


大数据NiFi(二十):实时同步MySQL数据到Hive

实时同步MySQL数据到Hive
案例:将mysql中新增的数据实时同步到Hive中。
以上案例需要用到的处理器有:“CaptureChangeMySQL”、“RouteOnAttribute”、“EvaluateJsonPath”、“ReplaceText”、“PutHiveQL”。
首先通过“CaptureChangeMySQL”读取MySQL中数据的变化(需要开启MySQL binlog日志),将Binlog中变化的数据同步到“RouteOnAttribute”处理器,通过此处理器获取上游数据属性,获取对应binlog操作类型,再将想要处理的数据路由到“EvaluateJsonPath”处理器,该处理器可以将json格式的binlog数据解析,通过自定义json 表达式获取json数据中的属性放入FlowFile属性,将FlowFile通过“ReplaceText”处理器获取上游FowFile属性,动态拼接sql替换所有的FlowFile内容,将拼接好的sql组成FlowFile路由到“PutHiveQL”将数据写入到Hive表。
一、开启MySQL的binlog日志
mysql-binlog是MySQL数据库的二进制日志,记录了所有的DDL和DML(除了数据查询语句)语句信息。一般来说开启二进制日志大概会有1%的性能损耗。这里需要开启MySQL的binlog日志方便后期使用“CaptureChangeMySQL”处理器来获取MySQL中的CDC事件。MySQL的版本最好是5.7版本之上。
1、登录mysql查看MySQL是否开启binlog日志
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';
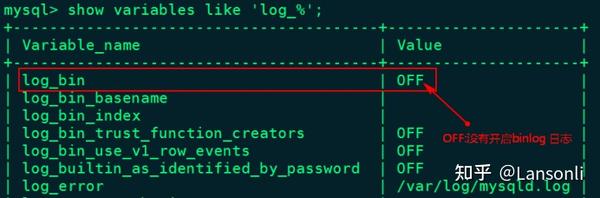

2 、开启mysql binlog日志
在/etc/my.cnf文件中[mysqld]下写入以下内容:
[mysqld]
#随机指定一个不能和其他集群中机器重名的字符串
server-id=123
#配置binlog日志目录,配置后会自动开启binlog日志,并写入该目录
log-bin=/var/lib/mysql/mysql-bin
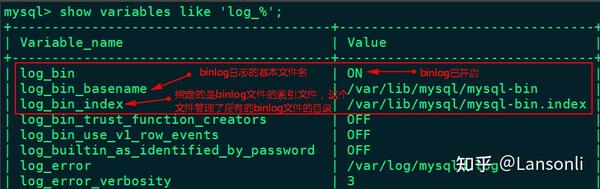
3、重启mysql 服务,重新查看binlog日志情况
[root@node2 ~]# service mysqld restart
