

SQL学习笔记 - V:临时表与视图

1. 临时表(temporary table)
在MySQL中,临时表是一种特殊类型的表,允许我们存储一个临时结果集,并将其在一次会话中多次进行使用。
比如,在employees数据库中,表employees存储了员工的基本信息,表departments存储了部门的信息,表dept_emp存储了全时段下员工和部门的从属关系,表salaries存储了全时段下员工的薪资情况,表titles存储了全时段下员工的职级信息。这种充分分散式的存储方式满足了关系型数据库设计理论的要求,但如果我们想要刻画不同部门,不同职级的当前在职员工的统计特征时,就会十分不便。该数据库中共有约30w名员工,属于一个中型数据库。我们可以创建一个临时表以完成统计任务。
CREATE TEMPORARY TABLE employees2
SELECT d.dept_no AS dept_no, de.emp_no AS emp_no, e.gender AS gender,
s.salary AS salary, t.title AS title
FROM (SELECT * FROM salaries WHERE to_date = '9999-01-01') s
INNER JOIN (SELECT * FROM titles WHERE to_date = '9999-01-01') t USING(emp_no)
INNER JOIN dept_emp de USING(emp_no)
INNER JOIN departments d USING(dept_no)
INNER JOIN employees e USING(emp_no);
SELECT * FROM employees2;运行6.609秒,生成临时表employees2如下:
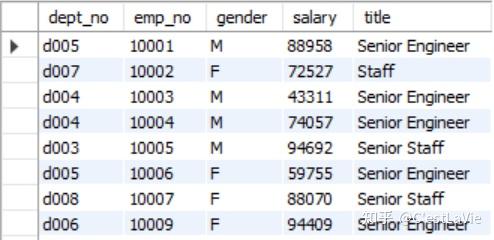
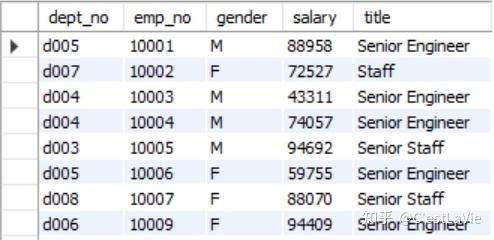
临时表有以下特性:
- 临时表由CREATE TEMPORARY TABLE语句创建,可以使用DROP TEMPORARY TABLE语句主动删除,也可以在会话结束或者与数据库的连接中断时自动被移除。这使得临时表具有相对于永久表的优势——对存储资源的占用是临时性的,可以用毕即弃。
- 临时表可以与普通表同名。在这种情况下,当同名临时表存在时,普通表将不能被访问,所有指令指向同名临时表。当临时表被删除时恢复如常。尽管创建同名临时表是被允许的,但并不建议这么做。
- 调用临时表的方式与调用普通表完全一致。
2. 派生表(derived table)
派生表是从SELECT语句返回的虚拟表(不实际存储在数据库中),派生表类似于临时表,但不需要建表语句。
派生表与子查询息息相关,通常我们把由独立子查询(Independent Subquery)返回的表称作是派生表。
派生表必须具有别名。
我们在介绍临时表时,语句第四行和第五行,FROM子句和第一个INNER JOIN中引用的表都是派生表。
在classicmodels数据库中完成以下两个任务,以演示派生表的使用:
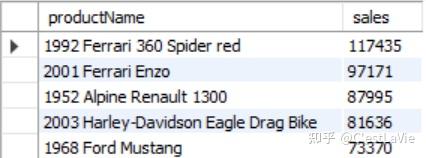
- 查询2004年销售额最高的5个产品,返回它们的名字和销售额:
USE
classicmodels;
SELECT p.productName AS productName,
prod_top5_sales.sales AS sales
FROM (SELECT od. productCode,
ROUND(SUM(od.quantityOrdered * od.priceEach)) AS sales
FROM orderdetails od
INNER JOIN orders o USING(orderNumber)
WHERE YEAR(o.shippedDate) = 2004
GROUP BY od.productCode
ORDER BY SUM(od.quantityOrdered * od.priceEach) DESC
LIMIT 5) prod_top5_sales INNER JOIN products p USING(productCode);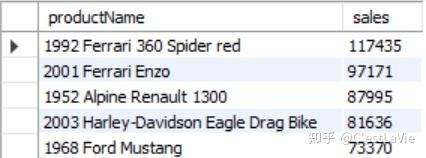
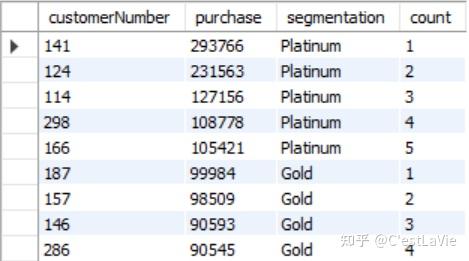
- 对在2004年内完成过订单的客户进行分级——总订单额大于100000的是白金客户,总订单额在(20000,100000]的是黄金客户,总订单额在(0, 20000]的是白银客户;并统计各分级客户的数量:
SELECT *, COUNT(*) OVER (PARTITION BY segmentation ORDER BY purchase DESC) AS count
FROM(SELECT c.customerNumber,
ROUND(SUM(od.quantityOrdered * od.priceEach)) AS purchase,
CASE WHEN SUM(od.quantityOrdered * od.priceEach)>100000 THEN 'Platinum'
