


retinaface - 人脸检测网络解析


paper: https:// arxiv.org/pdf/1905.0064 1.pdf
github: https:// github.com/deepinsight/ insightface/tree/master/RetinaFace
Retinaface是来自insightFace的又一力作,基于one-stage的人脸检测网络。
一、主干特征提取网络介绍( MobilenetV1-0.25为例 )
官方提供两种主干特征提取网络:MobilenetV1-0.25和Resnet,本文以MobilenetV1-0.25为例。MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是深度可分离卷积(depthwise separable convolution),具体请看 轻量级网络-Mobilenet系列(v1,v2,v3) - 知乎 (zhihu.com) 。
(1)mobilenetV1-1的网络结构
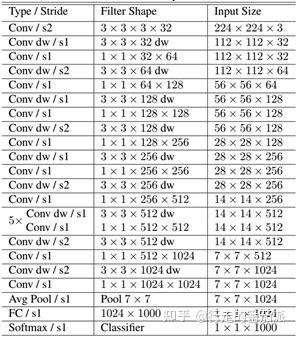
(2)mobilenetV1-0.25的网络结构
mobilenetV1-0.25是mobilenetV1-1通道数压缩为原来1/4的网络,网络结构如下:

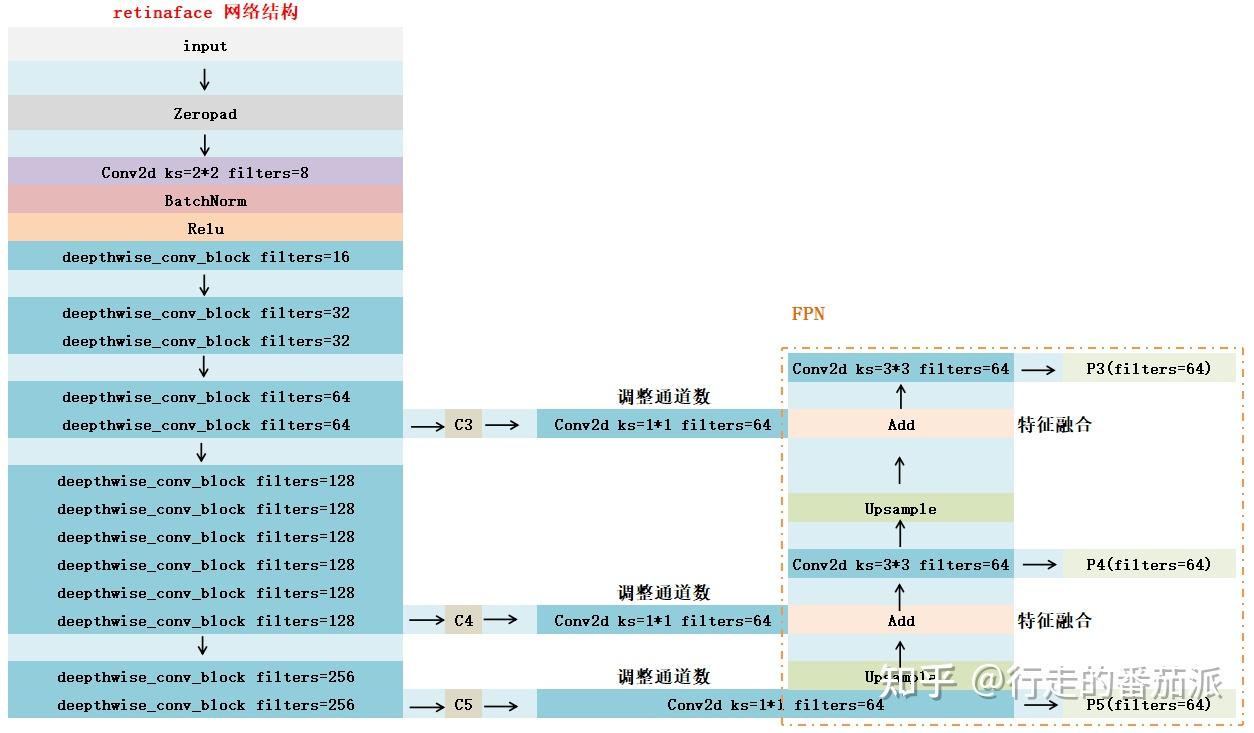
取最后三个feature map作为输出,即 C3、C4、C5 。

二、FPN特征金字塔
如下图,首先利用1x1卷积对三个有效特征层进行通道数的调整,调整后利用Upsample和Add进行上采样的特征融合,如下图。
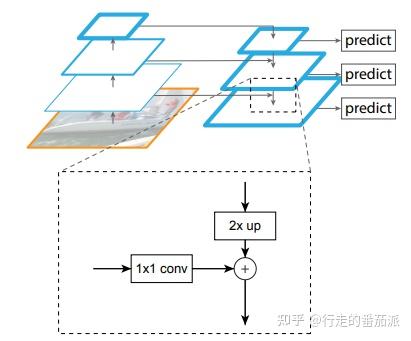
Retinaface使用了FPN的结构,如上图,对MobilenetV1-0.25最后三个有效特征层(feature map)进行FPN操作,得到P3、P4、P5。(特征金字塔网络FPN介绍: 什么是FPN(Feature Pyramid Networks--特征金字塔)? - 知乎 (zhihu.com) )
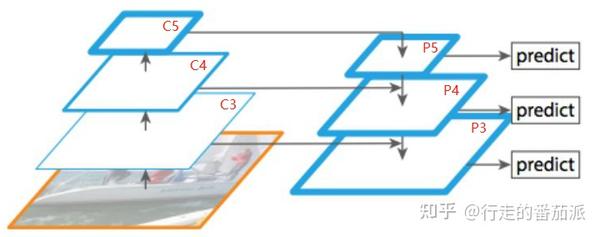

加入了FPN之后的网络结构如下:
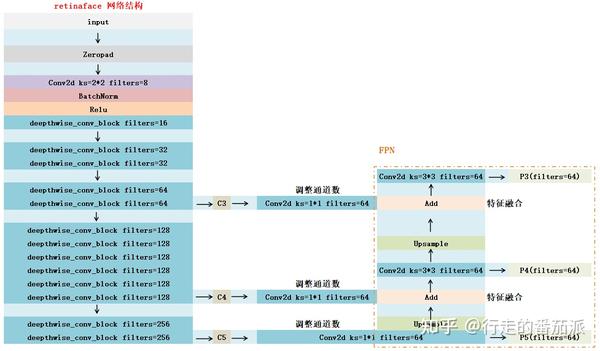
三、SSH(特征提取)