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';

二、配置“CaptureChangeMySQL”处理器
“CaptureChangeMySQL”主要是从MySQL数据库捕获CDC(Change Data Capture)事件。CDC事件包括INSERT,UPDATE,DELETE操作,事件按操作发生时的顺序输出为单独的FlowFile文件。
关于“CaptureChangeMySQL”处理器的“Properties”主要配置的说明如下:
| 配置项 | 默认值 | 允许值 | 描述 |
|---|---|---|---|
|
MySQL Hosts
(MySQL 节点) |
| | MySQL集群节点相对应的主机名/端口项的列表。多个节点使用逗号分隔,格式为:host1:port、host2:port…,处理器将尝试按顺序连接到列表中的主机。如果一个节点关闭,并且群集启用了故障转移,那么处理器将连接到活动节点。 |
|
MySQL Driver Class Name
(MySQL驱动名称) |
com.mysql.jdbc.Driver | | MySQL数据库驱动程序类的类名。 |
|
MySQL Driver Location(s)
(MySQL驱动的位置) |
| | 包含MySQL驱动程序包及其依赖项的文件/文件夹和/或url的逗号分隔列表(如果有),例如"/var/tmp/mysql-connector-java-5.1.38-bin.jar文件"。 |
|
Username
(用户名) |
| | 访问MySQL集群的用户名。 |
|
Password
(密码) |
| | 访问MySQL集群的密码。 |
|
Database/Schema Name Pattern
(匹配数据库/Schema) |
| | 用于根据CDC事件列表匹配数据库(或模式,具体取决于RDBMS类型)的正则表达式。正则表达式必须与存储在RDBMS中的数据库名称匹配。如果未设置属性,则数据库名称将不会用于筛选CDC事件。 |
|
Table Name Pattern
(匹配表) |
| | 用于匹配影响匹配表的CDC事件的正则表达式(regex)。regex必须与存储在数据库中的表名匹配。如果未设置属性,则不会根据表名筛选任何事件。 |
|
Max Wait Time
(最大连接等待时长) |
30 seconds | | 允许建立连接的最长时间,零表示实际上没有限制。 |
|
Distributed Map Cache Client
(分布式缓存客户端) |
