


python数据分析实例:泰坦尼克号上的生还率和各因素(客舱等级、年龄、性别、上船港口等)的关系


泰坦尼克号数据集,是kaggle( Titanic: Machine Learning from Disaster )上入门机器学习(ML)的一个好的可选数据集,当然,也是不错的练习数据分析(DA)的数据集。而python语言,在数据分析方面,作为一柄利器,涵盖了“数据获取→数据处理→数据分析→数据可视化”这个流程中每个环节, 这风骚的操作,也是没谁了。
这个项目做下来,除了没有涉及到数据抓取(python爬虫)外,基本上把python数据处理分析的各个版块都做了一个完整的贯穿。对此进行归纳总结,算是倒逼自己对所接触到的知识,进行结构化的梳理和输出。
0,环境搭建
环境:win10+Anaconda +jupyter Notebook
库:Numpy,pandas,matplotlib,seaborn ,missingno,各种包的管理和安装主要利用conda和pip。
数据集:泰坦尼克号事故样本
1,要探索的问题
要探索的问题:本文主要探寻坦尼克号上的生还率和各因素(客舱等级、年龄、性别、上船港口等)的关系。
2,数据导入和观察
在数据分析中,当拿到一个数据集后,第一步是观察数据的内容和质量。
尤其是当我们利用爬虫从网络中爬取的数据,数据质量基本不高,比如数据集中的空值,异常值,重复值,字母大小写区分,乱码,格式等,都需要我们进一步观察后,对数据集做处理。
#导入需要的库
import pandas as pd
import numpy as np
import seaborn as sns
sns.set()
import matplotlib.pyplot as plt
#配置jupyter notebook
%matplotlib inline
%config InlineBackend.figure_format = "retina"
#导入数据
titanic_df = pd.read_csv("titanic.csv")这里给到的是csv格式的数据,所以直接利用pandas的IO函数pd.read_csv()读取数据。
数据读取工作完成后,可以开始对数据进行简单的预览。预览内容主要包括了解数据表的大小,字段的名称,数据格式等等。为后续的数据处理工作做准备。
- 1.1,查看数据集概要信息
titanic_df.info()#查看数据集概要信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 66.2+ KB观察到数据主要有12列字段,891行,甚至可以看到Age和Cabin字段有较多缺失值,Embanked字段有2个缺失值,数据类型为:float64(2), int64(5), object(5)。
这些信息,我们也可以利用数据集的shape属性,columns属性,以及dtypes属性分别查看
titanic_df.shape
#输出:(891, 12)
titanic_df.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
titanic_df.dtypes
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object- 2, 我们继续查看数据表中具体的数据内容,一般如果数据表行数较多,我们不查看所有数据,只查看开始和结束的几行,熟悉一下数据具体内容即可。
titanic_df.head()#默认显示数据集前5行数据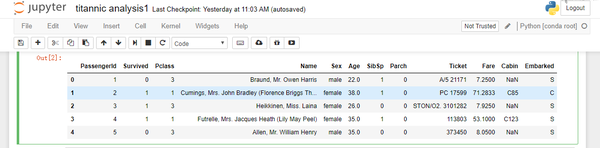
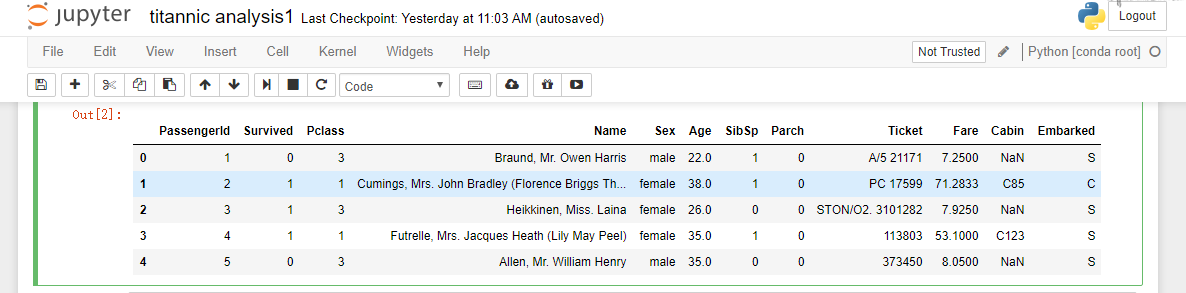
- 3, 数据预览和观察中发现的问题,我们一般都会放在数据处理中解决,数据缺失值是影响数据集的质量的一个重要因素,我们也可以在数据预览中,看看缺失值的情况。
titanic_df.isnull().sum()#查寻整个数据集缺失值的个数
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64其实这里,还有一种可视化的缺失值查询方法,用的是missingno库,这个库在利用可视化的方式查看缺失值时不要太屌!
import missingno as msno
msno.matrix(titanic_df,figsize=(12,5))#可视化查询缺失值

闪瞎了,有木有!哪些字段有缺失值,一眼落下即可得,首次利用这个库,查看缺失值的时候,直接把我“震精~”了!!!
