


MGN多粒度行人重识别复现--总结(更新中)

近几日投完paper后,闲来无事,决定还是从代码基本功下手,谈谈自己复现MGN代码的过程,也算是一种自我学习的过程。完整代码已经放出,可以戳这里:
这篇论文可以说是ReID中比较出名的了,之前的PCB可以说证明了local(partial) feature在ReID中举足轻重的作用,而MGN也是采用local的思想去切feature,18年的论文却仍然在Market上达到了惊人的95.7%的Rank-1(比我的工作还高一点,惭愧)。框架说实话并不是很复杂,如下图所示,主要是结合全局特征和局部特征,获得更加具有描述力的特征,一共有3个分支,第一个是global的特征分支,另外两个是local的。具体细节看图就能懂。
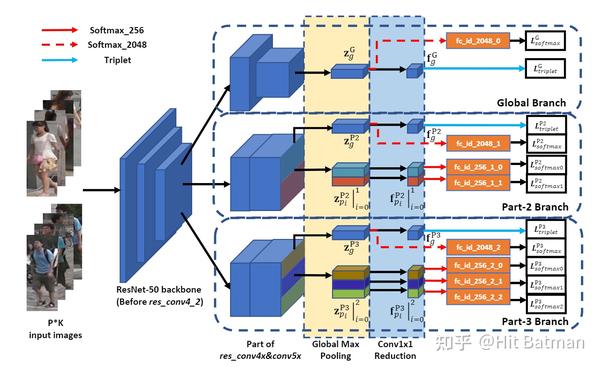
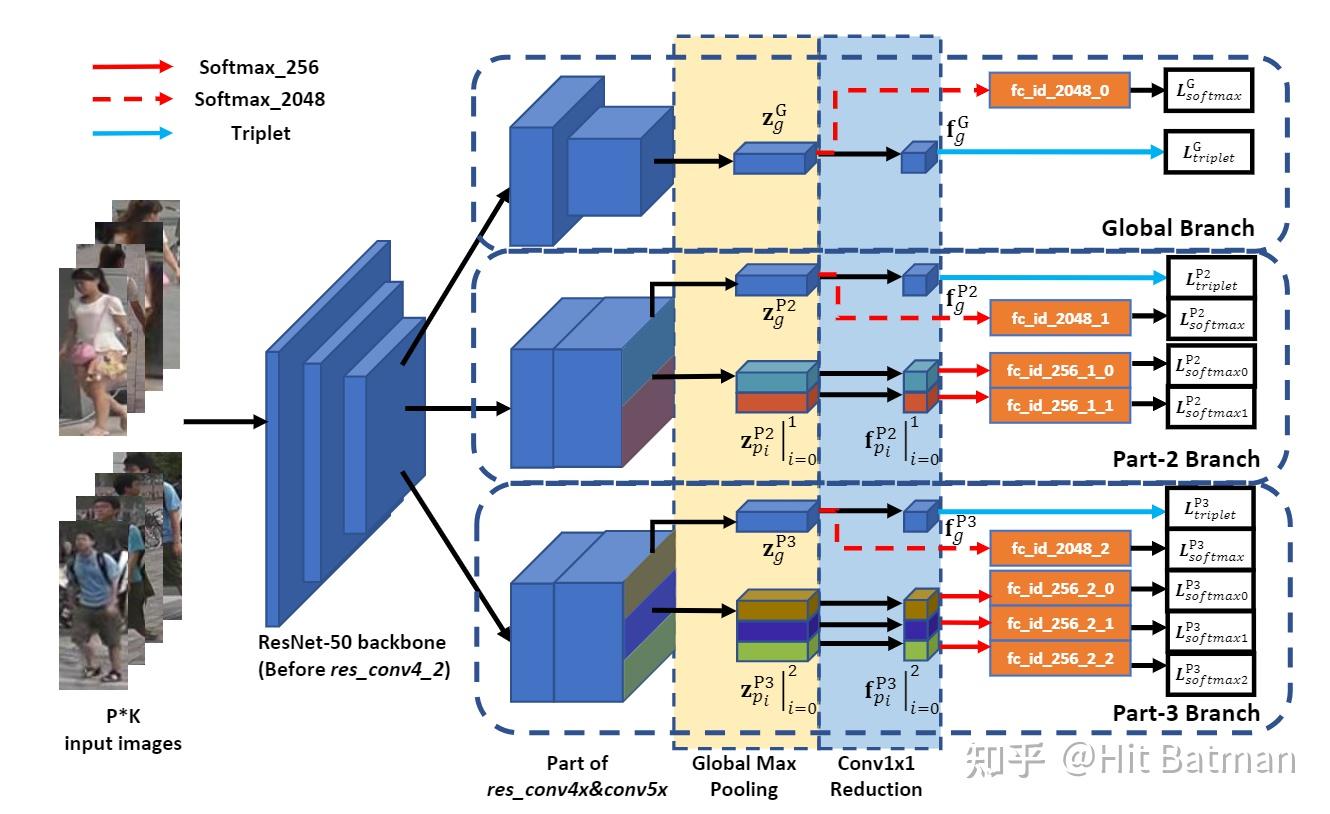
说实话,要完整的去复现一篇论文,这个网络结构是最简单的部分了,要实现整个网络,最重要的是要想好怎么样去实现,也就是整个代码的架构是怎样的,说实话我在这块是个小白,我最近投稿的工作也不是自己从头搭出来的,也是从已有的开源代码框架修修补补,一点一点叠出来的。所以呢,这篇复现工作我想完完全全的自己从头到尾走一遍框架。基本遵循下面的范式: 模型、数据、损失函数、优化器、参数控制、Trainer以及Test(各个模块间要解耦,不要写在一起,到时候出错了都不好查) 。该复现工作的架构如下:
|--data
|--make_dataloader.py, sampler.py, ........
|--loss
|--make_loss.py, ........
|--model
|--build_model.py
|--processor
|--make_optimizer.py, trainer.py
|--utils
|--metrics.py
|--configs.py, train.py, test.py....
一、模型的构建(build_model.py)
既然是要实现MGN网络,那么这个模型肯定是第一要义,先把模型撸清除,自己写了一遍,但是效果不太好,所以还是模仿下面这位大佬的写了一遍,跟着论文和图走,其实应该很简单。构建完model后,最好还是要测试一下,看看维度什么的能不能对的上。
def make_model(args): #args 是要传入的config,构建模型时需要的一些参数
return bulid_MGN_resnet(args)
class bulid_MGN_resnet(nn.Module):
def __init__(self, args):
super(bulid_MGN_resnet, self).__init__()
num_classes = args.num_classes
resnet = resnet50(pretrained=True)
self.backone = nn.Sequential(
resnet.conv1,
resnet.bn1,
resnet.relu,
resnet.maxpool,
resnet.layer1,
resnet.layer2,
resnet.layer3[0],
res_conv4 = nn.Sequential(*resnet.layer3[1:])
res_g_conv5 = resnet.layer4
res_p_conv5 = nn.Sequential(
Bottleneck(1024, 512, downsample=nn.Sequential(nn.Conv2d(1024, 2048, 1, bias=False), nn.BatchNorm2d(2048))),
Bottleneck(2048, 512),
Bottleneck(2048, 512))
res_p_conv5.load_state_dict(resnet.layer4.state_dict())
self.p1 = nn.Sequential(copy.deepcopy(res_conv4), copy.deepcopy(res_g_conv5))
self.p2 = nn.Sequential(copy.deepcopy(res_conv4), copy.deepcopy(res_p_conv5))