| | 指定用于保存处理器所需的各种表、列等信息的分布式映射缓存客户端控制器服务。如果未指定,则生成的事件将不包括列类型或名称等信息。 |
|
Retrieve All Records
(检索所有记录) |
true |
▪true
▪false |
指定是否获取所有可用的CDC事件,而不考虑当前的binlog文件名或位置。
如果处理器状态中存在binlog文件名和位置值,则忽略此属性的值。 这允许4种不同的配置: 1).如果处理器State中存在binlog数据,则State用来确定开始位置,并忽略Retrieve All Records的值。(目前NiFi版本测试有问题) 2).如果处理器State中不存在binlog数据,此值设置为true意味着从头开始读取Binlog 数据。 3).如果处理器State中不存在binlog数据,并且没有指定binlog文件名和位置,此值设置为false意味着从binlog尾部开始读取数据。 4).如果处理器State中不存在binlog数据,并指定binlog文件名和位置,此值设置为false意味着从指定binlog尾部开始读取数据。 |
|
Include Begin/Commit Events
(包含开始/提交事件) |
false |
▪true
▪false |
指定是否发出与二进制日志中的开始或提交事件相对应的事件。如果下游流中需要开始/提交事件,则设置为true,否则设置为false,这将抑制这些事件的生成并可以提高流性能。 |
|
Include DDL Events
(标准表/列名) |
false |
▪true
▪false |
指定是否发出与数据定义语言(DDL)事件对应的事件,如ALTER TABLE、TRUNCATE TABLE。如果下游流中需要DDL事件,则设置为true,否则设置为false。为false时这将抑制这些事件的生成,并可以提高流性能。 |
配置步骤如下:
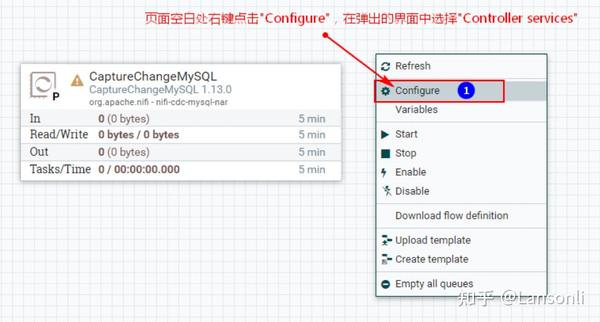
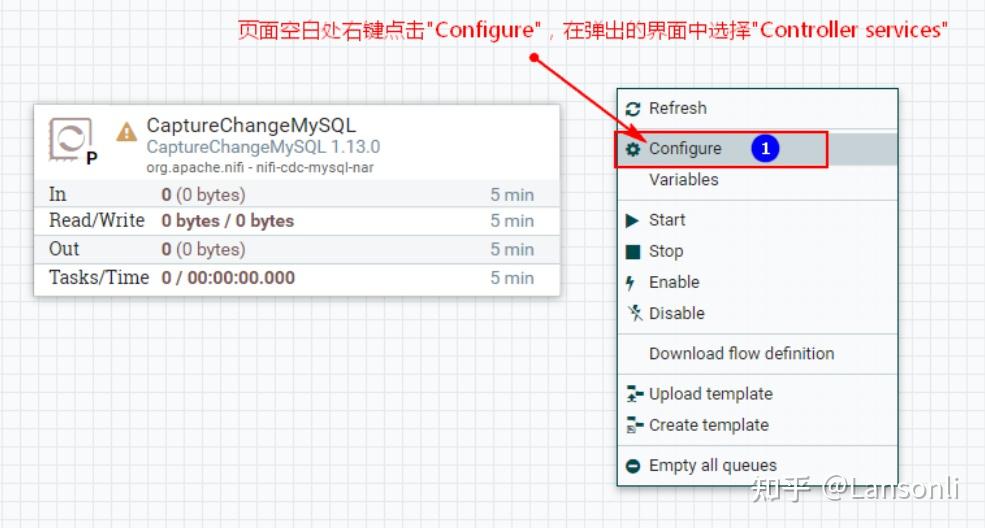
1、创建“CaptureChangeMySQL”处理器
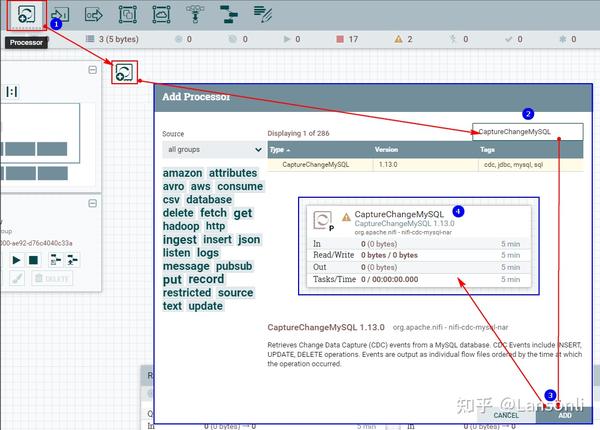
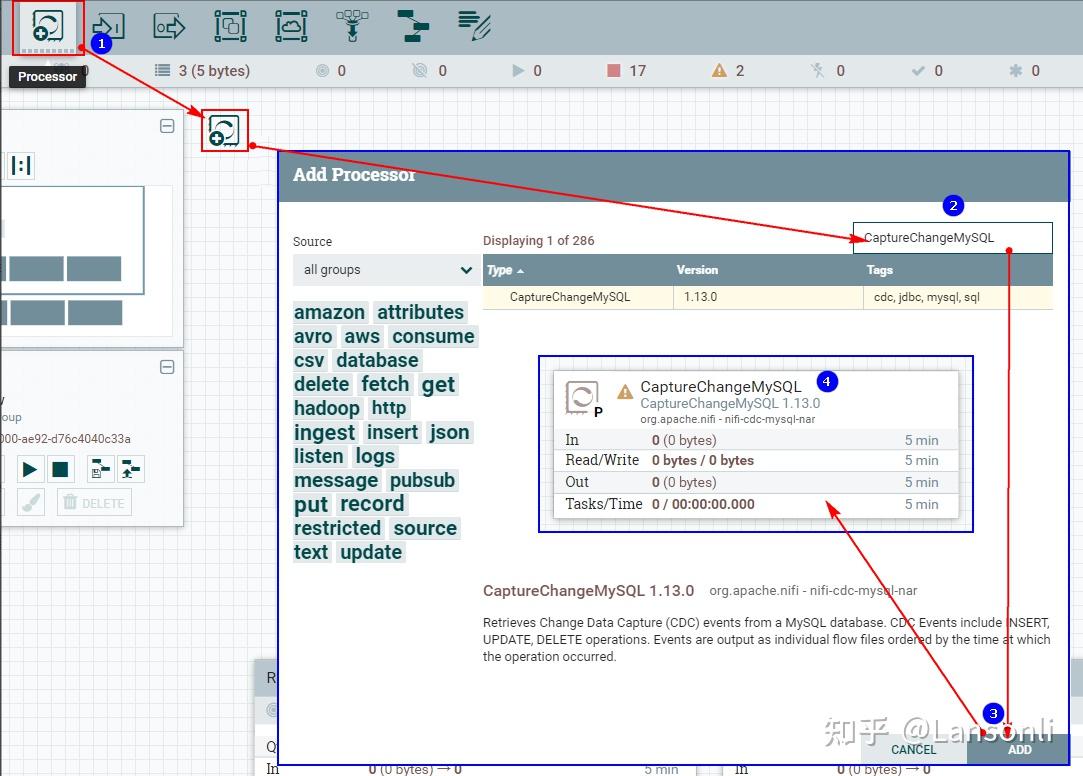
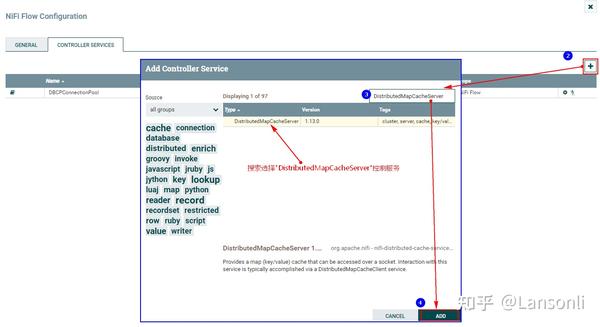
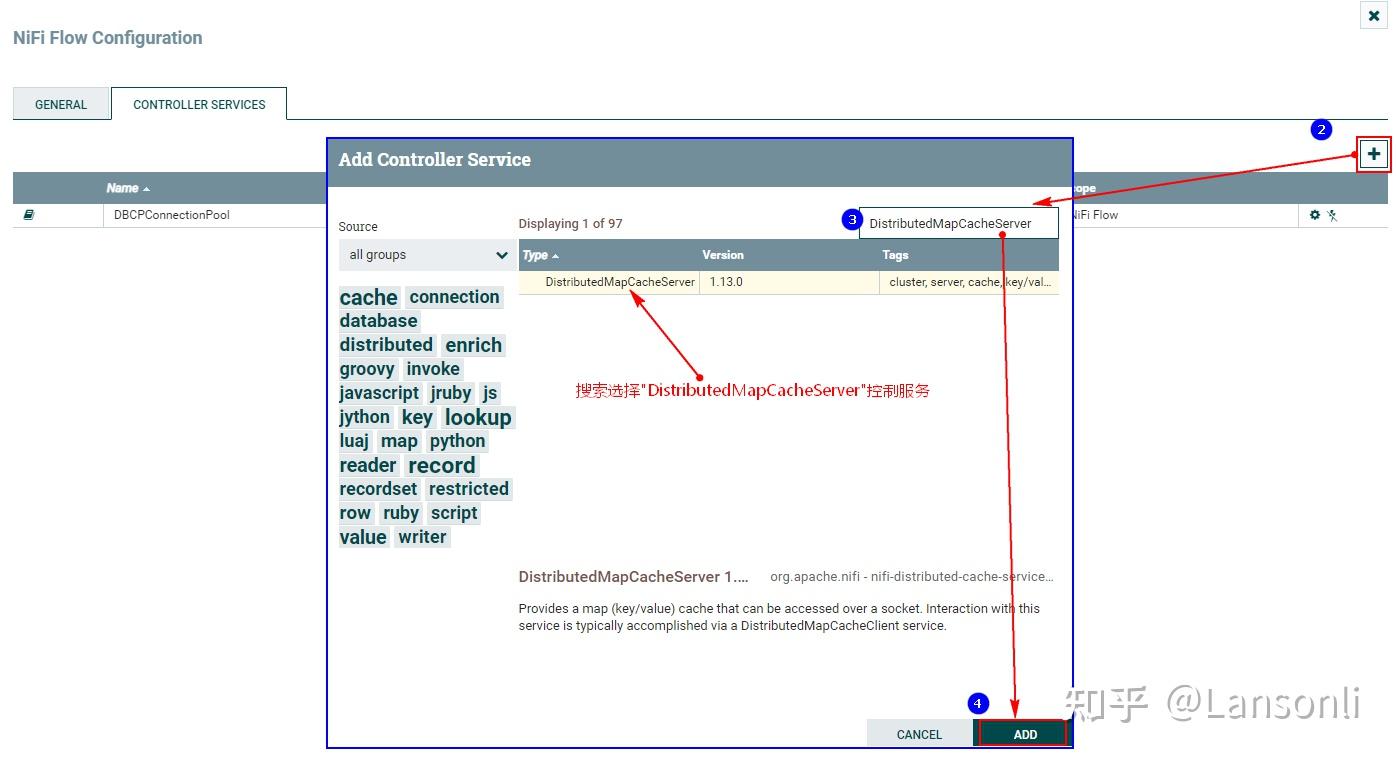
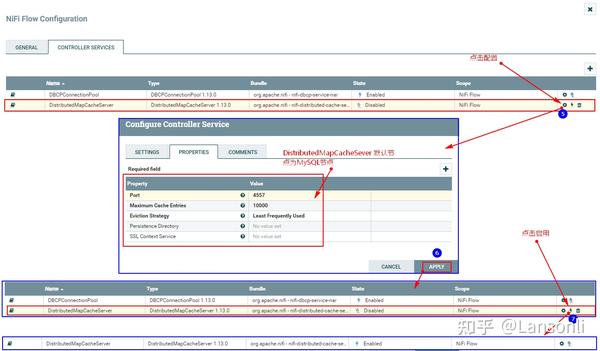
