|
|
|


为什么 ThreadLocal 可以做到线程隔离?
关注者
158
被浏览
77,030
34 个回答


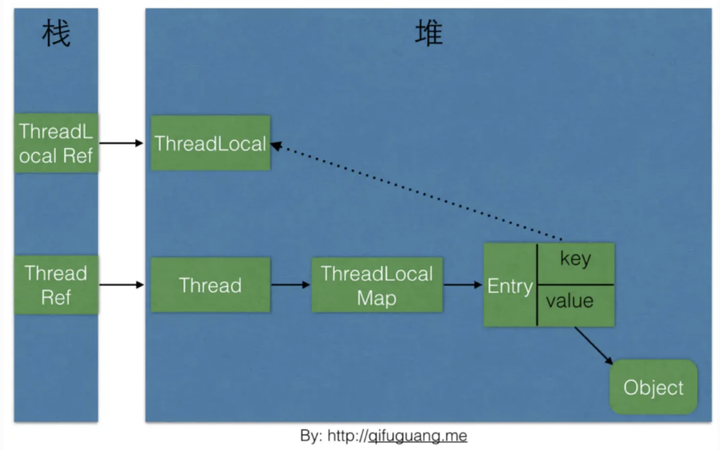
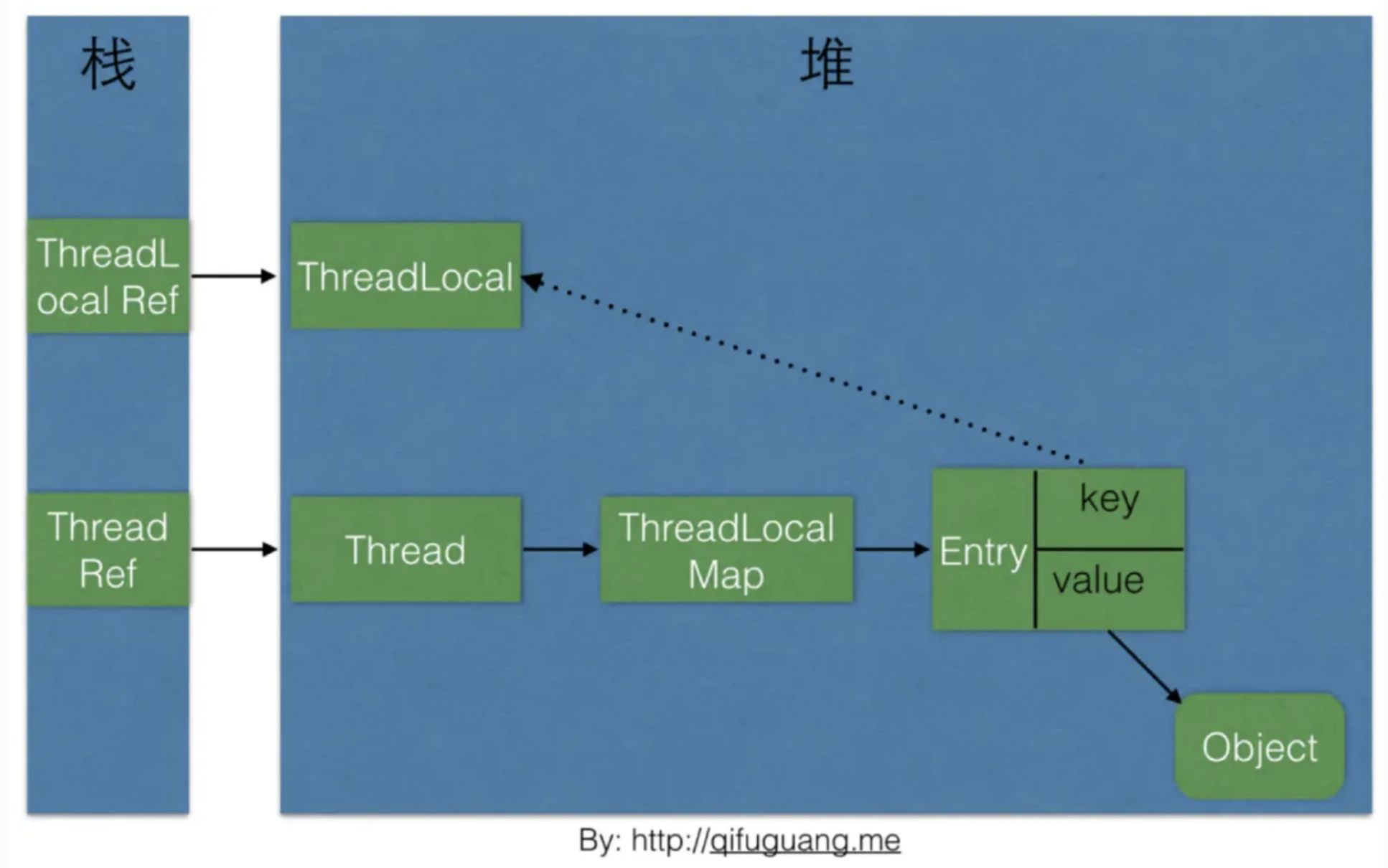
之所以 ThreadLocal 可以做到线程隔离,是因为有操作系统的支持,在 x86(32/64) 上,通过 fs/gs 寄存器指向线程控制块,从而可以实现每个线程有各自私有的存储空间,就是 ThreadLocal 。其它平台上,也是通过类似的方式来实现(专门的寄存器来指向线程控制块)。
ThreadLocal 的性能可以非常高,相比普通全局变量只多一次间接访问,但是这种 ThreadLocal 必须静态分配。为了在灵活性与性能之间折衷,ELF 有 4 种 ThreadLocal 模型(太长不看) ,简单点说就是除静态分配 ThreadLocal 最快,其它的都慢。
使用 ThreadLocal 的目的一般有两种:
- 业务需求线程级的作用域/生存期
- 提升性能(减少写写/读写冲突,降低甚至消除锁需求)

省流:ThreadLocal是一个 壳子 ,真正的存储结构是ThreadLocal里有 ThreadLocalMap 这么个 内部类 。ThreadLocalMap该结构 本身就在Thread 下定义,而 ThreadLocal只是作为key ,存储set到ThreadLocalMap的变量当然是线程私有的咯
面试官 : 今天要不来聊聊ThreadLocal吧?
候选者 :我个人对ThreadLocal理解就是
候选者 :它提供了线程的局部变量,每个线程都可以通过set/get来对这个局部变量进行操作
候选者 :不会和其他线程的局部变量进行冲突,实现了线程的数据隔离
面试官 : 你在工作中有用到过ThreadLocal吗?
候选者 :这块是真不多,不过还是有一处的。就是我们项目有个的DateUtils工具类
候选者 :这个工具类主要是对时间进行格式化
候选者 :格式化/转化的实现是用的SimpleDateFormat
候选者 :但众所周知SimpleDateFormat不是线程安全的,所以我们就用ThreadLocal来让每个线程装载着自己的SimpleDateFormat对象
候选者 :以达到在格式化时间时,线程安全的目的
候选者 :在方法上创建SimpleDateFormat对象也没问题,但每调用一次就创建一次有点不优雅
候选者 :在工作中ThreadLocal的应用场景确实不多,但要不我给你讲讲Spring是怎么用的?
面试官 :好吧,你讲讲呗
候选者 :Spring提供了事务相关的操作,而我们知道事务是得保证一组操作同时成功或失败的
候选者 :这意味着我们一次事务的所有操作需要在同一个数据库连接上
候选者 :但是在我们日常写代码的时候是不需要关注这点的
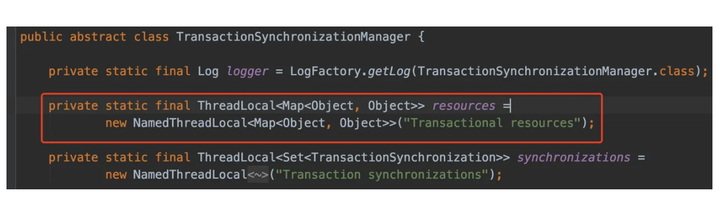
候选者 :Spring就是用的ThreadLocal来实现,ThreadLocal存储的类型是一个Map
候选者 :Map中的key 是DataSource,value 是Connection(为了应对多数据源的情况,所以是一个Map)
候选者 :用了ThreadLocal保证了同一个线程获取一个Connection对象,从而保证一次事务的所有操作需要在同一个数据库连接上
面试官 :了解
面试官 : 你知道ThreadLocal内存泄露这个知识点吗?
候选者 :怎么都喜欢问这个…
候选者 :了解的,要不我先来讲讲ThreadLocal的原理?
面试官 :请开始你的表演吧
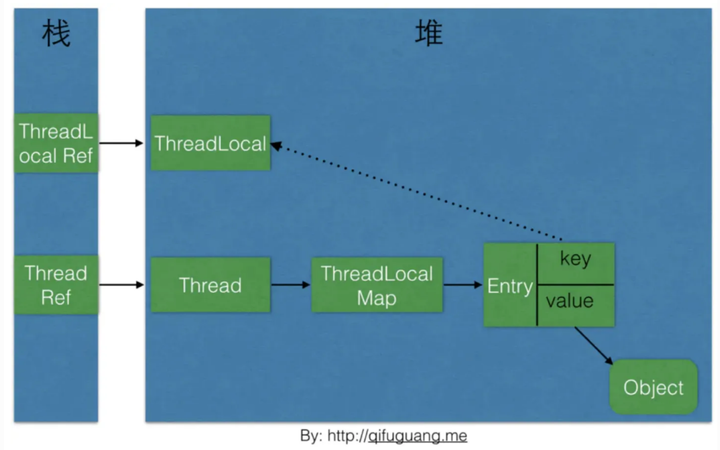
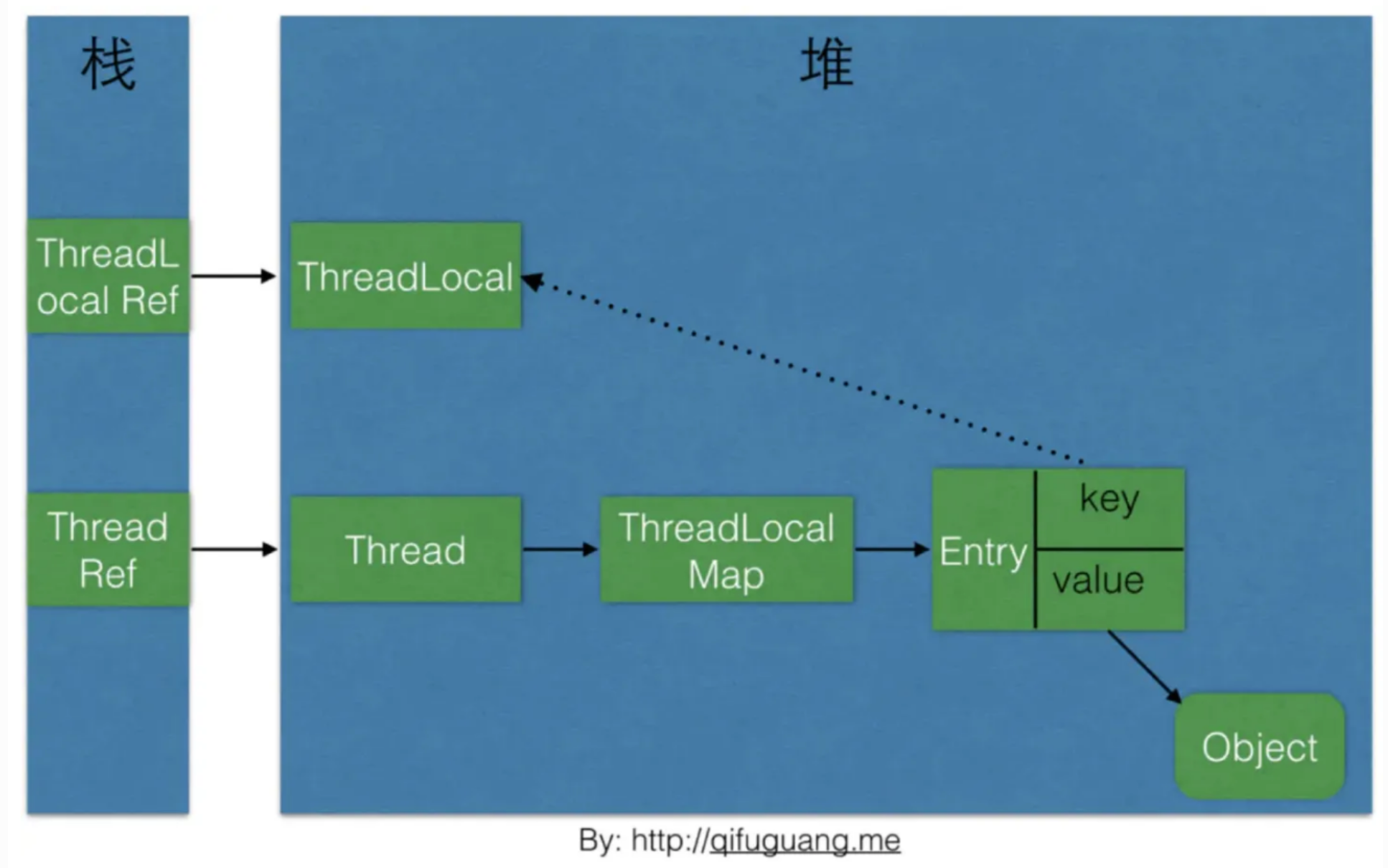
候选者 :ThreadLocal是一个壳子,真正的存储结构是ThreadLocal里有ThreadLocalMap这么个内部类
候选者 :而有趣的是,ThreadLocalMap的引用是在Thread上定义的
候选者 :ThreadLocal本身并不存储值,它只是作为key来让线程从ThreadLocalMap获取value
候选者 :所以,得出的结论就是ThreadLocalMap该结构本身就在Thread下定义,而ThreadLocal只是作为key,存储set到ThreadLocalMap的变量当然是线程私有的咯
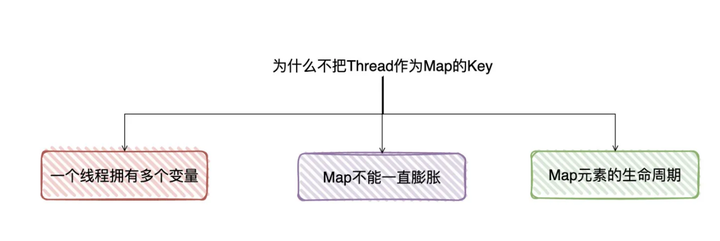
面试官 :那我想问下,我可以在ThreadLocal下定义Map,key是Thread,value是set进去的值吗?
面试官 :就是说,为啥我要把ThreadLocal做为key,而不是Thread做为key?这样不是更清晰吗?
候选者 :嗯,我明白你的意思。
候选者 :理论上是可以,但没那么优雅。
候选者 :你提出的做法实际上就是所有的线程都访问ThreadLocal的Map,而key是当前线程
候选者 :但这有点小问题,一个线程是可以拥有多个私有变量的嘛,那key如果是当前线程的话,意味着还点做点「手脚」来唯一标识set进去的value
候选者 :假设上一步解决了,还有个问题就是;并发量足够大时,意味着所有的线程都去操作同一个Map,Map体积有可能会膨胀,导致访问性能的下降
候选者 :这个Map维护着所有的线程的私有变量,意味着你不知道什么时候可以「销毁」
候选者 :现在JDK实现的结构就不一样了。
候选者 :线程需要多个私有变量,那有多个ThreadLocal对象足以,对应的Map体积不会太大
候选者 :只要线程销毁了,ThreadLocalMap也会被销毁
面试官 :嗯,了解。
面试官 : 回到ThreadLocal内存泄露上吧,谈谈你对这个的理解呗
候选者 :ThreadLocal内存泄露其实发生的概率非常非常低,我也不知道为什么这么喜欢问。
候选者 :回到原理上,我们知道Thread在创建的时候,会有栈引用指向Thread对象,Thread对象内部维护了ThreadLocalMap引用
候选者 :而ThreadLocalMap的Key是ThreadLocal,value是传入的Object
候选者 :ThreadLocal对象会被对应的栈引用关联,ThreadLocalMap的key也指向着ThreadLocal
候选者 :ThreadLocalRef && ThreadLocalMap Entry key ->ThreadLocal
候选者 :ThreadRef->Thread->ThreadLoalMap-> Entry value-> Object
候选者 :网上大多分析的是ThreadLocalMap的key是弱引用指向ThreadLocal
面试官 :嗯… 要不顺便讲讲Java的4种引用吧
候选者 :强引用是最常见的,只要把一个对象赋给一个引用变量,这个引用变量就是一个强引用
候选者 :强引用:只要对象没有被置null,在GC时就不会被回收
候选者 :软引用相对弱化了一些,需要继承 SoftReference实现
候选者 :软引用:如果内存充足,只有软引用指向的对象不会被回收。如果内存不足了,只有软引用指向的对象就会被回收
候选者 :弱引用又更弱了一些,需要继承WeakReference实现
候选者 :弱引用:只要发生GC,只有弱引用指向的对象就会被回收
候选者 :最后就是虚引用,需要继承PhantomReference实现
候选者 :虚引用的主要作用是:跟踪对象垃圾回收的状态,当回收时通过引用队列做些「通知类」的工作


候选者 :了解了这几种引用之后,再回过头来看ThreadLocal
面试官 :嗯..
候选者 :ThreadLocal内存泄露指的是:ThreadLocal被回收了,ThreadLocalMap Entry的key没有了指向
候选者 :但Entry仍然有ThreadRef->Thread->ThreadLoalMap-> Entry value-> Object 这条引用一直存在导致内存泄露
面试官 :嗯..
候选者 :为什么我说导致内存泄露的概率非常低呢,我觉得是这样的
候选者 :首先ThreadLocal被两种引用指向
候选者 :1):ThreadLocalRef->ThreadLocal(强引用)
候选者 :2):ThreadLocalMap Entry key ->ThreadLocal(弱引用)
候选者 :只要ThreadLocal没被回收(使用时强引用不置null),那ThreadLocalMap Entry key的指向就不会在GC时断开被回收,也没有内存泄露一说法
候选者 :通过ThreadLocal了解实现后,又知道ThreadLocalMap是依附在Thread上的,只要Thread销毁,那ThreadLocalMap也会销毁
候选者 :那非线程池环境下,也不会有长期性的内存泄露问题
候选者 :而ThreadLocal实现下还做了些”保护“措施,如果在操作ThreadLocal时,发现key为null,会将其清除掉
候选者 :所以,如果在线程池(线程复用)环境下,如果还会调用ThreadLocal的set/get/remove方法
候选者 :发现key为null会进行清除,不会有长期性的内存泄露问题
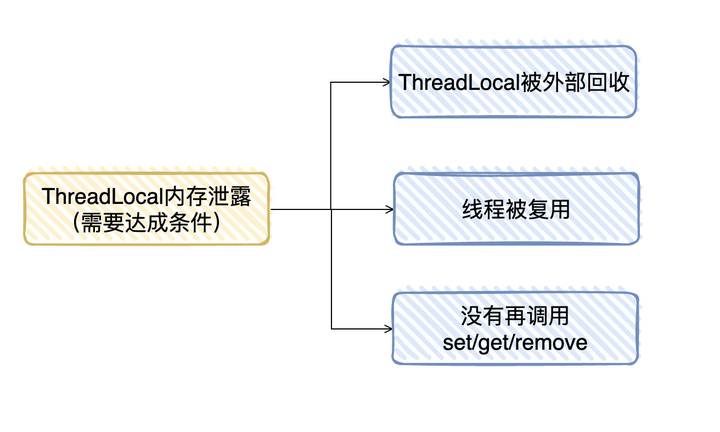
候选者 :那存在长期性内存泄露需要满足条件:ThreadLocal被回收&&线程被复用&&线程复用后不再调用ThreadLocal的set/get/remove方法
候选者 :使用ThreadLocal的最佳实践就是:用完了,手动remove掉。就像使用Lock加锁后,要记得解锁
面试官 :那我想问下, 为什么要将ThreadLocalMap的key设置为弱引用呢?强引用不香吗?