WHEN SUM(od.quantityOrdered * od.priceEach)<=100000
AND SUM(od.quantityOrdered * od.priceEach)>30000 THEN 'Gold'
WHEN SUM(od.quantityOrdered * od.priceEach)<=30000
AND SUM(od.quantityOrdered * od.priceEach)>0 THEN 'Silver'
ELSE NULL END AS segmentation
FROM orderdetails od
INNER JOIN (SELECT * FROM orders WHERE YEAR(shippedDate)=2004) o USING(orderNumber)
INNER JOIN customers c USING(customerNumber)
GROUP BY customerNumber
ORDER BY SUM(od.quantityOrdered * od.priceEach) DESC) customer_segmentation
ORDER BY purchase DESC;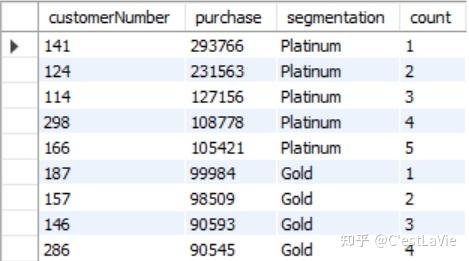
3. 公共表表达式(common table expressions, CTEs)
公共表表达式是一个命名的临时结果集,仅在单个SQL语句(增删改查)的执行范围中存在。与派生表类似,CTE不实际存储在数据库中,只是个虚拟表。与派生表不同的是,CTE可以自引用——递归CTE(Recursive CTEs),也可以在同一查询中多次引用。除此以外,CTE比派生表拥有更好的可读性和性能。
CTE:
WITH cte_name(column_list) AS (subquery)
[, cte_name_2(column_list_2) AS (subquery_2) ......]
SELECT CLAUSE;派生表中的第一个例子即可改写为:
WITH prod_top5_sales(productCode, sales) AS (
SELECT od. productCode,
ROUND(SUM(od.quantityOrdered * od.priceEach))
FROM orderdetails od
INNER JOIN orders o USING(orderNumber)
WHERE YEAR(o.shippedDate) = 2004
GROUP BY od.productCode
ORDER BY SUM(od.quantityOrdered * od.priceEach) DESC
LIMIT 5)
SELECT p.productName AS productName, pts.sales AS sales
FROM prod_top5_sales pts
INNER JOIN products p USING(productCode)
ORDER BY sales DESC;这种写法与之前的派生表完成相同的任务,但更为直观。
查询每个客户和负责该客户的销售代表:
WITH sales_rep AS (
SELECT employeeNumber,
CONCAT(firstName,' ',lastName) AS salesRepName
FROM employees
WHERE jobTitle = 'Sales Rep'),
cust_sales_rep AS (
SELECT customers.customerName AS customer,
sales_rep.salesRepName AS salesRep
FROM customers INNER JOIN sales_Rep
ON (customers.salesRepEmployeeNumber=sales_rep.EmployeeNumber))
SELECT *
FROM cust_sales_rep
ORDER BY customer;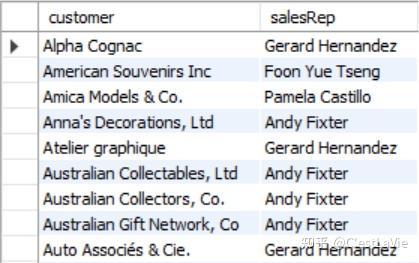
这段语句中使用了两个CTE,第一个CTE的名称在第二个CTE中被引用,第二个CTE是基于第一个CTE定义的。
当然,直接使用自连接也可以达到相同的效果:
SELECT c.customerName,
CONCAT(e.firstName,' ',e.lastName) AS salesRep
FROM customers c INNER JOIN
(SELECT * FROM employees WHERE jobTitle='Sale Rep') e
ON (c.salesRepEmployeeNumber = e.employeeNumber)
ORDER BY c.customerName;递归CTE(recursive CTEs):
WITH RECURSIVE cte_name(column_list) AS (
initial_query
UNION [DISTINCT]
recursive_query)
SELECT CLAUSE;定义中包含引用自身的CTE称作递归CTE。递归CTE包含一个由UNION连接的结构,
