许多时候,我们对程序的速度都是有要求的,速度自然是越快越好。对于Python的话,一般都是使用multiprocessing这个库来实现程序的多进程化,例如:
我们有一个函数my_print,它的作用是打印我们的输入:
def my_print(x):
print(x)
但是我们嫌它的速度太慢了,因此我们要将这个程序多进程化:
from multiprocessing import Pool
def my_print(x):
print(x)
if __name__ == "__main__":
x = [1, 2, 3, 4, 5]
pool = Pool()
pool.map(my_print, x)
pool.close()
pool.join()
很好,现在速度与之前的单进程相比提升非常的快,但是问题来了,如果我们的参数不只有一个x,而是有多个,这样能行吗?比如现在my_print新增一个参数y:
def my_print(x, y):
print(x + y)
查看pool.map的函数说明:
def map(self, func, iterable, chunksize=None):
Apply `func` to each element in `iterable`, collecting the results
in a list that is returned.
return self._map_async(func, iterable, mapstar, chunksize).get()
发现函数的参数是作为iter传进去的,但是我们现在有两个参数,自然想到使用zip将参数进行打包:
if __name__ == "__main__":
x = [1, 2, 3, 4, 5]
y = [1, 1, 1, 1, 1]
zip_args = list(zip(x, y))
pool = Pool()
pool.map(my_print, zip_args)
pool.close()
pool.join()
可是执行后却发现,y参数并没有被传进去:
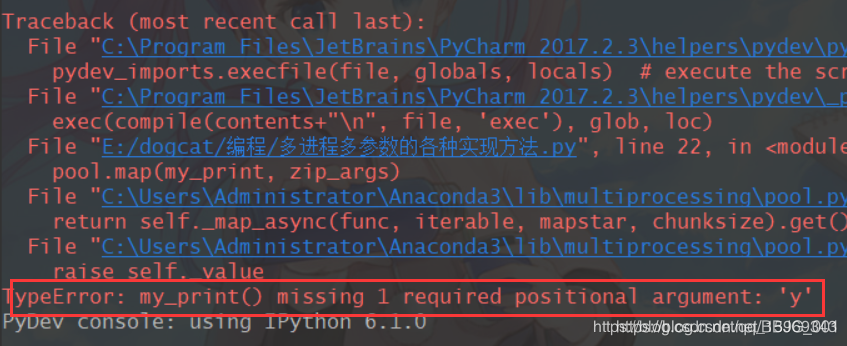
那么如何传入多个参数呢?这也就是本文的重点,接着往下看吧。
2.1 使用偏函数(partial)
偏函数有点像数学中的偏导数,可以让我们只关注其中的某一个变量而不考虑其他变量的影响。上面的例子中,Y始终等于1,那么我们在传入参数的时候,只需要考虑X的变化即可。例如你有一个函数,该函数有两个参数a,b,a是不同路径的下的图片的路径,b是输出的路径。很明显,a是一直在变化的,但是因为我们要将所有图片保存在同一个文件夹下,那么b很可能一直都没变。具体如下:
if __name__ == '__main__':
x = [1, 2, 3, 4, 5]
y = 1
partial_func = partial(my_print, y=y)
pool = Pool()
pool.map(partial_func, x)
pool.close()
pool.join()
2.2 使用可变参数
在Python函数中,函数可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,这就直接给我们提供了一种思路。具体如下:
def multi_wrapper(args):
return my_print(*args)
def my_print(x, y):
print(x + y)
if __name__ == "__main__":
x = [1, 2, 3, 4, 5]
y = [1, 1, 1, 1, 1]
zip_args = list(zip(x, y))
pool = Pool()
pool.map(multi_wrapper, zip_args)
pool.close()
pool.join()
2.3 使用pathos提供的多进程库
from pathos.multiprocessing import ProcessingPool as newPool
if __name__ == '__main__':
x = [1, 2, 3, 4, 5]
y = [1, 1, 1, 1, 1]
pool = newPool()
pool.map(my_print, x, y)
pool.close()
pool.join()
在该库的map函数下,可以看到,它允许多参数输入,其实也就是使用了可变参数:
def map(self, f, *args, **kwds):
AbstractWorkerPool._AbstractWorkerPool__map(self, f, *args, **kwds)
_pool = self._serve()
return _pool.map(star(f), zip(*args))
2.4 使用starmap函数
if __name__ == '__main__':
x = [1, 2, 3, 4, 5]
y = [1, 1, 1, 1, 1]
zip_args = list(zip(x, y))
pool = Pool()
pool.starmap(my_print, zip_args)
pool.close()
pool.join()
其实在以上4种实现方法中 ,第1种方法的限制较多,如果该函数的其它参数都在变化的话,那么它就不能很好地工作,而剩下的方法从体验上来讲是依次递增的,它们都可以接受任意多参数的输入,但是第2种需要额外写一个函数,扣分;第3种方法需要额外安装pathos包,扣分;而最后一种方法不需要任何额外不择就可以完成,所以,推荐大家选择第4种方法!
