import wave
wavFile = r"C:\Users\Lenovo\Desktop\G0001.wav"
f = wave.open(wavFile)
params = f.getparams()
Channels = f.getnchannels()
SampleRate = f.getframerate()
bit_type = f.getsampwidth() * 8
frames = f.getnframes()
Duration = wav_time = frames / float(SampleRate)
print("音频头参数:", params)
print("通道数(Channels):", Channels)
print("采样率(SampleRate):", SampleRate)
print("比特(Precision):", bit_type)
print("采样点数(frames):", frames)
print("帧数或者时间(Duration):", Duration)
输出结果:
音频头参数: _wave_params(nchannels=1, sampwidth=2, framerate=48000, nframes=171698592, comptype='NONE', compname='not compressed')
通道数(Channels): 1
采样率(SampleRate): 48000
比特(Precision): 16
采样点数(frames): 171698592
帧数或时间(Duration): 3577.054
这是在win 下 使用sox 命令 检查下的结果:
win 下的sox命令(需要安装sox ,可百度一下) : sox --i G0001.wav
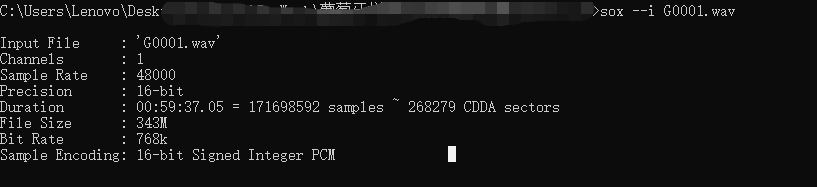
可以看出 ,两种方法,输出的结果是一致的。
安装:pip install wave在wav 模块中 ,主要介绍一种方法:getparams(),该方法返回的结果如下:_wave_params(nchannels=1, sampwidth=2, framerate=48000, nframes=171698592, comptype='NONE', compname='not compressed')参数解释:nchannel...
采样频率
每秒从连续信号中提取并组成离散信号的采样个数。用Hz表示,采样频率的倒数是采样周期,即采样之间的时间间隔。
通俗的讲:采样频率是指计算机每秒钟采集的多少声音样本。采样频率越高,即采样的间隔时间越短,则在单位时间内计算机得到的声音样本数据就越多,对声音波形的表示也越精确。
采样定理
也称作奈奎斯特采样定理,只有采样频率高于声音信号最高频率的两倍时,才能把数字信号...
wav文件提取音频数据_python
wav文件格式
首先需要知道wav文件格式:(10条消息) WAV文件格式详解_imxiangzi的专栏-CSDN博客_wav文件格式
简单来说wav文件分为三个区块
这里主要讲的是提取wav文件的data部分
观察数据在文件头的分段
当然由于每个wav文件的采样规格不一样,在data数据部分的分段(比如左声道右声道以及每个采样点的字节数)是不一样的
我们可以看到的是data部分每个sample占两个字节,另外需要注意data的数据sample部分是小端存储,这就意
将10s、44.1kHZ的wav音频文件处理成5个2s、8000Hz的音频片段,其中每个2s的音频片段都包含8*2(s)*2(channel),000个采样点,即32,000个采样点,前16,000个为左声道采样点,后16,000个为右声道采样点(对于单通道数据,直接复制16,000个采样点追加在后面),再存储到csv文件中。
即将10s、44.1kHZ的wav音频文件输出为(5,8000)的特征向量。
涉及模块
os、shutil、random、numpy、pydub、pandas
本文主要使用python编程,实现解析wav语音文件,得到.wav语音文件的声道数,量化位数,采样频率,采样点数。编写python程序使用pycharm。
下面简单介绍一下wav文件结构。
一 解析.wav文件原理
WAVE文件本质上就是一种RIFF格式,它可以抽象成一颗树(数据结构的一种)来看。
如图所示,从上到下分别对应着二进制数据在文件中相对于起始位置的偏移量。每一个格子对应一...
原文https://blog.csdn.net/qq_31615049/article/details/88562892
publicstaticinttoInt(byte[] b) {
return((b[3]<<24)+(b[2]<<16)+(b[1]<<8)+(b[0]<<0));
publicstaticshorttoShort(byte[] b) {
x1 = np.linspace(1, 4096, 1024)
x_new = np.linspace(1, 4096, 4096)
from scipy import interpolate
tck = interpolate.splrep(x1, data)
y_bspline = interpolate.splev(x_new, tck)
其中y_bspline就是从1024插值得到的4096的数据
但是,scipy中好像并没有进行下采样的函数,嗯..难道是因为太过
resample(self, rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention=‘start’, kind=None, loffset=None, limit=None, base=0, on=None, level=None)
比较关键的是rule,closed,label下面会随着两个用法说明
对时间数据细粒度增大,可以把每天的数据聚合成一周,可以求和或者均值的方式进行聚合
下面给出列子
times=pd.date_range('20180101',period
转:https://blog.ailemon.me/2017/08/29/python-read-wav-files/
https://www.cnblogs.com/xingshansi/p/6799994.html
我们经常需要处理wav格式的文件,读取其中的声音信号和相关参数,来做一些事情。如果我们使用C++来做,那么需要对文件的底层存储格式有一个透彻的了解才行,而且考虑不周还有可能出B...
小波作为一种信号处理的工具在脑波分析中应用很多,常用的有连续小波变换、小波包分析等等。小波涉及的相关介绍和公式推导有很多资料,推荐下面几个连接,本文主要介绍连续小波变换,小波包分解重构,对应频段能量计算这3种应用在Python中的实现。
小波变换:
https://www.cnblogs.com/jfdwd/p/9249850.html
https://blog.csdn.net/weixin_42943114/article/details/89603208
https://my.oschina.

