由于没有完全理解numba就直接使用了,所以犯了一些使用时的错误。
-
尽量使用numpy的数据类型来写代码,numba对numpy的支持最好;但是并不是所有的numpy函数都被支持,比如我用到的np.clip, np.pad等函数都不支持,通过下面网址查看到底支持哪些numpy函数:http://numba.pydata.org/numba-doc/latest/reference/numpysupported.html。 遇到无法支持的函数时,两个选择,一个是重新手写该函数;另一个则是选择不在jit加速范围内调用该函数。
-
np.zeros(shape, type)函数的调用中犯了一个错误,平时习惯性地会使用一个list作为shape参数,如[10, 10],平时正常使用numpy的时候也没问题,但是使用numba加速时却遇到了编译问题:
Compilation is falling back to object mode WITHOUT looplifting enabled because Function "xxx" failed type inference due to: Invalid use of type(CPUDispatcher(<function xxx at 0x000001B6981D4708>)) with parameters (int64, int64, int64, array(float64, 4d, C))
During: resolving callee type: type(CPUDispatcher(<function xxx at 0x000001B6981D4708>))
numba的编译告警确实有点不太直观,从告警上很难定位到具体的问题出在哪儿,而且往往一个问题会引发出多处的告警。具体在定位的时候我喜欢用简化排除法,构造很简单的例子来排除问题,比如先把函数体变成空的,然后一点点加上内容,看问题到底出在哪里。
-
再来看一个类似的例子:https://github.com/numba/numba/issues/4650
在numba的官方那里的一个issue,跟我上面的报错很类似。
from numba import njit
import numpy as np
@njit
def _get_most_similar(query_ftrs: np.ndarray, all_images_ftrs: np.ndarray) -> np.ndarray:
products = np.empty(all_images_ftrs.shape[0], dtype=query_ftrs.dtype)
for i in range(len(all_images_ftrs)):
ftrs = all_images_ftrs[i]
products[i] = np.dot(query_ftrs, ftrs)
query_ftrs = np.zeros((1, 2048), dtype="float32")
all_images_ftrs = np.zeros((18536, 2048), dtype="float32")
_get_most_similar.py_func(query_ftrs, all_images_ftrs) # numpy is fine
_get_most_similar(query_ftrs, all_images_ftrs) # numba is not
报错信息如下:
The error:
numba.errors.TypingError: Failed in nopython mode pipeline (step: nopython frontend)
Invalid use of Function() with argument(s) of type(s): (array(float64, 1d, C), int64, array(float32, 1d, C))
官方人员给出了如下的定位过程:
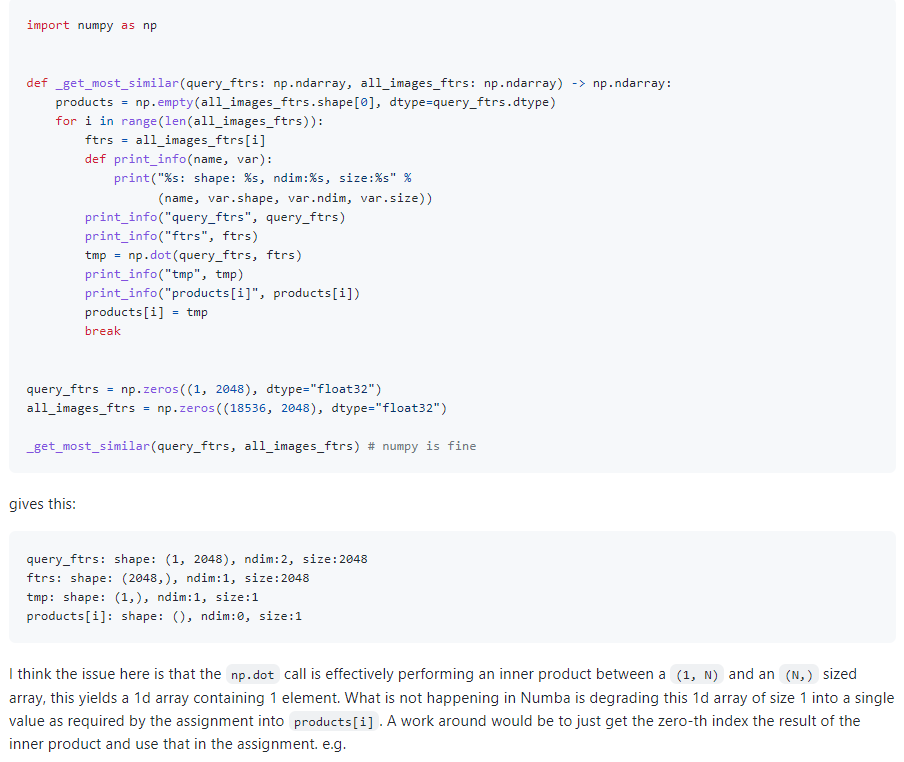
总结下就是numba不能混用一个元素的list和单个scaler,但是numpy是可以的。这跟我那个问题的原因也很像,充分说明了numba对数据类型的要求很严格,推理地很严谨,不具有Numpy的兼容性。应该是tuple就别用list,应该是scaler也别用tuple(1,)。
