上采样的技术是图像进行超分辨率的必要步骤,最近看到了CVPR2019有一些关于上采样的文章,所以想着把上采样的方法做一个简单的总结。
看了一些文章后,发现上采样大致被总结成了三个类别:
1、基于线性插值的上采样
2、基于深度学习的上采样(转置卷积)
3、Unpooling的方法
其实第三种只是做各种简单的补零或者扩充操作,下文将不对其进行涉及。
为了方便大家阅读,做了个小的目录,接下来的文章介绍主要分为以下内容:
线性插值
1、最近邻算法
2、双线性插值算法
3、双三次插值算法(bicubic)
深入学习
1、转置卷积
2、PixelShuffle(亚像素卷积,CVPR2016)
3、DUpsampling(亚像素卷积,CVPR2019)
4、Meta-Upscale(任意尺度缩放,CVPR2019)
5、CAPAFE(内容关注与核重组,思路新颖,ICCV2019)
线性插值用的比较多的主要有三种:最近邻插值算法、双线性插值、双三次插值(BiCubic),当然还有各种其改进型。在如今SR中这些方法仍然广泛应用。这些方法各有优劣和劣势,主要在于处理效果和计算量的差别。
计算效果:最近邻插值算法 < 双线性插值 < 双三次插值
计算速度:最近邻插值算法 > 双线性插值 > 双三次插值
在接下来我会将测试这些算法的效果和运行速度。
1、最近邻插值算法
最近邻插值算法是最简单的一种插值算法,当图片放大时,缺少的像素通过直接使用与之最近原有颜色生成,也就是说照搬旁边的像素这样做结果产生了明显可见的锯齿。在待求像素的四邻像素中,将距离待求像素最近的邻灰度赋给待求像素。

一张来自网上的图,描述的很清楚,也就是说在A区域的值邻近于(i,j)点,所以都将(i,j)点的像素值赋予在A区域的所有像素,同理可得其他的区域。在图上没有表达清楚的是在坐标轴上的像素如何处理,个人觉得可能是在程序中定义等号偏向于一边。

可见有很明显的马赛克块,这里我没有用opencv的resize去做(这个函数里的最近邻应该不是很准确,不清楚里面做了什么优化或者其他处理,理论上相邻的像素值是一样的,但是那个库调用后出来的效果和其他两种方法的效果基本相同而且时间差不多。。。。)
2、双线性插值
双线性插值就是做两次线性变换,先在X轴上做一次线性变换,求出每一行的R点:
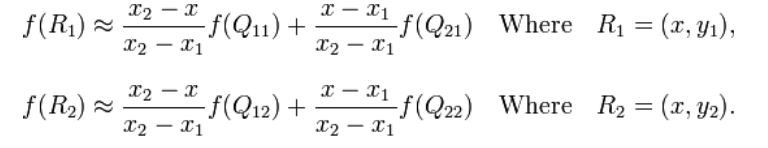
再通过一次线性变换求出在该区域中的P点:
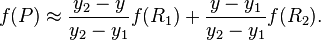
可以把上式汇成所要计算的f(x,y)