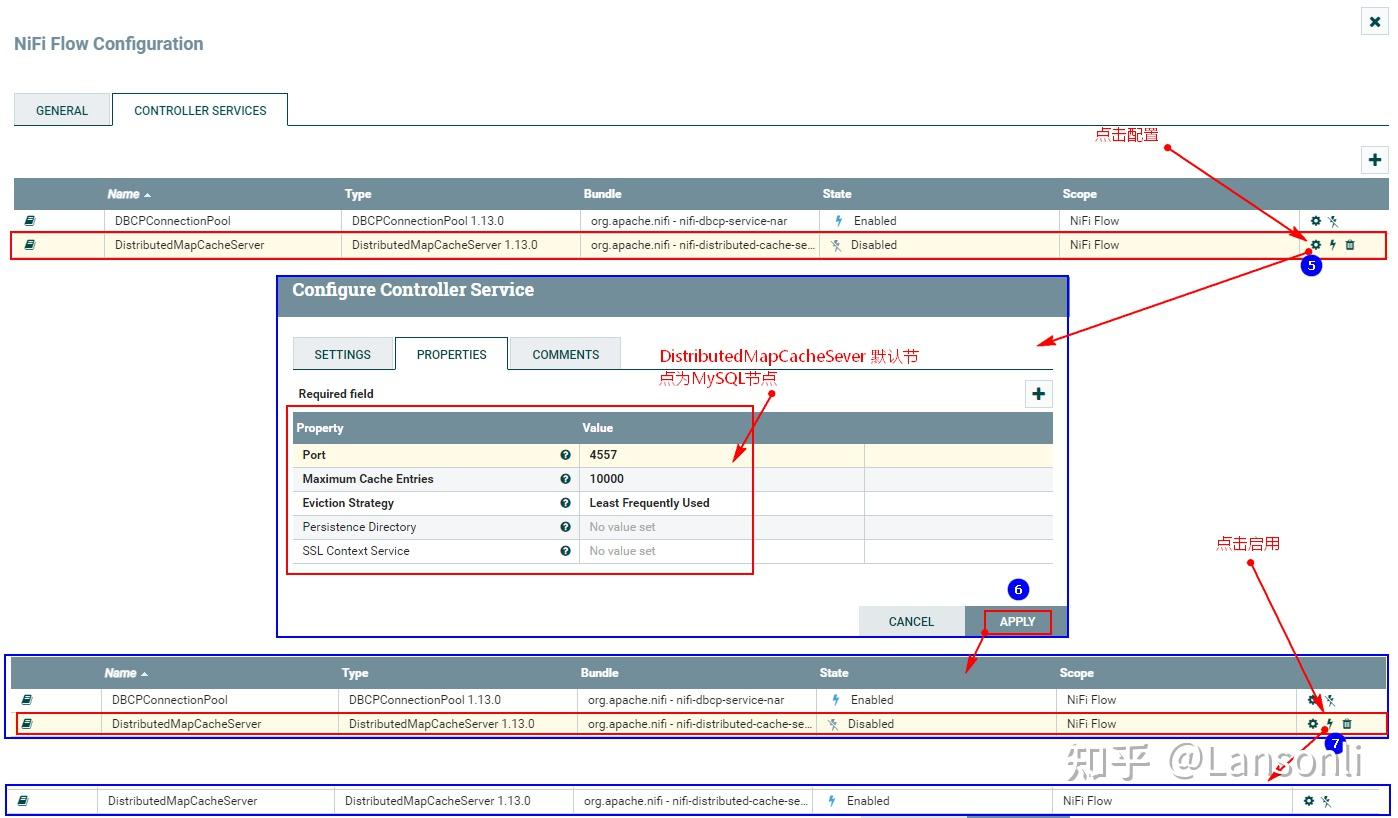
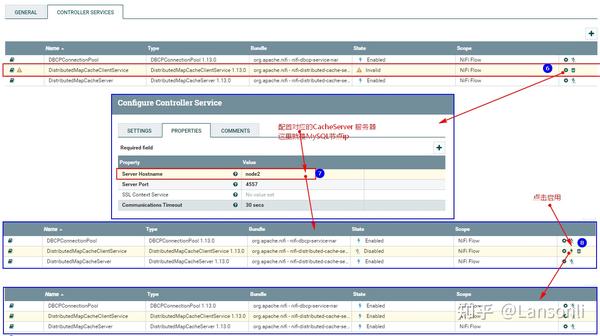
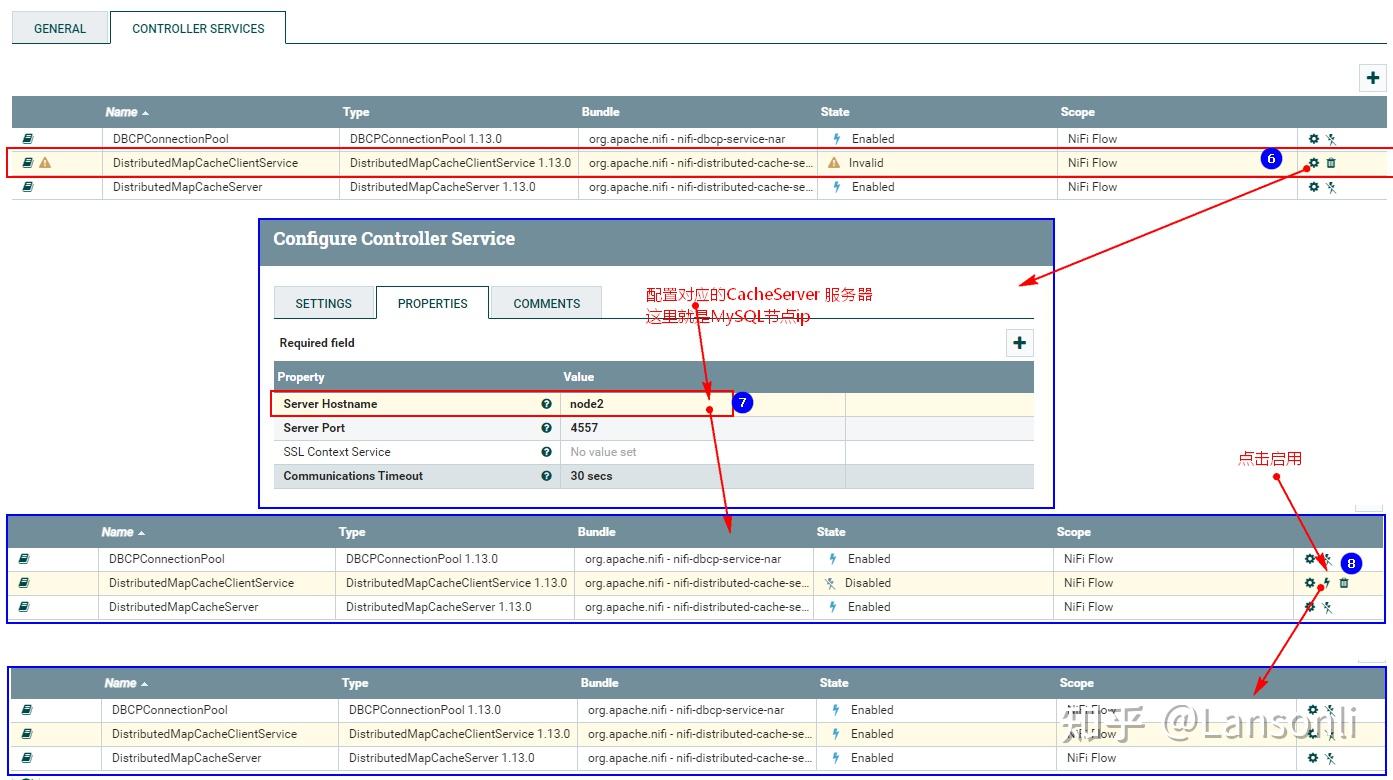
2、配置“DistributeMapCacheServer”控制服务
监控mysql变化需要设置“DistributedMapCacheClient”控制服务,其对应的Server中存储处理器所需的各种表、列等信息,所以这里需要首先配置“DistributeMapCacheServer”控制服务。
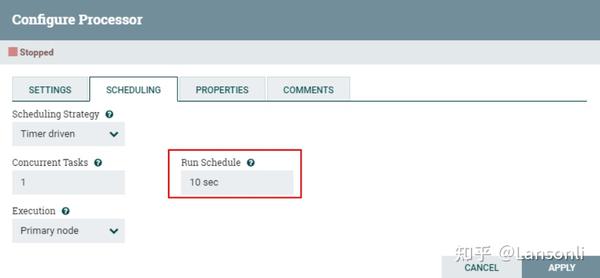
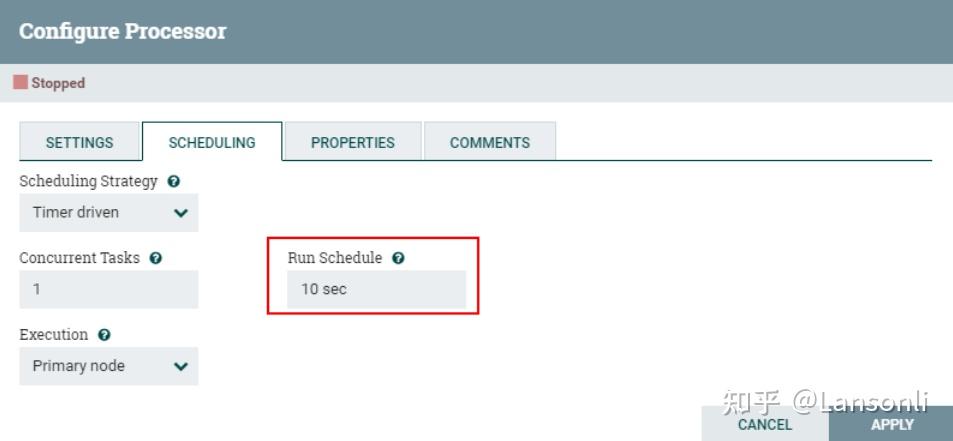
3、配置“SCHEDULING”
由于这里使用“CaptureChangeMySQL”处理器监控“MySQL”中的数据,所以设置调度访问周期为“10s”,防止一直监听MySQL binlog数据,带来性能消耗。
4、配置“PROPERTIES”
在“CaptureChangeMySQL”处理器中配置“PROPERTIES”,配置如下:
- MySQL Host : 192.168.179.5:3306
- MySQL Driver Class Name:com.mysql.jdbc.Driver
- MySQL Driver Location(s):/root/test/mysql-connector-java-5.1.47.jar
注意:这里需要在每台NiFi节点上创建对应目录,上传mysql驱动包。
“PROPERTIES”配置如下:
此外,在“PROPERTIES”中还需要配置“Distributed Map Cache Client”控制服务,来读取“DistributeMapCacheServer”控制服务中的缓存数据:
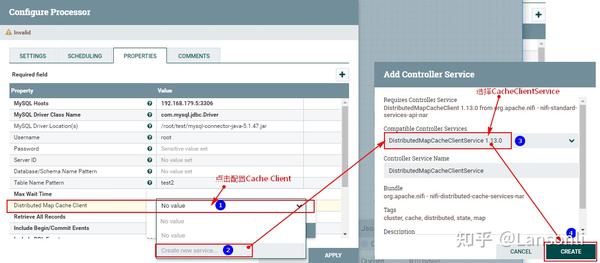
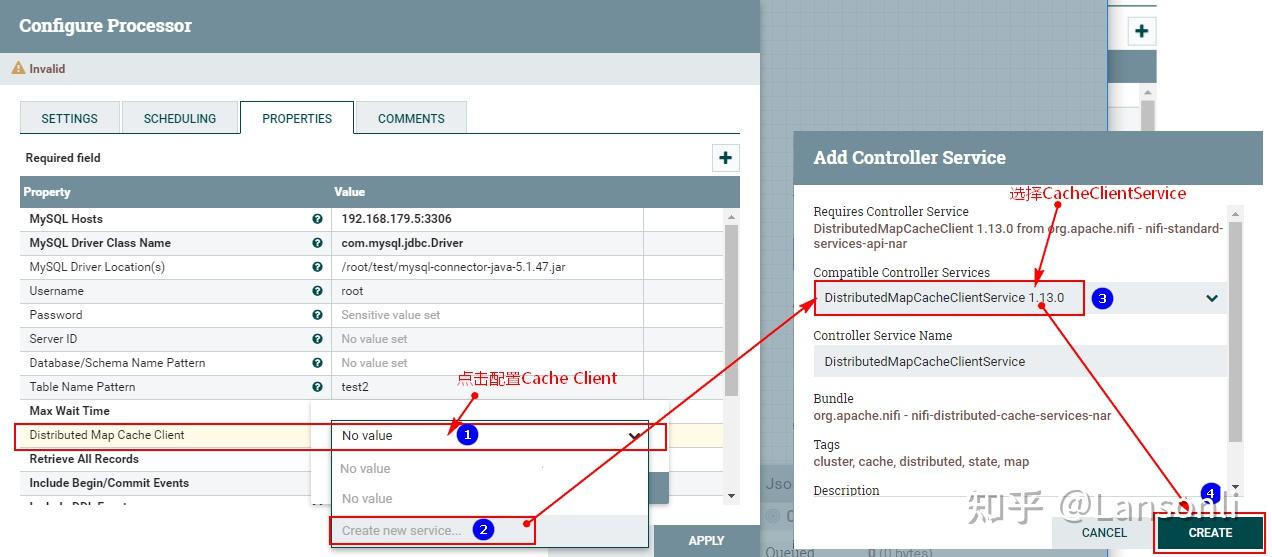
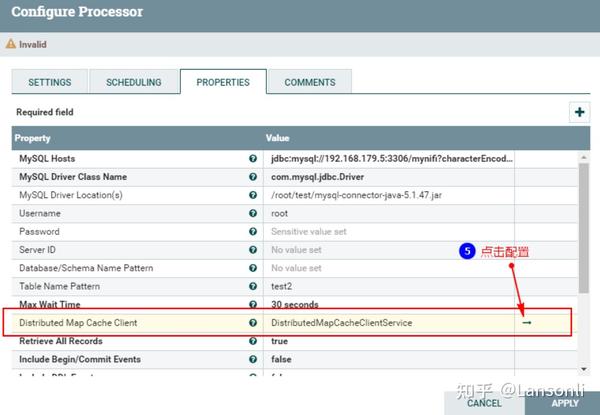
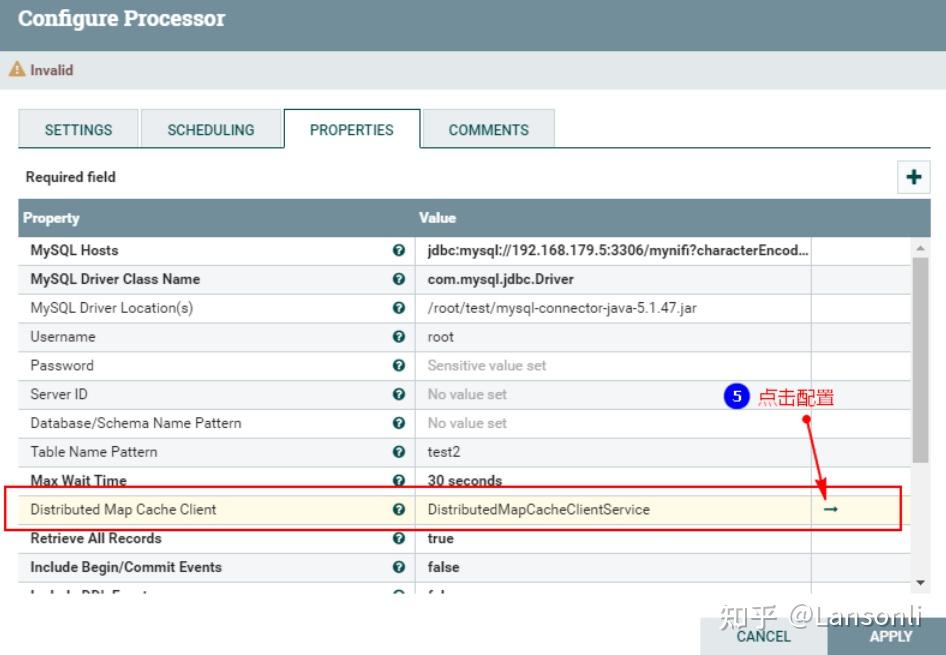
另外,这里我们只是监控表“test2”对应的CDC事件,这里设置匹配表名为“test2”,最终“PROPERTIES”的配置如下:
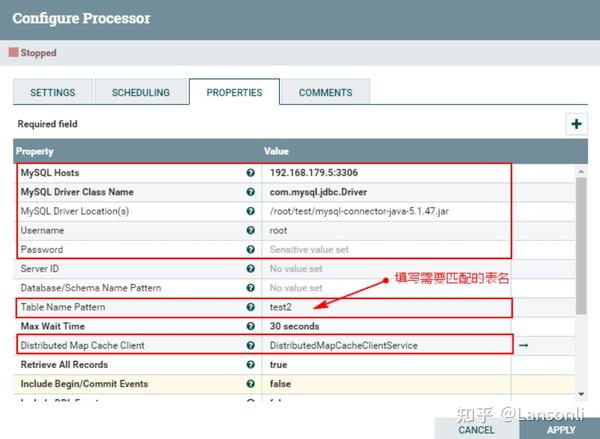
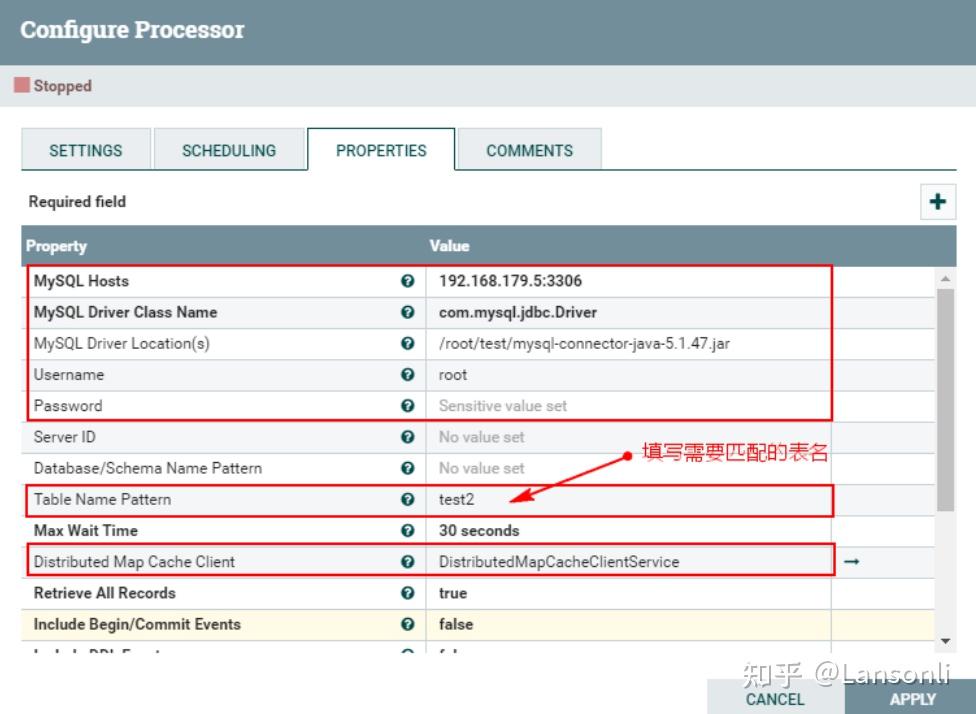