2,数据处理(清洗)
这一步的数据处理,主要是我们在上一步骤中发现的数据集问题:缺失值问题。实际业务中,数据清洗,往往比这麻烦的多,是一项复杂且繁(ku)琐(bi)的工作(用过excel清洗数据的都知道~),在网上看到,有人说一个分析项目80%的时间都是在清洗数据数据,不无道理。清洗的目的有两个,第一是通过清洗让数据可用。第二是让数据变的更适合进行后续的分析工作。总的说来,一份“脏”数据要清晰,一份“干净”的数据也要清洗。
““脏”数据需要清洗,这是众所周知的。但“干净”的数据也要清洗?这听起来很让人疑惑,其实我个人觉得更准确的表达是,这属于特征工程中的特征构造,构造出我们需要的特征。利于下一步分析。
就拿数据分析钟我们常见的处理日期变量问题来说,有时需要我们在日期变量中,提取对应的星期数,构造为以星期的方式来表述日期,有时又需要我们在日期变量中,提取月份,构造为以月份的方式展现日期,又或者把连续型数值数据离散化,构造分类区间等等。这些处理方式,在ML中被叫做特征工程,但本质上就是数据清洗。
缺失值处理中,我们一般会删除缺失值。pandas模块中,提供了将包含NaN值的行删除的方法dropna(),但其实处理缺失值最好的思路是“ 用最接近的数据替换它 ”
对于数值型数据,可用该列的数据的均值或者中位数进行替换,对于分类型数据,可利用该列数据的出现频数最多的数据(众数)来填充。
实在处理不了的空值,可以暂时先放着,不必着急删除。因为在后续的情况可能会出现:后续运算可以跳过该空值进行。
在前面的数据预览中,知道有三列数据有空值:Age,Cabin,Embarked,其中Cabin这列数据,缺失值太多,在此次分析中没有意义(不能用此数据分析出 Cabin 不同对生存率的影响),所以我们可以先不管它,真正需要我们处理的就是Age(数值型数据),Embarked(分类型数据)。
- 2.1,数值型数据缺失值处理
我们先来看数值型数据:Age,对数值型数据,前面说过一般采用该列的数据的均值或者中位数,进行替换。
age_median = titanic_df.Age.median()# 计算所有人年龄的中位数
titanic_df.Age.fillna(age_median, inplace=True)# 使用fillna填充缺失值,inplace=True表示在原数据titanic_df上直接进行修改
titanic_df.Age.describe()# 查看Age列的描述性统计值
count 891.000000
mean 29.361582
std 13.019697
min 0.420000
25% 22.000000
50% 28.000000
75% 35.000000
max 80.000000
Name: Age, dtype: float64
我们这次填充的是所有人的年龄的数据的中位数,其实更好的处理方法是按照性别分组,各自计算男性和女性的年龄中位数,然后再填充。
titanic_df=pd.read_csv("titanic.csv")#重新读取数据集
age_median_sex = titanic_df.groupby("Sex").Age.median()#按性别将男性,女性分组,然后各自计算中位数
titanic_df.set_index('Sex', inplace=True)#设置原数据集的索引为“Sex”
Pandas 的值在运算的过程中,会根据索引的值来进行自动的匹配。
在这里我们可以看到上一步骤的Series:age_median_sex的索引是 female 和 male 两个值,
所以需要把原始数据titanic_df中的性别也设置为索引,用 fillna 自动匹配相应的索引进行填充。
titanic_df.Age.fillna(age_median_sex,inplace=True)#分别用男女各自年龄的中位数来填补,inplace=True表示在原数据titanic_df上直接进行修改
titanic_df.reset_index(inplace=True)#重置索引,取消Sex索引
titanic_df.Age.describe()# 查看Age列的描述统计值
count 891.000000
mean 29.441268
std 13.018747
min 0.420000
25% 22.000000
50% 29.000000
75% 35.000000
max 80.000000
Name: Age, dtype: float64
我们这次填充的是按照性别来分组后,各自计算的男性和女性的年龄平均值。这样是不是就好了呢,其实还可以再把舱位(Pclass)这个因素加进来,分组计算不同舱位男女年龄的中位数,然后再进行填充。
titanic_df = pd.read_csv("titanic.csv")# 重新读取原始数据
age_median_psex = titanic_df.groupby(["Pclass","Sex"]).Age.median()#分组计算不同舱位男女年龄的中位数
titanic_df.set_index(["Pclass","Sex"],inplace=True)#设置Pclass, Sex为索引, inplace=True表示在原数据titanic_df上直接进行修改
titanic_df.Age.fillna(age_median_psex,inplace=True)#用fillna填充缺失值,根据索引值填充
titanic_df.reset_index(inplace=True)#重置索引,取消Sex,Pclass索引
titanic_df.Age.describe()# 查看Age列的描述性统计值
ount 891.000000
mean 29.112424
std 13.304424
min 0.420000
25% 21.500000
50% 26.000000
75% 36.000000
max 80.000000
Name: Age, dtype: float64
- 2.2,分类型数据缺失值处理
我们再来看看分类型数据:Embarked,前面说过对于分类型数据,可利用该列数据的出现频数最多的数据(众数)来填充。
titanic_df.describe(include=[np.object])#利用include=[np.object]查看分类型数据的描述性统计


能看到“S”出现的频数最多,咖位最高。
其实这里也可以利用计数统计的方式,求出Embarked列出现频数最多的值。
titanic_df.Embarked.value_counts()
S 644
C 168
Q 77
Name: Embarked, dtype: int64
titanic_df.fillna({"Embarked":"S"},inplace=True)#用“S”,填充Embarked列的缺失值
titanic_df[titanic_df.Embarked.isnull()].Embarked#查看缺失值填充效果
Series([], Name: Embarked,
dtype: object) #可以看到,已经没有缺失值了。至此,我们已经完成了此次分析中的数据清洗。
因为此次提供的数据集,在利用pandas读取后是一个DateFrame,如果是多个DateFrame,还会涉及到多个DateFrame 的合并,类似于SQL语言中的join操作,这次分析中没有涉及到多个DateFrame 的合并操作,这里就不多说了。在这一步中,我们也明白数据清洗的工作,是为了提高数据集的质量,利于后续的数据分析。接下来,我们正式进入数据分析阶段。
3,数据分析(可视化分析)
数据透视表是Excel中最常用的数据汇总分析工具,它可以根据一个或多个制定的维度对数据进行聚合,探索数据内深层次的信息。
在pandas中,同样提供了pandas.pivot_table函数来实现这些功能。在接下来的分析中,我们会多次用到这个函数,所以先来熟悉下下这个函数:


pandas.pivot_table函数中包含四个主要的变量,以及一些可选择使用的参数。四个主要的变量分别是数据源data,行索引index,列columns,和数值values。可选择使用的参数包括数值的汇总方式,NaN值的处理方式,以及是否显示汇总行数据等。
在可视化分析方面,会涉及到python常用的绘图库:matplotlib和seaborn,网上已经有非常多的使用指南,这里就不多说了,以后有时间,也会做一些总结。
- 3.1,基本情况分析
我们先来看下基本情况:891人当中,生还比率与未生还比率是多少?