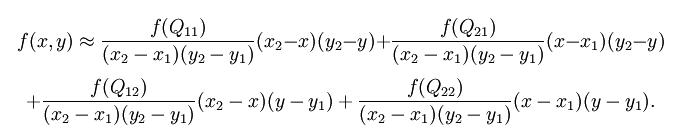
效果如图:

3、双三次插值
双三次插值在SR中引用的比较多,其计算也比较复杂速度较慢。它实际上也是一种插值的方式,但是并不是通过线性插值,而是通过邻近的4x4的像素做加权。
首先第一步是先构建作者所说的BiCubic函数,即上式中的aij
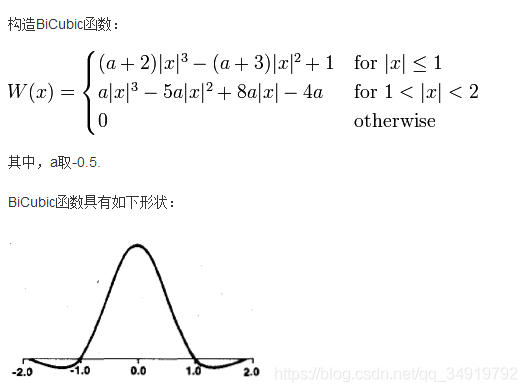
其中aij = W(x)* W(y),即我们要分别求取x,y方向的W,然后相乘作为权重。
至于x的取值访问如何理解,我简单把我的理解绘制成这张图,当要求的像素点为(u,v),则内圈的四个点权值计算选用|x|<=1的计算公式,外圈的选择另一个公式。
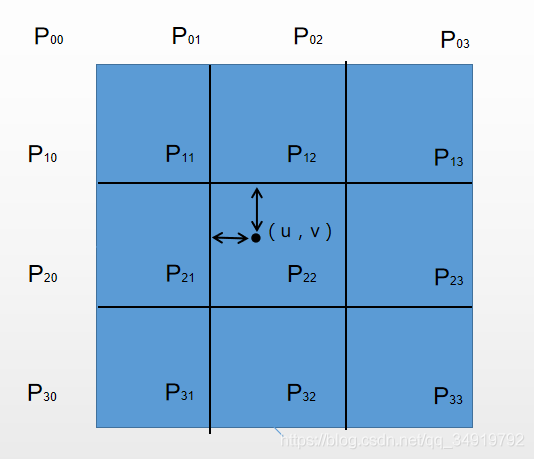
之后的计算就是对这16个值做加权,即可求出(u,v)的像素值。

手写代码的运行速度(按原理写的,没有优化有点慢)

使用的话opencv中的resize可以直接使用,而且速度特别快,但是他的最近邻运行出来的效果太好了,而且时间最长,对于有点疑惑。。如果有懂的朋友麻烦解惑谢谢。以下是opencv运行时间:

1、转置卷积
基于深度学习的上采样实际上就是通过训练转置卷积核对图片的尺寸进行扩充,当然为了取得好的效果,肯定不单单是一个转置卷积核就可以办到的,很多的学者对上采样的网络做了很多工作。
基础的转置卷积可以参考这篇文章:
https://blog.csdn.net/gaotihong/article/details/79164172

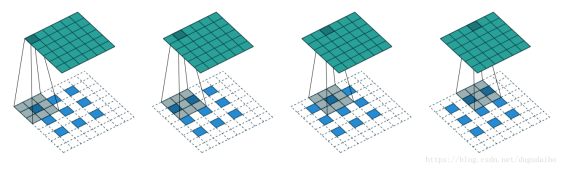
除了以上这种单纯通过补零和unpooling来做输入的扩大的方法之外,近几年来,随着语义分割和超分辨率的发展,也出现了很多其他深度学习的方法来做上采样,取得了很好的效果。
2、PixelShuffle
PixelShuffle是在CVPR2016的Real-Time Single Image and Video Super-Resolution Using an Effificient Sub-Pixel Convolutional Neural Network一文中提出。ESPCN的主要概念是关注于亚像素卷积层,通过三次卷积之后输出与原图一样尺寸的r
2
通道的输出图,再通过如下图所示的reshape方法将 Hx Wxr
2
