|
|
|


使用Python数据分析进行标准化和归一化的意义是什么,以及有哪些操作方法?
关注者
0
被浏览
4,763
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

Mr数据杨

使用Python数据分析进行标准化和归一化的意义在于,它们可以将不同的数据特征统一到同一个尺度上,从而消除特征值之间的量级差异,提高模型的准确性和鲁棒性。
特征缩放是机器学习的预处理之一,标准化和归一化就是典型的例子。
- 标准化是一种均值为 0,方差为 1 的缩放技术。
- 归一化是最小值为 0,最大值为 1 的 0-1 缩放技术。
这种缩放是有效的,当单位不同或值因特征量而异时,更容易理解各个维度之间的关系。
在Python中,可以通过一些操作方法来进行标准化和归一化。其中一些常见的方法包括:
- 标准化(Standardization):这种方法是将数据的值减去它的均值,再除以它的标准差,得到一个标准正态分布(即均值为0,标准差为1)。在Python中,可以使用sklearn库中的StandardScaler类来实现数据标准化。
- 归一化(Normalization):这种方法是将数据的值减去它的最小值,再除以它的最大值和最小值的差值,得到一个[0,1]之间的数值。在Python中,可以使用sklearn库中的MinMaxScaler类来实现数据归一化。
需要注意的是,标准化和归一化是两种不同的数据预处理方法,适用于不同的情况。标准化通常用于处理连续性数据,例如定量数据,并且能够保留数据的分布特征,例如峰值和偏度。而归一化通常用于处理离散性数据,例如定类数据,并且能够将数据的值缩放到一个固定的区间,例如[0,1]。因此,在选择进行标准化或归一化时,需要根据实际情况和需求来进行选择。
此外,在进行标准化和归一化时,还需要注意数据中缺失值的处理。通常情况下,如果数据中存在缺失值,那么在计算均值、标准差、最大值或最小值时,需要将缺失值排除在外,以避免影响数据预处理的结果。
标准化和归一化的意义
在学习机器学习或深度学习中经常可能已经看过下面的神经网络图。
W 表示与输入值相乘的权重。 在这个图中,输入了两个特征值,通过将特征值乘以权重来创建三个中间层。
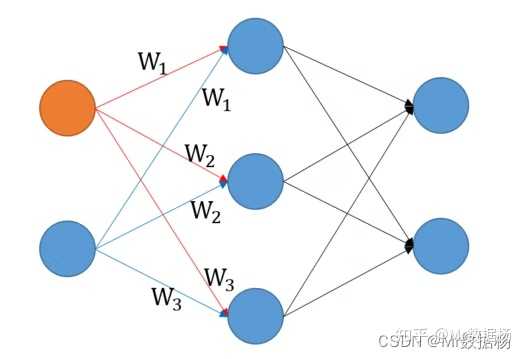
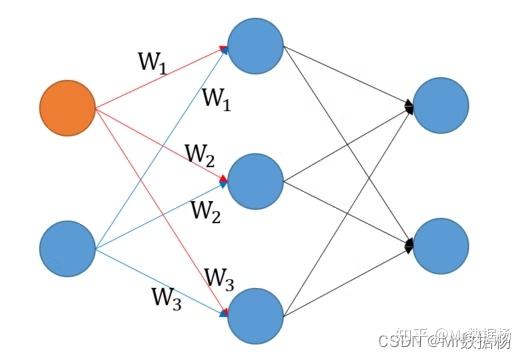
假设输入特征是 年龄 和 身高 ,试图从这些特征中构建模型。假设现在有 5 组数据进行计算,假设中间层是简单地通过将输入乘以权重来创建的。
年龄 = {10,15,20,25,30}
身高 = {130,165,170,173,170}1.假设年龄和身高权重相等
10 × 1 + 130 × 1 = 140
15 × 1 + 165 × 1 = 180
20 × 1 + 170 × 1 = 190
25 × 1 + 173 × 1 = 198
30 x 1 + 170 x 1 = 2002.假设身高比年龄特征更重要
10 × 1 + 130 × 2 = 270
15 × 1 + 165 × 2 = 345
20 × 1 + 170 × 2 = 360
25 × 1 + 173 × 2 = 371
30 × 1 + 170 × 1 = 3703.假设年龄比身高特征更重要
10 × 2 + 130 × 1 = 150
15 × 2 + 165 × 1 = 195
20 × 2 + 170 × 1 = 210
25 × 2 + 173 × 1 = 223
30 × 2 + 170 × 1 = 230比较 2(强调身高) 和 3(强调年龄) 的的结果, 2(强调身高) 的结果数值更大。 3(强调年龄) 的结果数值也很大,但和 1(强调身高和年龄) 的结果相差不大。
如果使用现有数据进行计算,则结果是 2(强调身高) 对计算结果的影响更大,而与体重无关。
如果想猜的结果高度依赖身高,模型构建可能会更好,但如果高度依赖年龄,结果可能会被身高拖累,模型可能构建的不是那么理想。
这是因为即使身高的可能值大致是 0 到 100,身高的可能值也在 50 到 200 左右,并且最大值和最小值是不同的。
因此,标准化或标准化对于在同一水平上对待年龄和身高是必要的。
是否有任何负面影响?
