

【理房通】-Spring Batch源码解读及使用手册(一)

理房通做为第三方支付公司,与备付金合作银行存在大量的支付通道交互,日终需进行通道交易明细对账及备付金账户资金对账。同时系统自身存在交易服务与账务服务的日间校验,所以理房通存在大量的批处理任务。由于理房通核心系统基于spring Boot搭建 ,所以选用业界成熟的springbatch 做为批处理技术栈选项。
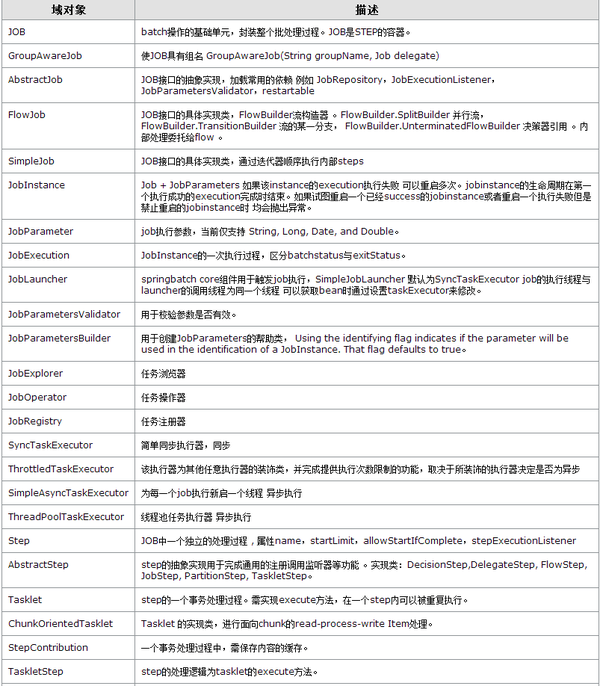
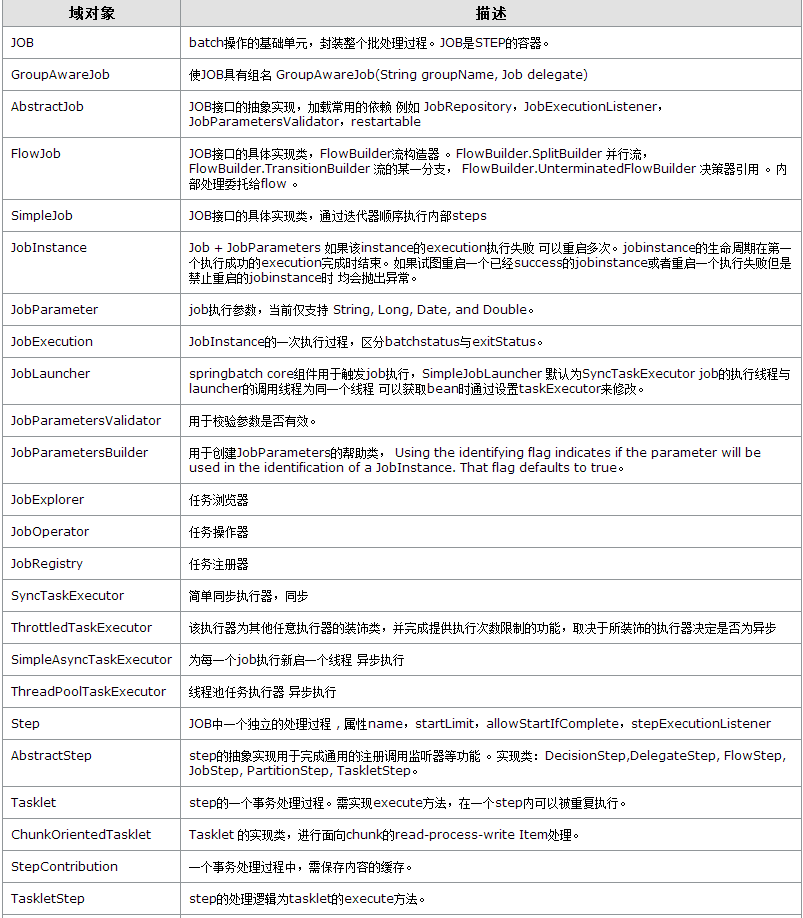
基础域
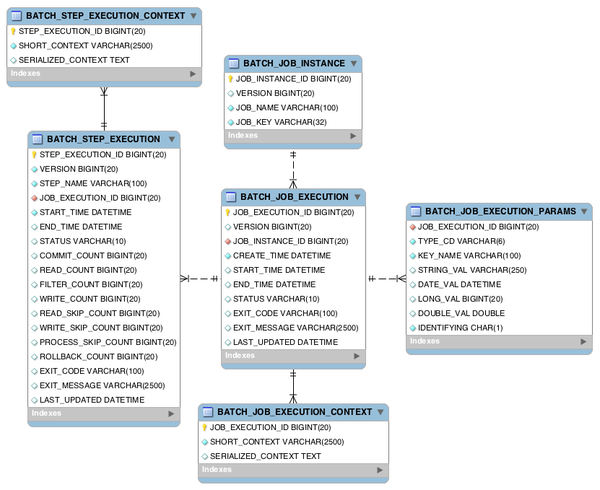
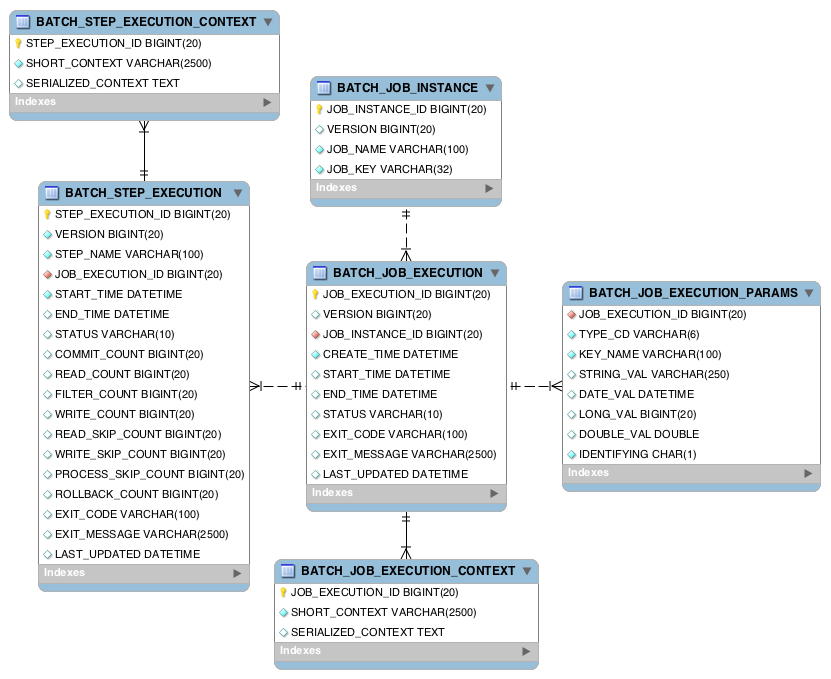
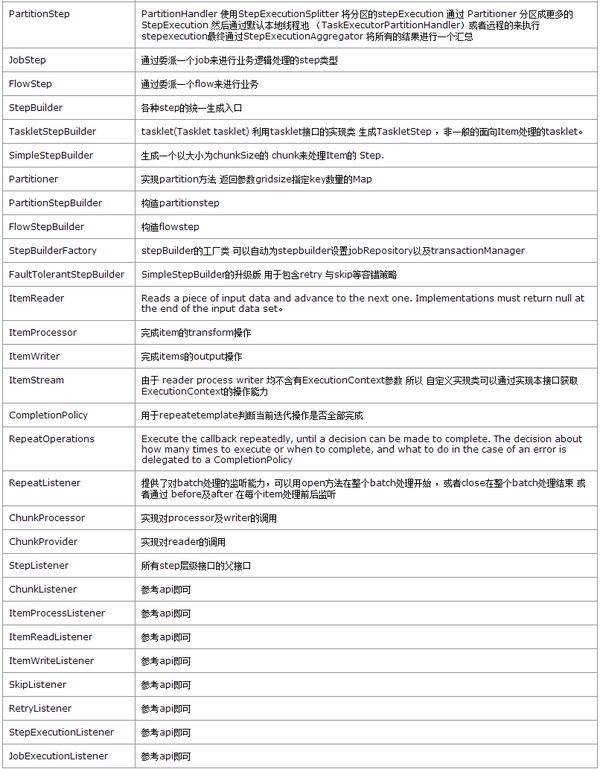

源码解读-以面向chunk处理的taskletstep为例方法调用分析
1. JobExecutionListener.beforejob();
2. 开始循环处理step。
3. StepExecutionListener.beforeStep();
4. ItemStream.open();
5. ItemStream.update();
6. CompletionPolicy.start()
7. RepeatListener.open();
8. 开始循环执行多次chunktasklet直到没有记录,或者返回终止。
9. RepeatListener.before();
10. CompletionPolicy.upadte();
11. 开始事务执行
12. ChunkListener.beforeChunk();
13. 开始循环执行多次读取item直到达到chunksize。
14. ItemReadListener.beforeRead();
15. 读取一个Item。