self.p3 = nn.Sequential(copy.deepcopy(res_conv4), copy.deepcopy(res_p_conv5))
pool2d = nn.MaxPool2d
self.maxpool_zg_p1 = pool2d(kernel_size=(12, 4))
self.maxpool_zg_p2 = pool2d(kernel_size=(24, 8))
self.maxpool_zg_p3 = pool2d(kernel_size=(24, 8))
self.maxpool_zp2 = pool2d(kernel_size=(12, 8))
self.maxpool_zp3 = pool2d(kernel_size=(8, 8))
reduction = nn.Sequential(nn.Conv2d(2048, args.feats, 1, bias=False), nn.BatchNorm2d(args.feats), nn.ReLU())
self._init_reduction(reduction)
self.reduction_0 = copy.deepcopy(reduction)
self.reduction_1 = copy.deepcopy(reduction)
self.reduction_2 = copy.deepcopy(reduction)
self.reduction_3 = copy.deepcopy(reduction)
self.reduction_4 = copy.deepcopy(reduction)
self.reduction_5 = copy.deepcopy(reduction)
self.reduction_6 = copy.deepcopy(reduction)
self.reduction_7 = copy.deepcopy(reduction)
self.fc_id_2048_0 = nn.Linear(args.feats, num_classes)
self.fc_id_2048_1 = nn.Linear(args.feats, num_classes)
self.fc_id_2048_2 = nn.Linear(args.feats, num_classes)
self.fc_id_256_1_0 = nn.Linear(args.feats, num_classes)
self.fc_id_256_1_1 = nn.Linear(args.feats, num_classes)
self.fc_id_256_2_0 = nn.Linear(args.feats, num_classes)
self.fc_id_256_2_1 = nn.Linear(args.feats, num_classes)
self.fc_id_256_2_2 = nn.Linear(args.feats, num_classes)
self._init_fc(self.fc_id_2048_0)
self._init_fc(self.fc_id_2048_1)
self._init_fc(self.fc_id_2048_2)
self._init_fc(self.fc_id_256_1_0)
self._init_fc(self.fc_id_256_1_1)
self._init_fc(self.fc_id_256_2_0)
self._init_fc(self.fc_id_256_2_1)
self._init_fc(self.fc_id_256_2_2)
@staticmethod
def _init_reduction(reduction):
# conv
nn.init.kaiming_normal_(reduction[0].weight, mode='fan_in')
nn.init.normal_(reduction[1].weight, mean=1., std=0.02)
nn.init.constant_(reduction[1].bias, 0.)
@staticmethod
def _init_fc(fc):
nn.init.kaiming_normal_(fc.weight, mode='fan_out')
nn.init.constant_(fc.bias, 0.)