递归CTE的执行步骤如下:
- 首先执行initial_query,该查询为CTE产生最初的一条或多条记录,该查询不引用CTE名称;
- recursive_query通过在FROM子句中引用CTE名称,从而进行递归,生成新的记录;
- 直到某个终止条件被满足后,不再产生新的记录,递归终止;
- 使用CTE执行SELECT CLAUSE。
另需注意,recursive_query中不能包含聚合函数、窗口函数、GROUP BY、ORDER BY、LIMIT这些结构。
一个最简单的toy example,利用递归CTE生成一个斐波那契数列:
WITH RECURSIVE fibonacci(n, a_n, a_n_next) AS (
SELECT 1, 0, 1
UNION ALL
SELECT n+1, a_n_next, a_n + a_n_next
FROM fibonacci
WHERE n<9)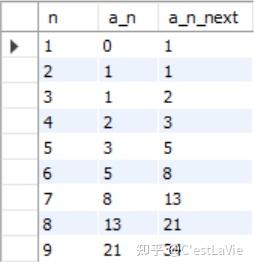
WITH RECURSIVE employee_network AS (
SELECT employeeNumber,
reportsTo,
CONCAT(firstName,' ',lastName) AS employeeName,
CAST('Top Manager' AS CHAR(20)) AS managerName, #如果不转换类型会报错
1 AS nlevel
FROM employees
WHERE reportsTo IS NULL
UNION ALL
SELECT e.employeeNumber,
e.reportsTo,
CONCAT(firstName,' ',lastName),
employeeName,
nlevel + 1
FROM employees e INNER JOIN employee_network en
ON (e.reportsTo=en.employeeNumber))
SELECT employeeName, managerName, nlevel
FROM employee_network
ORDER BY nlevel;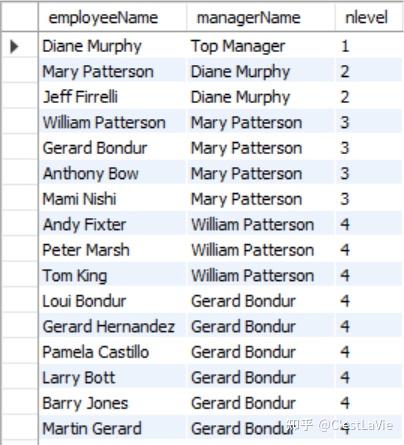
可以看到,这实现了比前面连接更进一步的功能——显示从属关系的等级。
4. 视图(view)
视图是虚拟的表,它包含的不是数据而是用于检索数据的查询语句。当视图被使用时,对应的查询被执行,得到存储在内存中的临时结果。
视图的优点在于:
- 封装了查询语句,方便重用;
- 可以保护数据,一方面可以让用户仅访问表的部分而非全表,另一方面可以创建只读视图防止用户修改数据;
- 允许更改数据格式和表示,添加计算字段等,以优化用户看到的数据形式。
视图的使用方式和普通表相似,可以对视图执行查询,将视图连接到其它表或视图,甚至可以嵌套视图(基于视图创建视图),但这么做会导致效率降低。但不能在视图中创建索引。
#创建视图
CREATE [OR REPLACE] [ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}] VIEW view_name AS SELECT_CLAUSE;
#更改视图
ALTER [ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}] VIEW view_name AS SELECT_CLAUS;
#删除视图
DROP VIEW view_name;当OR REPLACE关键词被指明时,若名称为view_name的视图不存在,那么创建视图;若已经存在同名视图,那么将原视图替换为新视图。
ALGORITHM=指定了视图底层实现的算法:
- MERGE算法将使用视图的查询语句与视图的定义语句组合成一个查询语句,然后执行该查询返回结果;
- TEMPTABLE算法如其名,先根据视图的定义语句创建一个临时表,再在该临时表上做查询;
- 未显式指定ALGORITHM时,算法为UNDEFINED,UNDEFINED会在允许的情况下优先选择MERGE(效率更高)。
在MySQL中,视图可以是可更新的,可以通过INSERT、UPDATE、DELETE通过视图更新基表的行(本质上更新的不是视图而是基表)。要使视图可更新,需要在定义时满足以下要求:
- SELECT_CLAUSE不包含聚合函数、窗口函数、DISTINCT、GROUP BY [HAVING]、UNION [ALL]、任意外连接(左、右、全);
- SELECT_CLAUSE的FROM子句中不含子查询,不含不可更新视图;
- SELECT_CLAUSE不能仅引用常数;
- 算法不能是TEMPTABLE;
- 多次引用基表的同一个列(违反INSERT INTEGRITY CONSTRAINT)。
检查一个视图是否可更新,可使用以下语句:
SELECT table_name, is_updatable
FROM information_schema.views
WHERE table_schema = 'db_name';一个最简单的例子:
CREATE VIEW new_emps AS