total_survived= titanic_df['Survived'].sum()
total_no_survived = 891 - total_survived
plt.figure(figsize = (10,5))#创建画布
plt.subplot(121)#添加第1个子图
sns.countplot(x='Survived', data=titanic_df)
plt.title('Survival count')
plt.subplot(122)#添加第2个子图
plt.pie([total_no_survived, total_survived],labels=['No Survived','Survived'],autopct='%1.0f%%')
plt.title('Survival rate')
plt.show()
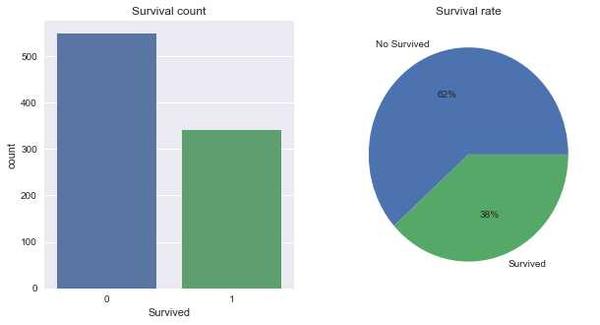
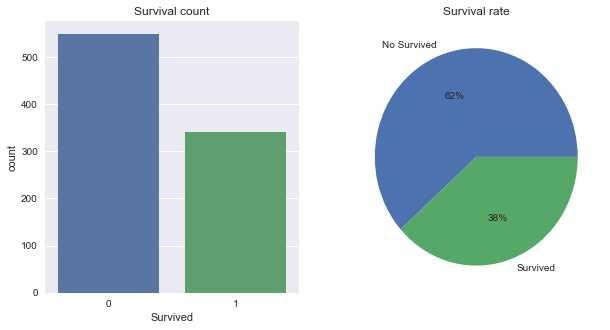
然而左边竖形柱状图中,0代表是无生还,1代表是生还,但这种表示只有知道数据集内容的分析人员才能看明白,实际操作中,数据分析的成果往往是展示给他人看的,所以我们需要把这种情况转换为其他不知道数据集的人也能看明白的展示图。
因此,我们还需要一波操作:定义一个映射{0:"no-survived",1:"survived"}应用到原有的titanic_df['Survived']列中。
titanic_df['Survived_cat'] = titanic_df['Survived'].\
map({0:"no-survived",1:"survived"})
plt.figure(figsize = (10,5))#创建画布
plt.subplot(121)#添加第1个子图
sns.countplot(x='Survived_cat', data=titanic_df)#修改下X轴统计数据列
plt.xlabel("Survived distribution")#修改下X轴标签