def load_param(self, weight):
param_dict = torch.load(weight)
for i in param_dict:
self.state_dict()[i.replace('module.', '')].copy_(param_dict[i])
print('Loading pretrained model from {}'.format(weight))
def forward(self, x):
x = self.backone(x)
p1 = self.p1(x)
p2 = self.p2(x)
p3 = self.p3(x)
zg_p1 = self.maxpool_zg_p1(p1)
zg_p2 = self.maxpool_zg_p2(p2)
zg_p3 = self.maxpool_zg_p3(p3)
zp2 = self.maxpool_zp2(p2)
z0_p2 = zp2[:, :, 0:1, :]
z1_p2 = zp2[:, :, 1:2, :]
zp3 = self.maxpool_zp3(p3)
z0_p3 = zp3[:, :, 0:1, :]
z1_p3 = zp3[:, :, 1:2, :]
z2_p3 = zp3[:, :, 2:3, :]
fg_p1 = self.reduction_0(zg_p1).squeeze(dim=3).squeeze(dim=2)
fg_p2 = self.reduction_1(zg_p2).squeeze(dim=3).squeeze(dim=2)
fg_p3 = self.reduction_2(zg_p3).squeeze(dim=3).squeeze(dim=2)
f0_p2 = self.reduction_3(z0_p2).squeeze(dim=3).squeeze(dim=2)
f1_p2 = self.reduction_4(z1_p2).squeeze
(dim=3).squeeze(dim=2)
f0_p3 = self.reduction_5(z0_p3).squeeze(dim=3).squeeze(dim=2)
f1_p3 = self.reduction_6(z1_p3).squeeze(dim=3).squeeze(dim=2)
f2_p3 = self.reduction_7(z2_p3).squeeze(dim=3).squeeze(dim=2)
l_p1 = self.fc_id_2048_0(fg_p1)
l_p2 = self.fc_id_2048_1(fg_p2)
l_p3 = self.fc_id_2048_2(fg_p3)
l0_p2 = self.fc_id_256_1_0(f0_p2)
l1_p2 = self.fc_id_256_1_1(f1_p2)
l0_p3 = self.fc_id_256_2_0(f0_p3)
l1_p3 = self.fc_id_256_2_1(f1_p3)
l2_p3 = self.fc_id_256_2_2(f2_p3)
if self.training:
return fg_p1, fg_p2, fg_p3, l_p1, l_p2, l_p3, l0_p2, l1_p2, l0_p3, l1_p3, l2_p3
else:
predict = torch.cat([fg_p1, fg_p2, fg_p3, f0_p2, f1_p2, f0_p3, f1_p3, f2_p3], dim=1)
return predict
二、数据流的构建(data)
让网络能够读到数据,首先得去写一个Dataset,能够去读取数据集中每一张图的各种属性,比如路径,标签等等。这里以Market1501为例(模仿了Transreid的dataset的写法):
# encoding: utf-8
import glob
import re
import os.path as osp
from collections import defaultdict
import pickle
class Market1501(object):
Market1501
Reference:
Zheng et al. Scalable Person Re-identification: A Benchmark. ICCV 2015.