-
再看一个类型问题:http://numba.pydata.org/numba-doc/latest/user/troubleshoot.html#my-code-doesn-t-compile
是个官网文档上的例子。
调用entropy库时报错:
numba
.
errors
.UntypedAttributeError: Failed at no
python
(no
python
frontend)解决办法
最近想用
python
计算功率谱密度的熵,于是在网上查到了entropy这个库,包含计算熵的功能,再按照官网上的标准命令安装后,调用entropy库时报错了,错误信息如下
numba
.
errors
.UntypedAt...
包含5个文件适用于64位windows系统中
python
安装
numba
加速
1 pyphon 3.7 已经安装,且pycharm也已经安装
2 安装vs2015/2017/2019均可,然后运行VC
3 将上述whl文件运用批评分别安装,顺序依次为
numpy
、llvm、
numba
、import
4 至此在pycharm中file-setting-project-interpreter中可以看到所有已经都安装
5 安装完成,网上找
使用
方法
from
numba
import jit
@jit(no
python
=True)
def nodets2key(batch: int, node: int, ts: float):
key = '-'.join([str(batch), str(node), str(ts)])
return key
在pycharm中报错如下:
numba
.
errors
.TypingError: Failed in no
python
mode pipeline (step
心比天高,仗剑走天涯,保持热爱,奔赴向梦想!低调,谦虚,自律,反思,成长,还算是比较正能量的博主,公益免费传播……内心特别想在AI界做出一些可以推进历史进程影响力的东西(兴趣使然,有点小情怀,也有点使命感呀)……
05-16
成功解决from
numba
.np.ufunc import _internal SystemError: initialization of _internal failed without raising an exception
System initialization is yet anotherparticularity of Unix systems. As explained in Chapter 2, the kernel's lastinitialization action is to start the
initprogram. This program is in charge of finalizi
@File : 191218_obstacle_detection_测试加空间过滤器和jit加速器.py
@Time : 2019/12/18 11:47
@Author : Dontla
@Email : sxana@qq.com
@Software: PyCharm
import time
impor...
由于安装
numba
库时需要安装对应版本的llvmlite,我直接用pip安装
numba
==0.48库时,报错如下:
FileNotFoundError: [Errno 2] No such file or directory: 'llvm-config'
ERROR: Command errored out with exit status 1:...
一开始怀疑是llvm-config无法找到的问题,后面发现是安装
numba
0.48需要先安装llvmlite0.31.0的版本
pip 安装
numba
报错
问题描述:
本人在一个十分干净的容器里面,想pip安装
numba
库,但是该库需要依赖llvmlite这个库,然后就它自己安装llvmlite的时候,就报错了。(报的错忘了截图,大意是缺少llvm-config这个命令)
一、安装llvm
网上有很多教
使用
apt,或者编译的,我捣弄了半天,最方便的还是直接下载预编译好的包。
进入以下网址 https://releases.llvm.org/download.html,
往下翻找到最新版本的 Pre-Built Binaries