的特征图转成 rHxrW 的输出图。而扩大的倍数刚刚好等同于通道数。这样的做法可以让网络去学习到一种插值方法,并存在于前面三层卷积层的参数中。
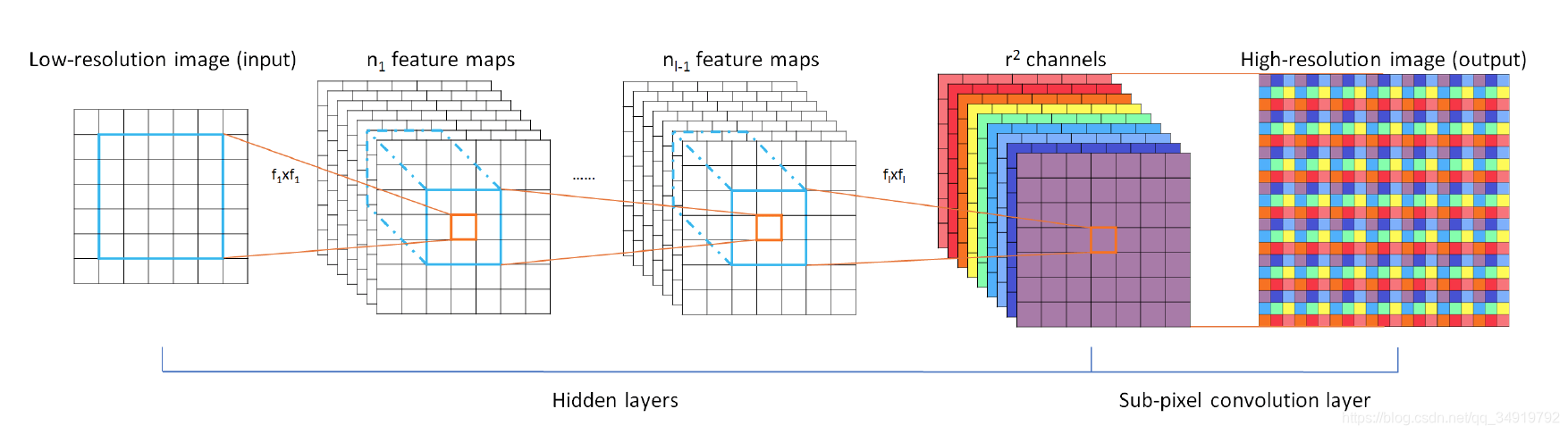
这个方法的提出对超分辨率有两个与之前不同的贡献:一个是不需要再通过一开始进行线性插值来扩大输入的尺寸了,从而可以用更小的卷积核就可以获得很好的效果,另一个是作者认为bicubic是一种卷积的特殊情况(即计算权重相乘求和),用卷积学习可以学会比手工设计更好的拟合方式。
3、DUpsampling
这个上采样方法是在CVPR2019中的Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation∗中提出的,从下面的网络结构来看和PixelShuffle有点类似,它是通过卷积学习亚像素,并最后重组来获得更大的图像。

DUpsampling在对特征图的操作上有所不同,是先通过将单个像素所对应的C个通道reshape成一个1xC的向量,与CxN的矩阵相乘得到1xN的向量,再reshape成为2x2xN/4(2应该指的是放大倍数,即rxrxN/r
2
)的扩大后的亚像素块,组合成放大后的特征图。
以上这两种算法都是基于数据去训练的,可以获得比线性插值更好的效果,但是与线性插值相比存在的问题是:1、对于不同的放大倍数的图像需要训练不同的网络(因为通道数的改变);2、不容易进行连续的放大,比如1.1倍,1.2倍这样。说不容易而不是不能是因为可以适当放大输入图像或者对权重和步长进行调整后放缩,但是计算很复杂,效果没有整数倍好,线性插值却很容易办到。
4、Meta-Upscale
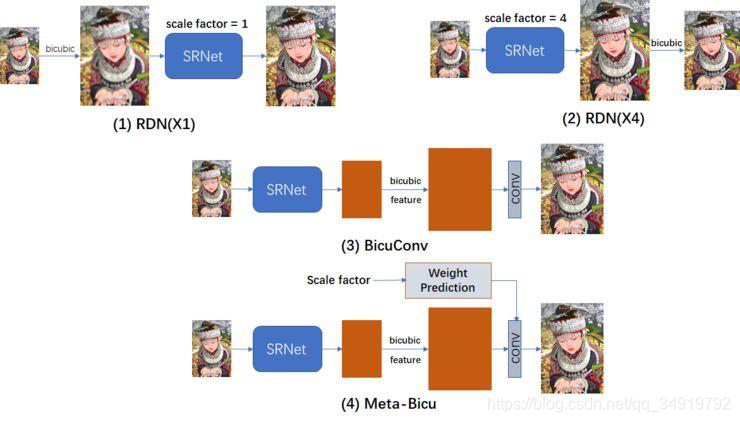
先上一张图,这张图我觉得比较好的说明了原来的方法要如何做一次非整数尺度的放缩,这样方便进一步了解Meta-SR的思路。
Meta-SR中的Meta-Upscale是在CVPR2019上的Meta-SR: A Magnifification-Arbitrary Network for Super-Resolution一文中提出来的,作者提出了一种可以任意尺度缩放的方法,可以实现较好效果的非整数的放缩。
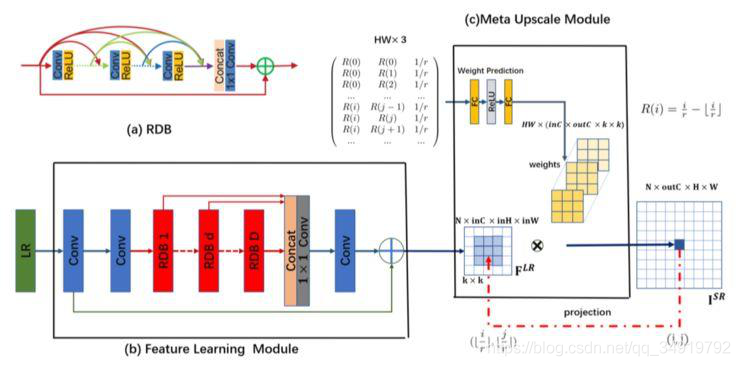
F
LR
表示由特征学习模块提取的特征,并假定缩放因子是 r。对于 SR 图像上的每个像素(i, j),文中认为它由 I
LR
图像上像素(i′,j′)的特征与一组相应卷积滤波器的权重所共同决定。从这一角度看,放大模块可视为从 F