URL: http://www.liangzheng.org/Project/project_reid.html
Dataset statistics:
# identities: 1501 (+1 for background)
# images: 12936 (train) + 3368 (query) + 15913 (gallery)
dataset_dir = 'market1501'
def __init__(self, root='', verbose=True, pid_begin = 0, **kwargs):
super(Market1501, self).__init__()
self.dataset_dir = osp.join(root, self.dataset_dir)
self.train_dir = osp.join(self.dataset_dir, 'bounding_box_train')
self.query_dir = osp.join(self.dataset_dir, 'query')
self.gallery_dir = osp.join(self.dataset_dir, 'bounding_box_test_500k')
self._check_before_run()
self.pid_begin = pid_begin
train = self._process_dir(self.train_dir, relabel=True)
query = self._process_dir(self.query_dir, relabel=False)
gallery = self._process_dir(self.gallery_dir, relabel=False)
if verbose:
print("=> Market1501 loaded")
self.print_dataset_statistics(train, query, gallery)
self.train = train
self.query = query
self.gallery = gallery
self.num_train_pids, self.num_train_imgs, self.num_train_cams, self.num_train_vids = self.get_imagedata_info(self.train)
self.num_query_pids, self.num_query_imgs, self.num_query_cams, self.num_query_vids = self.get_imagedata_info(self.query)
self.num_gallery_pids, self.num_gallery_imgs, self.num_gallery_cams, self.num_gallery_vids = self.get_imagedata_info(self.gallery)
def get_imagedata_info(self, data):
pids, cams, tracks = [], [], []
for _, pid, camid, trackid in data:
pids += [pid]
cams += [camid]
tracks += [trackid]
pids = set(pids)
cams = set(cams)
tracks = set(tracks)
num_pids = len(pids)
num_cams = len(cams)
num_imgs = len(data)
num_views = len(tracks)
return num_pids, num_imgs, num_cams, num_views
def print_dataset_statistics(self, train, query, gallery):
num_train_pids, num_train_imgs, num_train_cams, num_train_views = self.get_imagedata_info(train)
num_query_pids, num_query_imgs, num_query_cams, num_train_views = self.get_imagedata_info(query)
num_gallery_pids, num_gallery_imgs, num_gallery_cams, num_train_views = self.get_imagedata_info(gallery)
print("Dataset statistics:")
print(" ----------------------------------------")
print(" subset | # ids | # images | # cameras")
print(" ----------------------------------------")
print(" train | {:5d} | {:8d} | {:9d}".format(num_train_pids, num_train_imgs, num_train_cams))
print(" query | {:5d} | {:8d} | {:9d}".format(num_query_pids, num_query_imgs, num_query_cams))
print(" gallery | {:5d} | {:8d} | {:9d}".format(num_gallery_pids, num_gallery_imgs, num_gallery_cams))
print(" ----------------------------------------")
def _check_before_run(self):
"""Check if all files are available before going deeper"""
if not osp.exists(self.dataset_dir):
raise RuntimeError("'{}' is not available".format(self.dataset_dir))
if not osp.exists(self.train_dir):
raise RuntimeError("'{}' is not available".format(self.train_dir))
if not osp.exists(self.query_dir):
raise RuntimeError("'{}' is not available".format(self.query_dir))
if not osp.exists(self.gallery_dir):
raise RuntimeError("'{}' is not available".format(self.gallery_dir))
def _process_dir(self, dir_path, relabel=False):
img_paths = glob.glob(osp.join(dir_path, '*.jpg'))
pattern = re.compile(r'([-\d]+)_c(\d)')
pid_container = set()
for img_path in sorted(img_paths):
pid, _ = map(int, pattern.search(img_path).groups())
if pid == -1: continue # junk images are just ignored
pid_container.add(pid)
pid2label = {pid: label for label, pid in enumerate(pid_container)}
dataset = []
for img_path in sorted(img_paths):
pid, camid = map(int, pattern.search(img_path).groups())
if pid == -1: continue # junk images are just ignored