游标统计各推广号对应的注册、登录、充值、活跃数、游戏时长等数据,并将结果插入到统计表。这里变量是在存储过程里面定义的,它的值是在存储过程的语句执行的过程中得到的。对于这种本地变量,SQL Server在编译的时候不知道它的值是多少。
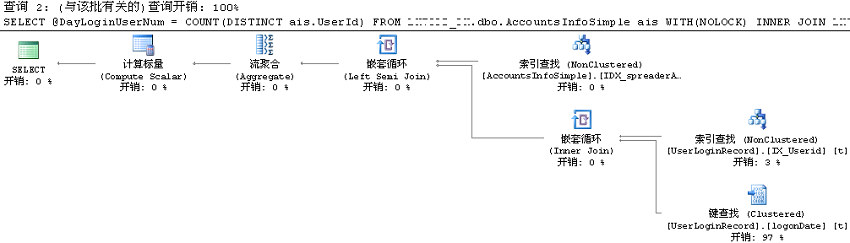
我们使用代码中提供的两个推广号分别测试存储过程的执行情况,spreaderAccount='LG0537'


spreaderAccount='LG0540'

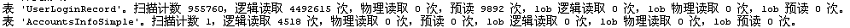

它们的执行计划相同,并不是重用了执行计划。每次都是先修改存储过程(对应缓存被清除),然后再执行存储过程。从执行计划可以看出,对于@Spreader变量的两个不同值,它对AccountsInfoSimple表的估计行数(EstimateRows)都是2978.927。但实际上LG0537只有1条记录,LG0540却有955760条记录。它们记录数直接影响UserLoginRecord的执行次数(Executes)。
一般来说,使用本地变量作出来的执行计划是一种比较"中庸"的方法,不是最快的,也不是最慢的。它对语句性能的影响,一般不会有parameter sniffing那么严重。很多时候,它还是解决parameter sniffing的一个候选方案。本例中的@Spreader是本地变量,但是它选择的执行计划并不太好。尤其是@Spreader在AccountsInfoSimple表返回记录数很多时,嵌套循环简直就是一个噩梦。
修改推广号语句where spreadAccount in('LG0537','LG0540'),实际执行计划如下:

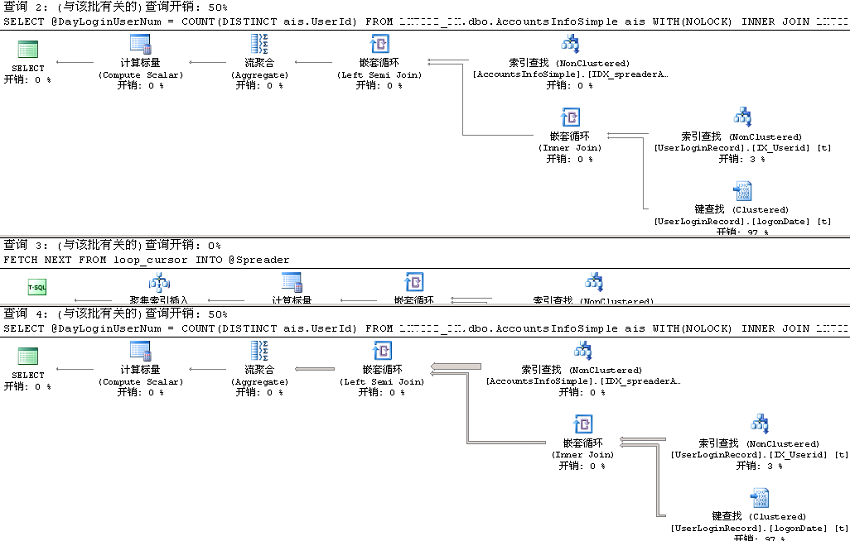
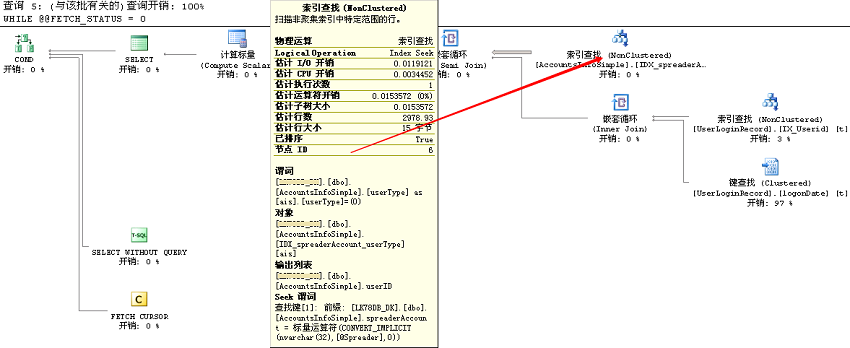
针对每一个推广号都可以看到计算@DayLoginUserNum的执行计划,并且会有每个操作的实际行数、执行次数信息。如果从sys.dm_exec_query_plan(These plans that are stored in cache do not contain runtime information such as the actual number of rows or actual number of executions.They are the estimated plans.<<SQL Server Execution Plans>>,Page52)中取对应的执行计划,只有估计信息,不能一眼看出选择的操作是否合适:
查看过程中语句执行情况:

存储过程执行一次(ProcExCount),@DayLoginUserNum语句执行两次(SQLExCount),从逻辑读、CPU时间、总时间可知,语句第二次执行占大部分开销。这里第二次的@DayLoginUserNum重用第一次的语句缓存计划。
如果在日登录用户语句的末尾加上option (recompile),再次执行后获取过程语句执行情况:

@DayLoginUserNum语句显示只执行一次,这是由于语句重编译只保留最后一次的缓存。指定语句层次的Recompile,存储过程级别的计划重用还是会有的。只是在运行到那句话的时候,才会发生重编译。下图中执行两次带option (recompile)的存储过程:

注意加上option (recompile),执行计划与之前不同,因此逻辑读、CPU时间、总时间有所差异:

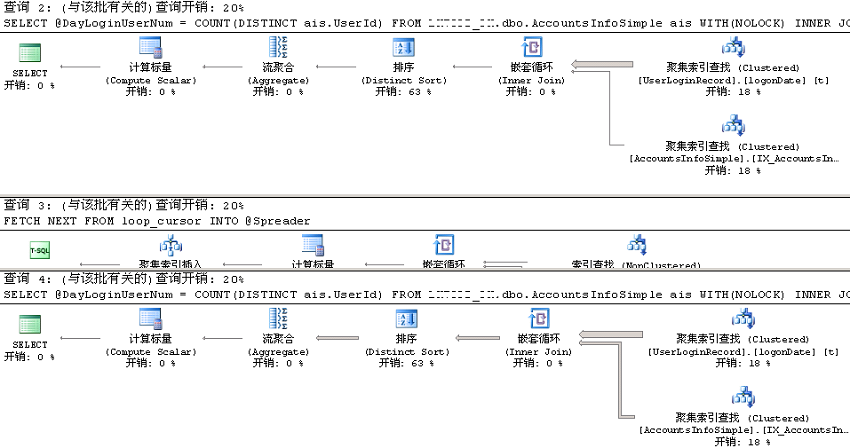
嵌套循环的外部表与内部表进行调换,使用的索引也有所改变。单独从逻辑读来看,语句加有option (recompile)貌似比不加所读取的页面要少。但,真的是这样吗?如果99%的推广号在AccountsInfoSimple表中只有少量匹配的记录,option (recompile)还合适吗?从前面的执行计划来看并不一定。我希望的是当推广号在AccountsInfoSimple表匹配记录很少时,它选择AccountsInfoSimple(外部表,IDX_spreaderAccount_userType)嵌套循环UserLoginRecord(内部表,IX_Userid);当推广号在AccountsInfoSimple表匹配记录很多时,它使用UserLoginRecord(外部表,logonDate)嵌套循环AccountsInfoSimple(内部表,IX_AccountsInfoSimple_UserID),或者两表哈希匹配得出结果。
不太明白的是,加有option (recompile),每次执行语句为什么不能选择"聪明"点的执行计划?
发现存储过程只统计了一个推广号数据,用时却比以往400+推广号还多!这个推广号对应在AccountsInfoSimple表有千万级的数据量,可是之前这个推广号也包含在内,等待核查!!!
一个推广号时
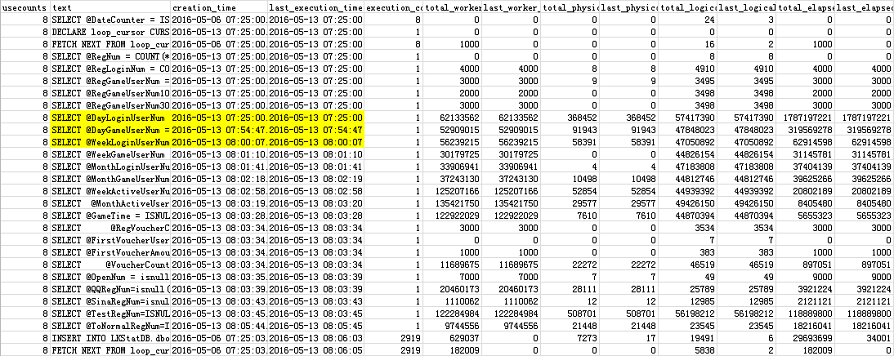
存储过程执行8次,@DayLoginUserNum语句执行一次。可以看到@DayLoginUserNum开始时间是(2016-05-13 07:25:00.363),@DayGameUserNum开始时间是(2016-05-13 07:54:47.530),中间隔了29分钟,大致等于last_elapsed_time(1787197221µs)。根据总消耗与最后消耗,可知此时sys.dm_exec_query_stats只保留了最后一次的执行,汇总存储过程中的各语句的消耗小于存储过程本身的消耗。
422个推广号时
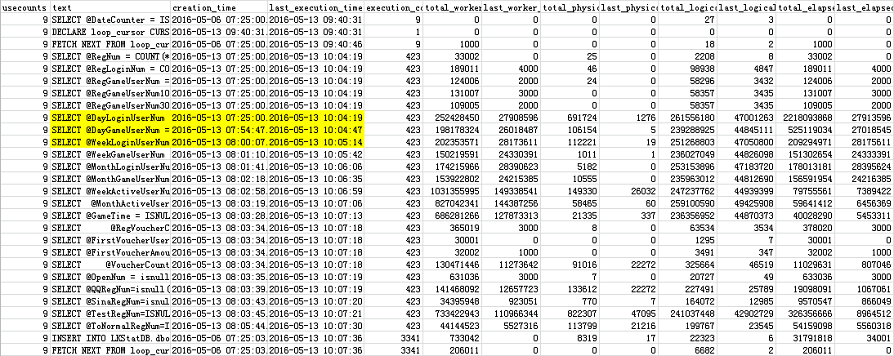
存储过程执行9次,@DayLoginUserNum执行423次(之前有执行1次)。这是由于存储过程读取游标得到422个推广号,存储过程执行一次,对应语句执行422次。@DayLoginUserNum最后执行时间是(2016-05-13 10:04:19.450),@DayGameUserNum最后执行时间是(2016-05-13 10:04:47.363),中间只隔了28秒!要知道,它们对应的是同一个推广号,时间竟然相差那么多!
上面两图最大的区别是在计算@DayLoginUserNum时的last_physical_reads,能解释的是执行一个推广号时有很多其他作业在执行,而且它的物理读太高,导致长时间的等待。执行多个推广号时,由于前面的推广号对应reads很低,对系统影响不大,随着其他作业的执行,相关数据逐渐缓存到内存,等到执行最后的推广号时,只需从内存读取数据即可。我们可以看到它们的last_logical_reads差不多。
附上05版本查看存储过程的执行情况的语句
--存储过程的执行情况(b汇总值会小于a的实际值)
SELECT top 50 CASE when c.dbid = 32767
then 'Resource'
