

Python 链接oracle数据库(直接读入成dataframe)

python做科学计算是所有除编译语言最快的,原因在于python的numpy直接封装了大量优化性能最好的c库。
做数据操作也是我接触过最方便的(保留意见),因为基于pandas提供了大量的简易化数据操作api。
数据库:数据库提供高效简易的数据结构化查询语言,和excel一样属于很伟大的创作。
但数据库有的时候会面临一个问题:当我们遇到较为复杂的逻辑化数据操作的时候,sql语言有时候借助存储过程,(尤以付费的oracle 提供了多于mysql的方法)也能实现操作,但较之于服务端语言(如java,python)等实在是有点费劲且不讨好。
所以,我们希望可以把数据库的表式数据,直接读为python里pandas。datafram的表式数据,然后实现复杂逻辑的数据变换。
工具:python,oracle; python插件:cx_oracle,sqlalchemy,pandas,以及oracle的oci组件。( 相比较于mysql确实费劲不少,mysql的链接可百度或者见之前的文章 )
准备工作
1.oci 64位
oracle是远程服务器,应该是64位,但这边plsql(oracle的一款开发中间件)使用oracle的oci是32位,navicat用这个32位的也能连。唯独python报64位的oci无法被loaded。
因为plsql和navicat都在配置文件里指定了32位oci的位置,所以我决定下一个64位的oci放到环境变量里,把之前的32位环境换掉(两款软件都指定了位置,所以不影响使用 )
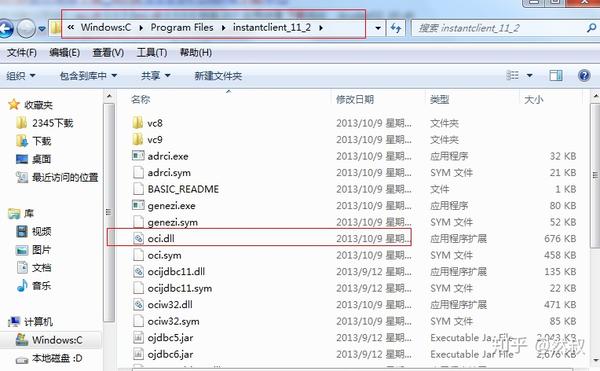
上面是下载地址,解压然后把目录加入环境变量里就好了。
2.cx_oracle
这个是驱动,mysql的就是mysqldb(新版为mysqlclient)和pymysql。
这个驱动也要对应。
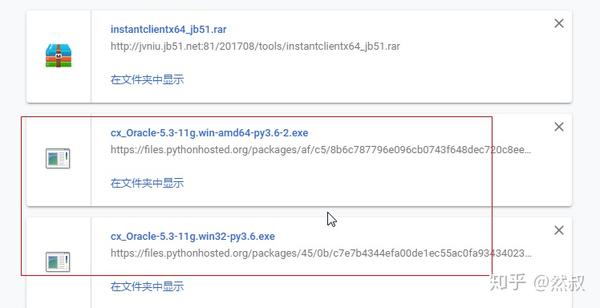
我的系统是win64 python 64位,所以只要amd64 python3.6版本。(ps,pip也能直接安装,但不建议,我的就出错。)
这个是5.3版本,最新是7.0,建议用老版本。
3.oracle servername问题
import sqlalchemy
import pyodbc
engine = sqlalchemy.create_engine("mssql+pyodbc://<username>:<password>@<dsnname>")
# write the DataFrame to a table in the sql database
df.to_sql("table_name", engine)sqlalchemy create engine(数据库类型+驱动[oracel默认是cx]+用户+密码+服务器+库名)如果只是本地普通的mysql或者oracle 完全ojb8k。
但是正式的业务环境都是主备集群等,外加网络ip限制,以此来容灾。
如oracel 有severename的设置,在oracle network/admin下有一个配置文件,navicat直接有服务名的填写项,但python这里没有。
所以我们用驱动来生成这样一个记载信息的token。
import pandas as pd
from sqlalchemy import create_engine
import cx_Oracle