

现有人才测评企业计算机自适应测验产品技术的比较和盘点


近日,前程无忧测评公众号发布了一篇文章,引起了行业内人士的关注。这篇文章推送了前程无忧旗下智鼎在线研发的一款产品“IQCAT”,这款产品测的是认知能力,使用的测评算法技术是计算机多阶段自适应技术。这两年在认知能力测评领域,北森的“CATA”气势正盛,从名称上来看猎聘这款产品似乎有与之抗衡的意味。智鼎这个产品,并不是最近才开发出来,去年心理学大会上,他们的研发人员就相关技术做过口头报告。实际上,在国内企业当中,并不是只有他们两家有计算机自适应技术(computer adaptive testing)的认知测验产品,猎聘旗下的才测网也研发出CAT类的产品,但实在话,猎聘才测的产品宣传略逊一筹,导致很多人忽略了它的存在。
笔者将网上查到的专利名称截图下来,大家就可一目了然。




但是智鼎在线的这种自适应测验方法和北森、才测的自适应测验方法是有所不同的。
所谓的自适应测验,自适应测验是根据被试者在作答过程中表现出来的能力水平匹配相对应难度的试题进行动态评估的。那匹配相对应难度的试题就有两种模式,一种是一道道题来匹配,这是北森、才测所使用的方法;但是智鼎在线并不是一道题一道题的匹配,而是一组题(相当于一个缩小版的测验),前期被试者做完一组题后,估计出来一个能力,然后会根据能力匹配第二阶段的另一组题,实际上也是一种自适应模式,因此也被叫做多阶段自适应测验(multistage adaptive testing,MST)。
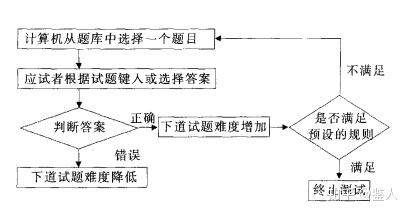
那么问题来了,以一组题为单位的自适应测试和以一组题为单位的自适应测试各有什么优点呢?为什么有了CAT后,还需要MST。
■CAT和MST的比较
1.CAT的关键技术上的问题
(1)抽题技术
CAT的理想是很美好的,但是在运用过程中会存在技术上的问题。首先,如何在考生作答的过程中抽题,常用方法是选择在当前估计出来的能力值附近“误差”最小的题目(术语:fisher最大信息量,有兴趣的翻统计学上的fisher信息量概念),这么做当然可以增加精度。但是这种方法也会存在问题,导致高区分度的题目被经常选出来,题目就曝光,曝光过度的题目一般就不能再用了,所以就使得题库的维护存在问题。
这里牵扯到另外一个技术,题库怎么更新的问题,应该说任何使用自适应平台的人都是题库更新的贡献者。
(2)题库建立和维护技术
CAT在前期开发时,很大部分精力是要找样本去施测,然后通过“等值”的技术将题目的难度值统一到一个量尺上。这个怎么理解呢,CAT的逻辑是:题的难度匹配人的能力,以最少的、因人施测的题目去估计受测者的能力。所以前期需要通过数学模型建立题的难度和人的能力的直接关系(IRT模型,有兴趣去查资料),并且通过一定的试测,搜集样本的数据,估计题目难度。
大家想想一个问题,1000道题,你不可能让所有的人都做一遍。分开做,如果试题不同,因为被试者样本能力不同,估计出来的难度也不是同一量尺的(同一批题给能力高的人做难度就低,给能力低的人做难度就高)。所以在题库建立时候就有一个关键技术是 等值技术 。举一个设计例子就是A样本做40道题,B样本做40道题,其中15道题是A和B都要做的,在A样本中15道题有难度值,B样本中也有难度值,实际上它们应该相等的,通过难度等值公式就可以将其他题目在A样本和B样本中的难度给统一到一个尺度上去。前期可通过这样的模式将1000道题的题库建立起来。
在平台上线后,因为题目曝光的问题,需要更新题库,而更新题库如果再用前面说的这种模式会费时费力,所以一般会在每次施测中插入几道没有经过试测的、没有题目参数的题,让被试者去做,搜集数据上来后,因为题库中的题都有参数,每道题的作答者达到一定数量后,将试题的难度估算出来往题库上等就好了,这牵扯到另外一个技术就是 在线试题参数标定技术。 所以说,任何使用自适应平台的人都是题库更新的贡献者。
(3)人才测评领域CAT使用的问题
以上说的都是技术理论讨论上的问题,但是在现实使用中CAT有什么问题吗?