如上图,经FPN得到P3、P4、P5三个有效特征层,Retinaface为了进一步加强特征提取,使用了SSH模块加强感受野( 什么是感受野 ?, 什么是SSH ?)。
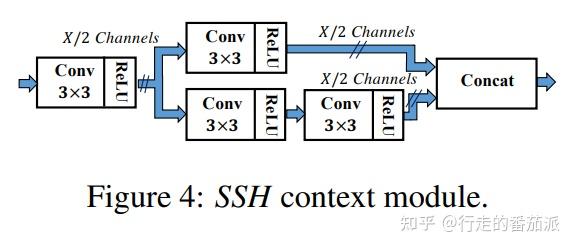
SSH通过在特征图中引入上下文信息来提高小人脸的检测,下图为SSH中的上下文模块。

retinaface中SSH的结构如如下所示:


SSH的思想非常简单,使用了三个并行结构,利用3x3卷积的堆叠代替5x5与7x7卷积的效果:左边的是3x3卷积,中间利用两次3x3卷积代替5x5卷积,右边利用三次3x3卷积代替7x7卷积。
加入了SSH之后的网络结构如下,经过SSH后,得到 S3、S4、S5 三个特征层:
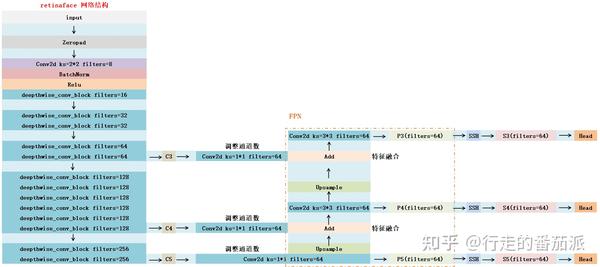

四、Head
经上述特征提取操作获得 S3、S4、S5 三个有效特征层,接下来需要通过这三个有效特征层来获得预测结果。
retinaface的预测结果分为三个:分类预测、人脸框预测、人脸关键点预测;
(1)分类预测(face or not)
用于 判断先验框内部是否包含物体(二分类) ,Retinaface官方使用的是softmax进行判断(也可以利用一个1x1的卷积,将SSH的通道数调整成num_anchors x 2,用于代表每个先验框内部包含人脸的概率) 。
(2)人脸框的回归(bbox)
用于 对先验框进行调整从而获得预测框,需要四个参数, 前两个用于对先验框的中心进行调整,后两个用于对先验框的宽高进行调整(可以利用一个1x1的卷积,将SSH的通道数调整成num_anchors x 4,用于代表每个先验框的调整参数)
(3)人脸关键点的回归(landmarks)
用于 对先验框进行调整,从而获得人脸关键点坐标,需要十个参数, 每一个人脸关键点需要两个调整参数,对先验框中心的x、y轴进行调整获得关键点坐标,一共有五个人脸关键点(可以利用一个1x1的卷积,将SSH的通道数调整成num_anchors x 10(num_anchors x 5 x 2),用于代表每个先验框的每个人脸关键点的调整).
若网络输入尺寸为 3*640*640 ,经上述处理后得到: S3、S4、S5 的 shape 分别为: (80, 80, 64) , (40, 40, 64) , (20, 20, 64) 。
经过【Head】完成调整、判断之后,还需要进行非极大值抑制(即筛选出一定区域内属于同一种类得分最大的框)。