测等研究,最近发现了一个Python第三方库pgmpy很好,并且在一些网站和pgmpy官方教程上对于贝叶斯网络预测代码都有详细的解释。现分享如下:该链接为一个大致的教程,但讲的大致比较全面:
http://www.manongjc.com/detail/22-pnexhswgyrokfuw.htmlpgmpy0.1.15版本的官方教程,讲的非常详细,推荐!
https://pgmpy.org/index.html
但是不知道为什么,这个教程用在pgmpy0.1.18时,在m
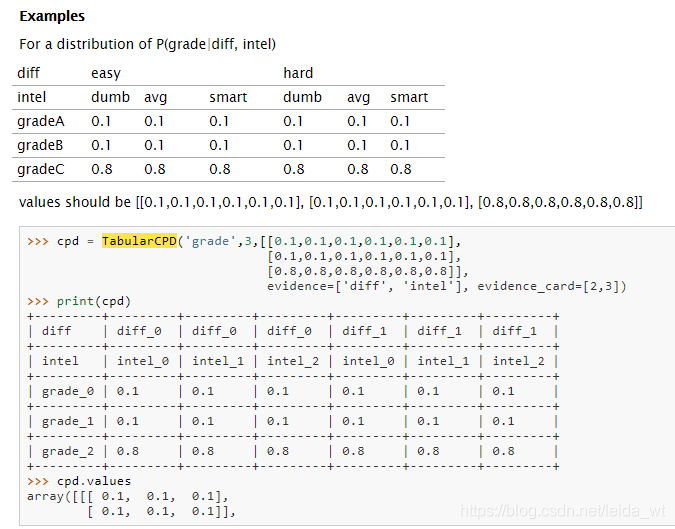
我只是应用一下说明一下,本文会详细说一下如何通过TabularCPD构造条件概率分布CPD(condition probability distribution)表格,以及各个参数的意义,如果需要完整的贝叶斯网络案例请看这个大神
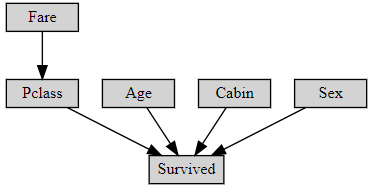
首先咱是这么个网络
先把点点连起来,前面是箭头出来的事务,后面是箭头到达的事务,如L->N
from pgmpy.models import BayesianNetwork
my_model = BayesianNetwork([('L','N'),('I','N'),('S
无向
图实现。
用于测试独立性的 a-Separation 类。
i-Separation,一种在 DAG 中测试独立性的替代方法,它考虑了初始变量及其后代,并且在更大的
网络中速度更快。
具有乘法、除法、边缘化等操作的条件概率表 (CPT) 实现。
消除排序(最小邻居、最小权重、最小填充、加权最小填充)
变量消除(删除贫变量,独立于证据变量,创建一张新的根变量表,等等)。
实用程序:
从 BIF 文件加载
网络。