

56. StackLLaMA: 使用 RLHF 训练 LLaMA 模型的指导手册

StackLLaMA: A hands-on guide to train LLaMA with RLHF
Paper Reading Note
Project URL: https:// huggingface.co/blog/sta ckllama
Code URL: https:// huggingface.co/docs/trl /index
TL;DR
- Huggingface 公司开发的 RLHF 训练代码,已集成到 huggingface 的 trl 库中,在 Stack Exchange 数据集对 LLaMA 模型进行了微调。博客详细介绍了 SFT(有监督微调)、RM(奖励/偏好建模)和 RLHF(人类反馈的强化学习)的训练细节,并介绍了一些训练中可能遇到的问题及解决思路
Introduction
背景
- ChatGPT、GPT-4 和 Claude 等模型是功能强大的语言模型,它们人类反馈强化学习 (RLHF) 的方法进行了微调,以使得它们的行为方式更好地符合我们的期望
本文方案
-
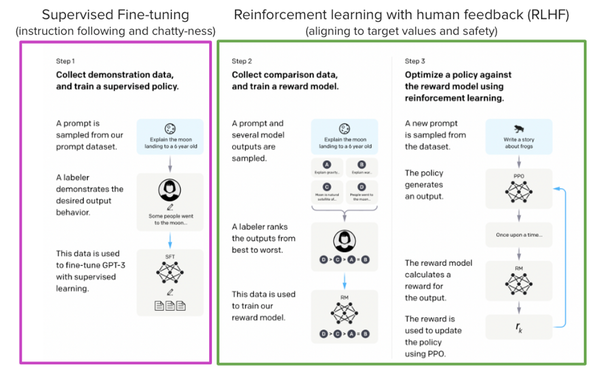
在这篇博客文章中,我们展示了使用 SFT(有监督微调)、RM(奖励/偏好建模)和 RLHF(人类反馈的强化学习)相结合的方法,训练 LlaMa 模型回答
Stack Exchange
(一个问答网站,每个答案有对应的用户点赞数目标注) 上的问题的所有步骤。
Dataset/Algorithm/Model/Experiment Detail
实现方式
LLaMA 模型
- 在进行RLHF时,从一个有能力的模型开始非常重要:RLHF 步骤只是微调模型以使其与本文想要与其交互和期望其响应的方式相一致。因此,本文选择使用最近推出的性能出色的 LLaMA 模型 。LLaMA 模型是由 Meta AI 开发的最新大型语言模型,大小从 7B 到 65B 参数不等,并在 1T 到 1.4T 个 token 数据集之间进行了训练,使其性能很强。本文使用 7B 模型作为所有后续步骤的基础
Stack Exchange 数据集
- 收集人类反馈是一项复杂而昂贵的工作。为了引导这个例子的过程,同时仍然建立一个有用的模型,使用 Stack Exchange 数据集,数据集包括来自 StackExchange 平台的问题及其相应的答案(包括用于代码和许多其他主题的 StackOverflow)。这个数据集信息量很大,回复的答案与赞成票的数量和已接受答案的标签都有
-
本文使用
A General Language Assistant as a Laboratory for Alignment
中提到的方法来给每个答案进行打分
- score = round(log2 (1 + upvotes)) (注:这里用 log 的原因是人们一般优先看高赞回答,导致强者恒强,这里希望用 log 稍微拉低高赞回答的分数)
- 被提问者接受的答案分数再加上 1
- upvotes 为负的分数设置为 -1
- 对于 reward model,每个问题需要两个回答用于对比。一些问题有几十个回复,导致有很多个匹配答案对,本文对每个问题最多采样 10 个答案对,以限制每个问题的数据数量。最后通过将 HTML 转换为 markdown 得到格式干净的数据,数据示例和处理脚本在: stack-exchange-paired
高效训练策略
-
即便训练最小的 LLaMA 模型也需要大量的显存消耗,简单计算
- 基于 bf16 进行参数存储,每个参数占用 2 bytes,Adam 优化器暂用 8 bytes,所以一个 7B 参数模型会消耗 (2+8)*7B=70GB 左右显存,计算注意力分数等中间值时可能需要更多显存
-
本文使用 Parameter-Efficient Fine-Tuning (PEFT) 技巧,比如在 8 bit load 的模型上使用 LoRA
- 以 8 bit 加载模型可显著减少显存占用,因为每个参数只需要一个 byte (例如 7B LlaMa 在显存中占用 7GB)
- 在这种配置下,一般 1B 的参数需要 1.2~1.4Gb 的显存 (取决于批量大小和序列长度),80GB A100 一般可以训练 50-60B 的模型
-
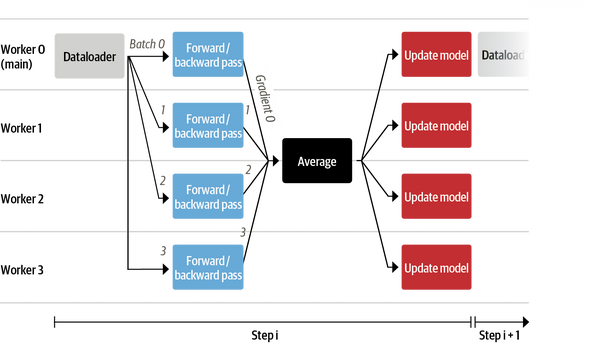
同时使用 dp 进行加速
Supervised fine-tuning