plt.title('Survival count')
plt.subplot(122)#添加第2个子图
plt.pie([total_no_survived, total_survived],labels=['No Survived','Survived'],autopct='%1.0f%%')
plt.title('Survival rate')
plt.show()
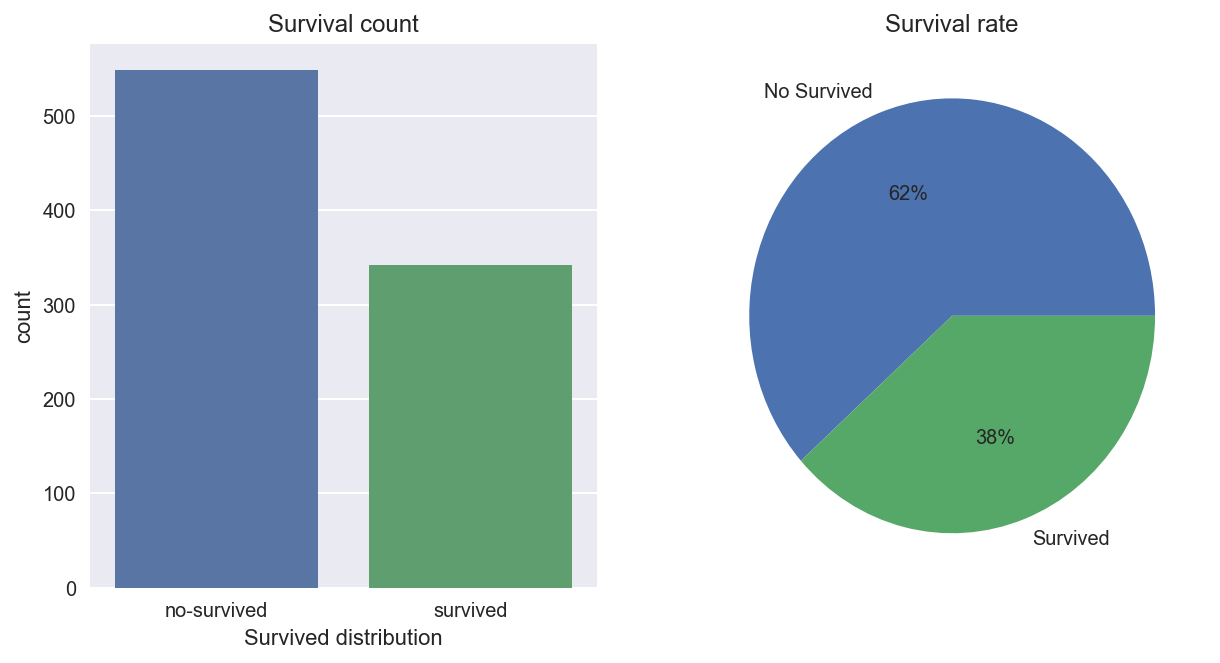
结论:这891名乘客中,生还和未生还的 比率 分别为 38% 和 62%。
- 3.2, 分别探索下 Pclass、Sex、Age 和 Embarked 等与“生还率”的关系.
A.舱位(Pclass)与生还率关系
这时候,就该上pivot_table函数这个大杀器了,正所谓“屠龙在手,天下我有。。。”
咳咳咳。。。一不小心,乱入了,嗯,咱回到正题,来看下如何使用。
不同级别的客舱人数分布
titanic_df.pivot_table(values="Name",index="Pclass",aggfunc="count")

看,就是这么简单,粗暴,嗯,没有黄。
当然,如果不使用pivot_table函数,我们一般用groupby来分组聚合。
titanic_df[['Pclass','Name']].groupby(['Pclass']).count()
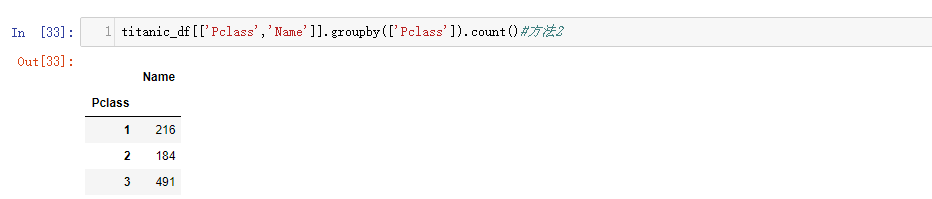
不过怎么看,都觉着还是pivot_table函数,身段更曼妙更悦目。这句话,翻译成人话,就是pivot_table函数可读性更高,传几个参数,秒秒钟出结果。
可视化展示操作
plt.figure(figsize= (10 ,5))#创建画布
sns.countplot(x='Pclass', data=titanic_df)
plt.title('Person Count Across on Pclass)
plt.show()