16. 如果开启容错机制调用FaultTolerantChunkProvider的read方法抛
17. 如果异常不允许被跳跃则继续判断该异常是否可以不回退事务。
18. 以(jdbcpagingItemReader为例) 同步方法首先读取缓存中是否存在有效记
19. 如果读取到有效Item 则调用ItemReadListener.afterRead();
20. 如果出现异常调用ItemReadListener.onReadError();
21. 在chunk事务提交之前所有的读取等操作记录数会放到stepContribution中缓
22. 开始循环处理每个Item。chunkProcessor.process(contribu
23. ItemProcessListener.beforeProcess();
24. itemProcessor.process();
25. ItemProcessListener.afterProcess();
26. 处理时判断是否容错如果是则调用FaultTolerantChunkProcessor的t
27. 调用BatchRetryTemplate的excute方法 。如果重试成功则返回retr
28. 每次执行时首先调用RetryListener的open方法
29. 之后在每次retry之间可以通过backoffpolicy初始化环境
30. 调用backoffpolicy的start方法。
31. 如果执行过程中出现异常调用backOffPolicy.backOff(backOffCo
32. 在执行过程中如果出现异常首先判断该异常是否导致数据库事务回退。
33. 如果不回退的化继续判断当前一场是否可以被skip。
34. 如果可以调用skiplistener的onSkipInProcess方法。
35. 如果不回退同时不可以跳跃则抛出异常。所以需要确保所有异常或者回退或者不回退可以被skip
36. 最后在一次执行的结束前调用RetryListener的close方法。