- 开始训练奖励模型和通过强化学习调整模型之前,如果模型在我们感兴趣的领域中表现良好,那么这会有所帮助。在本文的情况下,希望它能够回答问题,而对于其他用例,可能希望它能够遵循指令,这种情况下需要进行指令调整。实现这一点最简单的方法是使用来自该领域或任务的文本,继续使用语言建模目标对语言模型进行训练。StackExchange 数据集非常庞大(超过 1000 万条指令),因此可以轻松地在其中的一个子集上训练语言模型。
-
利用与预训练阶段一样的 causal language modeling objective 损失来仅模型微调。为了有效地使用数据,本文使用了一种叫做“packing”的技术:不是在批次中每个样本都有一个文本,然后填充到模型的最长文本或最大上下文,而是将许多文本连接在一起,用 EOS token 分隔,并切割上下文大小的块来填充批次,无需任何填充。
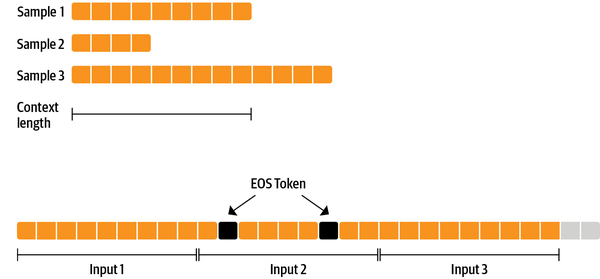
采用这种方法,训练效率要高得多,因为每个通过模型的 token 都会被训练,而传统的数据读取方法会在损失计算中将填充的 token 排除掉。如果没有太多的数据,并且不希望有偶尔截断一些溢出上下文的 token 这种问题,也可以使用传统的数据加载器。上面描述的数据预处理方法在代码中是
ConstantLengthDataset
实现的
- 模型使用 LoRA 方式进行训练,因为之后还需要使用不同的 loss 对模型进行训练,这里训练完成之后需要将 LoRA 的模型参数合入到原始模型中
Reward modeling and human preferences
-
原则上,可以直接使用人类标注来进行 RLHF 微调模型。然而,这将需要在每次优化迭代之后向人类发送一些样本进行评分。由于收敛所需的训练样本数量较大以及人类阅读和标注速度的固有延迟,这是昂贵而缓慢的。一般是训练一个奖励模型 (reward model) 来代替人类标注。奖励模型的目标是模仿人类来评价一段文本。有几种可能的策略来构建奖励模型:最直接的方法是预测人类标注结果(例如评分分数或“好/坏”的二进制值)。在实践中,更好的方法是预测两个答案的排名,其中奖励模型输入为一个给定的 prompt x,以及两个基于 x 输入的回复 (yk, yj),奖励模型来预测哪一个会被人类注释者评价更高。奖励函数的 loss 设计为
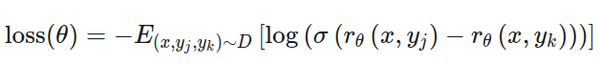
其中 r 是模型的输出分时,yj 是两个回复中更好的回复,也即期望奖励模型对于更好的回复的打分需要尽量高,更差的回复的打分需要尽量低。loss 的代码实现如下
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return loss
-
实验配置
- 训练数据使用了 100000 个候选对,评测使用了 50000 数据
- batchsize 4,1 epoch
- Adam,BF16
- Lora rank 8,alpha 32
- 8xA100 训练需要几个小时
- 实验结果:67% 的准确率
Reinforcement Learning from Human Feedback
-
基于前述的微调后的模型以及奖励模型进行强化学习训练,包含以下步骤
- 基于 prompt 输入生成回复
- 使用奖励模型对回复进行评级
- 使用评级进行 reinforcement learning policy-optimization 更新
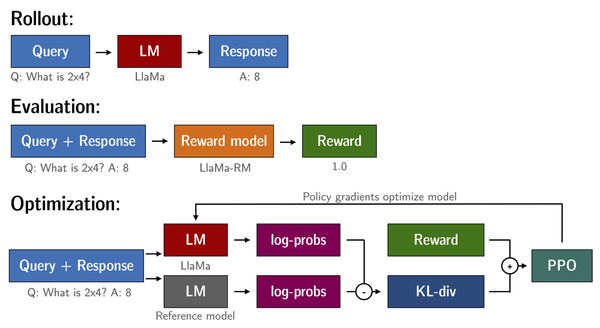
-
查询和响应提示在被 token 化并传递给模型之前按如下方式模板化,该模板在 SFT,RM 和 RLHF 三个步骤中保持一致
Question: <Query>
Answer: <Response>
-
使用 RL 训练语言模型的一个常见问题是,该模型可以通过生成完整的乱码来学习利用奖励模型,这会导致奖励模型分配高奖励。为了平衡这一点,在奖励中增加了一个惩罚:保留了一个没有训练的模型 (即 SFT 后的模型) 作为参考,并通过计算 KL-divergence 来对新模型的生成与参考模型的生成的相似性进行约束
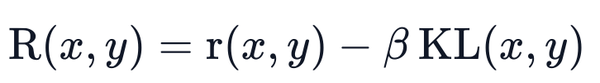
- 整个 RLHF 的代码示例如下
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# sample from the policy and generate responses
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# Compute sentiment score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]