


看图说话的AI小朋友——图像标注趣谈(下)

版权声明:本文
智能单元首发,本人原创,禁止未授权转载。
前言:近来 图像标注(Image Caption) 问题的研究热度渐高。本文希望在把问题和研究介绍清楚的同时行文通俗有趣,让非专业读者也能一窥其妙。
内容列表:
- 图像标注问题简介
- 图像标注是什么
- 当前水平
- 价值和意义
- 图像标注数据集
- MSCOCO
- Flickr8K和Flickr30K
- PASCAL 1K
- 创建一个守望先锋数据集?
- 图像标注评价标准
- 人类判断与自动评价标准
- Perplexity
- BLEU
- ROUGE
- METEOR
- CIDEr
- 图像标注模型发展 注:下篇起始处
- 百度的m-RNN
- 谷歌的NIC
- 目前最高水平模型
- 模型的比较思考
- 代码实践
- CS231n的LSTM_Captioning
- 基于Numpy的NerualTalk
- 图像标注问题展望
- 模型的更新
- 自动评价标注的更新
- 数据集的更新
- 小结
上篇回顾
在上篇中,我们介绍了研究图像标注问题常用的 数据集 和评价算法常用的 自动评价标准 ,并脑洞了一个 开源创建基于守望先锋游戏画面的中文图像标注数据集 的想法。文章发布后,有不少感兴趣的知友表示愿意参与,并提出了意见和建议。对此我将单独分出一篇文章介绍相关情况,请感兴趣的知友注意。在下篇中,我们将对比较有代表性的图像标注方法进行介绍,展示一些代码实践。
图像标注模型的发展
说是发展,其实时间也并不长,将CNN和RNN结合的模型用于解决图像标注问题的研究最早也就从2014开始提出,在2015年开始对模型各部分组成上进行更多尝试与优化,到2016年CVPR上成为一个热门的专题。
在这个发展中,将RNN和CNN结合的核心思路没变,变化的是使用了更好更复杂的CNN模型,效果更好的LSTM,图像特征输入到RNN中的方式,以及更复合的特征输入等。正由于其发展时间跨度较短,通过阅读该领域的一些重要文章,可以相对轻松地理出大牛们攻城拔寨的思路脉络,这对我们自己从事研究的思路也会有所启发。
m-RNN模型
2014年10月,百度研究院的Junhua Mao和Wei Xu等人在arXiv上发布论文《 Explain Images with Multimodal Recurrent Neural Networks 》,提出了 multimodal Recurrent Neural Network(即m-RNN) 模型,创造性地将深度卷积神经网络CNN和深度循环神经网络RNN结合起来,用于解决图像标注和图像和语句检索等问题。通过14年的相关新闻可知,Wei Xu应该是百度研究院的徐伟,Junhua Mao是徐伟团队中的毛俊华,此外还有杨亿,王江等。
这篇论文是首先抓住这个想法并实现的文章,作者们在文中也当仁不让地说:
To the best of our knowledge, this is the first work that incorporates the Recurrent Neural Network in a deep multimodal architecture.
在后续的几篇优秀论文中,m-RNN都被作为一个基准方法用于比较和超越。因此, 首先介绍百度研究院的m-RNN模型,在于其创造性工作。知友切莫遇百度即黑 。
论文中,在对原始RNN结构进行简要说明后,提出了m-RNN模型如下:
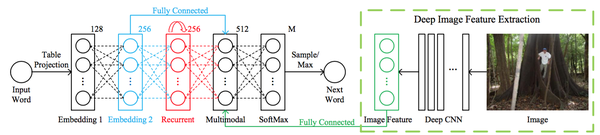
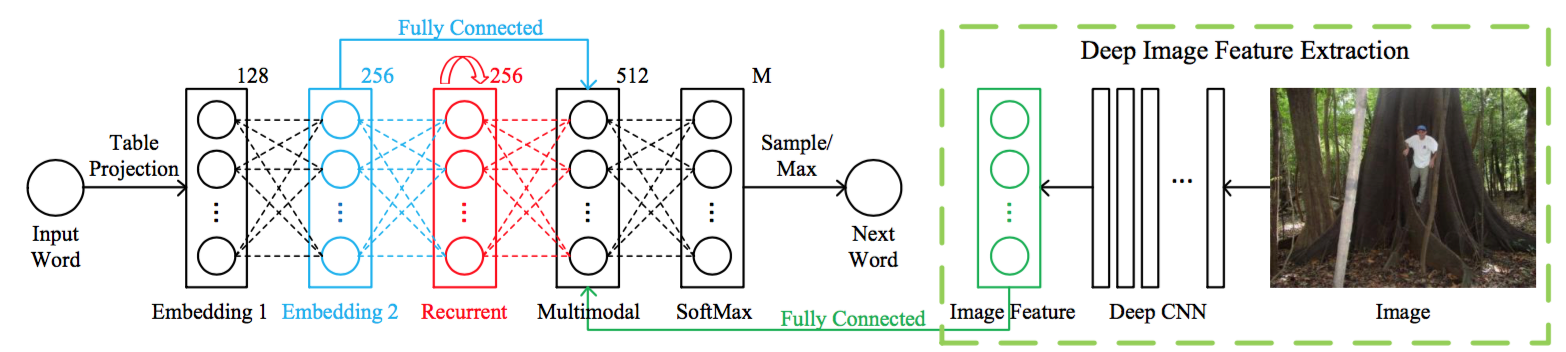
- 模型的 输入 是图像和与图像对应的标注语句(比如在上图中,这个语句就可能是a man at a giant tree in the jungle)。其 输出 是对于下一个单词的可能性的分布;
- 模型在 每个时间帧 都有6层:分别是输入层、2个单词嵌入层,循环层,多模型层和最后的Softmax层;
- 输入单词本来是以独热码(one-hot)方式编码,但是经过两个单词嵌入层后,最终变换为稠密单词表达。在该文中,单词表达层是随机初始化并在训练过程中自己学习的。第二个嵌入层输出的激活数据,作为输入直接进入到多模型层(蓝色线条);
- 循环层的维度是256维,在其中进行的是对 t 时刻的单词表达向量 w(t) 和 t-1 时刻的循环层激活数据 r(t-1) 的变换和计算,具体计算公式是: r(t)=f_2(U_r\cdot r(t-1)+w(t)) 。其中,函数 f_2(.) 是 ReLU ,这个非线性激活函数在 本专栏的CS231n笔记系列 中已经详细介绍过,这里略过。而 U_r 是为了将 r(t-1) 映射到和 w(t) 同样的向量空间中所做的变换;