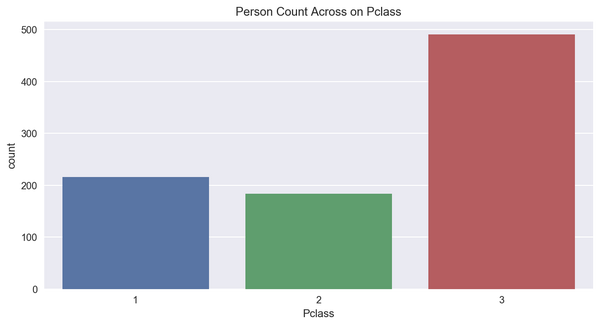
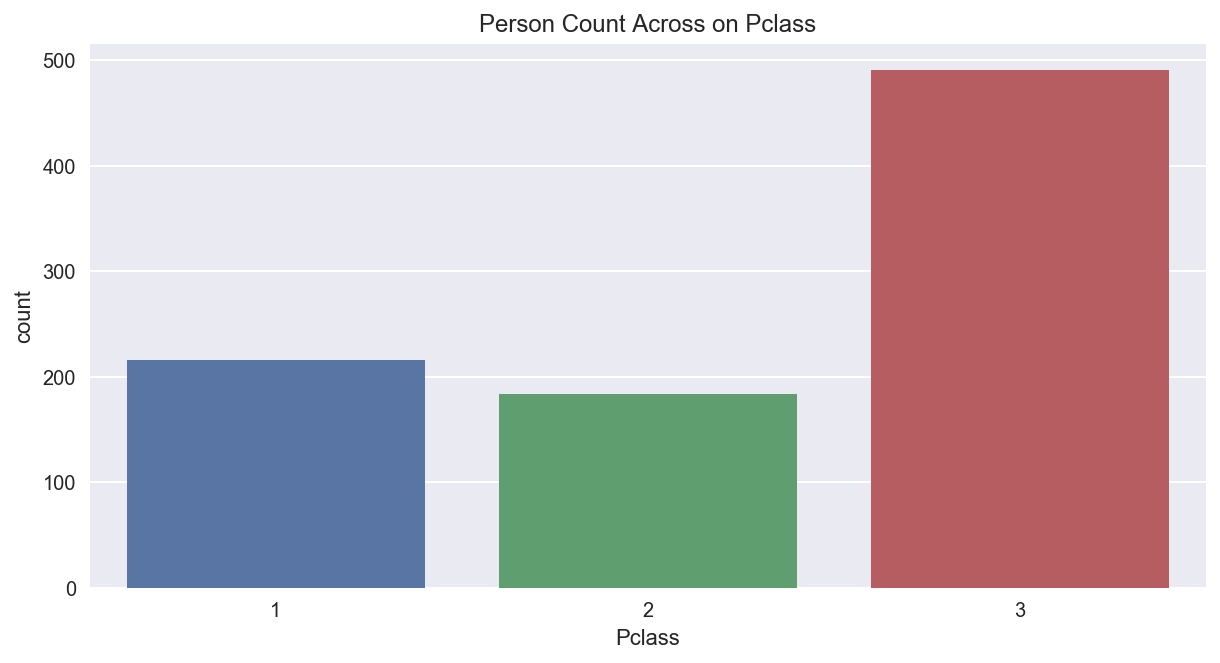
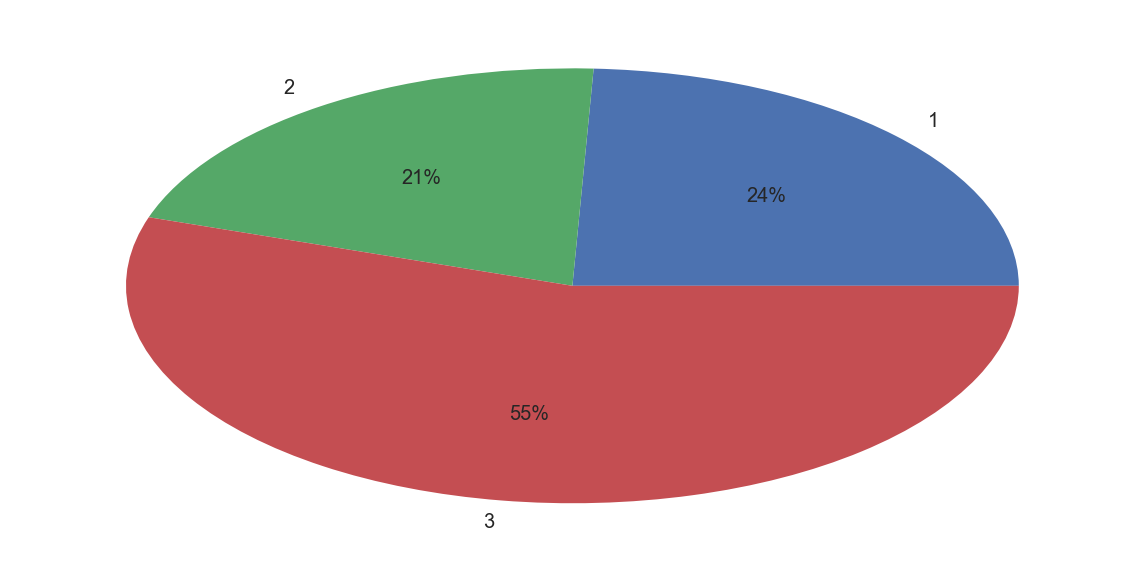
如果我们不用柱状图形,也可以用饼图展示
plt
.figure(figsize= (10 ,5))#创建画布
plt.pie(titanic_df[['Pclass','Name']].groupby(['Pclass']).count(),\
labels=['1','2','3'],autopct='%1.0f%%')
plt.show()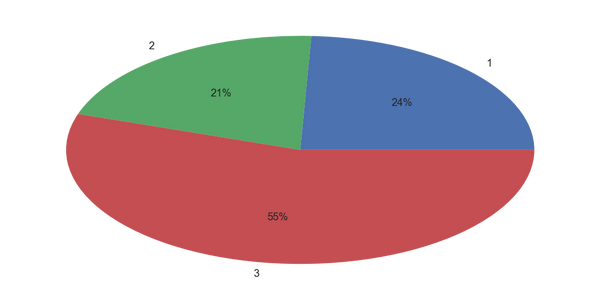
不过,这饼图,也忒丑了。。。。。。嗯,确实,所以,还需要限制下坐标轴
plt.figure(figsize= (10 ,5))#创建画布
plt.pie(titanic_df[['Pclass','Name']].groupby(['Pclass']).count(),\
labels=['1','2','3'],autopct='%1.0f%%')
plt.axis("equal")#绘制标准的圆形图
plt.show()
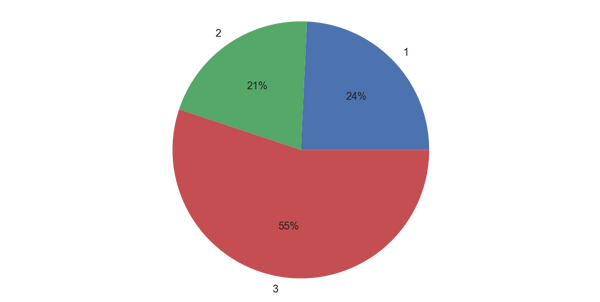
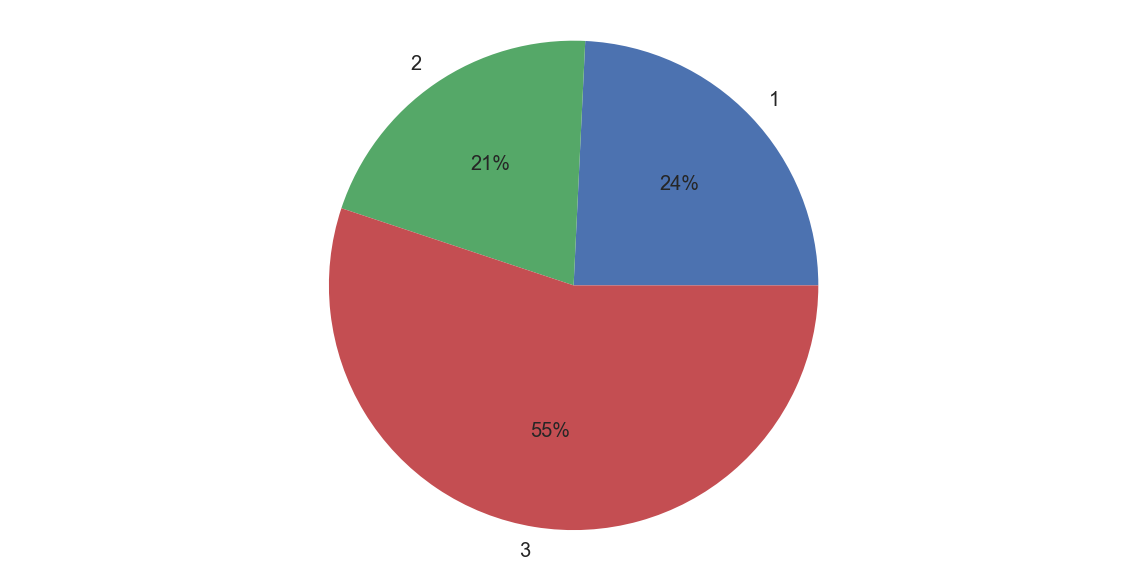
ok,这是不同舱位的人数分布情况,我们需要求出的是舱位与生还率的关系。
舱位与生还率的关系
titanic_df.pivot_table(values="Survived",index="Pclass",aggfunc=np.mean)

可视化展示操作
plt.figure(figsize= (10 ,5))
sns.barplot(data=titanic_df,x="Pclass",y="Survived",ci=None)#ci表示置信区间
plt.show()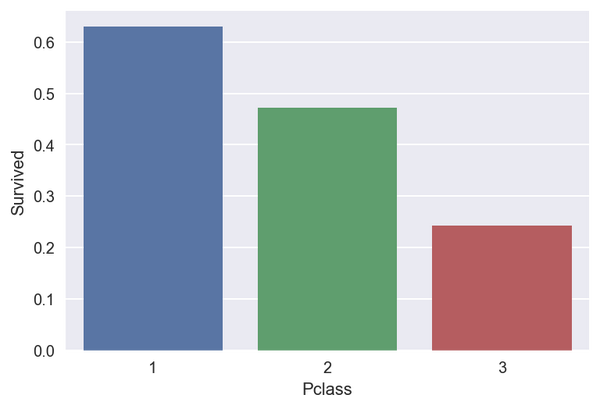