机器学习的输入不是数据值本身,因为它被称为 特征值 ,通过捕获特征来学习的。因此如果数据的特征即使经过归一化和标准化后也没有变化,就没有问题。
在这个例子中身高被归一化为 200,最大值为 200,但如果 1000 的值作为异常值混入会发生什么?因为 1000 是异常值,所有其他的值都除以1000,所以值变得极小,特征不太好出现。
但是在图像处理中,像素的RGB值(0到255)是一个特征值,但它不会取1000 等异常值,所以如果明确确定了这样的最小值和最大值用易于计算的归一化。
所以基本上都进行了标准化,但是如果值的范围很明确,就进行了标准化。
当上述年龄和身高被归一化和标准化后。
归一化(通过将每个数据除以 100(年龄)和 200(身高)来计算)。
Age = {0.1, 0.15, 0.2, 0.25, 0.3}
Height = {0.65, 0.825, 0.85, 0.865, 0.85}标准化。
年龄 = {-1.264911064, -0.632455532, 0, 0.632455532, 1.264911064}
身高 = {-1.76566624, 0.189976747, 0.469354317, 0.636980859, 0.469354317}标准化
数据标准化
对原始数据进行处理,少不了的就是 standardization (或 Z-score normalization ),要求 均值 μ=0 和 标准差 σ=1 。
$z = \frac{x - u}{s}$
scikit-learn 实现数据标准化
from sklearn.preprocessing import StandardScaler
import numpy as np
sc = StandardScaler()
data = np.random.randint(10, size=(2,5))
X_std = sc.fit_transform(data)
print("均值", X_std.mean())
print("标准差", X_std.std())
均值 0.0
标准差 1.0归一化
数据归一化
Min-Max scaling (或 normalization ),也就是常说的 0-1 归一化)。处理后的所有特征的值都会被压缩到 0到1 区间上,这样做还可以抑制离群值对结果的影响。
$x = \frac{x - \min{\left( x \right)}}{\max{\left( x \right)} - \min{\left( x \right)}}$
scikit-learn 实现数据归一化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler([0,1]) # 0~1の归一化
X_MinMaxScaler = scaler.fit_transform(data)
print(X_MinMaxScaler)
[[0. 0. 0. 1. 1.]