- 512维的 多模型层 连接着模型的 语言部分 和 图像部分 。 图像部分 就是上图中绿色虚线包围的部分,其本质是利用深度卷积神经网络来提取图像的特征。在该文中,使用的是大名鼎鼎的AlexNet的 第七层的激活数据 作为特征数据输入到多模型层,如此就得到了图像特征向量 I 。而 语言部分 就是包含了单词嵌入层和循环层;
- 多模型层中所做的计算是: m(t)=g_2(V_w\cdot w(t)+V_r\cdot r(t)+I) 。其中, m 表示的是多模型层的特征向量, I 表示的是图像部分输入的特征向量, w(t) 和 r(t) 的解释同上。至于 V_w 和 V_r ,依旧是一个矩阵变换。在这个公式中, 需要特!别!注!意!的 是: 在每个t时刻,图像特征 I 都作为输入进入了计算 。这里向大家提问: 这样做好不好呢 ?先思考一下。后面会给出答案。最后, g_2(.) 函数是一个带参数的tanh函数: g_2(x)=1.7159\cdot tanh(\frac{2}{3}x) 。
该网络在训练的时候,设计的 代价函数是基于语句的困惑度(Perplexity) 的。关于困惑度,我们在 上篇中已经介绍 ,这里就不重复了。论文设计的代价函数为:
C=\frac{1}{N}\sum^N_{i=1}L\cdot log_2PPL(w^{(i)}_{1:L}|I^{(i)})+||\theta||^2_2其中N是训练集中单词的数量, \theta 是模型的参数。所以 ||\theta||^2_2 实际上是一个正则化部分。而L是单词序列的长度。 训练的目标 就是最小化代价函数值。可以看见,上述代价函数是可导的,由此就可以用反向传播来求梯度,而后用随机梯度下降方法来学习参数。
模型的语句生成 :模型从一个特殊的开始符号“##START##”或者任意个参考单词(这里的意思是,作者们可以输入参考语句中的前K个单词作为开始)开始,然后模型开始计算下一个单词的概率分布 P(w|w_{1:n-1}|I) 。然后取概率最大的一个单词作为选取的单词,同时再把这个单词作为输入,预测下一个单词,循环往复,直到生成结束符号##END##。
实验数据集和标注 :该论文发表较早,使用的数据集有我们在上篇中介绍的 Flickr8K和30K ,也有我们没有介绍的 IAPR TC-12 。使用的自动评价标准也较少,有 Perplexity,BLUE1-3,没有BLUE4,其余评价都没有。 与该方法对比的,也是一些相对传统的方法。因此在这里,就对其实验结果略过了,感兴趣的知友可以自行阅读论文。
综上 :该论文的主要贡献就是提出了将RNN和CNN结合起来的模型。模型中有一些设计在后续中被证明不是良好的设计,后续的论文在这个模型的基础上逐渐优化。
NIC模型
2014年11月,谷歌的Vinyals等人发布了论文《 Show and Tell: A Neural Image Caption Generator 》,推出了 NIC(Neural Image Caption)模型 。
相较于百度的m-RNN模型,NIC模型的主要不同点在于:
- 抛弃RNN,使用了 LSTM ;
- CNN部分使用了一个比AlexNet 更好的卷积神经网络 ;
- CNN提取的 图像特征数据只在开始输入一次 。
而从论文角度来看,该论文使用的图像标注数据集较为丰富,有Pascal VOC 2008,Flickr8K和30K,MSCOCO,SBU。其采用的自动评价标准也较为齐全,有BLEU-1,BLEU-4,METEOR和CIDEr。同时,就像我在上篇中提到的那样,论文还用人工方法客观地对NIC模型生成的标注语句进行了分级评价,展示了得分和实际效果之间的距离。下面我们主要对NIC模型本身进行一些讲解。
NIC模型结构 如下图所示:
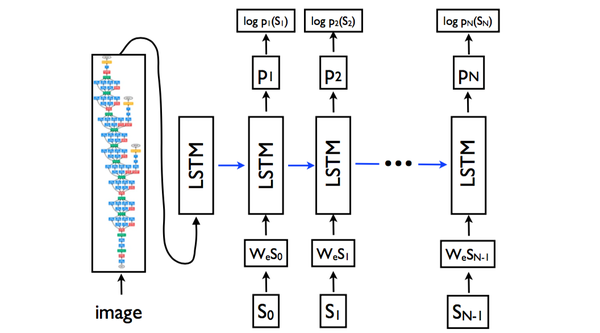
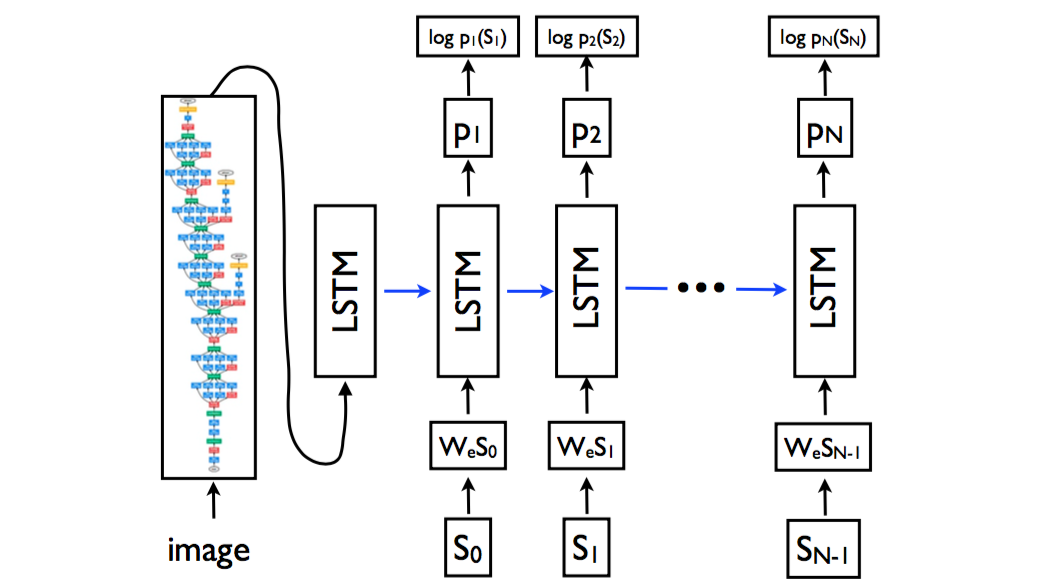
- 图像特征部分 是换汤不换药:我们可以看见,图像经过卷积神经网络,最终还是变成了特征数据(就是特征向量)出来了。唯一的不同就是这次试用的CNN不一样了,取得第几层的激活数据不一样了,归根结底,出来的还是特征向量;
- 但是! 图像特征只在刚开始的时候输入了LSTM,后续没有输入,这点和m-RNN模型是不同的!