37. 如果存在异常ItemProcessListener.onProcessError();
38. ItemWriteListener.beforeWrite(List);
39. itemWriter.write(items);
40. ItemWriteListener.afterWrite(List);
41. 写入时判断是否容错如果是则调用FaultTolerantChunkProcessor的w
42. 当时调用itemwriter及writelistener出现异常时 不论是否设置了nor
43. 执行FaultTolerantChunkProvider.postProcess(con
44. 如果当前taskletstep创建是支持faulttolerant(容错)。
45. 根据chunk中items是否为空判断是否继续循环。
46. 事务执行完成。
47. ChunkListener.afterChunk();
48. 判断循环是否完成。
49. 完成调用ExitStatus StepExecutionListener.afterSt
50. Itemstream.close()。
51. 处理完所有step 调用JobExecutionListener.afterJob();
源码解读-以面向chunk处理的taskletstep为例
1. jobLauncher触发Job。
2. 首先利用job名称,与jobParameters获取指定instance的最后一个JobExecution实例。
3. 如果存在当前job是否允许重启。禁止的话则抛出异常
4. 判断当前JobExecution是否存在batchstatus为未知的StepExecution,存在则抛出异常。
5. 进行jobParameters参数有效性校验。
6. 创建代表本次执行的jobExecution。
7. 使用job名称与jobParameters获取jobInstance.
8. 如果存在历史jobInstance,查询该jobInstance的所有jobExecution。判断是否存在运行中的jobExecution以及是否存在BatchStatus为ABANDONED或COMPLETED的。存在则抛出异常。
9. 继续获取该jobinstance最后一次执行对应的jobexecutionContext。
10. 如果不存在历史jobInstance。则新建jobexecutionContext。
11. 将jobexecutionContext赋值与新创建的jobExecution返回。
12. 利用TaskExecutor以JobExecution为参数执行job的execute方法。
13. 触发job具体实现类SimpleJob 或FlowJob的doExecute方法。
14. SimpleStepHandler执行handlestep方法(完成JobRepository存储与steprestart 相关的操作)。
15. 依据JobExecution获取当前step的最后一次StepExecution,判断该StepExecution是否属于当前的JobExecution如果是的话,则可能是因为我们希望重启一下。
16. 继续根据最后一次StepExecution的状态以及startLimit参数来判断是否允许start。
17. 如果允许的话新建StepExecution,判断是否为step重启是的话将最后一次执行的stepExecutionContext赋值给当前StepExecution。不是重启则新建stepExecutionContext赋值与StepExecution。
18. 存储之后调用step.execute(currentStepExecution)。
19. AbstractStep执行execute方法
20. 执行StepExecutionListener的beforeStep方法。
21. 调用ItemStream的open方法。
22. 执行Step具体实现类的doExecute方法。
23. 执行stream的update方法。相关信息存入JobRepository
24. RepeatOperations对象开始迭代执行stepOperations.iterate(new StepContextRepeatCallback(stepExecution)。
25. 调用repeatTemplate的iterate方法 进而调用executeInternal方法。
26. 调用RepeatListener的open方法(每次完整的批处理执行一次)
27. 开始循环处理 首先执行RepeatListener的before方法(每个ITEM执行一次)
28. 执行RepeatTemplate的getNextResult方法 update(RepeatContext context) {completionPolicy.update(context);} 首先更改completionPolicy计数。
29. 执行StepContextRepeatCallback的doInIteration方法
30. 执行StepContextRepeatCallback的doInChunkContext方法
31. 执行ChunkTransactionCallback的doInTransaction方法。
32. 执行chunkListener.beforeChunk(chunkContext);
33. 执行result = tasklet.execute(contribution, chunkContext);
34. 分析ChunkOrientedTasklet的execute方法。
35. 执行 SimpleChunkProvider.provide(contribution)。
36. 又一次循环执行,循环执行时RepeatTemplate的executeInternal方法内部会进行 if (isComplete(context, result) || isMarkedComplete(context) || !deferred.isEmpty()) {
37. running = false;} 完成策略是否结束的判断。
38. 继续调用SimpleChunkProvider的read方法 继续doread方法,调用 beforeRead方法。
39. 继续调用itemreader的read方法
40. AbstractItemCountingItemStreamItemReader的read方法
41. 调用 AbstractPagingItemReader的 doread方法此处有线程同步所以JdbcPagingItemReader是线程安全的。
42. 继续调用 JdbcPagingItemReader的doReadPage方法。使用PagingRowMapper ,pagesize,queryProvider,parameterValues等属性一次数据库访问批量获取pageSize个元素放入results中。
43. 所以chunkProvider的provide方法被循环执行一个一个item获取直到满足了chunksize大小 然后返回。pagesize决定了从数据库中一次性读出多少个元素。chunksize决定了多少个元素进行一个事务的提交。
44. 执行 chunkProcessor.process(contribution, inputs);
45. 进行 processor和writer的调用。
46. 一个chunk执行完成后 回到taskletstep的doExecute方法中继续循环执行。taskstep在build时AbstractTaskletStepBuilder会调用createTasklet方法
47. SimpleStepBuilder的createTasklet的方法中createChunkOperations继续调用getChunkCompletionPolicy方法最终返回SimpleCompletionPolicy。指定了chunk的size 并将其设置给chunkProvider。
48. TaskletStep的完成策略是默认DefaultResultCompletionPolicy。public boolean isComplete(RepeatContext context, RepeatStatus result) 当 doInChunkContext返回null或者result标识为迭代结束。(全部记录处理完毕)
49. 执行StepExecutionListener的afterStep方法。
50. 设置执行结束时间,执行状态等属性。
51. 调用ItemStream的close方法,返回结果。
使用手册
基于javaConfig实现
ItemReader
JdbcPagingItemReader一次性的调用doreadpage方法从数据库读取多条记录,之后缓存放入list中,reader的read方法 每次从缓存中读取一个item出来,使用chunk时候 则会有chunkprovider迭代调用知道循环次数等于了chunksize之后返回chunk (chunk中有个List) 之后交给chunkprocesser 去处理和写入 chunk 。一个面向chunk的taskletstep会有多次chunk执行 每次chunk被包装为一个chunkoriendtasklet执行。所以tasklet是事务的一个基本单位。一个step可能触发多次tasklet的执行。所以说tasklet是可以repeat的。
JdbcPagingItemReader
ItemReader for reading database records using JDBC in a paging fashion.
在关闭restart功能saveState=false时 可以是线程安全的。 建议pageSize同chunksize设置为同一合理大小的数值。 常见设置 datasoure, QueryProvider ,pageSize, parameterValues以及rowMapper QueryProvider 可以通过工厂类创建 常见属性 select where from group sortkey 等
@Bean("jdbcReader")
@JobScope
public JdbcPagingItemReader<User> pageingReader() throws Exception {
String selectClause = "";
String fromClause = "";
String whereClause = "where ( first_name like :first_name or last_name like :last_name ) ";
String groupClause = "";
int pageSize = 10;
SqlPagingQueryProviderFactoryBean factory = new SqlPagingQueryProviderFactoryBean();
factory.setSortKey("");
factory.setSortKeys(new HashMap<String, Order>());
factory.setDataSource(null);
factory.setSelectClause(selectClause);
factory.setFromClause(fromClause);
factory.setWhereClause(whereClause);
factory.setGroupClause(groupClause);
Map<String, Object> parameterValues = new HashMap<String, Object>();
parameterValues.put("first_name", "#{jobParameters['first_name']}");
parameterValues.put("last_name", "#{jobExecutionContext['input.name']}");
JdbcPagingItemReader<User> reader = new JdbcPagingItemReader<User>();
reader.setQueryProvider(factory.getObject());
reader.setPageSize(pageSize);
reader.setParameterValues(parameterValues);
reader.setRowMapper(new UserRowMapper());
return reader;
@Bean("jdbcwriter")
@JobScope
public JdbcBatchItemWriter<User> batchWriter() throws Exception {
JdbcBatchItemWriter<User> writer = new JdbcBatchItemWriter<User>();
writer.setSql("insert into lift_c.user values (:id,:username, :password , : age)");
ItemSqlParameterSourceProvider<User> provider = new BeanPropertyItemSqlParameterSourceProvider<User>();
writer.setItemSqlParameterSourceProvider(provider);
writer.setDataSource(null);
return writer;
FlatFileItemReader
Restartable ItemReader that reads lines from input setResource(Resource). Line is defined by the setRecordSeparatorPolicy(RecordSeparatorPolicy) and mapped to item using setLineMapper(LineMapper). If an exception is thrown during line mapping it is rethrown as FlatFileParseException adding information about the problematic line and its line number.
@Bean("fileReader")
@JobScope
public FlatFileItemReader<User> fileReader() throws Exception {
FlatFileItemReader<User> reader = new FlatFileItemReader<User>();
String[] comments = { "#" };
reader.setComments(comments);// 注释的前缀
Resource resource = new FileSystemResource("#{jobParameters['filepath']}");// 绝对路径
reader.setResource(resource);
reader.setEncoding("UTF-8");// 字符编码
reader.setSaveState(true);// 多线程初始时需要设置为false,同时失去了restart的功能
//PassThroughLineMapper passLineMappe = new PassThroughLineMapper();// 不加任何修改的映射
// reader.setLineMapper(passLineMappe);// 行与bean的映射器
DefaultLineMapper<User> dmapper = new DefaultLineMapper<User>();
BeanWrapperFieldSetMapper<User> bmapper = new BeanWrapperFieldSetMapper<User>();
bmapper.setPrototypeBeanName("user");// 引用一个bean 为prototype类型
dmapper.setFieldSetMapper(bmapper);
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setDelimiter("|");
String[] names = { "pkid", "id" };
tokenizer.setNames(names);
dmapper.setLineTokenizer(tokenizer);
reader.setLineMapper(dmapper);
reader.setName("");
reader.setLinesToSkip(1);// 文件起始几行需要被跳过
return reader;
自定义Processor
@Component("itemProcessor")
@Scope(value = "step")
public class UserProcessor implements ItemProcessor<User, User> {
@Value("#{stepExecutionContext[name]}")
private String threadName;
@Override
public User process(User item) throws Exception {
System.out.println(threadName + " processing : " + item.getId() + " : " + item.getUsername());
return item;
public String getThreadName() {
return threadName;