[0. 1. 1. 0. 0.]]红酒数据集的操作
import pandas as pd
import numpy as np
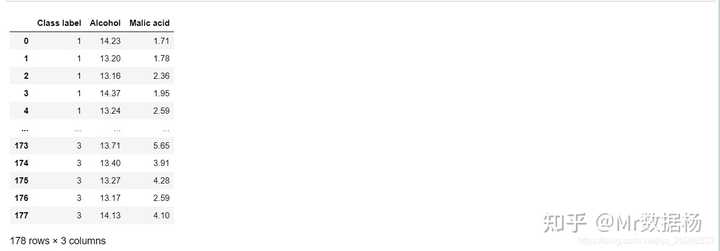
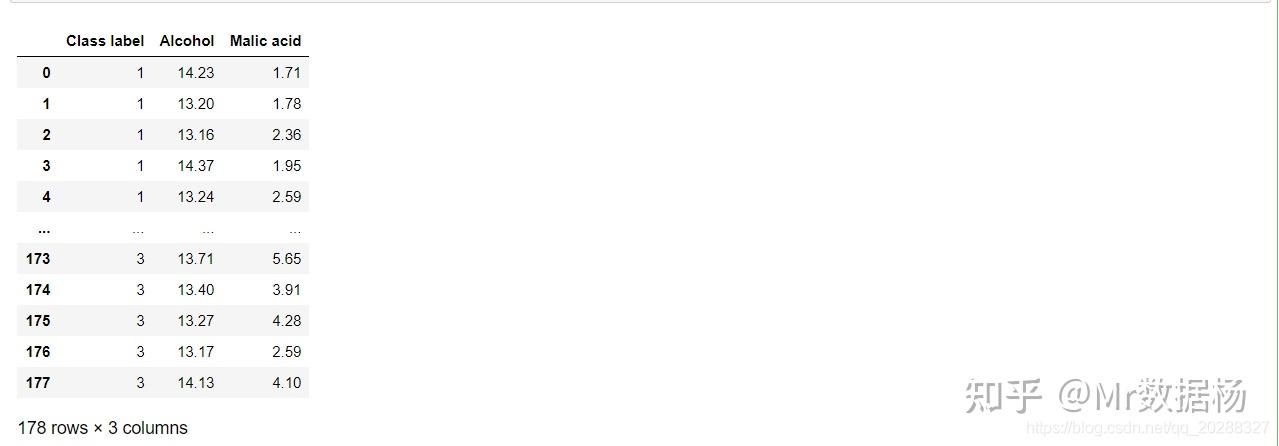
df = pd.read_excel('data/wine_data.xlsx') #葡萄酒数据集
df.head()


# 选取指定字段
# 在数据中,Alcohol和Malic acid 衡量的标准应该是不同的,特征之间数值差异较大
df
[['Class label', 'Alcohol', 'Malic acid']]
# 标准化和归一化实现
from sklearn import preprocessing
std_scale = preprocessing.StandardScaler().fit(df[['Alcohol', 'Malic acid']])
df_std = std_scale.transform(df[['Alcohol', 'Malic acid']])
minmax_scale = preprocessing.MinMaxScaler().fit(df[['Alcohol', 'Malic acid']])
df_minmax = minmax_scale.transform(df[['Alcohol', 'Malic acid']])
print('标准化后:Alcohol={:.2f}, Malic acid={:.2f}'.format(df_std[:,0].mean(), df_std[:,1].mean()))
print('\n标准化后的标准差:Alcohol={:.2f}, Malic acid={:.2f}'.format(df_std[:,0].std(), df_std[:,1].std()))
标准化后:Alcohol=-0.00, Malic acid=-0.00
标准化后的标准差:Alcohol=1.00, Malic acid=1.00
print('归一化后的最小值:Alcohol={:.2f}, Malic acid={:.2f}'
.format(df_minmax[:,0].min(), df_minmax[:,1].min()))
print('\n归一化后的最大值:Alcohol={:.2f}, Malic acid={:.2f}'
.format(df_minmax[:,0].max(), df_minmax[:,1].max()))
归一化后的最小值:Alcohol=0.00, Malic acid=0.00
归一化后的最大值:Alcohol=1.00, Malic acid=1.00
# 数据可视化
from matplotlib import pyplot as plt
def plot():
plt.figure(figsize=(8,6))