LR
到 I
SR
的映射函数。
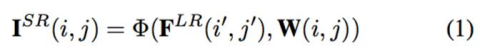
我对此的理解是,kxk应该是所设定的与I^SR所相关的一个像素搜索范围。及这个范围内的所有像素都是和最后输出的像素是有关系的,需要对其计算相应的权重并加权计算。HWx(InCxoutC)我的理解是图像最后输出的长x宽x输入的通道数(文中为64)x输出的通道数(文中为3)做为权值生成的输出的通道数。对于一个像素的计算我们需要对64个通道上feature map上的对应9个值加权求和,就可以计算出输出的一个通道值,重复3次就是一个值的3个通道数的值,重复HW次就可以计算出整个输出。
那么知道最后如何计算输出之后,我们关心的是文中提到的是怎么来做对不同的放缩大小的权值计算的以及如何在任意尺度下完成输出像素和LR特征图上的对应。
作者把 Meta-Upscale 模块由三个重要的函数,即 Location Projection、Weight Prediction、Feature Mapping(这个就是上文讲的如何乘以权值得到最后的输出)。
先说下文中的Location Projection,如下图:
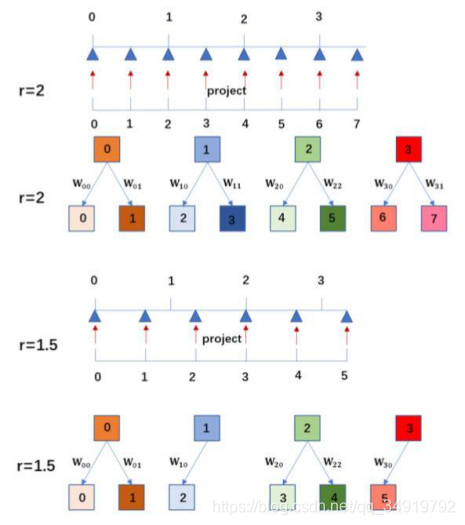
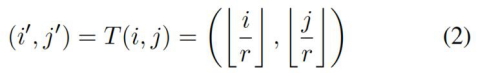
通过向下取整使得I
SR中的每一个值都可以在I
LR上找到一个对应的值。如放大1.5倍,那么I
LR上的0对应I
SR中的0和1(0/1.5<1,1/1.5<1)。
而权重预测Weight Prediction在网络中是通过构建了两层全链接层和relu来实现的,输出在上文已经讲过了就不再重复,而文中用于预测的输入是这样获得的,如下式:
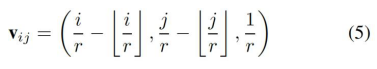
总结一下,Meta-SR中的思路有点像RPN,做了一个外部的推荐网络,来推荐放缩的权值及像素的对应关系,在非整数倍放大上起的不错的效果。
5、CAPAFE
CAPAFE是出自ICCV2019中的CARAFE: Content-Aware ReAssembly of FEatures 一文中的,作者提出了构建一种内容感知并重组特征的上采样方法,看到这篇文章的时候感觉到它的结构思路与之前有很大的不同。
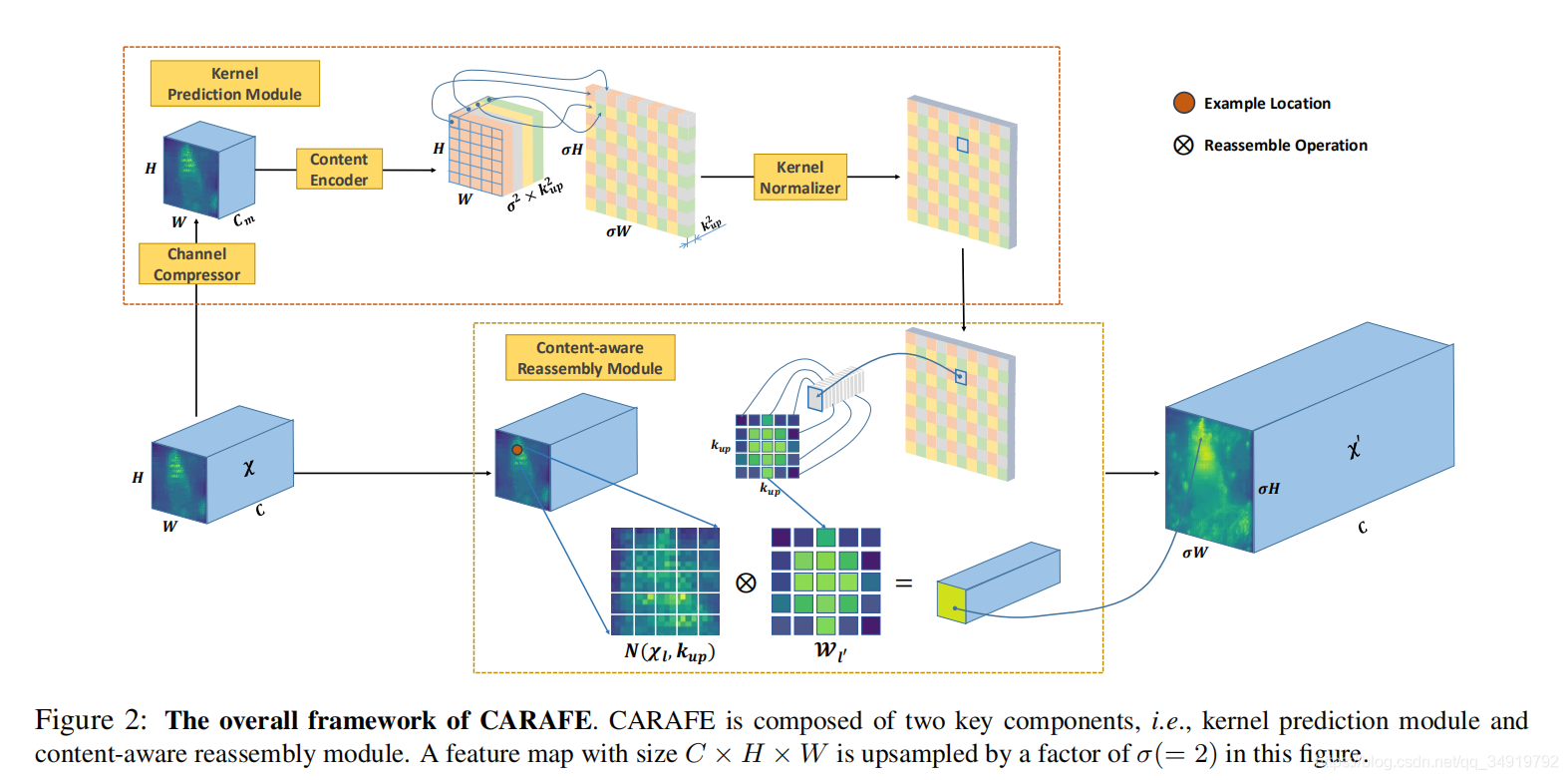