候选者 :外界是通过ThreadLocal来对ThreadLocalMap进行操作的,假设外界使用ThreadLocal的对象被置null了,那ThreadLocalMap的强引用指向ThreadLocal也毫无意义啊。
候选者 :弱引用反而可以预防大多数内存泄漏的情况
候选者 :毕竟被回收后,下一次调用set/get/remove时ThreadLocal内部会清除掉
面试官 : 我看网上有很多人说建议把ThreadLocal修饰为static,为什么?
候选者 :ThreadLocal能实现了线程的数据隔离,不在于它自己本身,而在于Thread的ThreadLocalMap
候选者 :所以,ThreadLocal可以只初始化一次,只分配一块存储空间就足以了,没必要作为成员变量多次被初始化。
面试官 :最后想问个问题: 什么叫做内存泄露?
候选者 :…..
候选者 :意思就是:你申请完内存后,你用完了但没有释放掉,你自己没法用,系统又没法回收。
面试官 :清楚了
本文总结 :
- 什么是ThreadLocal :它提供了线程的局部变量,每个线程都可以通过set/get来对这个局部变量进行操作,不会和其他线程的局部变量进行冲突,实现了线程的数据隔离。
- ThreadLocal实际用处 (举例):Spring事务,ThreadLocal里存储Map,Key是DataSource,Value是Connection
- ThreadLocal设计 :Thread有ThreadLocalMap引用,ThreadLocal作为ThreadLocalMap的Key,set和get进去的Value则是ThreadLocalMap的value
- ThreadLocal内存泄露 :ThreadLocal被回收&&线程被复用&&线程复用后不再调用ThreadLocal的set/get/remove方法 才可能发生内存泄露(条件还是相对苛刻)
- ThreadLocal最佳实践 :用完就要remove掉


Java开源项目推荐
我推荐一个拥有从零开始的文档的Java开源项目, 既能用于毕业设计,又可以用在面试 。已经有不少的同学通过这个项目拿到了 大厂的offer啦 (美团/vivo/阿里等等)
该项目业务极容易理解,代码结构是比较清晰的,最可怕的是几乎每个方法和每个类都带有中文注释,并且代码完全通过阿里开发插件检查。
拥有非常全的文档,作者从零搭建的过程都有详细地记录,项目里使用了蛮多的可靠和稳定的中间件的。在使用每一个技术栈之前作者都讲述了为什么要使用,以及它的业务背景。我看过, 他所说的场景是完全贴合线上环境的 。
我感觉这个项目就是 奔着真实互联网线上项目 去设计和实现的,将项目克隆下来把中间件换成目前公司在用的,配合自身的需求完善下基础建设,它就能在线上运行了。
我跟着README文档的部署使用姿势很快就能跑起来, 最少只需要依赖MySQL和Redis 。作者还搞了个前端功能界面,这就让系统变得更好理解了。而且,在GitHub或者Gitee所提的Issue几乎都会有回复,看出来也非常乐于合并开发者们的pull request, 会让人参与感贼强 。
我相信在校、工作一年左右或常年做内网CRUD后台的同学去看看 肯定会有所启发 ,作者也会经常在群里回答该项目相关的问题和代码设计思路。
项目里会应用到各种 设计模式 (我稍微看了下,应该有7~8种吧),用到了各种的好用的工具组件, 动态线程池、日志切面 组件之类,都是 主流的技术栈 ...目前这个项目GitHub和Gitee加起来已经 9K stars 了,我相信 破万 是迟早的事情。
项目Gitee链接:
项目GitHub链接:
项目文档&视频 :
项目介绍
核心功能 :统一的接口发送各种类型消息,对消息生命周期全链路追踪。
意义 :只要公司内部有发送消息的需求,都应该要有类似 消息推送平台 的项目。消息推送平台对各类消息进行统一发送处理,这有利于对功能的收拢,以及提高业务需求开发的效率。
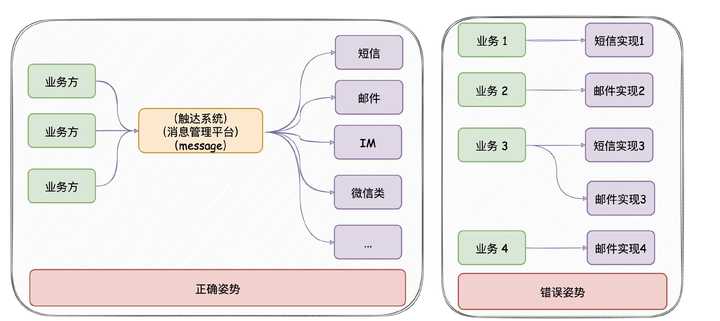
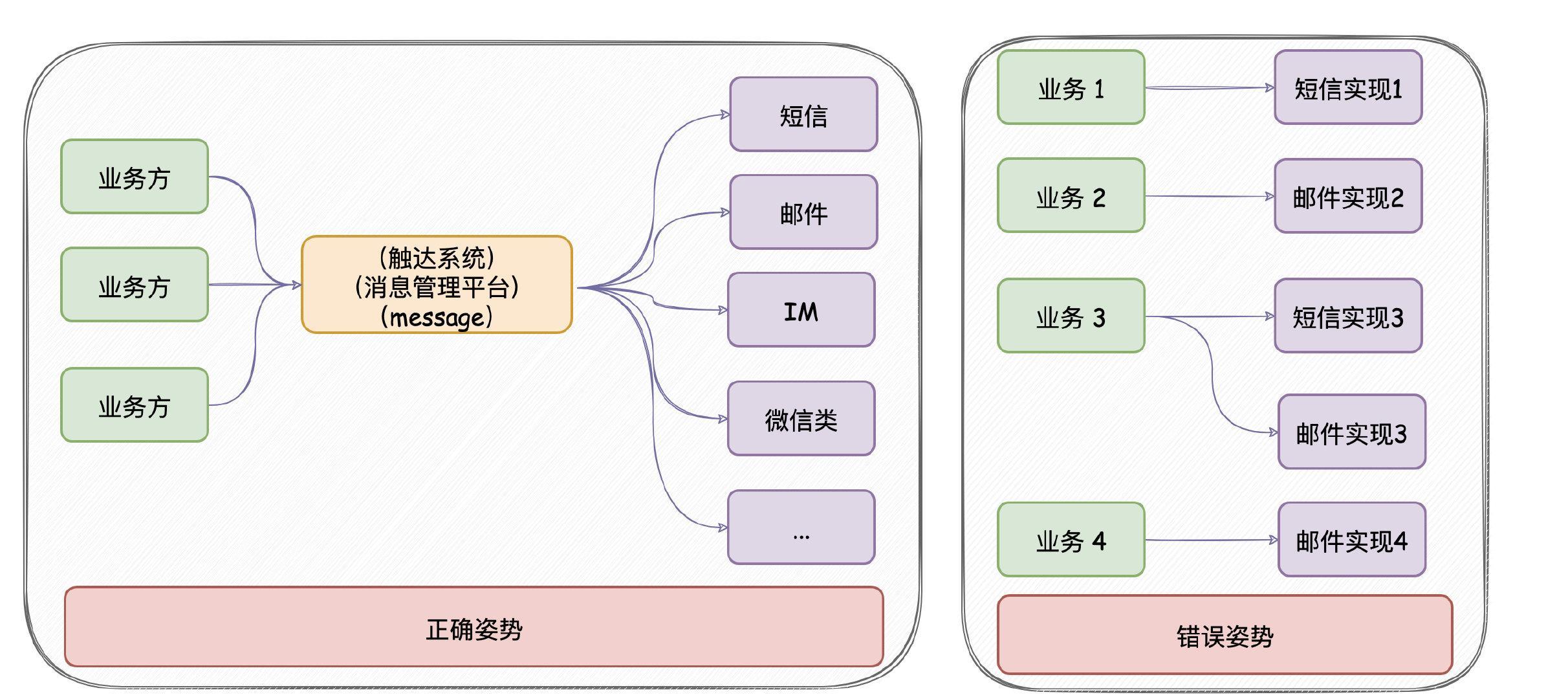
技术栈
| 技术栈 | 实现 |
|---|---|
| 编程语言 | Java(JDK 1.8) |
| 项目管理工具 | Maven 3.x |
| 集成开发工具 | IDEA 2022 |
| 部署服务器 | Centos 7.6 |
| 系统部署工具 | Docker & Docker-compose |
| 项目环境 | SpringBoot 2.5.6 |
| 关系型数据库 | MySQL 5.7.X |
| 缓存数据库 | Redis:lastest |
| ORM框架 | SpringData JPA 2.5.6 |
| 分布式定时任务框架 | XXL-JOB v2.3.0 |
| 分布式配置中心 | Apollo & Nacos |
| 消息队列 | Kafka & RabbitMQ & RocketMQ |
| 分布式日志采集框架 | Graylog |
| 分布式计算引擎 | Flink 1.16.0 |
| 监控采集组件 | Prometheus |
| 监控可视化组件 | Grafana |
| 数据仓库 | Hive 2.3.2 |
| 大数据环境 | Hadoop 2.7.4 |
| 大数据可视化 | Metabase:lastest |
| 前端技术 | Amis |
使用教程
项目有预览地址,可自行体验 : http:// 139.9.66.219:3000/
1 、创建需要发送的渠道账号
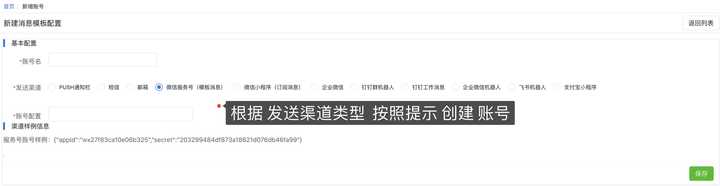
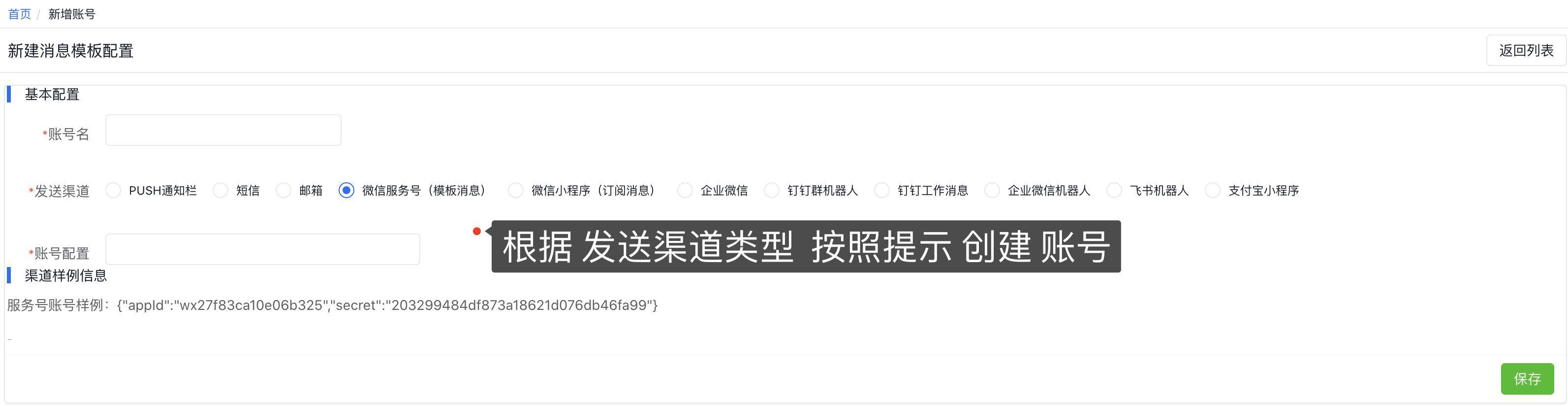
2 、创建消息模板
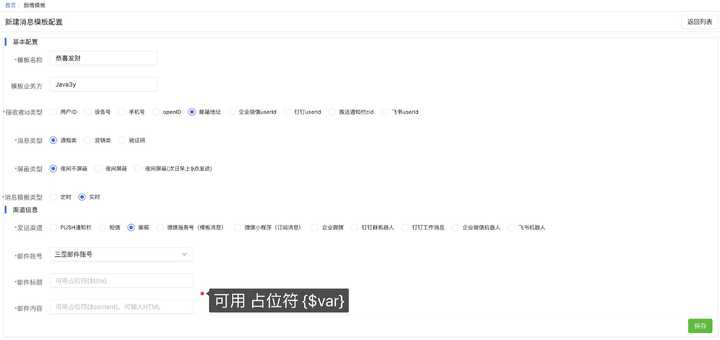
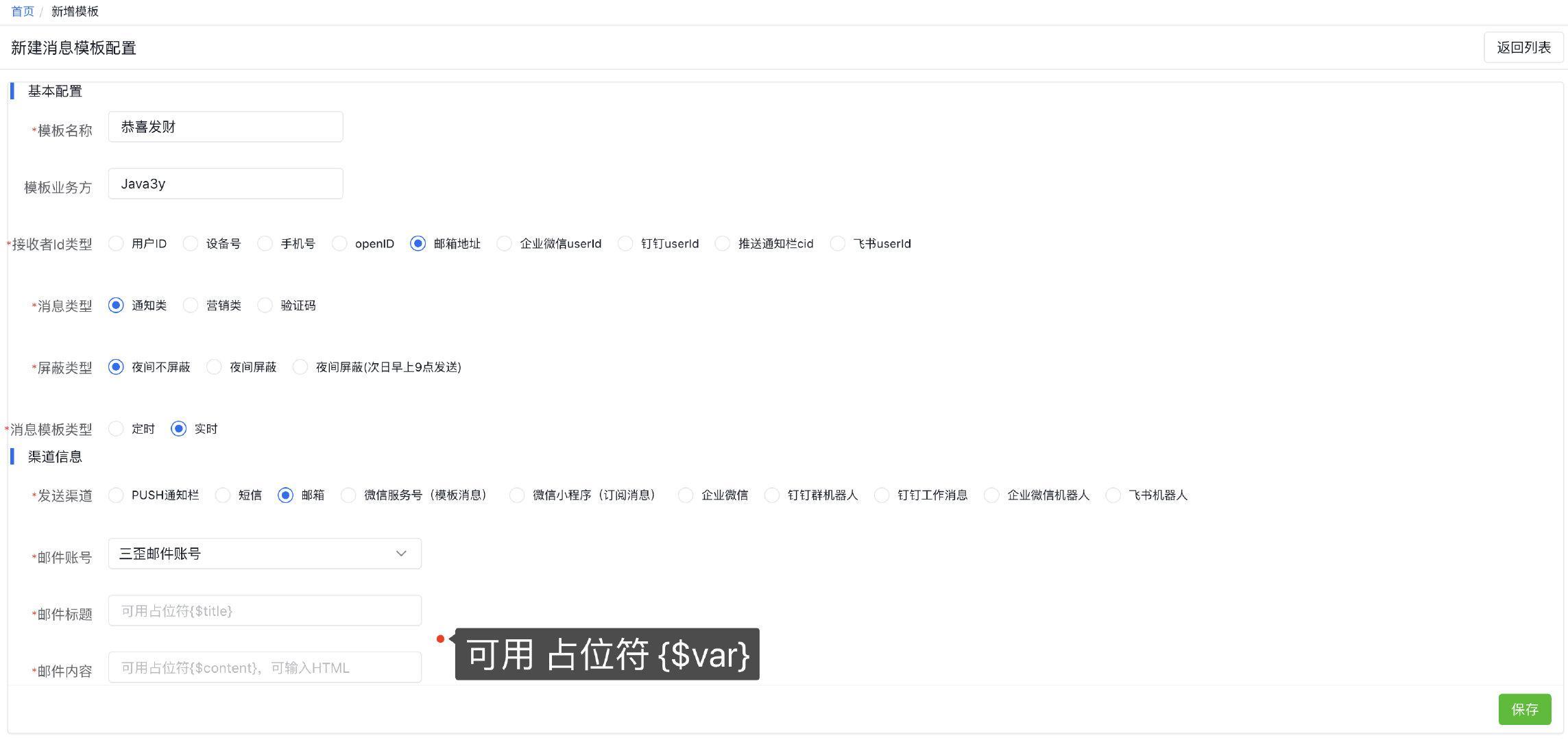
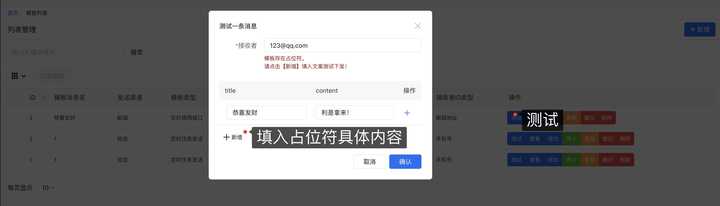
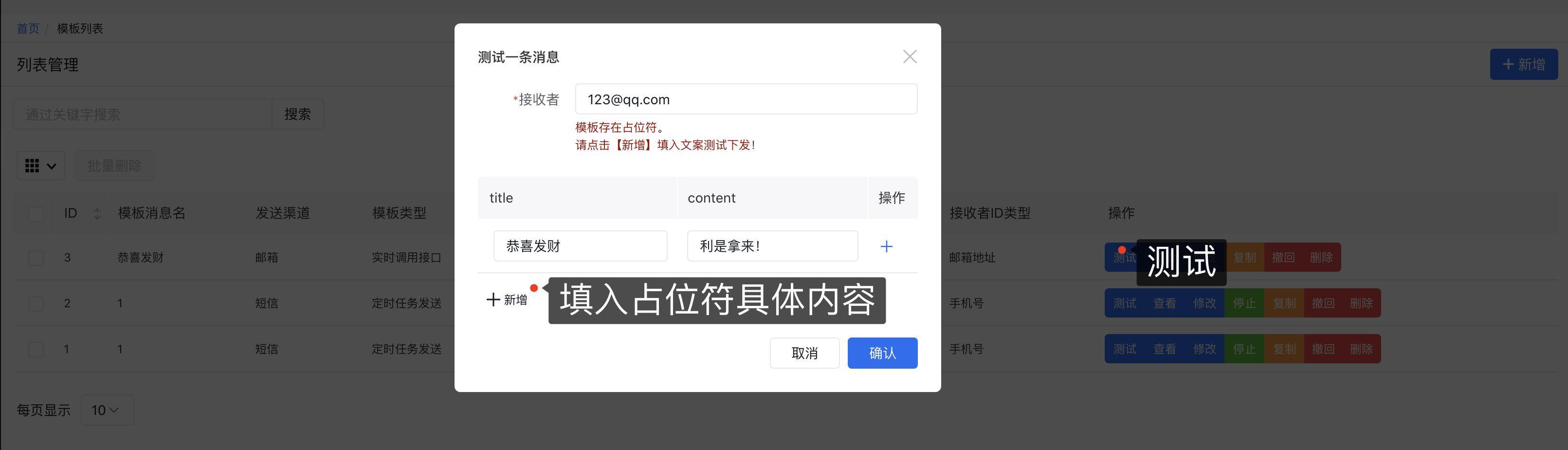
3 、测试发送消息是否正常
4 、查看消息下发情况
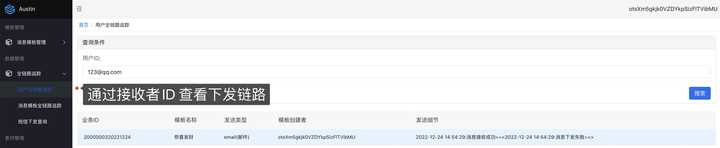
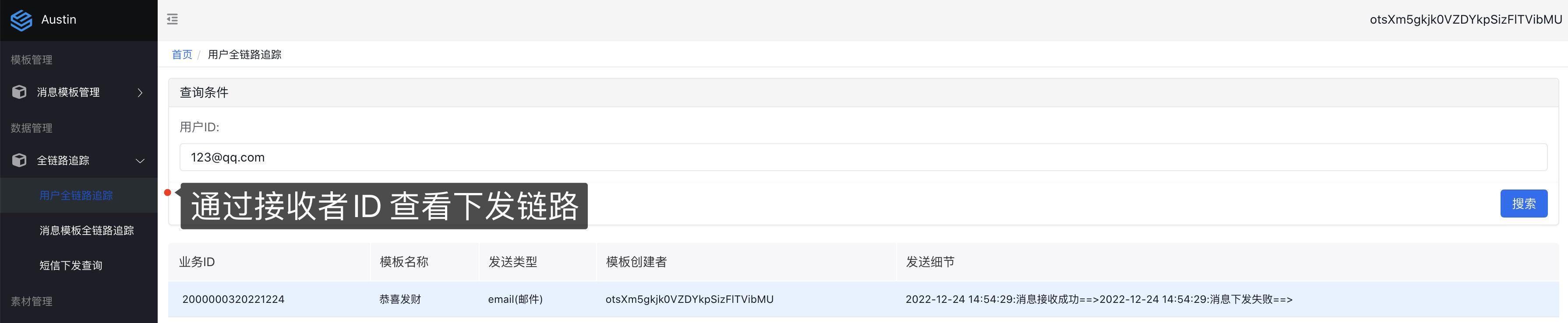
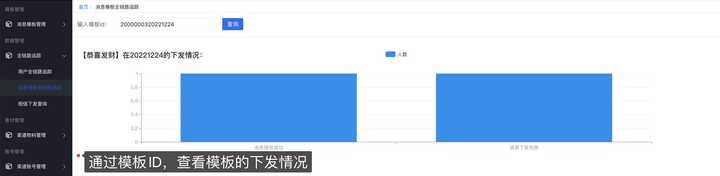
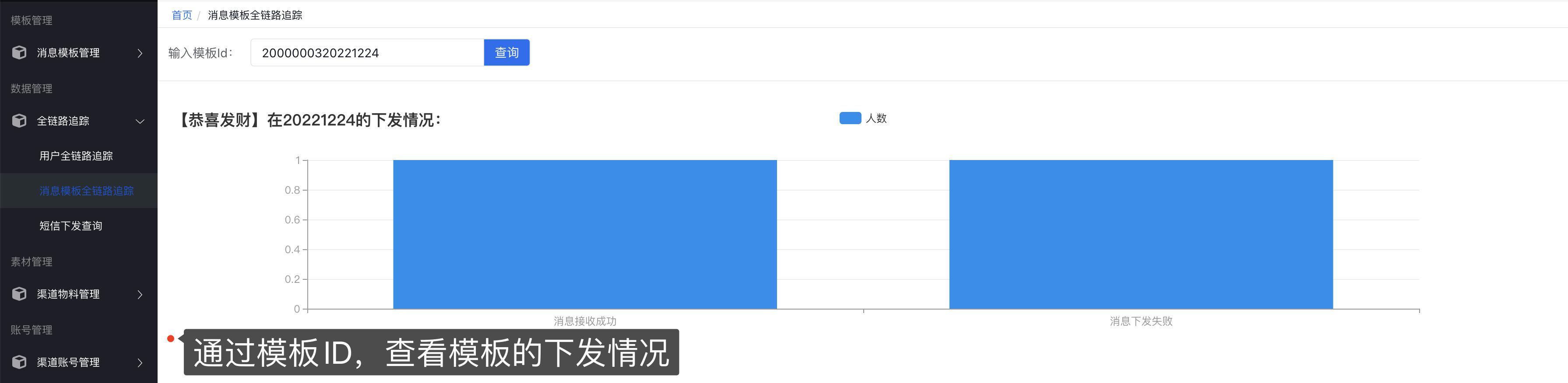
5 、亦可在新建模板时选择 定时任务 ,通过上传 csv文件 和指定cron表达式实现下发消息
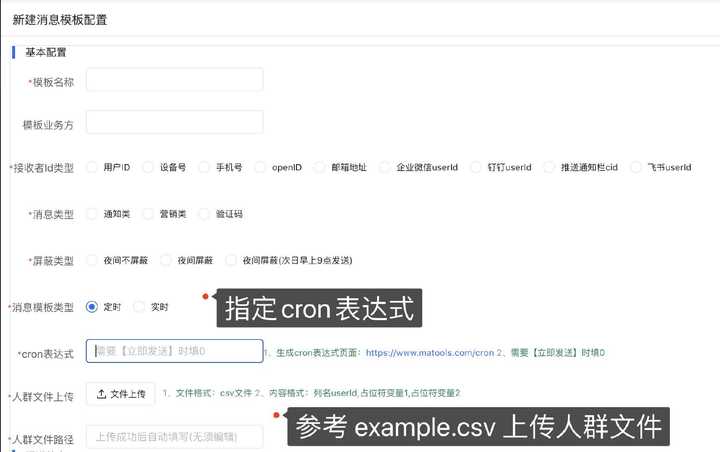
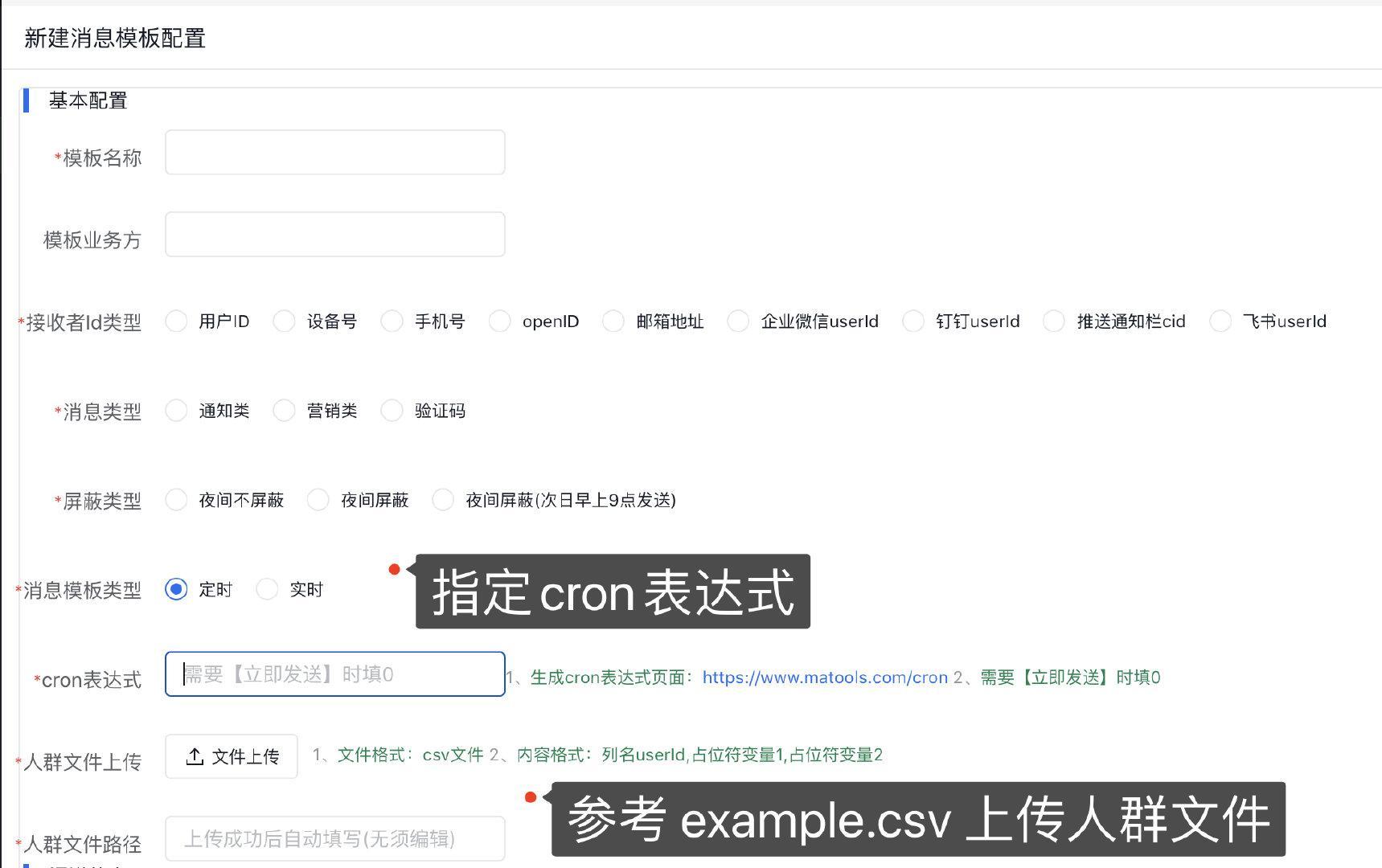
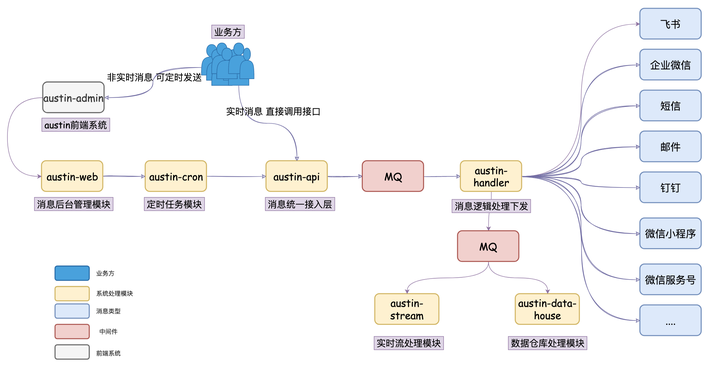
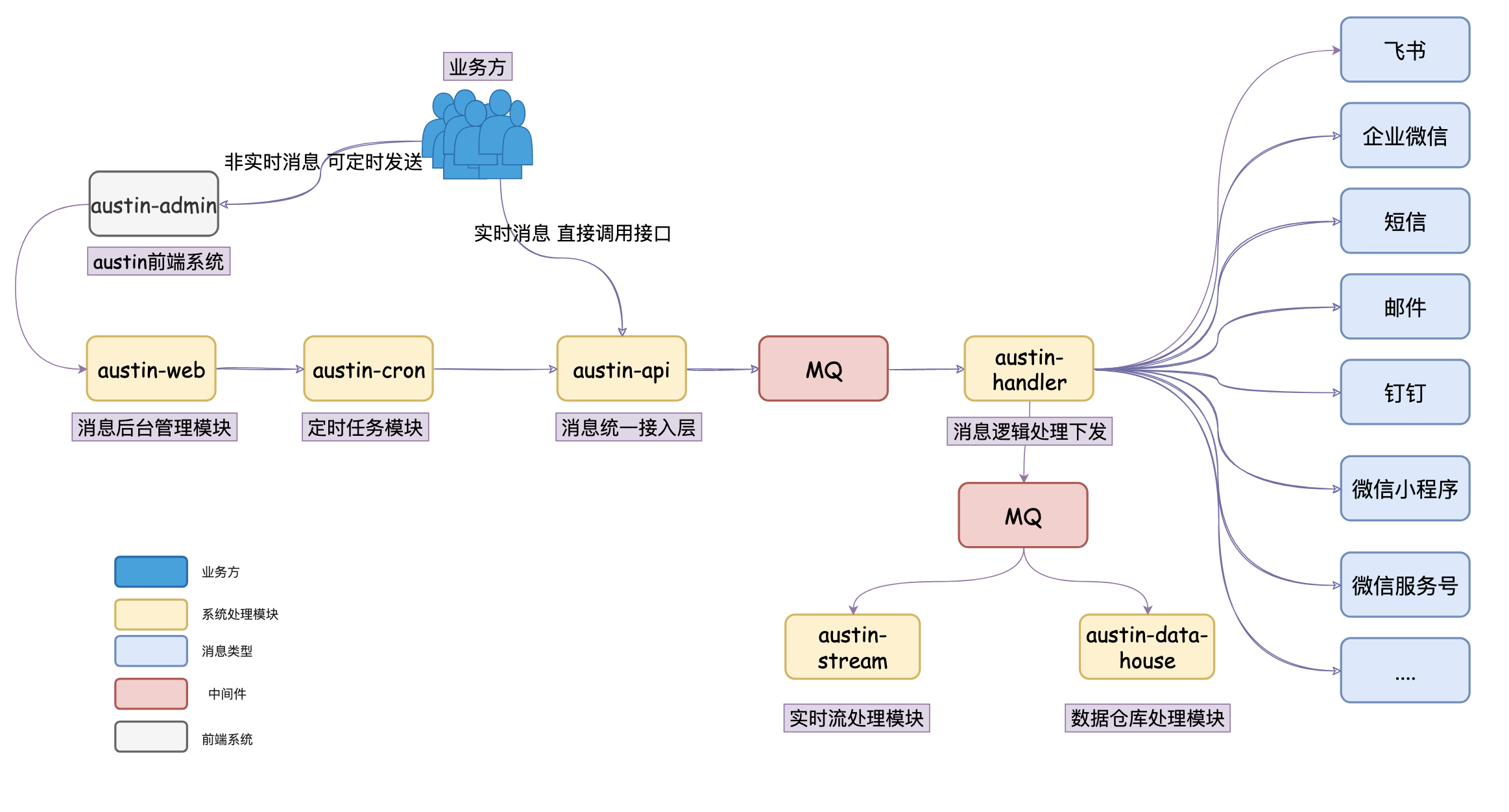
工程模块&系统流程
了解工程模块的职责,这对看项目代码的时候会有个比较清晰的认识:
| 工程模块 | 作用 |
|---|---|
| austin-common | 项目公共包:存储着项目公共常量/枚举/Bean |
| austin-support | 项目工具包:对接中间件/组件 |
| austin-cron | 定时任务模块:对xxl-job封装和项目定时任务逻辑 |
| austin-web | 后台管理模块:提供接口给前端调用 |
| austin-service-api | 消息接入层接口定义模块:只有接口和必要的入参依赖 |
| austin-service-api-impl | 消息接入层具体实现模块:真实处理请求 |
| austin-handler | 消息处理逻辑层:消费MQ下发消息 |
| austin-stream | 实时处理模块:利用flink实时处理下发链路数据 |
| austin-data-house | 数据仓库模块:消费MQ数据写入hive |
项目Gitee链接:
项目GitHub链接:
项目文档 :