- 很少企业完整说明其CAT构建的整个过程,特别是题库构建过程的说明
CAT构建有题库构建和平台系统搭建两个过程,平台系统搭建因为现有的IT技术发达,有一定的算法嵌套上去,问题不大。但是目前各个企业很少报告它们题库构建的过程,在第二点中已经说到题库构建的重要性,如果没有那种等值设计,算出来的题目难度都不是在同一尺度上,后期无论使用何种抽题技术都可能导致偏差。
- CAT在人才测评领域真的能够达到提高效率、减少题量的目的吗
CAT因为其因人施测、量体裁衣的特点,理论上是可以减少题量的目的。但是在人才测评领域是否真能达到这种目的吗?一般做认知能力的题,都是多维度的,每个维度也就是10多道题,而在CAT运行过程中,前期要几道探测题,后期要几道题库更新题,实际上加起来也要10道题左右。减少题量的目的实际上很难达到。它最主要的功能还是 在“因人施测”、防止作弊、提高评价精度等方面。
- 人才测评领域的题目曝光很严重吗?
CAT首先是用在教育测评领域的,广为人知的GRE\SAT等测试,就是使用CAT的模式。但是在人才测评领域,认知测验还不算是那种高厉害的考试,不像选拔考试那样的备受关注,题目曝光的风险相对较低。
2.MST的关键技术和存在问题
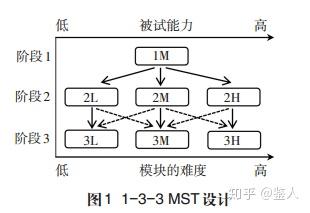
计算机多阶段自适应测验如上图所示,第一阶段是探测阶段,用一组题初步探测被试者的能力,这是比较粗的估计;第二阶段就可以根据第一阶段估计出来的被试者的粗略能力,推送能力附近难度的一组题,进一步估计考生的能力,例如估计出来是低能力(L),则第二阶段推送L组块的题;第三个阶段可再一步估计。这是标准的3阶段MST的模式。
从中可看出,这里面用一组题去替代一道题,优势是显而易见的,考生在做一组题时候可以跳题、修改作答,这在CAT当中是困难的,因为CAT根据前面题目估计出来的考生能力值迭代更新题。此外,在题库开发阶段,可人工组装每个题组块,除了考虑难度等统计学上的指标外,还可以考虑内容平衡、覆盖情况,比CAT每道题只依赖难度、误差等统计指标更具科学性。
这种模式下的关键技术有:
- 题库建设: 无论CAT和MST,题库建设都是重中之重,这里的题库技术和CAT并无什么太大区别。
- 组卷策略:MST构建题库后有进一步工作就是把题组装成题组模块,这里面的组装方法某种程度上需要发挥命题专家和测评专家的作用 ,比如在组建上述的第二阶段的M模块时,如何从题库里面选择中等难度的题,且考虑内容、测量目标、材料的平衡。同时也有开发出自动组卷的方法(具体可见李贵玉的文章,计算机多阶段自适应测验的组卷方法)。
- 路径规则(推题策略):路径规则(routing methods) 是对阶段与阶段间进行模块的自适应选择,目的在于通过考生在上一阶段作答选择针对该能力的最优模块,这块技术也是核心技术,因为涉及到较多的统计学内容,不做进一步展开回应,有兴趣者可看王睿(基于计算机化多阶段自适应测验的路由规则比较及其应用研究)的文章。
MST存在的若干待考虑的问题:
- MST是多阶段测验,到底需要几个阶段?