CAPAFE的整个网络结构由两部分组成,一部分是核预测模块(Kernel Prediction Module),用于生成用于重组计算的核上的权重。另一部分是内容感知重组模块(Content-aware Reassembly Module),用于将计算到的权重将通道reshape成一个kxk的矩阵作为核与原本输入的特征图上的对应点及以其为中心点的kxk区域做卷积计算,获得输出。
首先我们先关注下核预测模块是如何预测出权重值的,这一部分文中分为三部分:通道压缩器(Channel Compressor)、内容编码(Content Encoder)、核归一化(Kernel Normaliaer)。输入的Feature map通过1x1的卷积核,完成对通道数的压缩,文中提及这一步的原因是为了减少计算量,而且文中说通过实验将通道数压缩在64不会影响效果,文中给的Cm为64。之后通过多层Kenconder x Kenconder的卷积核完成对特征图的计算,输出HxWxσ
2
xKup
2
的特征图,这里Kenconder的大小与感受野有关,越大生成的权重与周围的内容的关联性越高。最后将特征图reshape成σHxσWxKup
2
,之后单独对每一个像素的所有通道用softmax做归一化,为了是最后生成的重组核内权重值和为1。这样权重的预测就完成了。
之后将预测好的权重对每一个像素都拉成kupxkup的卷积核即图中对应的Wl,通过对(i/σ,j/σ)向下映射的方法(floor function)找到每个像素在原来的feature map上对应的点,以其为中心点构建出kupxkup的区域做卷积计算,就可以得到一个像素的输出,重复操作可以获得整个输出。
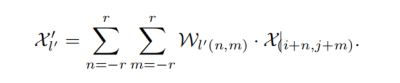
CAPAFE的整个网络内的参数量特别少,只有Content Encoder中的NxKenconder x Kenconderxσ
2
xKup
2
的卷积核的参数,同时它的上采样思路也比较不同,当然它无法如Meta-SR那样做连续缩放。
一、简介上采样的技术是图像进行超分辨率的必要步骤,最近看到了CVPR2019有一些关于上采样的文章,所以想着把上采样的方法做一个简单的总结。看了一些文章后,发现上采样大致被总结成了三个类别:1、基于线性插值的上采样2、基于深度学习的上采样(转置卷积)3、Unpooling的方法其实第三种只是做各种简单的补零或者扩充操作,下文将不对其进行涉及。为了方便大家阅读,做了个小的目录,接下来的...