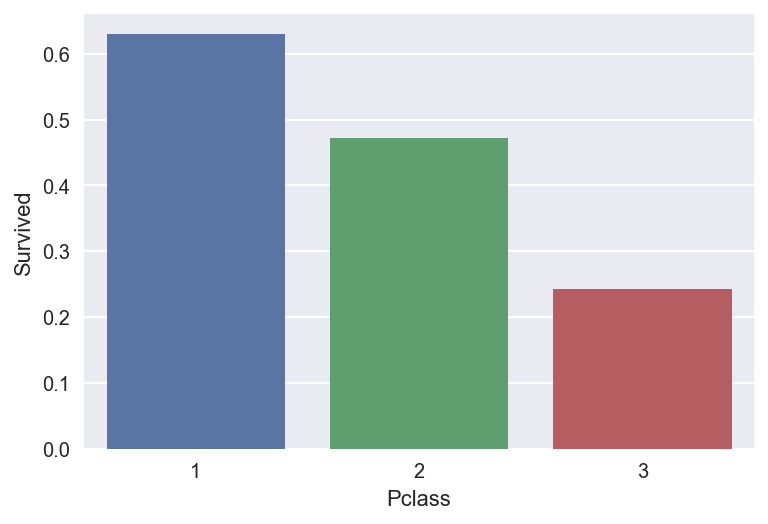
结论: 头等舱的生还概率最大,其次是二等舱,三等舱的概率最小。
B.性别(Sex)与生还率关系
不同性别生还率
titanic_df.pivot_table(values="Survived",index="Sex",aggfunc=np.mean)

可视化展示操作
plt.figure(figsize= (8 ,5))#创建画布
sns.barplot(data=titanic_df,x="Sex",y="Survived",ci=None)
plt.show()
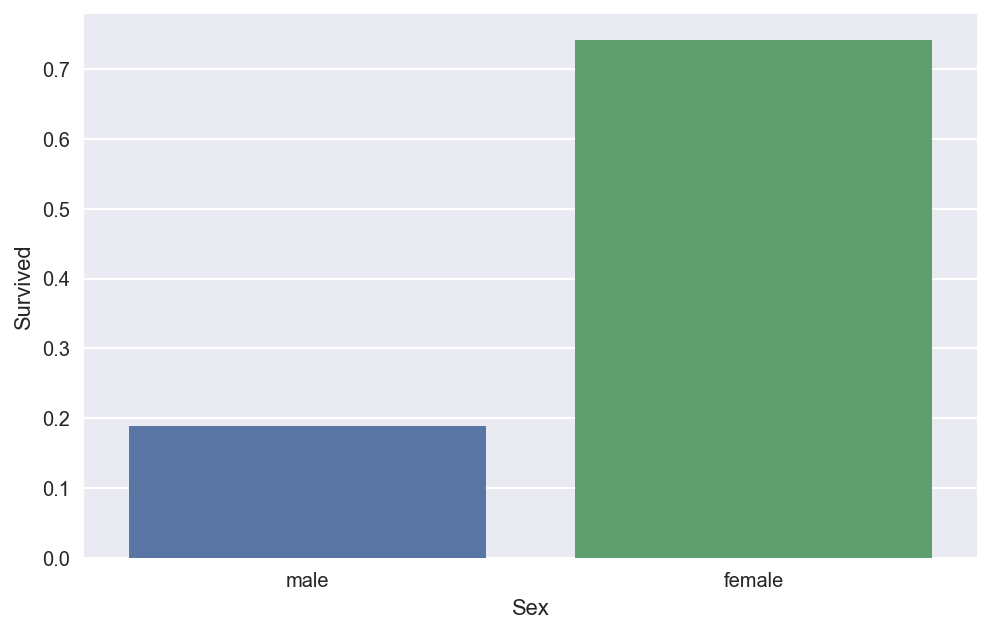
结论 :女性幸存概率远远大于男性。
C.综合考虑性别(Sex),舱位(Pclass)与生还率关系
首先计算不同舱位不同性别的人的生还概率
titanic_df.pivot_table(values="Survived",index=["Pclass","Sex"],aggfunc=np.mean)
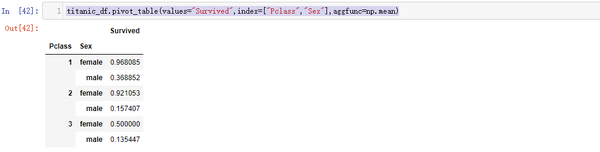

可视化展示操作
plt.figure(figsize= (10 ,5))
sns.pointplot(data=titanic_df,x="Pclass",y="Survived",hue="Sex",ci=None)
plt.show()

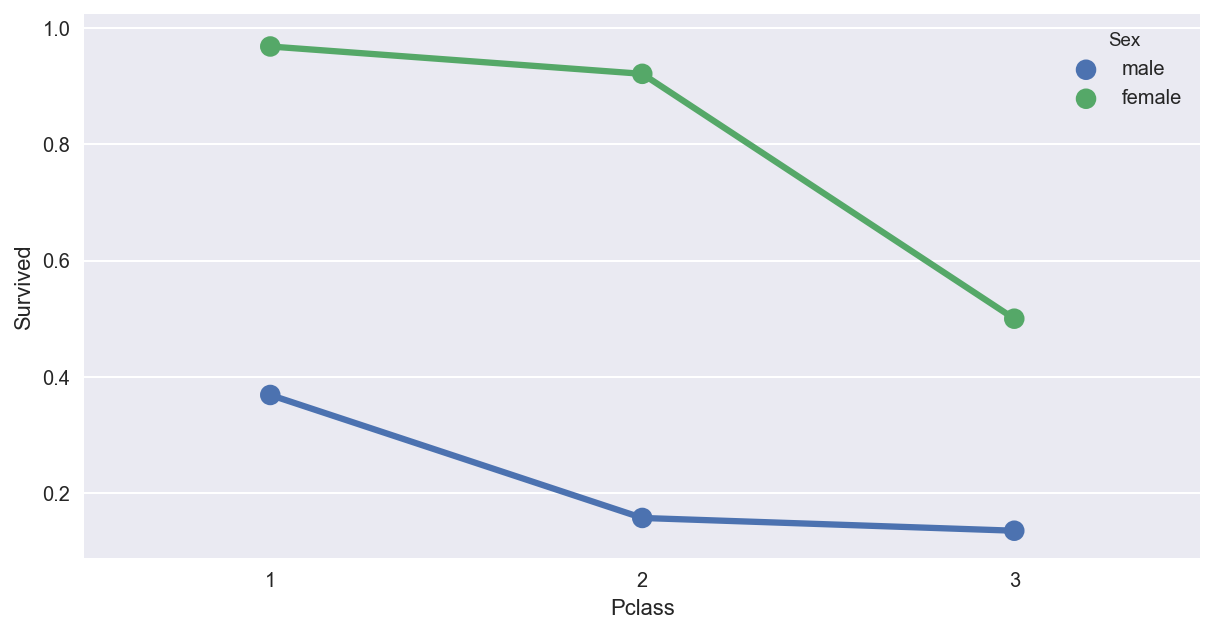
结论:1, 在各个舱位中,女性的生还概率都远大于男性。
2, 一二等舱的女性生还率接近,且远大于三等舱。
3, 一等舱的男性生还率大于二三等舱,二三等舱的男性生还率接近。
D.年龄(Age)与生还率关系
与上面的舱位、性别这些分类变量不同,年龄是一个连续的数值变量,一般处理这样的数据类型,我们采用将连续性的变量离散化的方法。