理论上来说,阶段越多,好像误差越小,测的越准。但是从上面描述可知,阶段越多,MST的结构会越复杂,每个模块的组装会比较麻烦,增加难度。而且阶段多到一定数量时,对精度的提高作用也没那么大。已有的实践应用中,3阶段是比较常用的。
这次智鼎在线的MST使用的是两阶段,两阶段的优势是实施方便,除了使用在线测试以外还可以使用纸笔测试。 但是两阶段只有一次分流,被试在第二阶段很有可能分到不恰当的模块,特别是能力在分流时模块间的临界分数附近的被试(杨涛,黄顺生,辛涛,2015)。所以该方法在实践中的情况还有待观察。
- 每个阶段到底需要几个模块?
如图所示,每个阶段的能力可以划分为3个水平,也可划分为其他数量的水平,这里面就有多种多样的设计。到底每个阶段需要几个模块,可参考已有的研究,也可自己做模拟研究实现。这里只罗列三阶段的几种结构设计:1-2-2、1-2-3、1-3-2、1-3-3,1-3-5。1-3-3和1-3-5在三阶段结构设计当中比较常见,效果也较好。
以上大概讲了一下CAT和MST的优劣势以及各自的关键技术,供大家在了解和使用各自产品时候有些认识。
■现有市场上的人才测评企业的计算机自适应测验产品介绍


以上是对部分计算自自适应测验产品的汇总,猎聘才测网的这个产品,似乎市场上很少人知道,也在于他们的宣传推广做的不够充分。
大家注意测量模型列所说的3PL、2PL的含义,是指3参数logistics模型和2参数logistics模型,对于统计学基础较好的人可充分了解。所谓的1个参数、2个参数和3个参数是指对题目质量的衡量指标,1个参数是指在模型中只有难度参数,2个参数只是模型中有难度和区分度参数,3个参数是指在模型中有难度、区分度、猜测度参数。模型中似乎将题目的因素考虑的越多越好,参数越多越好,这实际上是不实际的,也会造成问题的。例如3PL,猜测度参数的估计会比较不稳定,所以北森CAT的结果如何也需要时间来检验。
其他公司的产品相应的资料较少,对其结果如何,不太好评价。尽量罗列出来。
大家会发现大多数测评公司开发的CAT测验都是在认知部分,因为CAT本身的来源是教育考试领域,针对的也是考试类测验,这类测验是最高行为测验,答案有对错之分,所以有“能力”高低之分,测量(数学)模型的建立也是在这基础之上。在人才测评领域认知测验也是最高行为测验,整个模式与之相类似。而非认知领域的CAT虽然在学术界一直有研究或者讨论,目前应用较少,一个重要原因是非认知测验让一个人做100道题的时间也不是很长,而通常非认知测验也不会这么多题,所以通过CAT模式去减少题量的应用场景可能会比较局限;其次,非认知测验是典型行为测验,影响考生作答的因素很多,这方面的测量模型也相对较多,不像认知测验那样有比较公认的好用的模型存在。但是似乎这方面,国外的应用走的比较远,感兴趣者可进一步了解。
参考文献:
[1]李贵玉,涂冬波,戴步云,宗一涛,高旭亮,苗莹.计算机多阶段自适应测验的组卷方法[J].江西师范大学学报(自然科学版),2017,41(05):462-469+483.
[2]杨涛,黄生顺,辛涛.计算机化多阶段测验的基本结构及其研究进展[J].中国考试,2015(07):7-12+17.
[3]王钰彤,罗照盛,王睿.计算机化多阶段自适应测验研究述评[J].心理科学,2015,38(02):452-456.
因为才疏学浅,如有内容错误及不合理之处,请留言探讨。