卷积递归神经网络(CRNN)在OCR的研究中取得了巨大的成功。 但是现有的深度模型通常在池化操作中应用下采样,以通过丢弃一些特征信息来减小特征的大小,这可能会导致丢失占用率较小的相关字符。 而且,循环模块中的所有隐藏层单元都需要在循环层中连接,这可能导致沉重的计算负担。 在本文中,我们尝试使用密集卷积网络(DenseNet)替代CRNN的卷积网络来连接和组合多个功能,从而潜在地改善结果。 另外,我们使用
上采样
功能构造一个
上采样
块,以减少池化阶段下采样的负面影响,并在一定程度上恢复丢失的信息。 因此,信息特征也可以用更深层次的结构来提取。 此外,我们还直接使用内部卷积部分的输出来描述每个帧的标签分布,以提高处理效率。 最后,我们提出了一个新的OCR框架,称为DenseNet,带有
上采样
块联合和连接主义的时间分类,用于中文识别。 中文字符串数据集上的结果表明,与几种流行的深度框架相比,我们的模型提供了增强的性能。
三种
上采样
方式
总结
在GAN,图像分割等等的网络中
上采样
是必不可少的。这里记录一下自己学到的三种
上采样
方式:反卷积(转置卷积),双线性
插值
+卷积,反池化。
反卷积(转置卷积)
卷积只会减小或不变输入的大小,转置卷积则是用来增大输入的大小。用于细化粗的特征图等等,FCN中就有应用。这里一个图就能很简单表明他做的事情。感觉就是做的卷积反过来的事情。转置卷积是可以进行学习的。
kernel核张量与输入的张量中,逐个元素相乘,放在对应的地方。就是说第一个元素是0,就是0乘上整个核张量,放在对应的位置。第二个元素是
下采样即缩小图像,主要有两个目的:使得图像符合需要的大小;生成对应图像的缩略图。
下采样的原理很简单,比如对于一幅尺寸为MxN的图像,对其进行s倍下采样,即得到(M/s)x(N/s)尺寸的图像。这可以通过把原始图像划成sxs的窗口,使每个窗口内的图像变成一个像素,这个像素点的值可以是窗口内所有像素的均值或者最大值等等。另外我认为高斯滤波等卷积方式本身也是一种下采样。
上采样
与下采样相反,其目的是放大图像。注意,它并不能带来更多关于该图像的信息,因此图像的质
文章目录一、
上采样
二、下采样
一、
上采样
放大图像(或称为
上采样
(
ups
amp
lin
g)或图像
插值
(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
上采样
的原理:
图像放大几乎都是采用内
插值
方法
,即在原有图像像素的基础上在像素点之间采用合适的
插值
算法插入新的元素。
二、下采样
缩小图像(或称为下采样(subs
amp
led)或降采样(downs
amp
le...