注意:以上“Table Name Pattern”这里配置对应的Value值为:test2,也可以不配置,不配置会监控所有MySQL表的变化对应的binlog事件。当后面向Hive表中插入新增和更新数据时,对应MySQL中的元数据表也会变化,也会监控到对应的binlog事件。为了避免后期出现监控到其他表的binlog日志,这里建议配置上“test2”。
5、启动MySQL,创建表“test2”测试“CaptureChangeMySQL”处理器
登录mysql ,使用“mynifi”库,创建表“test2”。暂时设置“CaptureChangeMySQL”处理器“success”事件自动终止并启动,向表中插入对应的数据查看“CaptureChangeMySQL”处理器能否正常监控事件。
在mysql中创建对应的表:
use mynifi;
create table test2 (id int,name varchar(255),age int);
启动“CaptureChangeMySQL”处理器:
向表“test2”中插入以下数据:
insert into test2 values (1,"zs",18);
update test2 set name = "ls" where id = 1;
delete from test2 where id = 1;
可以在“CaptureChangeMySQL”处理器中右键“View data provenance”查看捕获到的“insert”、“update”、“delete”事件:
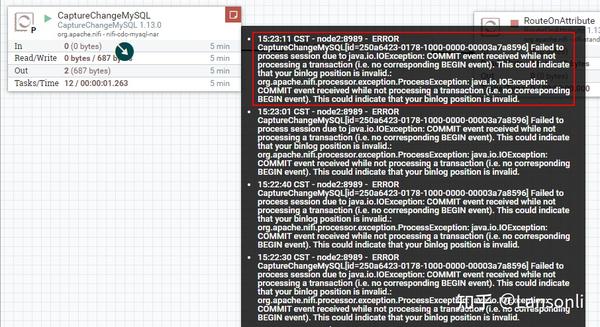
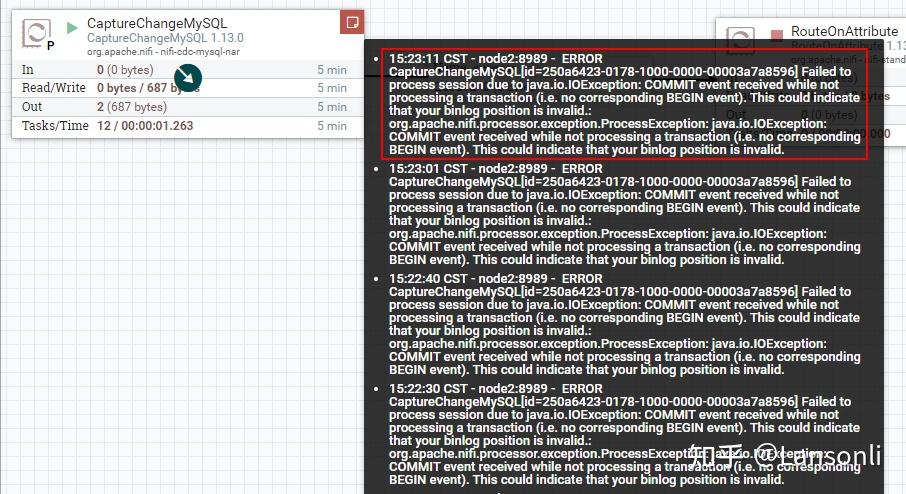
注意问题:在配置好“CaptureChangeMySQL”处理器启动后,当MySQL中有数据插入、修改、删除时当前处理器会读取MySql binlog日志,并在当前处理器中记录读取binlog的位置状态。正常来说这里关闭“CaptureChangeMySQL”处理器后再次启动,会接着保存的binlog位置继续读取(可以参照“PROPERTIES”属性中“Retrieve All Records”配置说明),但是经过测试,此NiFi版本出现以下错误(无效的binlog位置,目测是一个版本bug错误):
所以在之后的测试中,我们可以将“CaptureChangeMysql”处理器读取binlog的状态清空,然后再次启动即可,这里会重复读取MySQL之前已经检测到的新增、修改、删除数据。