else DB_NAME(c.dbid) end DbName
--,OBJECT_SCHEMA_NAME(c.objectid,c.dbid) AS SchName
,OBJECT_NAME(c.objectid,c.dbid) AS ObjName
,MIN(b.creation_time) AS creation_time --有时候多个计划存在于同一储存过程的缓存中
,MIN(b.last_execution_time) AS last_execution_time
,SUM(a.usecounts) AS UseCount
,SUM(b.total_logical_reads) / SUM(a.usecounts) AS avg_logical_reads
,SUM(b.total_logical_writes) / SUM(a.usecounts) AS avg_logical_writes
,SUM(b.total_worker_time) / SUM(a.usecounts) AS avg_worker_time
,SUM(b.total_elapsed_time) / SUM(a.usecounts) AS avg_elapsed_time
FROM sys.dm_exec_cached_plans a with(nolock)
INNER JOIN
(SELECT MIN(creation_time) AS creation_time
,MIN(last_execution_time) AS last_execution_time
,SUM(total_logical_reads) AS total_logical_reads
,SUM(total_logical_writes) AS total_logical_writes
,SUM(total_worker_time) AS total_worker_time
,SUM(total_elapsed_time) AS total_elapsed_time
,plan_handle
FROM sys.dm_exec_query_stats with(nolock)
GROUP BY plan_handle) b
ON a.plan_handle = b.plan_handle
CROSS APPLY sys.dm_exec_query_plan(a.plan_handle) c
--CROSS APPLY sys.dm_exec_sql_text(a.plan_handle) c --用于筛选text信息
WHERE a.objtype = 'Proc'
--AND c.text like 'Proc'
GROUP BY c.dbid,c.objectid
ORDER BY SUM(b.total_logical_reads) / SUM(a.usecounts) DESC;
--SQLCmd in Proc or Batch
SELECT top 500 CASE when c.dbid = 32767
then 'Resource'
else DB_NAME(c.dbid) end DbName
--,OBJECT_SCHEMA_NAME(c.objectid,c.dbid) AS SchName
,OBJECT_NAME(c.objectid,c.dbid) AS ObjName
,a.usecounts AS ProcExCount
--,a.plan_handle
, SUBSTRING (c.text,(b.statement_start_offset/2) + 1,
((CASE WHEN b.statement_end_offset = -1 THEN LEN(CONVERT(NVARCHAR(MAX), c.text)) * 2
ELSE b.statement_end_offset END - b.statement_start_offset)/2) + 1) RunSQL
,b.creation_time --编译计划的时间
,b.last_execution_time --上次开始执行计划的时间
,b.execution_count AS SQLExCount--计划自上次编译以来所执行的次数
,b.last_logical_reads --上次执行计划时所执行的逻辑读取次数