在做图像语义分割的时候,编码器通过卷积层得到图像的一些特征,但是解码器需要该特征还原到原图像的尺寸大小,才可以对原图像的每个像素点进行分类。从一个较小尺寸的矩阵进行变换,得到较大尺寸的矩阵,在这个过程就是
上采样
。
常见的
上采样
的
方法
有(1)
插值
法(最邻近
插值
、双线性
插值
等) (2)转置卷积(又称为反卷积) (3)
上采样
(uns
amp
lin
g)(4)上池化(unpoo
lin
g)
插值
法不需...
下采样的方式主要有两种:
1、采用stride为2的池化层,如Max-poo
lin
g和Average-poo
lin
g,目前通常使用Max-poo
lin
g,因为他计算简单而且能够更好的保留纹理特征;
2、采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替poo
lin
g可以得到更好的效果,
Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation
D
Ups
amp
lin
g-新型
上采样
模块:能够聚合丰富特征的数据相关型解码方式(CVPR2019)
该论文提出新型
上采样
方法
D
Ups
amp
lin
g来替代双线性
插值
。实验表明,基于D
Ups
amp
lin
g的解码器在多个通用数据集上取得了STOA效果,并且计算量仅有原有模型的20%~30%。
本文提出的
方法
在单一场景以及人群密集环境下都可以对暴力打斗行为进行准确识别。2.针对人脸图像在单训练样本下难以被准确识别的问题,提出了一种基于核主成分分析网络(Kerne1 Principle Component Analysis Networks,KPCANet)模型的二阶段投票人脸识别
方法
。该
方法
在不使用额外样本数据的情况下,利用非监督深层模型KPCANet对分块后的人脸图像进行训练并利用KPCA学习得到的滤波器进行特征提取,从而保证了提取的特征对光照及遮挡的鲁棒性,同时也消除了人脸局部形变对识别率的影响。本文通过投票的
方法
融合每一个分块的预测值来得到最后的识别结果,对于单次投票结果不唯一的情况,本文采取了二阶段的投票
方法
,通过扩大每一块的预测候选集,并对不同的区域赋予不同的权值来得出最后的结果,从而进一步提升了识别的准确率。实验结果表明,该
方法
在四个公开人脸数据集上都取得了优异的表现,算法准确率优于使用了额外数据集的通用
方法
,尤其是在非限制人脸数据集LFW-a上,本文提出的
方法
比SVDL和LGR
方法
准确率提升了约l5%。3.针对监控视频中人脸图像由于分辨率过低而无法准确识别的问题,提出了一种基于卷积神经网络模型的低分辨率人脸识别的解决方案。该方案提出了两种模型:多尺度输入的卷积神经网络(Convolutional Neural Networks,CNN)模型和基于空间金字塔池化(Spatial Pyramid Poo
lin
g,SPP)的CNN模型。(1)多尺度输入的CNN模型是对现有的"二步法"进行的改进,利用简单双三次
插值
方法
对低分辨率图像进行
上采样
,再将
上采样
得到的图像与高分辨率图像混合作为模型训练样本,让CNN模型学习高低分辨率图像共同的特征空间,然后通过余弦距离来衡量特征相似度,最后给出识别结果。在CMU PIE和Extended Yale B数据集上的实验表明,模型的准确率要优于其他对比
方法
,相对于目前识别率最高的CMDA_BGE算法,准确率获得了 2.5%~9.9%的显著提升。(2)基于SPP的CNN模型,属于改进的"跨空间法",通过在CNN模型中加入空间金字塔池化层,使模型对于不同尺寸的输入图像都可以输出恒定维度的特征向量,最后通过比较样本库与测试图像的特征相似度就可以得到最后的识别结果。实验表明,相比多尺度输入的CNN模型,该