清空“CaptureChangeMysql”读取binlog状态:
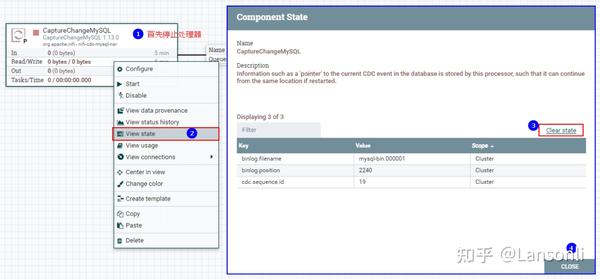
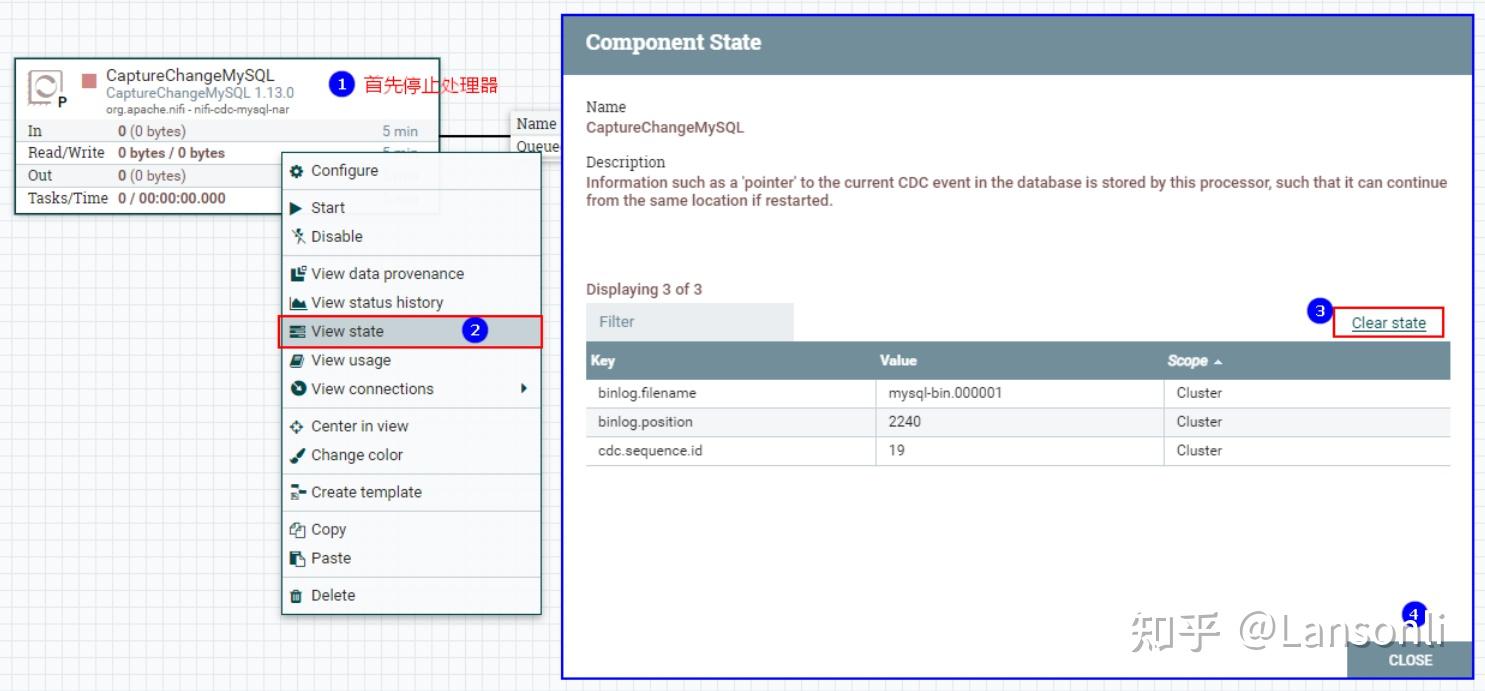
三、配置“RouteOnAttribute”处理器
“RouteOnAttribute”是根据FlowFile的属性使用属性表达式进行数据路由。
关于“RouteOnAttribute”处理器的“Properties”主要配置的说明如下:
| 配置项 | 默认值 | 描述 |
|---|---|---|
| Routing Strategy(路由策略) | Route to Property name |
指定在计算表达式语言时如何使用哪个关系。
有如下几个关系可选择: ▪Route to Property name FlowFile的副本将被路由到对应的表达式计算结果为'true'的每个关系。 ▪Route to 'matched' if all match 要求所有用户定义的表达式求值都为'true',才认为FlowFile是匹配的。 ▪Route to 'matched' if any matches 至少有一个用户定义的表达式求值为'true',才能认为FlowFile是匹配的。 |
注意:该处理器允许用户自定义属性并指定该属性的匹配表达式。属性与动态属性指定的属性表达式相匹配的FileFlow,映射到动态属性上。
配置如下:
1、创建“RouteOnAttribute”处理器
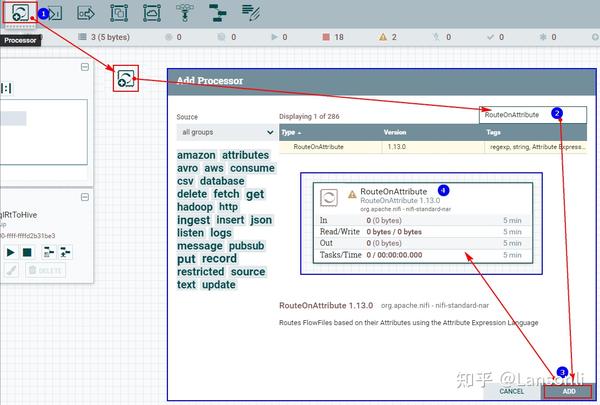
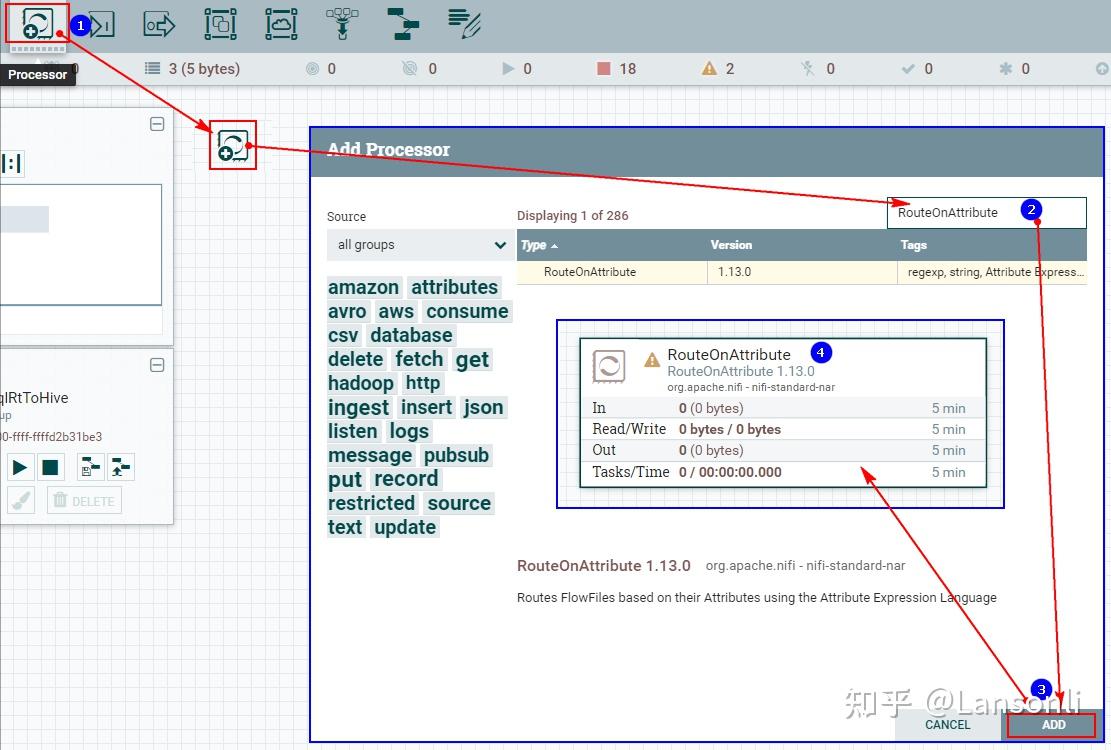
2、配置“PROPERTIES”自定义属性
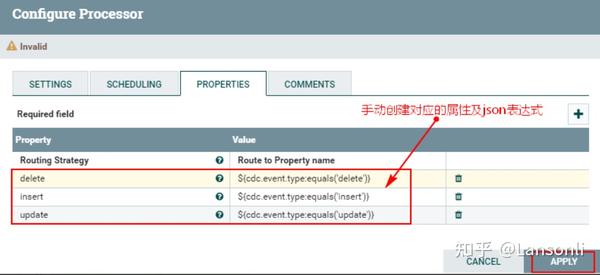
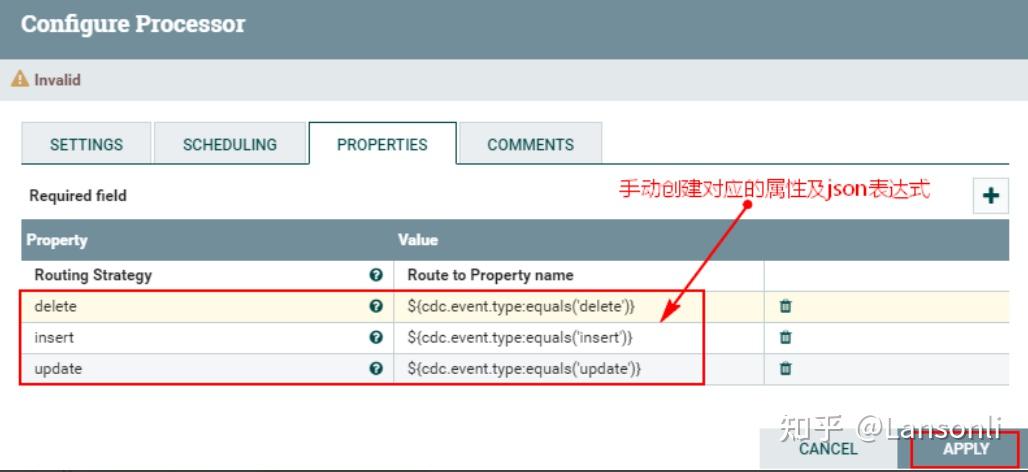
注意:以上自定义的属性中update、insert、delete对应的json 表达式写法为:${cdc.event.type:equals('delete')},代表匹配对应类型的FlowFile,“cdc.event.type”是上游FlowFile中的属性,“equales”是对应的方法,“delete”使用单引号引起,表示匹配的CDC事件。
3、连接“CaptureChangeMySQL”处理器与“RouteOnAttribute”处理器


四、配置“EvaluatejsonPath”处理器
“EvaluatejsonPath”处理器将根据上游“RouteOnAttribute”匹配的事件将内容映射成FlowFile属性,方便后期拼接SQL获取数据,上游匹配到的FlowFile中的数据格式为:
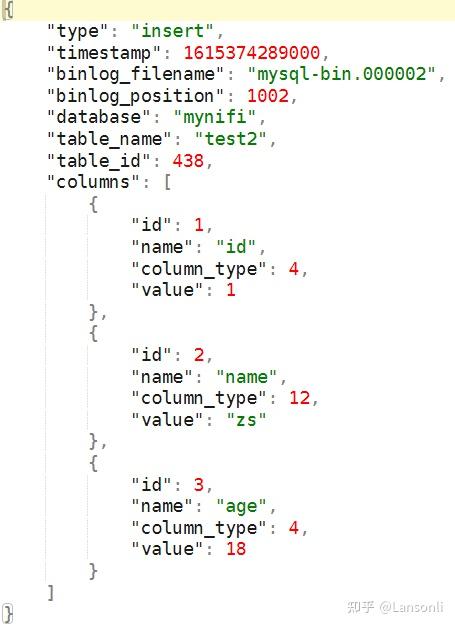
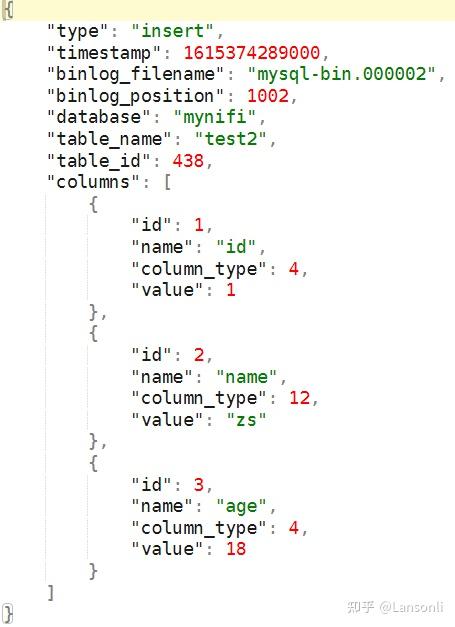
EvaluatejsonPath”处理器配置如下:
1、配置“EvaluatejsonPath”的“PROPERTIES”属性
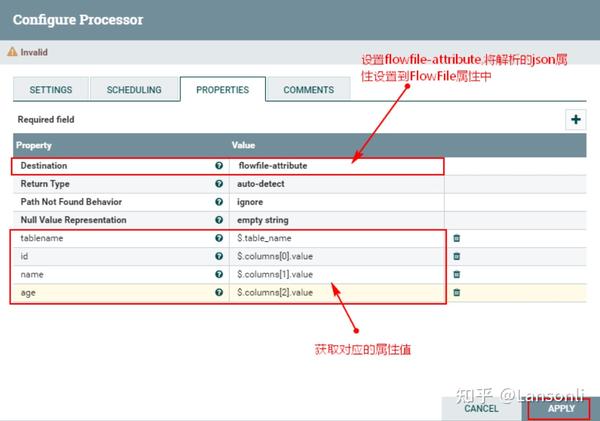

2、连接“RouteOnAttribute”处理器和“EvaluatejsonPath”处理器
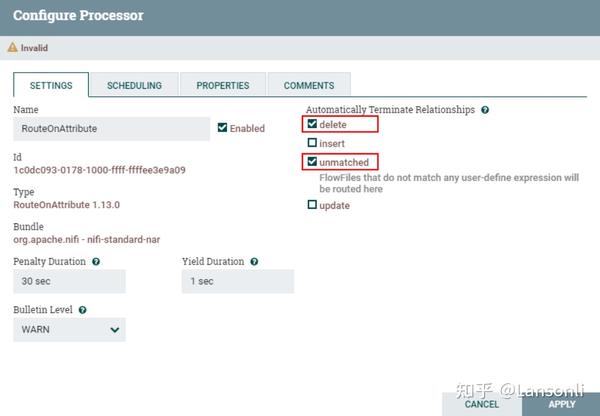
连接关系中,我们这里只关注“insert”和“update”的数据,后期获取对应的属性将插入和更新的数据插入到Hive表中,对于“delete”的数据可以路由到其他关系中,例如需要将删除数据插入到另外的Hive表中,可以再设置个分支处理。这里我们将“delete”和“failure”的数据设置自动终止关系。


设置“RouteOnAttribute”处理器其他匹配路由关系为自动终止:

五、配置“ReplaceText”处理器
“ReplaceText”处理器可以获取“EvaluatejsonPath”转换后FlowFile中的属性来替换原有数据组成一个“insert into ... values (... ...)”语句,方便后续将数据插入到Hive中。“ReplaceText”处理器的配置如下:
1、配置“RelaceText”处理器“PROPERTIES”属性
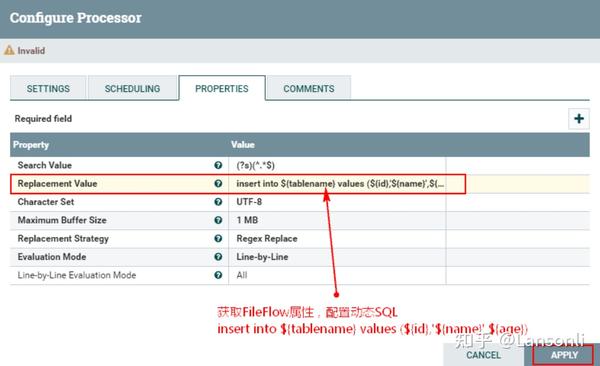
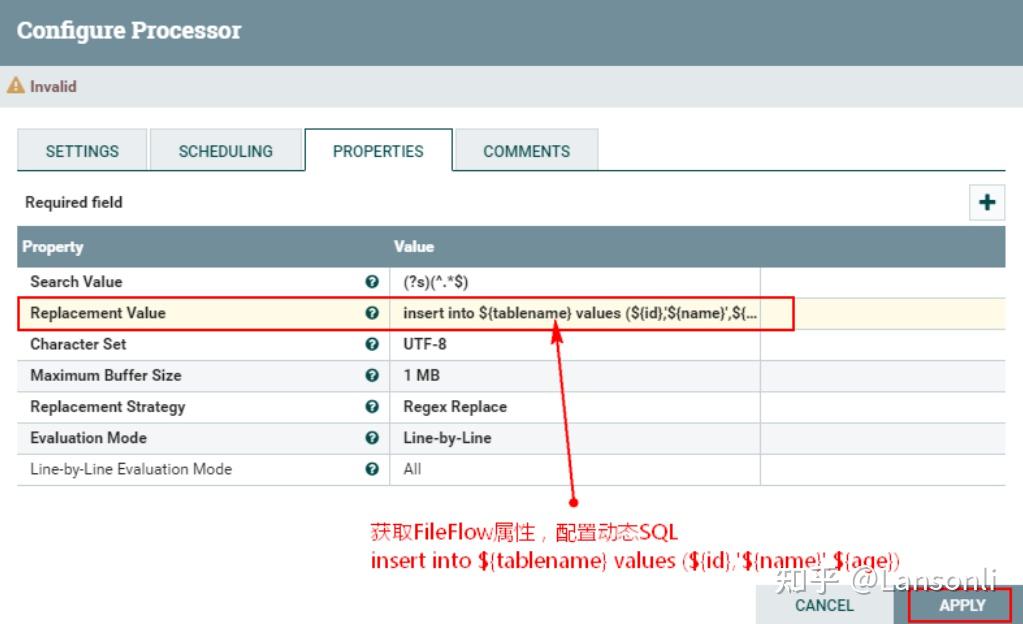
在“Replacement Value”中配置“insert into {tablename} values ( {id},' {name}', {age})”
注意:
以上获取的tablename名称为“test2”,后面这个sql是要将数据插入到Hive中的,所以这里在Hive中也应该创建“test2”的表名称,或者将表名称写成固定表,后期在Hive中创建对应的表即可。
另外,需要注意${name}在插入Hive中时对应的列为字符串,这里需要加上单引号。
2、连接“EvaluatejsonPath”处理器与“ReplaceText”处理器


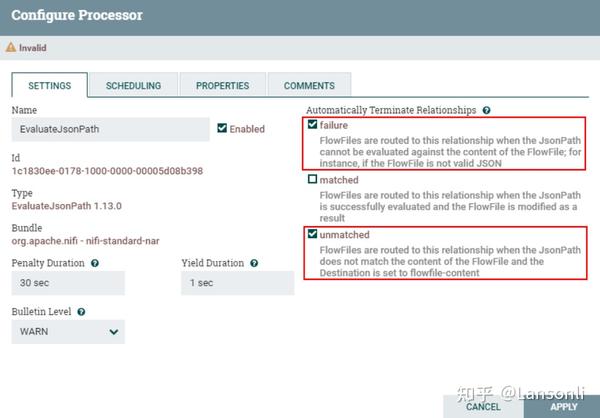
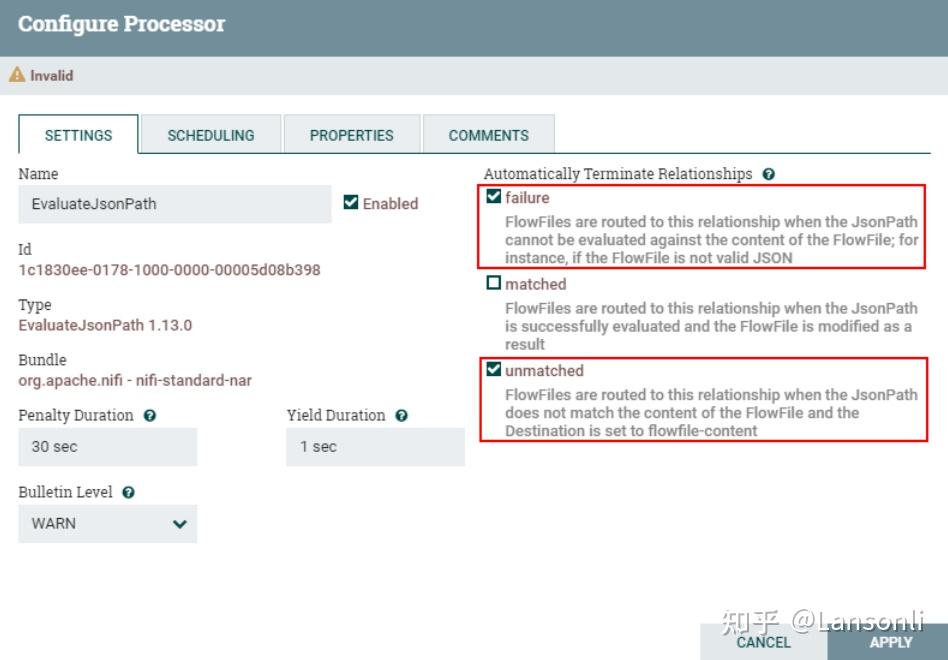
配置“EvaluatjsonPath”处理器“failure”和“unmatch”路由关系为自动终止。
六、配置Hive 支持HiveServer2
访问Hive有两种方式:HiveServer2和Hive Client,Hive Client需要Hive和Hadoop的jar包,配置环境。HiveServer2使得连接Hive的Client从Yarn和HDFS集群中独立出来,不需要每个几点都配置Hive和Hadoop的jar包和一系列环境。
NiFi连接Hive就是使用了HiveServer2方式连接,所以这里需要配置HiveServer2。
配置HiveServer2步骤如下:
1、在Hive服务端配置hive-site.xml
#在Hive 服务端 $HIVE_HOME/etc/hive-site.xml中配置:
<!-- 配置hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.179.4</value>
</property>
2、在每台Hadoop 节点配置core-site.xml
<!-- 配置代理访问用户 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
3、重启HDFS ,Hive ,在Hive服务端启动Metastore和HiveServer2服务
nohup hive --service metastore >> ./nohup.out 2>&1 &
nohup hive --service hiveserver2 >> ./nohup.out 2>&1 &
4、在客户端通过beeline连接Hive
[root@node3 test]# beeline
beeline> !connect jdbc:hive2://node1:10000 root
Enter password for jdbc:hive2://node1:10000: 没有密码直接跳过即可
0: jdbc:hive2://node1:10000> show tables;
+------------------------------------+
| tab_name |
+------------------------------------+
| personinfo |
| test2 |
+------------------------------------+