所谓离散化,指的是将某个变量的所在区间分割为几个小区间,落在同一个区间的观测值用同一个符号表示,简单理解就是将属于统一范围类的观测值分为一组。然后分组观察。
pandas中提供了cut函数,对变量进行离散化分割。
titanic_df["AgeGroup"]=pd.cut(titanic_df["Age"],5)#将年龄列的数值划分为5等分
titanic_df.AgeGroup.value_counts(sort=False)#查看每个分组有多少人数
(0.34, 16.336] 100
(16.336, 32.252] 523
(32.252, 48.168] 188
(48.168, 64.084] 69
(64.084, 80.0] 11
Name: AgeGroup, dtype: int64
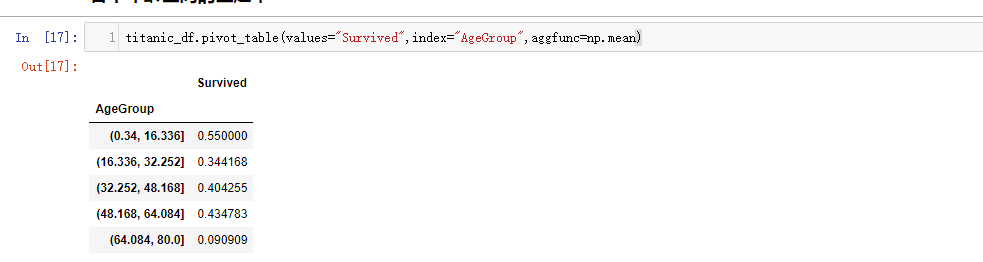
各个年龄区间的生还率
titanic_df.pivot_table(values="Survived",index="AgeGroup",aggfunc=np.mean)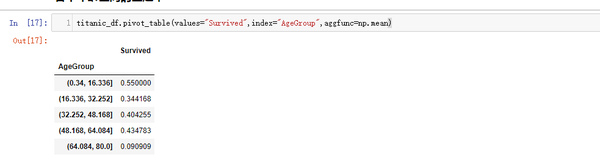
可视化展示操作
plt.figure(figsize= (10 ,5))
sns.barplot(data=titanic_df,x="AgeGroup",y="Survived",ci=None)
plt.xticks(rotation=60)#设置刻度标签角度
plt.show()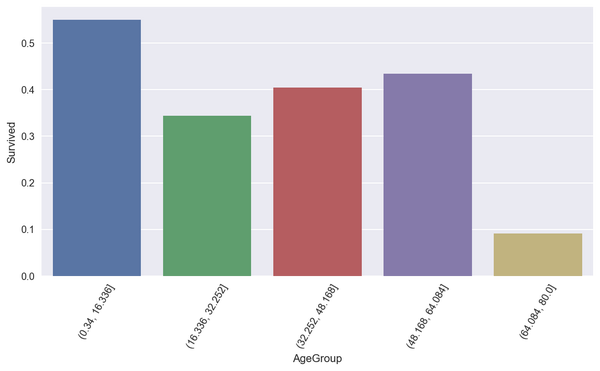
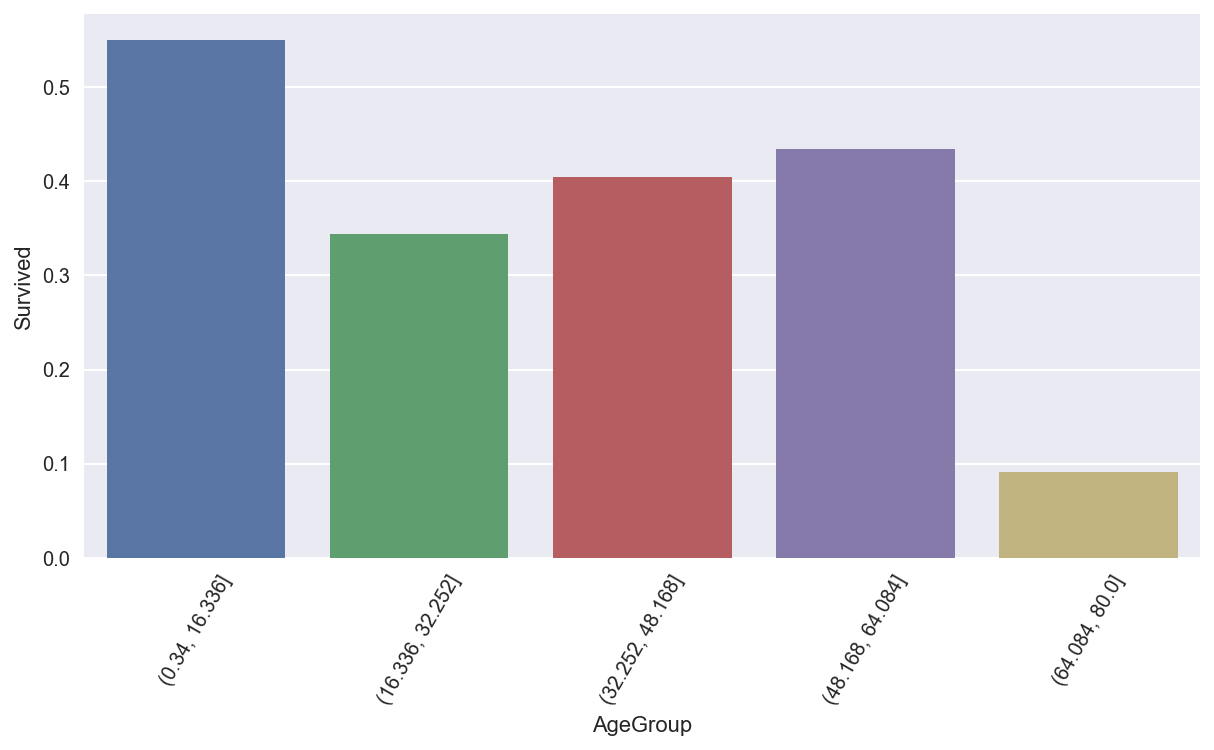
结论 :儿童少年组的生还率更高。
E.登船码头(Embarked)与生还率关系
sns.factorplot('Embarked','Survived', data=titanic_df,size=5,aspect=2)
plt.show()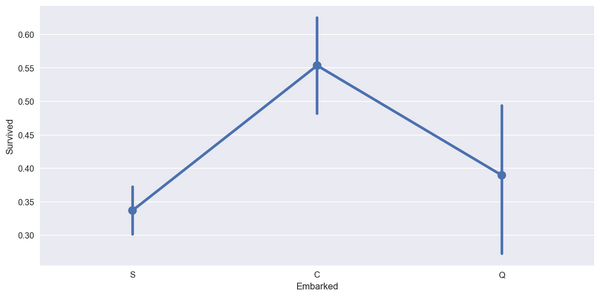
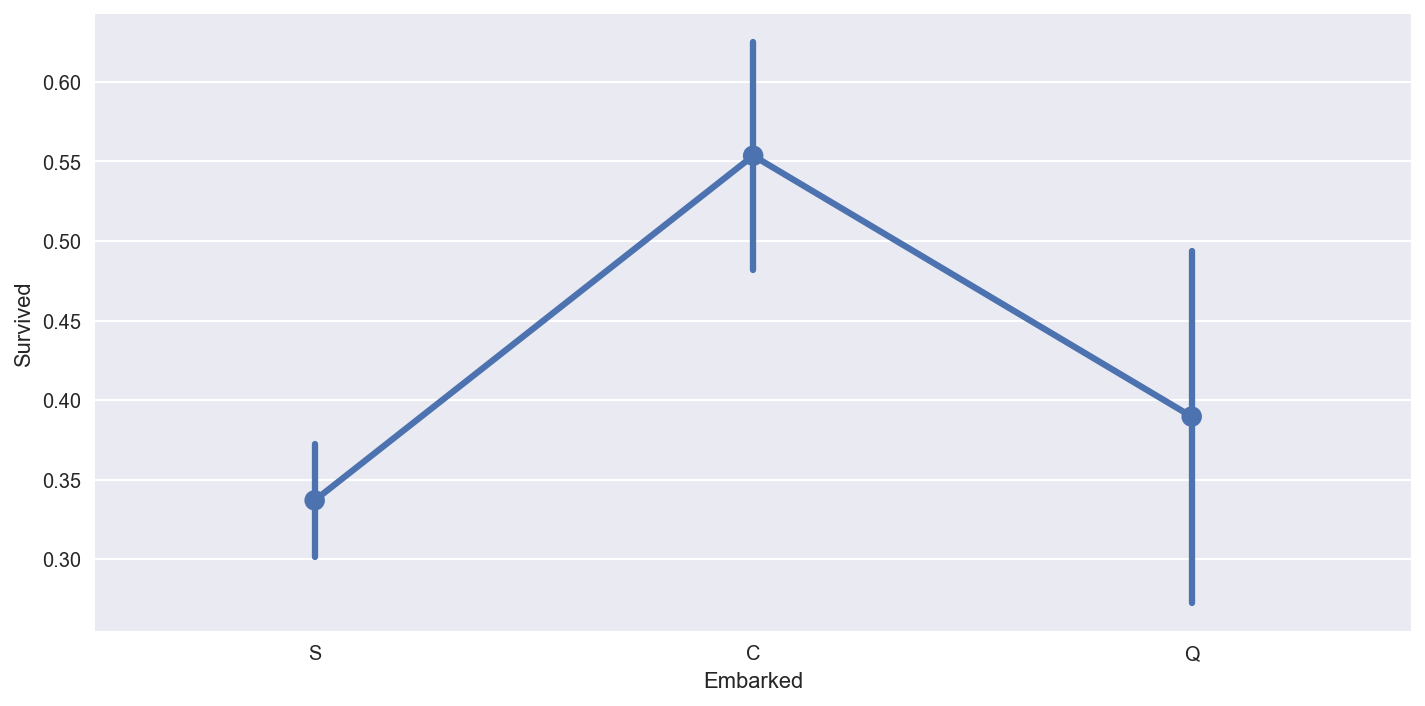
结论: 从 C 上船的生还率最高, Q 次之, S 最低。
F.多因素分析
以上是单独看年龄/性别/舱位和生还率的关系,下面我们综合多个因素来看生还率。
年龄(Age),性别(Sex)与生还率关系
titanic_df.pivot_table(values="Survived",index="AgeGroup",columns="Sex",aggfunc=np.mean)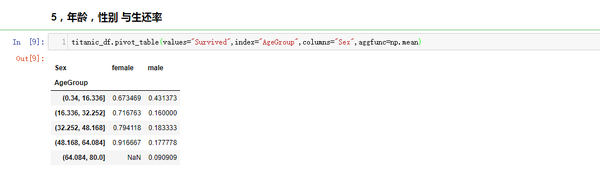
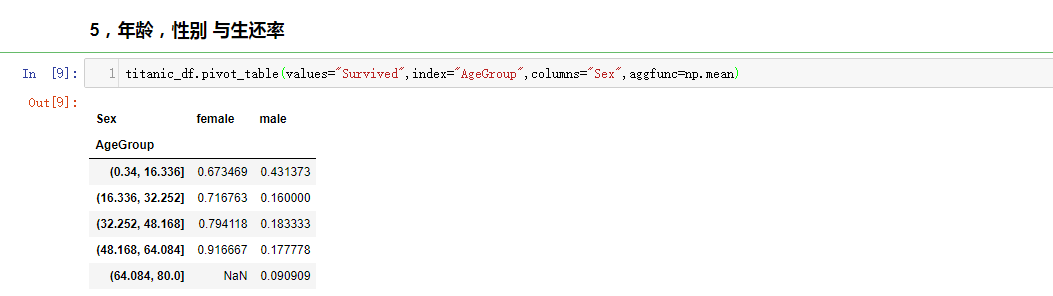
可视化分析操作
plt.figure(figsize= (10 ,5))
sns.pointplot(data=titanic_df,x="AgeGroup",y="Survived",hue="Sex",ci=None,
markers=["^", "o"], linestyles=["-", "--"])
plt.xticks(rotation=60)
plt.show()
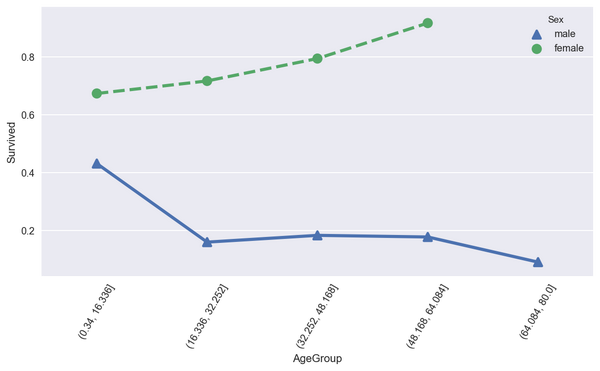
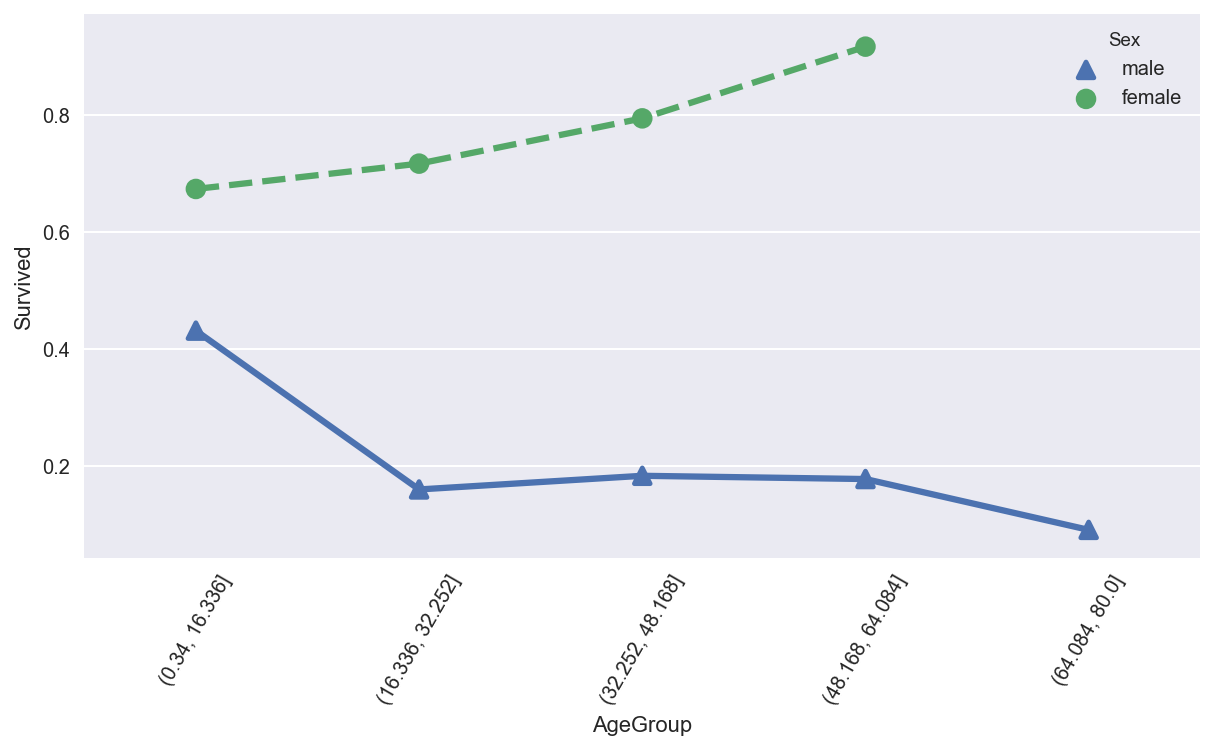
结论 :儿童少年,女性的生还率更高。男性生还的基本上都是儿童少年。
年龄(Age),性别(Sex),舱位(Pclass)与生还率关系
titanic_df.pivot_table(values="Survived",index="AgeGroup",columns=["Sex","Pclass"],aggfunc=np.mean)
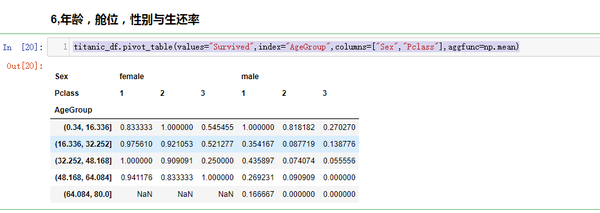
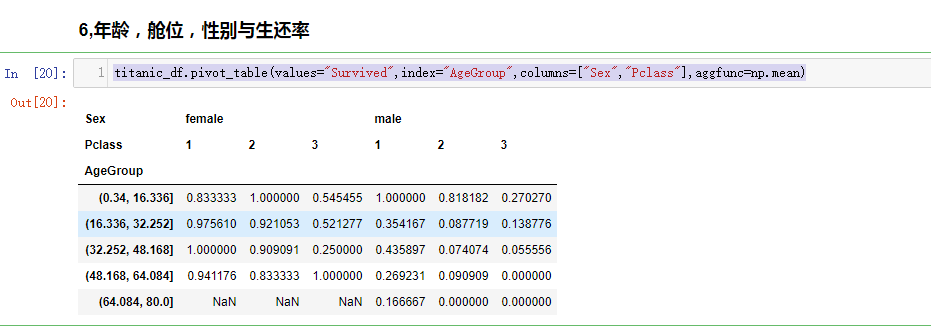
可视化分析操作
sns.FacetGrid(data=titanic_df,row="AgeGroup",aspect=2.5)\