————————————————
版权声明:本文为CSDN博主「Jayce~」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_15969343/article/details/84672527
问题引出许多时候,我们对程序的速度都是有要求的,速度自然是越快越好。对于Python的话,一般都是使用multiprocessing这个库来实现程序的多进程化,例如:我们有一个函数my_print,它的作用是打印我们的输入:def my_print(x): print(x)但是我们嫌它的速度太慢了,因此我们要将这个程序多进程化:from multiprocessing im...
这将自动将该实用程序安装到您的PATH中。
usage: kvminstall [-h] [-c CLONE] [-i IMAGE] [-v VCPUS] [-r RAM] [-d DISK]
[-D DOMAIN] [-N NETWORK] [--type TYPE]
[--variant VARIANT] [-f CONFIGFILE]
positional arguments:
$ python online_lda.py -h
usage: online_lda.py [-h] [-o OUTDIR] [-b BATCHSIZE] [-d NUM_DOCS]
[-k NUM_TOPICS] [-t TAU_0] [-l KAPPA] [-m MODEL_OUT_FREQ]
dataset vocab_file
positional arguments:
dataset Input dataset filename.
vocab_file Vocabulary filename.
optional arguments:
sudo dnf install tldr
usage: tldr [-u] [-p PLATFORM] [-s SOURCE] [-c] [-r] [-L LANGUAGE] command
Python command line client for tldr
positional arguments:
command command to lookup
optional arguments:
-h, --help show this help message and exit
-v, --ver
作为独立的应用程序
usage: python-lua [-h] [--show-ast] [--only-lua-init] [--no-lua-init] [IF]
Python to lua translator.
positional arguments:
IF A python script filename to translate it.
optional arguments:
-h, --help show this help message and exit
--show-ast Print python ast tree before code.
--only-lua-init Print onl
二、问题分析
TestMethod是自定义的类,test_01_getAuth为该类的实例化方法(self:表示实例化类后的地址ID),类未实例化直接调用TestMethod.test_01_getAuth(),导致报错
三、解决方案
1.自定义类加括号,直接调用方法
if __name__ == '__main_
1、根据gensim3.8.3的源码,log_perplexity()输出的是perwordbound,而perwordbound计算步骤如下:
先调用 bound() ,通过一个chunk的语料W⃗\vec{W}W计算整个语料库的对数似然值logp(W⃗)logp(\vec{W})logp(W)的下界,即Eq[logp(W⃗)]−Eq[logq(W⃗)]Eq[logp(\vec{W})]-Eq[logq(\vec{W})]Eq[logp(W)]−Eq[logq(W)] 。
然后用算出的bound除以整个
刚开始在借鉴别人方法的时候没有敲@classmethod这个修饰符,一直从外部找解决方法,重新装python还有库都没有用,最后加上修饰符就跑通了。百度到了这个修饰符的作用:
1、@classmethod声明一个类方法,而对于平常我们见到的则叫做实例方法。
2. 报错原因
从报错代码能够看出,我这里涉及了两个类,我用A类和B类来进行描述。
A类:一个方法类,其中报错的 get_element() 就是这个类下的一个方法。在该类我没有实例化
B类:在 get_element() 中调用了A的 get_element() 方法。只在开头 from A import A.
因为A类没有实例化,B类我也没有进行实例化,只是直接引入了这个类。...
在进行程序编写过程中,出现了一个报错:missing 1 required positional argument: 'self',一看这个报错信息就懵逼了,我所调用的函数没有哪个是需要self的参数的啊!
最后发现,是自己编写程序时太急,在调用某个类里面的方法之前,没有对类进行实例化,见下图错误示例:
result = Test.func1()
如果按...
您只需要注意: : 不使用任何递归神经网络对句子进行编码。 相反,他们利用位置编码,然后注意。 在本文中,thay使用不同频率的正弦和余弦函数:
P E(pos,2i) = sin(pos/10000**(2i/dmodel))
P E(pos,2i+1) = cos(pos/10000**(2i/dmodel))
其中pos是位置,而i是尺寸。 即,位置编码的每个维度对应于正弦曲线。 波长形成从2π到10000·2π的几何级数。 我们选择此函数是因为我们假设它会允许模型轻松学习相对位置的参加,因为对于任何固定的偏移量k,P Epos + k都可以表示为P Epos的线性函数。
coder.py提供了一个有助于对位置/时间分量以及单词嵌入进行编码的类。 位置和单词嵌入都可以训练。 此类的编码输出必须通过自我关注层才能获得更好的结果。
import torch
OptimizedLatent Dirichlet Allocation (LDA) <https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation>in Python.
For a faster implementation of LDA (parallelized for multicore machines), see ...

