

对话生成任务使用 GPT2LMHeadModel 还是 GPT2DoubleHeadsModel 训练?

是什么
二者都是 Hugging Face 的 Transformers 提供的 API,可用于 GPT-2 模型进行文本生成任务的预训练和微调阶段。
异同
GPT2LMHeadModel 的训练方式是 Next Token Prediction(LM)。
GPT2DoubleHeadsModel 除了 GPT2LMHeadModel 的训练方式外,还添加了 Next Sentence Predicion,具体方法为:为每组对话的最后一个提问提供至少一个正确回复和至少一个错误回复,模型进行一个二分类任务判断是否是正确回复。
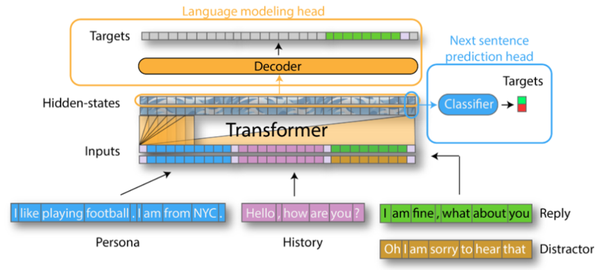
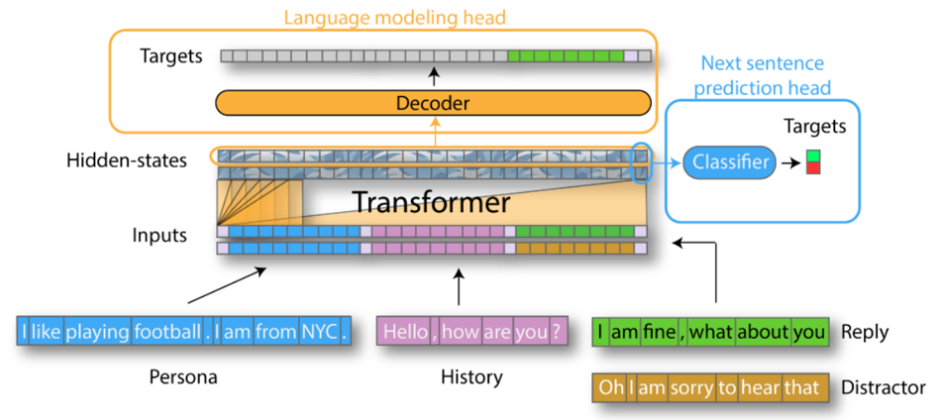
对话生成任务中,Double Heads 一定比 LM Head 好吗?
不一定。
首先,要完成 Next Sentence Predicion 任务,至少需要为每组对话的最后一轮提问提供一个正确回复和一个错误回复。而绝大多数对话语料库只提供一个正确回复,要想准备错误回复,一个比较省事的方法是从其他对话中随机挑选一个回复作为错误回复。但开放域对话任务中,一个提问的回复并非只有一个正确答案,看上去合理的答案可能是无穷尽的。而有些回答是通用的,可以用在很多问题上。因此,若是直接从其他对话随机挑选而不经过甄别,可能把一个合理的回复当作错误回复,导致模型无法很好地理解语义。
其次,由于 Double Heads 多了一个任务,导致训练时间大幅增加。
因此,在人力物力有限的情况下,使用 GPT2LMHeadModel 进行预训练和微调是更好的。
参考
Multi-turn chatbot project (3): GPT-2 chatbot with multi-turn generation settings