,b.total_logical_reads/b.execution_count avg_logical_reads
,b.last_worker_time --上次执行计划所用的 CPU 时间(微秒)
,b.last_elapsed_time --最近一次完成执行此计划所用的时间(微秒)
,b.total_elapsed_time/b.execution_count avg_elapsed_time --上次完成执行此计划所用的总时间
--,b.*
FROM sys.dm_exec_cached_plans a with(nolock)
INNER JOIN sys.dm_exec_query_stats b with(nolock)
ON a.plan_handle = b.plan_handle
CROSS APPLY sys.dm_exec_sql_text(b.sql_handle) c
WHERE a.objtype = 'Proc'
and OBJECT_NAME(c.objectid,c.dbid)='DBA_TroubleShooting'
order by a.plan_handle,b.sql_handle;
--Execution Plan
SELECT top 50 CASE when b.dbid = 32767
then 'Resource'
else DB_NAME(b.dbid) end DbName
,OBJECT_SCHEMA_NAME(b.objectid,b.dbid) AS SchName
,OBJECT_NAME(b.objectid,b.dbid) AS ObjName
,a.usecounts
,a.plan_handle
,b.query_plan
FROM sys.dm_exec_cached_plans a with(nolock)
CROSS APPLY sys.dm_exec_query_plan(a.plan_handle) b
WHERE a.objtype = 'Proc'
and OBJECT_NAME(b.objectid,b.dbid)='DBA_TroubleShooting';
--特定语句
select top 100 SUBSTRING (c.text,(b.statement_start_offset/2) + 1,
((CASE WHEN b.statement_end_offset = -1 THEN LEN(CONVERT(NVARCHAR(MAX), c.text)) * 2
ELSE b.statement_end_offset END - b.statement_start_offset)/2) + 1) RunSQL
,b.creation_time --编译计划的时间
,b.last_execution_time --上次开始执行计划的时间
,b.execution_count AS SQLExCount--计划自上次编译以来所执行的次数
,b.last_logical_reads --上次执行计划时所执行的逻辑读取次数
,b.total_logical_reads/b.execution_count avg_logical_reads
,b.last_worker_time --上次执行计划所用的 CPU 时间(微秒)
,b.last_elapsed_time --最近一次完成执行此计划所用的时间(微秒)
,b.total_elapsed_time/b.execution_count avg_elapsed_time --上次完成执行此计划所用的总时间
--,b.sql_handle,b.plan_handle
--,d.query_plan
,c.text
FROM sys.dm_exec_query_stats b with(nolock)
CROSS APPLY sys.dm_exec_sql_text(b.sql_handle) c
CROSS APPLY sys.dm_exec_query_plan(b.plan_handle) d
where c.text like '%keywords%'
View Code
存储过程里面:游标+查询语句;游标+查询语句抽离成存储过程;哪种更好?第二种会有parameter sniffing现象吗?