- 单词输入部分 还是老思路:和m-RNN模型一样,每个单词采取了独热(one-hot)编码,用来表示单词的是一个维度是词汇表数量的向量。向量和矩阵 W_e 相乘后,作为输入进入到LSTM中。
- 使用LSTM来替换了RNN 。LSTM是什么东西呢,简单地来说,可以把它看成是效果更好RNN吧。为什么效果更好呢?因为它的公式更复杂哈哈?(并不是)。如果知友对LSTM的细节感兴趣,想要理解LSTM。 建议观看CS231n的视频课程第10课:Recurrent Neural Networks, Image Captioning, LSTM 。
以上模型所示的流程,可以用下列公式来概括:
x_{-1}=CNN(I)x_t=W_eS_t,\quad t\in\{0...N-1\}
p_{t+1}=LSTM(x_t),\quad t\in\{0...N-1\}
那么,为什么在NIC模型中,只在第一次输入图像特征数据,而不是每次都输入了呢?论文中说:
We empirically verified that feeding the image at each time step as an extra input yields inferior results, as the network can explicitly exploit noise in the image and overfits more easily.
我们从实践经验上证实如果在每一个时间点都输入图像数据,将会导致较差的结果。网络可能会放大图像数据中的噪音,并且更容易过拟合。
后续的论文中,基本上都是采取在初始时输入一次图像特征数据,不再使用m-RNN每次都输入的方法了。
模型的训练 :NIC模型的损失函数和m-RNN模型却有不同,但基本思路还是一样的:一个可求导的损失函数,利用反向传播来求梯度,然后利用随机梯度下降来学习到最优的参数。其损失函数为:
L(I,S)=-\sum^N_{t=1}logp_t(s_t)实验结果 :经过了以上这些改进后,NIC模型比起m-RNN模型还是有了较大进步:
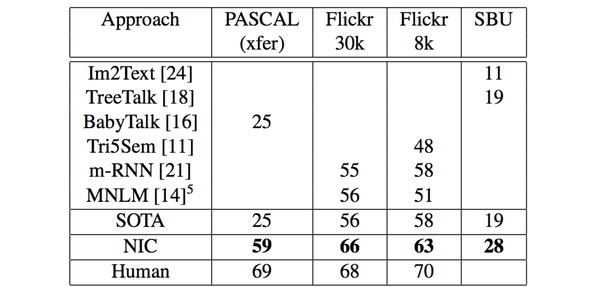
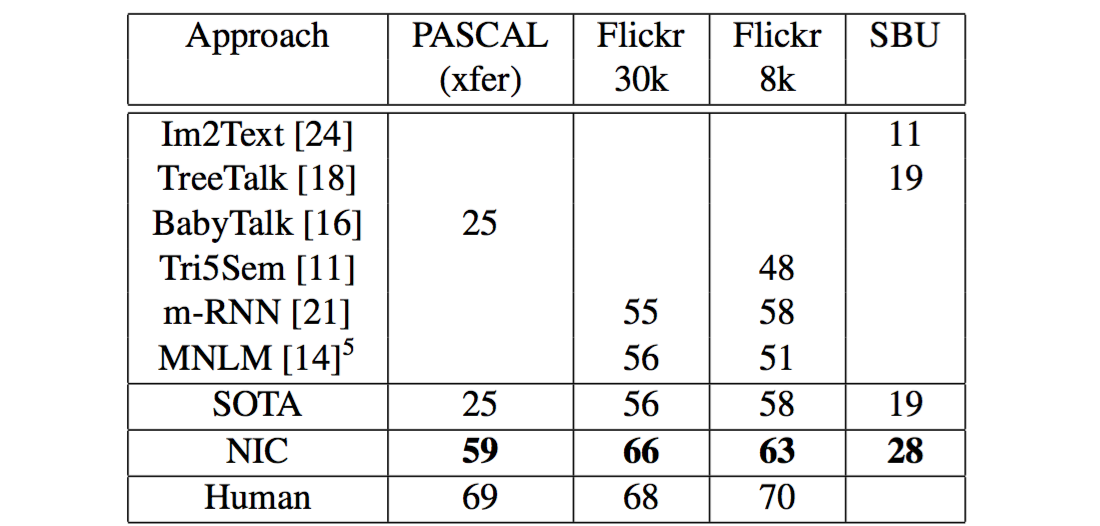
综上 :NIC模型相较于m-RNN模型,其重要的改进在于:
- 首先,在语言模型部分将RNN替换为了实践证明在NLP方面效果更好的 LSTM 。
- 其次,在图像模型部分使用了效果 更好的卷积神经网络模型 来做图像特征数据的提取。
-
最后,改变了图像特征数据的输入方式,从m-RNN的每个时间点都输入变成了
只在初始时输入1次
。
目前最高水平模型
在介绍完前面两个模型后,仍然有一些论文继续做出了更好水平的方法,但是没有选择介绍是因为他们的思路其实和NIC模型相较于m-RNN模型做出的改进思路是雷同的:更好的卷积神经网络模型,更好的语言模型,不同的图像输入方式,不同的单词嵌入方式等等。
那么为什么要选择这个模型呢?大家会说:当然咯,因为这是目前最好的嘛。其实并不完全是这个原因。关于如何看待论文,不久之前我看到了清华大学的 @肖寒 博士在 某个问题 下的回答, 个人认为说得非常好 ,这里 强力推荐 :
不过,一般注水的作者相对而言都是新手,因为比较有经验的研究者都知道:
“论文的一切都在于贡献,不在于结果”
你的结果只是一个说明你贡献的例证,多那么点少那么点, 大家看了毫无区别 。你注水除了恶心我们这些后来实验的人,就没什么别的用处了。有那些 疯狂调参和使劲弄技巧 的时间,真不如 拿来整理好你自己的思路,把论文的论述过程做到有理有据 ! 因为 80.2 和 80.3 正常人都没法记住其间区别,但你 循循善诱的精致论述会让所有人印象深刻 。我希望新手不要本末倒置!
所以,选择《 What Value Do Explicit High Level Concepts Have in Vision to Language Problems? 》这篇论文中的模型来讲,不仅仅是因为它效果好,还因为它的贡献:通过实验回答了论文题目本身提出的这个问题: 在视觉到语言问题(比如图像标注)中,明确的高等级概念到底有没有价值?
这个问题一旦我们对于现在流行的CNN+RNN模型比较熟练了,就会自然而然地产生疑问:话说这图像特征也不知道是啥,反正我卷积神经网络几个层一过,变成了激活数据,变成了一堆浮点数构成的向量,然后就往RNN初始状态里面一丢,诶,效果还可以。但是 为啥呢?! 为啥效果会不错呢?这明明就是一堆说不清楚的特征啊啊!图像的信息并没有用更高级的语义信息表达,就这么稀里糊涂的扔进去了。
该论文在摘要中就一针见血地指明了这个问题:
Much recent progress in Vision-to-Language (V2L) prob- lems has been achieved through a combination of Convolutional Neural Networks (CNNs) and Recurrent Neural Net- works (RNNs). This approach does not explicitly represent high-level semantic concepts, but rather seeks to progress directly from image features to text .
这种直接把用CNN提取的图像特征数据扔进RNN的方法 寻求的是从图像特征直接到文本,而不是先将其用更高等级的语义概念进行表达 。
那么面对这个情况,作者们做了什么(也就是贡献)呢?
In this paper we investigate whether this direct approach succeeds due to, or despite, the fact that it avoids the explicit representation of high-level information . We propose a method of incorporating high-level concepts into the successful CNN-RNN approach , and show that it achieves a significant improvement on the state-of-the-art in both image captioning and visual question answering.
作者们说,我们就来调查一下,当前流行的这个方法它成功,到底是不是因为它就是避免了将图像信息表达为高等级的语义信息呢?于是作者们在当前的CNN+RNN模型中,增加了一个高等级的语义概念表达,结果发现这么一改,结果很好,出现了很大的提升。这就说明, 之前稀里糊涂地把图像特征直接扔进RNN并不是一个好办法,将图像特征用高等级的语义概念表达后再输入RNN会更好 !
这篇论文解答了我同样存在的疑惑,并且通过改进和实验证明,我们存在疑惑的地方是可以有所作为的,改进后的方法有了较大提升。这就是我选择这篇论文的最主要原因。总之,看完摘要我就非常高兴,迫不及待地就开始跳进去想看看人家到底是怎么来做的了。
模型结构 :如下图所示,需要注意的特点有:
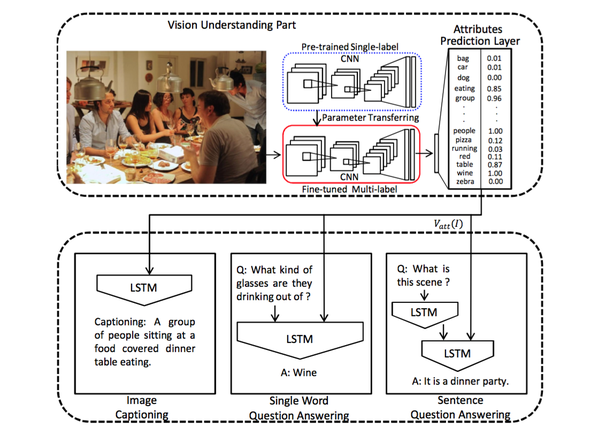
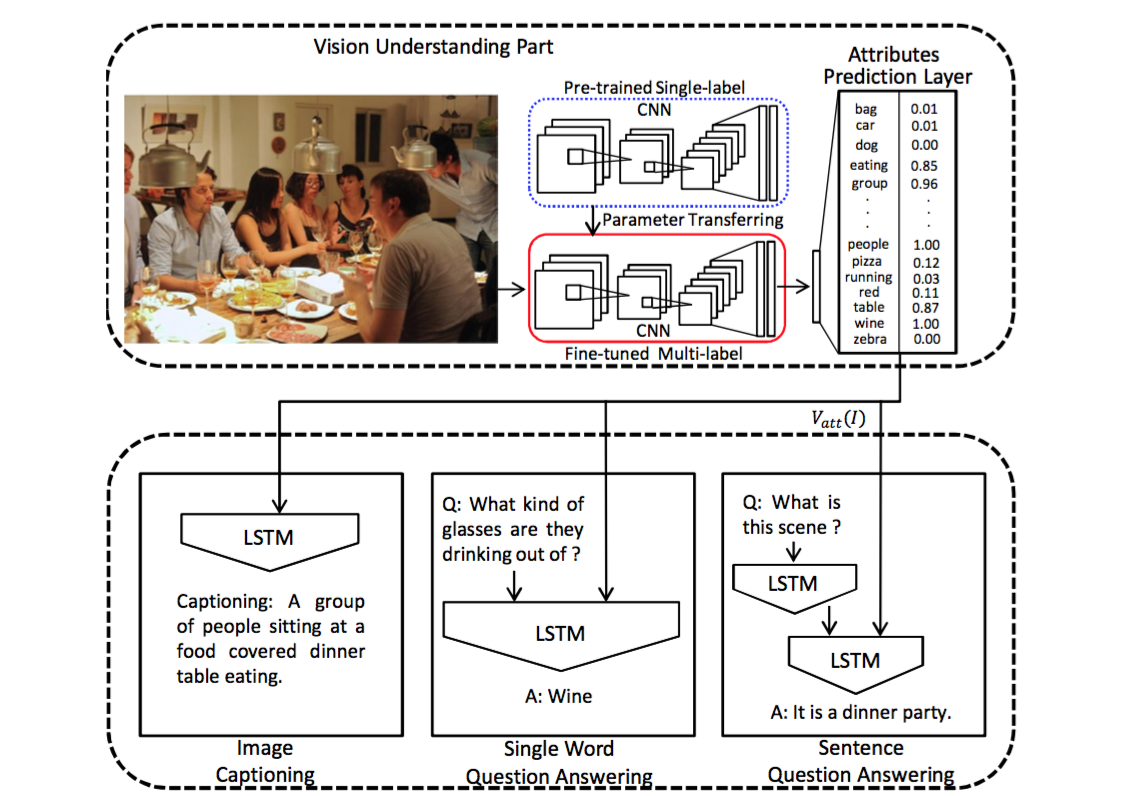
- 在语言模型部分使用的是LSTM,这一点和之前的模型 没有太大区别 。
- 针对3各不同的任务(图像标注、单个单词问答,语句问答)分别实际了3个语言模型部分,这里我们 只关注第一个图像标注任务 。
- 改进重在视觉部分 :请知友们往上看看之前的m-RNN和NIC模型,在他们的视觉部分,图像的处理是相对简单的:图像输入CNN,然后从CNN靠后的层中取出激活数据,输入到RNN即可。然而在这里,我们看到情况变复杂了。
- 首先预训练一个的单标签的CNN(蓝色虚线中),然后把该CNN的参数迁移到下方多标签的CNN中(红色虚线中),并对多标签的CNN做精细调整(fine-tune)。
- 图像输入到红色虚线中的CNN,输出的是一个 有高等级语义概念和对应概率的向量 ,并将这个向量作为语言部分LSTM的输入。
也就是说, 输入LSTM的不是一个不知道到底是什么的浮点数向量了,而是我们可以理解的语义概念的概率的向量 。
论文介绍模型的时候说:我们的模型还是由图像分析和语句生成两个部分构成。 在图像分析部分, 我们使用有监督学习来预测一个属性的集合,这些属性实际上就是图像的标注语句中常见的单词。这一步是如何做到的呢?我们把这一步 看做是一个多标签分类问题 ,训练了一个对应的深度卷积神经网络来实现。
图像经过模型的图像分析部分,输出的就是 V_{att}(I) ,它是一个向量,其长度等于标签集合中标签的数量(也就是词汇表的数量), 每个维度上装的是某个标签对应的预测概率 。然后这个 V_{att}(I) 就要作为输入进入到LSTM,也就是语言生成部分了。
在针对图像标注问题的语言模型部分,该论文中简明扼要地说,我们就是按照《 Show and Tell: A Neural Image Caption Generator 》论文中的方法来进行语句生成的,喏,就上面的NIC模型,所以这里也就不更多逼逼啦。
属性预测部分 :该论文,我个人感到最有价值的部分,还是在它的图像分析部分中 如何从图像到属性的实现,这是它的核心创新点, 所以对该部分做一个比较细节的介绍。需要注意的要点有:
- 属性词汇表的构建 :语义属性是从训练集标注语句中提取出来的,可以是句子中的任何部分:物体名称(名词),动作(动词)或者性质(形容词)。使用了 c 个最常用的单词来构建属性词汇表。在构建的时候,对复数和时态不区分,比如ride和riding,bag和bags被看做一个单词。这样就有效地缩小了词汇表数量,最后得到一个包含256个单词的属性词汇表;
- 属性预测器的实现 :有了词汇表,就希望给出一张图片,能够得到多个对应的在词汇表中的属性单词。将这个需求, 看做是一个多标签分类问题来解决 。具体怎么做呢?如下图所示:
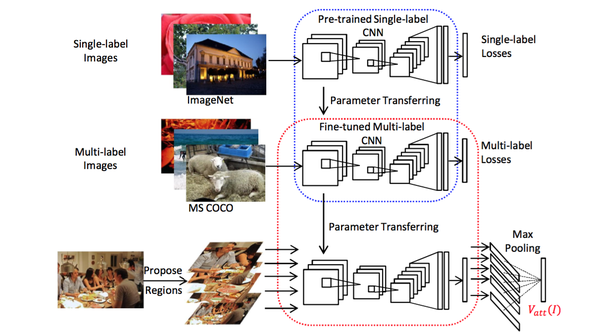
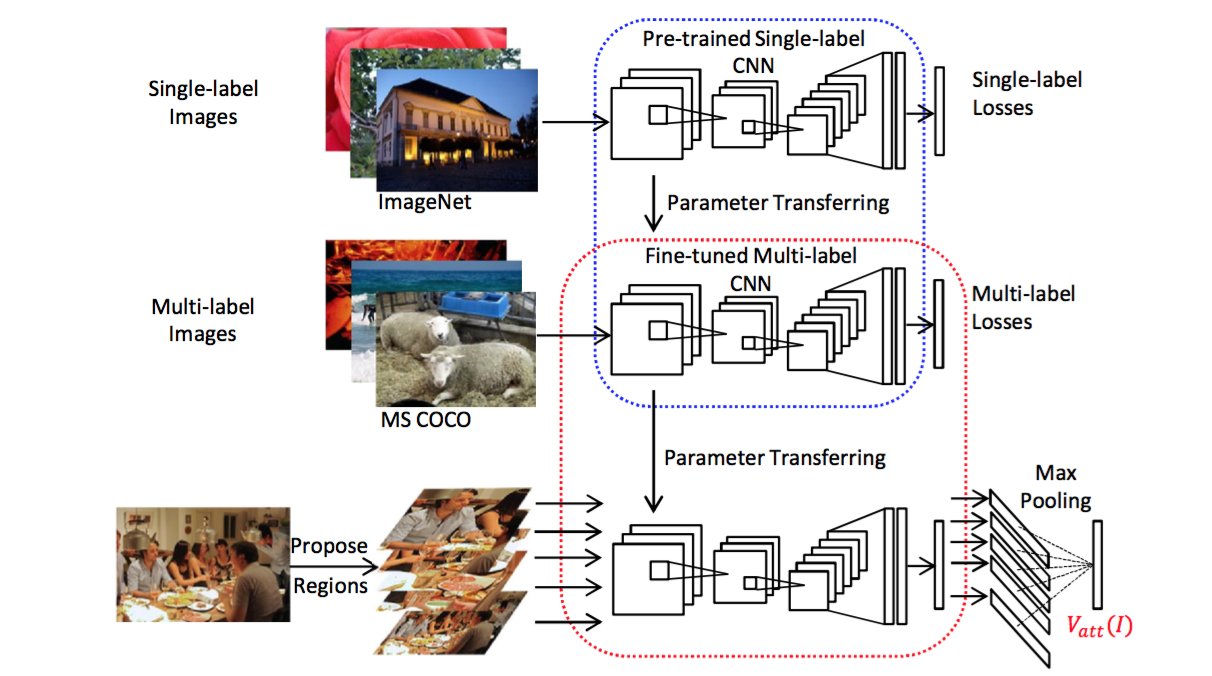
- 首先拿一个用ImageNet 预训练好的VGGNet模型作为初始模型 。然后再用MS COCO这样的有 多标签的数据集来对这个VGGNet做精细调整 (fine-tune)。精细调整具体怎么做呢?就是将最后一个全连接层的输出输入到c分类的softmax中。c=256代表的是词汇表的数量。然后使用逐元素的逻辑回归作为损失函数:
- 损失函数 :假设有 N 个训练样例, y_i=[y_{i1},y_{i2},...,y_{ic}] 是第i个图像对应的标签向量,如果 y_{ij} =1,表示图像中有该标签,反之则没有。 p_i=[p_{i1},p_{i2},...,p_{ic}] 是对应的预测概率向量,则损失函数为: J=\frac{1}{N}\sum^N_{i=1}\sum^c_{j=1}log(1+exp(-y_{ij}p_{ij})) 。在精细调整的训练过程中只需要最小化这个损失函数值即可;
- 然后对于一张输入的图像,要将其分割成不同的局部。刚开始的时候是计划分割出上百个局部窗口,后来感到计算起来太耗费时间,就采取了归一化剪枝的算法将所有的方框分从m个簇,然后每个簇中保留最好的k个方框,最后加上原图,得到m*k+1个建议方框,将对应的局部输入到网络中。在使用中,作者令m=10,k=5;
- 对于局部方框的生成,作者们使用的方法是Multiscale Combinatorial Grouping (MCG)方法。
实验结果:通过将图像信息表达为高等级的语义信息输入LSTM,该方法得到了一个比较显著的性能提升:
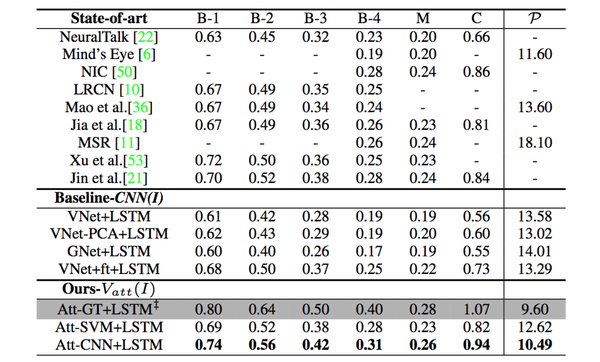
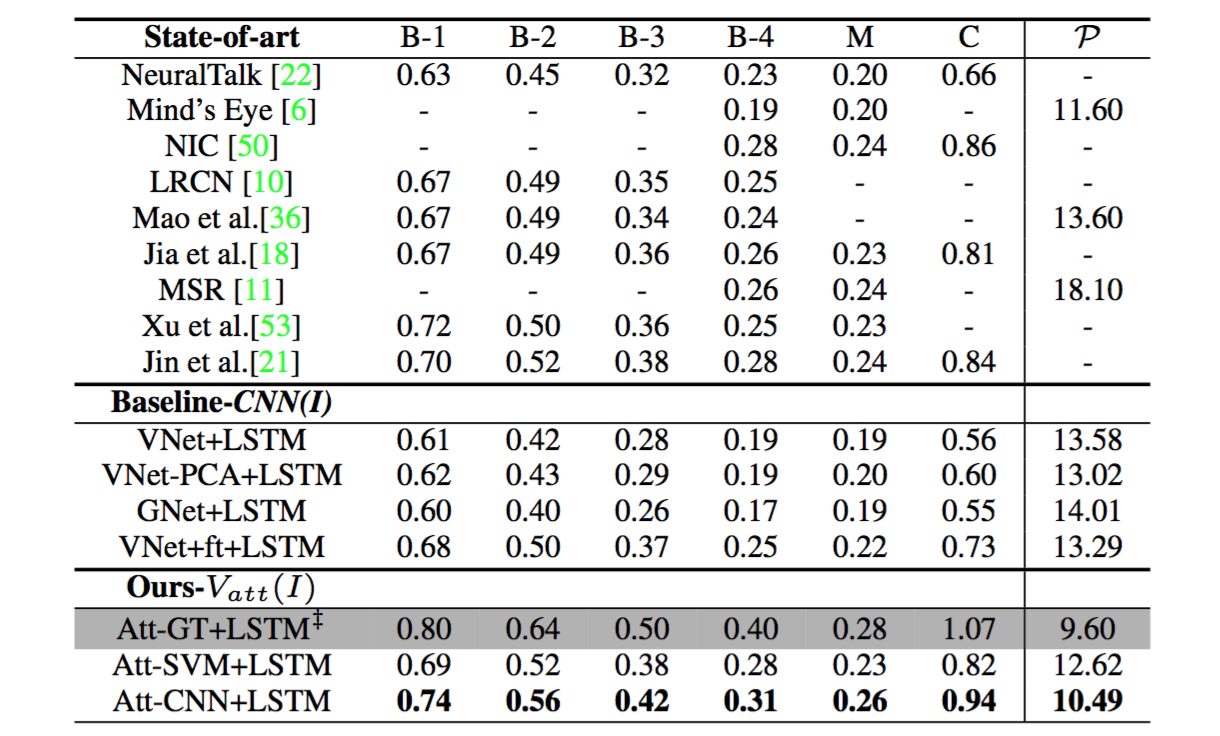
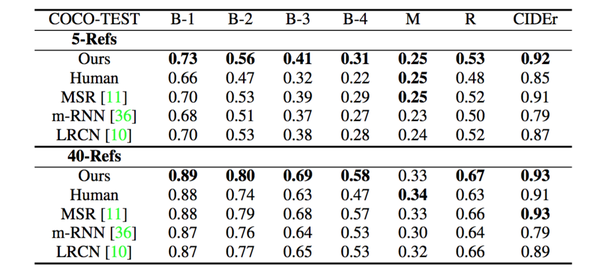
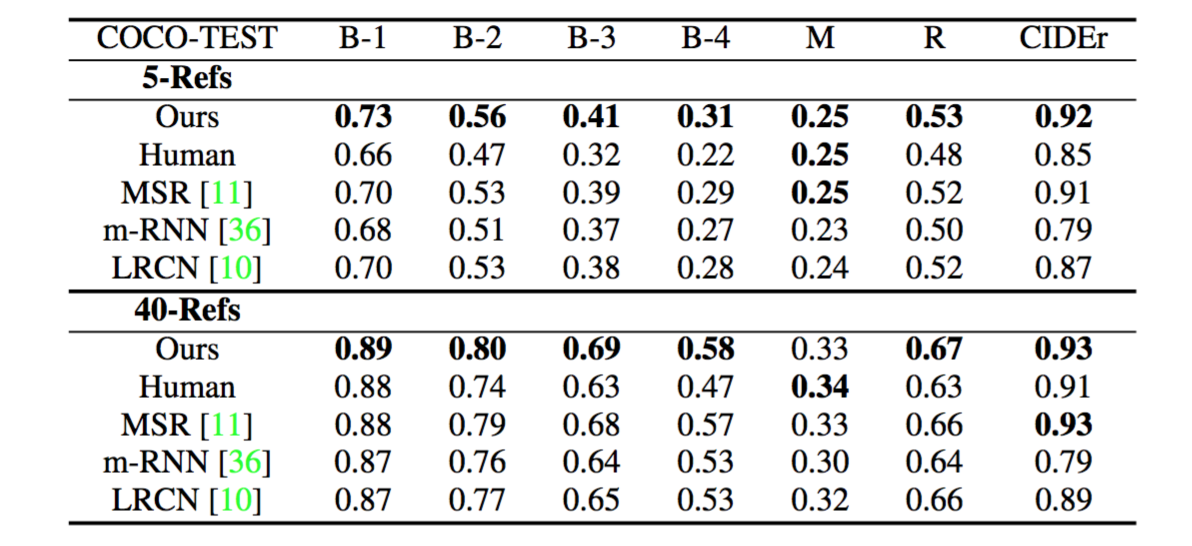
注意 :就如同我在上篇中所说,自动评价标准得分高于人类的分,并不代表实际标注语句就比人类标注语句水平高。 该论文没有如同谷歌NIC模型论文中一样,设置人工对生成的标注语句的分级评价,是一大遗憾 。
模型的比较思考
至此,3个模型及其论文介绍完毕。原本还有LRCN模型和斯坦福的NeuralTalk模型,后将其精简掉了。从这三个模型的进化我们可以看到一个比较清晰的脉络:一个创新之后,对这个创新中的局部进行优化,对局部之间的协作方式进行优化,对创新中说得不清晰或者不合理的部分敢于反思并探索,往往大的提升就在这些模糊的区域中了。
代码实践
光说不练假把式 。机器学习本来就是一个实践性很强的领域,工程能力是非常重要的一环。因此在我们专栏里面,比较推崇的就是知行合一的协作理念。在这个小节,会对CS231n课程的第三个大作业中的RNN图像标注作业部分内容进行解析,并简要介绍开源的NeuralTalk项目。
CS231n #A3 RNN_Captioning
首先,需要说一下的关于CS231n的几个课程作业,个人都非常推荐。希望入门深度学习的同学如能完成,则入门扎实了。我后续也会在专栏进行相关的解析。作业3相关情况请看我们的介绍: 斯坦福CS231n课程作业# 3简介 - 智能单元 - 知乎专栏 。由于本文主要是介绍图像标注问题,所以作业相关背景就不多说了。
完成RNN_Captioning作业首先需要运行jupyter notebook,然后打开 RNN_Captioning.ipynb 文件。然后就可以看到整个作业文件是由Markdown文字说明块(Cell)和python代码块组成的,基本上是手把手教你完成该实验,在某些代码块之前,实验要求你要实现某些核心函数。
代码块1-3: 这3个代码块都不需要我们做什么,他们依次是在进行一些文件导入,初始化设置,导入MS COCO数据,显示数据集中的某些图像和标注语句。在代码块-1的下方,有对MSCOCO数据集的介绍:
在本练习中,我们将使用微软COCO数据集2014版,该数据集已经成为图像标注的标准数据库。数据集包含80000张训练图像,40000张验证图像,每张图都有5个描述句子,句子是利用亚马逊的土耳其机器人招募人工做的。
要下载数据集,到cs231n/datasets目录中运行get_coco_captioning.sh脚本。我们已经为你对数据进行了预处理并从中提取出了特征。使用在ImageNet上预训练的VGG-16网络,我们从网络的 fc7层提取出了所有图像的特征。这些特征被分别存储在train2014_vgg16_fc7.h5 和val2014_vgg16_fc7.h5两个文件中。为了减少处理时间和内存需求,还使用PCA将维度从4096减少到了512,这些数据存在train2014_vgg16_fc7_pca.h5val201h和4_vgg16_fc7_pca.h5l两个文件中。原始图像有20G,所以没有包含在这次的下载中。然而所有的图像都是从Flickr中获取,训练和验证图像的url都存在train2014_urls.txt和val2014_urls.txt,这样你就可以通过网络下载图像了。
处理字符串是很低效的,所以练习中使用的是编码版的标注。每个单词都分配了一个整数ID,这样就能用数字序列来表示标注语句了。单词和ID之间的映射在文件coco2014_vocab.json中。你可以使用cs231n/coco_utils.py中的decode_captions来将装着整数ID的numpy数组转化为字符串。
我们向字符表中加入了一些特殊的标记,在每个标注的开头加入<START> 结尾加入<END>,很少见的单词用 <UNK>替换。还有,因为小批量数据中的标注句子长度不同,所有在短的句子结束 <END> 后后面加上了 <NULL>标记,并且对 <NULL>标记不计算损失值和梯度。因为处理起来有点痛苦,所以我们已经帮你搞定了这些特殊标记的实现细节。
使用load_coco_datah函数将所有的COCO数据进行加载。
从上面的说明中我们可以知道几个要点:
- 助教在设计实验的时候,已经将图像输入到卷积神经网络中,提取出了特征数据并将其文件化,我们可以直接用了;
- 单词都是用整数ID来表示的。打开json文件我们可以看到:
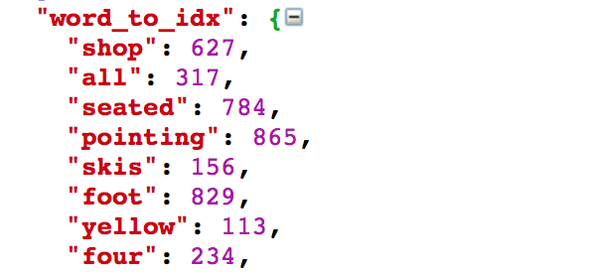
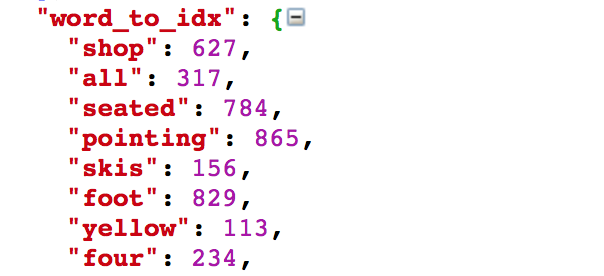
- 一些特殊的符号用来表示句子的开始和结束,以及不常见的单词。
接下来,我们需要开始在作业文件夹中的 cs231n/rnn_layers.py 文件中实现一些核心函数 rnn_step_forward ,不然代码块4运行是会报错的。rnn_step_forward函数实现的就是RNN模型一个时间戳的前向传播。我们先来看看代码块4。
代码块4:其实就是在 检验rnn_step_forward函数有没有正确实现 。
N, D, H = 3, 10, 4
x = np.linspace(-0.4, 0.7, num=N*D).reshape(N, D)
prev_h = np.linspace(-0.2, 0.5, num=N*H).reshape(N, H)
Wx = np.linspace(-0.1, 0.9, num=D*H).reshape(D, H)
Wh = np.linspace(-0.3, 0.7, num=H*H).reshape(H, H)
b = np.linspace(-0.2, 0.4, num=H)
next_h, _ = rnn_step_forward(x, prev_h, Wx, Wh, b)
expected_next_h = np.asarray([
[-0.58172089, -0.50182032, -0.41232771, -0.31410098],
[ 0.66854692, 0.79562378, 0.87755553, 0.92795967],
[ 0.97934501, 0.99144213, 0.99646691, 0.99854353]])
print 'next_h error: ', rel_error(expected_next_h, next_h)
现在让我们用sublime text打开cs231n/rnn_layers.py文件找到rnn_step_forward函数:
def rnn_step_forward(x, prev_h, Wx, Wh, b):
Run the forward pass for a single timestep of a vanilla RNN that uses a tanh
activation function.
The input data has dimension D, the hidden state has dimension H, and we use
a minibatch size of N.
Inputs:
- x: Input data for this timestep, of shape (N, D).
- prev_h: Hidden state from previous timestep, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,)
Returns a tuple of:
- next_h: Next hidden state, of shape (N, H)
- cache: Tuple of values needed for the backward pass.
next_h, cache = None, None
#######################################################################
# TODO: Implement a single forward step for the vanilla RNN. Store the next #
# hidden state and any values you need for the backward pass in the next_h #
# and cache variables respectively.
#######################################################################
# implemente the function #######################################################################
# END OF YOUR CODE #######################################################################
return next_h, cache
回顾课程,该函数主要要实现的就是RNN模型的下面计算:
h_t=tanh(W_{hh}h_{t-1}+W_{xh}x_t)在上述函数定义中,x就是该时间点的输入。prev_h就是RNN上一个隐藏状态,即 h_{t-1} 。Wx对应的就是 W_{xh} ,Wh对应的就是 W_{hh} ,b是偏置量。于是实现如下:
# stage computation
# Step 1. mul1: Wh(H, H) dot prev_h(N, H) -> (N, H)
mul1 = np.dot(prev_h, Wh)
# Step 2. mul2: Wx(D, H) dot x(N, D) -> (N, H)
mul2 = np.dot(x, Wx)
# Step 3. add1: mul1 + mul2 -> (N, H)
add1 = mul1 + mul2
# Step 4. add2: add1(N, H) + b(H,) Broadcasting -> (N, H)
add2 = add1 + b
# Step 5. tanhed: apply tanh to add2 -> (N, H)
tanhed = np.tanh(add2)
next_h = tanhed
# cache
cache = (mul1, mul2, add1, add2, tanhed, x, Wx, Wh, prev_h.copy())
# .copy is important!!!
大家看到这段实现可能会很奇怪,明明一行代码就能实现的事情, 为什么分成这么多步,还用了这么多中间变量 ?实际上,这种分段式的实现,是为了能够方便实现反向传播。为了说明这一点,接下来展示一下实现该步骤的反向传播函数rnn_step_backward。
def rnn_step_backward(dnext_h, cache):
Backward pass for a single timestep of a vanilla RNN.
Inputs:
- dnext_h: Gradient of loss with respect to next hidden state
- cache: Cache object from the forward pass
Returns a tuple of:
- dx: Gradients of input data, of shape (N, D)
- dprev_h: Gradients of previous hidden state, of shape (N, H)
- dWx: Gradients of input-to-hidden weights, of shape (N, H) ? maybe wrong -> (D, H)
- dWh: Gradients of hidden-to-hidden weights, of shape (H, H)
- db: Gradients of bias vector, of shape (H,)
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
#######################################################################
# TODO: Implement the backward pass for a single step of a vanilla RNN. #
# HINT: For the tanh function, you can compute the local derivative in terms of the output value from tanh.
#######################################################################
# implemente the function
#######################################################################
# END OF YOUR CODE
#######################################################################
return dx, dprev_h, dWx, dWh, db
我对该函数的实现如下:
# get the cache
mul1, mul2, add1, add2, tanhed, x, Wx, Wh, prev_h = cache
# backward pass
# Back to step 5: backprop through tanh. dnext_h(N, H) taned(N, H)
# d/dx (tanh x)^2 = 1 - (tanh x)^2
dadd2 = (1.0 - tanhed * tanhed) * dnext_h
# Back to step 4: z=x+y -> dz/dx(writted in dx) = 1, dz/dy(writted in dy) = 1
dadd1 = 1.0 * dadd2 # -> (N, H)
db = 1.0 * np.sum(dadd2, axis=0) # since db shape:(H,)
# Back to step 3: z=x+y -> dz/dx(writted in dx) = 1, dz/dy(writted in dy) = 1
dmul1 = 1.0 * dadd1 # -> (N, H)
dmul2 = 1.0 * dadd1 # -> (N, H)
# Back to step 2: x * y = z -> dx = y, dy = x
# dWx = x * dmul2. x(N, D) dmul2(N, H) dWx should be (D, H)
dWx = np.dot(x.T, dmul2)
# dx = Wx * dmul2. Wx(D, H), dmul2(N, H) -> (N, D)
dx = np.dot(dmul2, Wx.T)
# Back to step 1: x * y = z -> dx = y, dy = x