方法
在保持较高准确率的同时,省去了
上采样
的操作,简化了图像预处理的过程,同时也减少了传统"跨空间法"中需要学习的呋射函数的个数。4.针对监控系统中数据流传输带来的带宽占用问题以及对海量数据的快速准确分析需求,提出了一种基于"海云协同"的
深度学习
模型框架。海端系统利用
深度学习
的
方法
对本地数据进行训练得到局部模型,通过局部模型可以对数据进行快速检测,进而给出实时响应。海端系统通过上传局部模型和少量数据的方式协同云端训练,云端系统利用这些局部模型和数据构建更加复杂的深度模.型并进行调优,得到性能更好的全局模型。在MNIST、Cifar-10和LFW数据集上的实验表明,"海云协同"的
方法
有效地减少了数据传输的带宽消耗,同时也保证了海端的快速性和云端的精确性。上述
方法
已部分应用于中科院先导"海量网络数据流海云协同实时处理系统(XDA060112030)" 课题之中。
知网论文,学习使用
上采样
技术定义理解:可以理解为下采样的一种逆运算。下采样一般是特征图进行conv2d卷积操作或者poo
lin
g池化操作不断的提取原特征图的信息导致特征图会越来越小。而
上采样
技术恰好相反。我们希望将特征图变得越来越大,也就是在原来的信息基础上又生成一些信息出来
上采样
技术有以下几种:
反池化unpoo
lin
g
双线性
插值
interpolation
unpoo
lin
g技术又分为1、zero unpoo
lin
g 2、max unpoo
lin
g
zero unpoo
lin
g实际上就是在原来的特征
什么是
上采样
:
中文版维基百科上的解释,“升采样是一种
插值
的过程,应用于数字信号处理,当一串数列或连续的讯号经过升采样后,输出的结果约略等于讯号经由更高的取样速率采样后所得的序列。”
也就是说
上采样
就是
插值
,约等于提高了采样的频率。
上采样
在图像处理中的作用:
提高图像分辨率。因为,分辨率是一张图像像素点的个数,经过
上采样
后,像素点个数提高了,所以,分辨率提高了。
上采样
的
方法
:
三个常见的
插值
方法
:最近邻
插值
,双线性
插值
,双三次
插值
三个常见unpoo
lin
g:zero unpoo
lin
g, max un
1. 基于生成模型的
方法
基于生成模型的
方法
使用生成对抗网络(GAN)或变分自编码器(VAE)等模型来生成高分辨率图像。这些模型可以学习从低分辨率图像到高分辨率图像的映射,并生成逼真的高分辨率图像。这些
方法
的优点是生成结果逼真,能够处理各种不同的图像类型。
2. 基于卷积神经网络的
方法
基于卷积神经网络的
方法
使用卷积层和
上采样
层来学习从低分辨率图像到高分辨率图像的映射。这些
方法
使用深度卷积神经网络(DCNN)来提取图像特征,并使用反卷积或转置卷积等
上采样
层来将低分辨率图像转换成高分辨率图像。这些
方法
的优点是速度快,能够处理大量数据,但是生成结果可能存在伪影或失真。
基于卷积神经网络的
方法
可以进一步分为单图像
上采样
和多图像
上采样
两类。单图像
上采样
方法
使用一个低分辨率图像来生成一个高分辨率图像,而多图像
上采样
方法
使用多个低分辨率图像来生成一个高分辨率图像,例如超分辨率重建。
CSTrack: Rethinking the competition between detection and ReID in Multi-Object Tracking
非常不满意——:
牛客网笔试输入输出的一堆坑。。(Python)
七层皇堡 yyds:
MOT和MTMC指标总结及详细计算方法
weixin_46381582:

