(较多借鉴来自师傅,仅学习记录而已,勿喷)
/*创建数据集m*/
data m;
set sashelp.class;
run;
/*1 使用proc delete 删除m*/
proc delete data=m;
用这个删除特定数据集挺好的
quit;
/*2 使用proc datasets*/
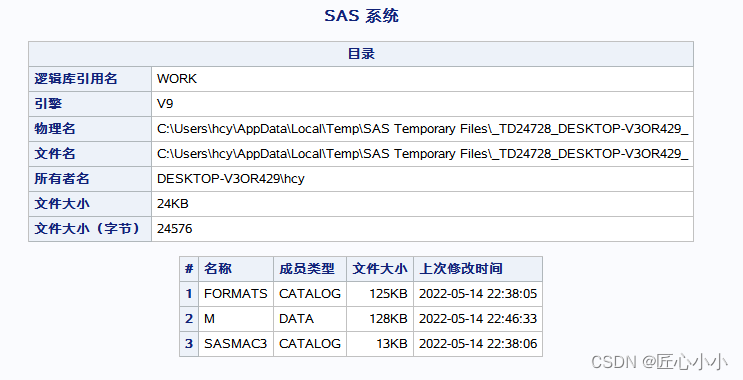
/*2.1 无nolist,此时结果查看器将会输出以下内容*/
proc datasets lib=work;
delete m;
run;
/*2.2有nolist*/
proc datasets lib=work nolist;
delete m;
run;
/*2.3 带memtype,log与2一致*/
proc datasets lib=work nolist;
delete m
/memtype=data
;
这个的日志与2.2一样
run;
/*
重点来了:
proc datasets程序常用于项目程序开头,用于清除临时逻辑库中所有数据集。配合dm语句清理log记录和输出*/
proc datasets lib=work
kill memtype=data nolist;
quit;
dm "clear log; clear output";
这个太常用了 如果你嫌日志太多了,可以在搜索框直接输出clear,一下子就把日志清除了
/*这个我抄别人程序用在最后了,我感觉可以前后都用下,前面可以清除掉之前work中的数据集,后边可以数据生成的数据集*/
/*1)dm语句用于清屏,清理log记录
2)memtype表示操作对象的类型,常为data,catalog等,猜测是上图中的成员类型,后期多理解
3)nolist表示不在SAS的结果查看器中显示,如上图所示
4)kill 表示删除全部数据集,delete语句用于删除特定数据集,save语句用于保留特定数据集,
目前仅用kill消灭所有了
*/
/*3 使用proc sql*/
proc sql ;/*proc sql 后面可以带noprint也可以不带,我试了效果一样*/
drop table m;
quit;
由于在Excel
中
进行数据挖掘的结果存在不确定性(参见《解读数据挖掘之关联规则》一文的最后一段),虽然它具有操作简单的特点,但是为了保险起见,建议还是使用更专业的统计软件来进行数据挖掘。
SAS
系统被誉为国际上的标准软件系统,本文将详细介绍如何在
SAS
/EM模块
中
进行关联规则数据挖掘,使用的软件版本是
SAS
9.1.3下的EnterpriseMiner4.3:从
SAS
顶端的【解决方案(S)】菜单下调出企业数据挖掘(也可以通过在命令行输入miner):
SAS
/EM的初始界面如下:接下来,将数据挖掘外接程序示例
数据集
中
的Associate表导入
SAS
逻辑库。先将xlsx文件另存为xls文件,再双击SA
通过本次实验了解了
SAS
系统的主要窗口及其功能熟悉了
SAS
软件的基本操作了解了
SAS
程序的组成及
SAS
程序规则掌握了新库标记的建立及编程建立永久的和临时的
SAS
数据集
的方法掌握了
SAS
数据集
的常用整理方法。
/*****
删除
sas
work逻辑库
中
的所有宏*****/proc catalog catalog=work.
sas
macr force kill;run; quit;/*****
删除
sas
work逻辑库
中
的
数据集
*****/proc datasets library=work nolist nodetails kill;run; quit;...
/** 读入数据,生成
SAS
数据集
mydata.Credit **/
proc import datafile="E:\data\ch2_credit.csv"
out=mydata.Credit dbms=DLM;
/*将数据从Credit.csv文件读入,存储在
SAS
逻辑...
sas
s的compact 编译排版格式,去掉缓存文件和map文件
sas
s --watch style.scss:output.css --style compact --sourcemap=none --no-cache
从数据表
中
删除
数据内容需要使用DELETE语句,它需要WHERE语句来配合它来指定我们究竟应该
删除
哪些数据内容。
语法规则为:
DELETE FROM 表名 WHERE 条件语句; 。
我们可以指定
删除
某一行的数据内容,当然,我们还可以指定
删除
很多行的数据内容,区别就在于条件语句。那么在接下来的例子里,我们来看看很多行内容是怎么
删除
的。
我们现在有一张表Mall_products2,内容如下图所示:
现在我们想把包含Span和Italy的这两行数据.
经过一系列的程序,work临时文件夹里有了很多过程
数据集
比如a1,a2,a3……;感觉看着不爽想删掉,怎么办?
你可以这么做:
proc delete data=a1 a2 a3;run;
如果你想精简程序为:
proc delete data=a1-a3;run;
那么很遗憾,
sas
出错了,因为proc delete 读不懂a1-a3;
问题起源:在真正的数据分析开始之前,需要确定如何从原始
数据集
中
提取有效信息,而通常我们拿到的数据
中
,并非所有点位/变量都包含信息,那么,快速
删除
空白列,而保留下有信息的列,就会大大降低工作量,避免投入不必要的时间。案例:data_08_1
中
存储的是手术相关信息,共包含2479个变量,总观测有19262条,有很多变量是整列都为空的,为从
中
找到合适的信息用于分析,拟
删除
空白列,留下有数据的列...
SET
数据集
1(
数据集
选项)
数据集
2(
数据集
选项)…;
SET语句作用是将若干个
数据集
依次纵向连接,并存放语法建立的
数据集
中
。如果SET4语句后面只有一个
数据集
,此时相当于复制作用,即将SET指定的
数据集
中
的数据复制到DATA语句建立的
数据集
中
。
数据集
选项最常用的2种:
SET
数据集
1...