# 绿色表示原始数据
plt.scatter(df['Alcohol'], df['Malic acid'], color='green', label='input scale', alpha=0.5)
# 红色表示标准化后数据
plt.scatter(df_std[:,0], df_std[:,1], color='red', label='Standardized [$N (\mu=0, \; \sigma=1)$]', alpha=0.3)
# 蓝色表示归一化后数据
plt.scatter(df_minmax[:,0], df_minmax[:,1], color='blue', label='min-max scaled [min=0, max=1]', alpha=0.3)
plt.title('Alcohol and Malic Acid content of the wine dataset')
plt.xlabel('Alcohol')
plt.ylabel('Malic Acid')
plt.legend(loc='upper left')
plt.grid()
plt.tight_layout()
plot()
plt.show()
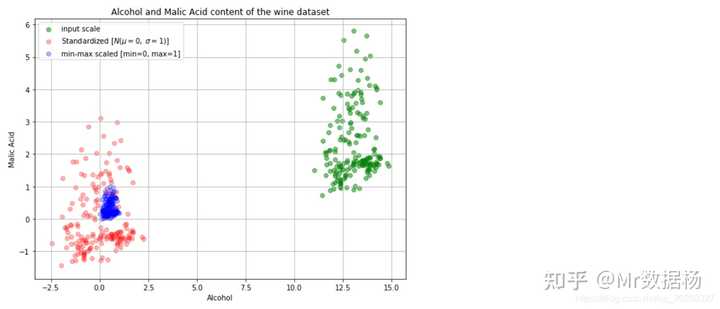
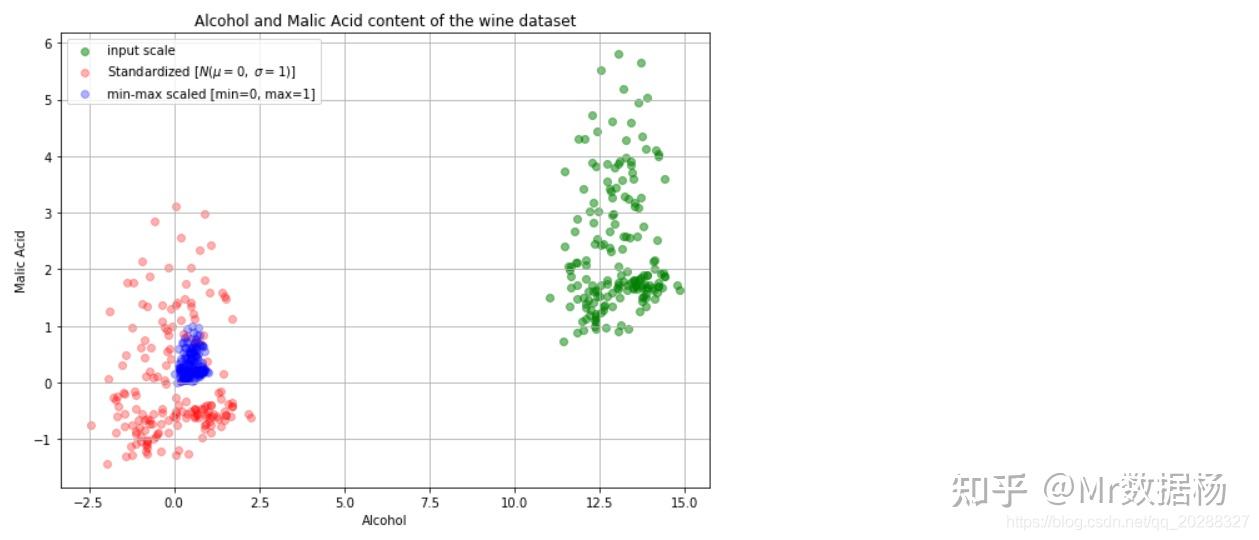
# 我们将原始的和变换后都放到了同一个图上,观察下结果吧!接下来我们再看看数据是否被打乱了呢?
fig, ax = plt.subplots(3, figsize=(6,14))
for a,d,l in zip(range(len(ax)),
(df[['Alcohol', 'Malic acid']].values, df_std, df_minmax),
('Input scale',
'Standardized [$N (\mu=0, \; \sigma=1)$]',
'min-max scaled [min=0, max=1]')
for i,c in zip(range(1,4), ('red', 'blue', 'green')):
ax[a].scatter(d[df['Class label'].values == i, 0],
d[df['Class label'].values == i, 1],
alpha=0.5,
color=c,
label='Class %s' %i
ax[a].set_title(l)
ax[a].set_xlabel('Alcohol')
ax[a].set_ylabel('Malic Acid')
ax[a].legend(loc='upper left')
ax[a].grid()
plt.tight_layout()
plt.show()

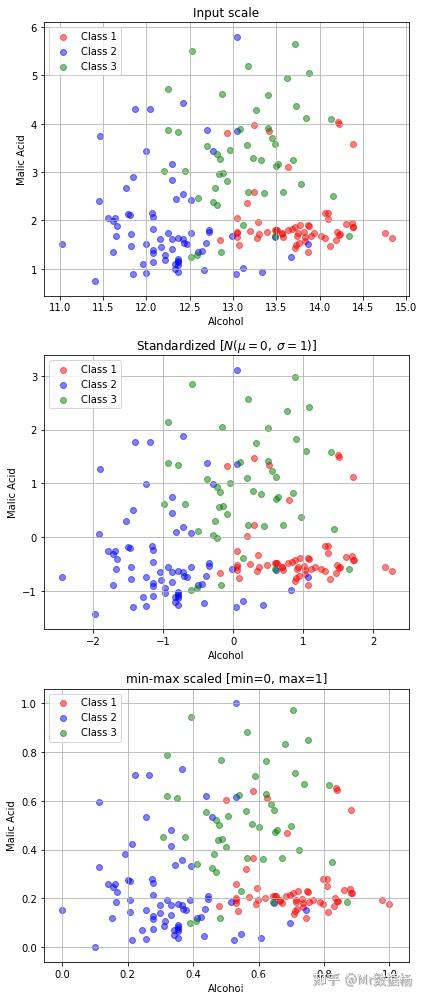
在机器学习中,如果我们对训练集做了上述处理,那么同样的对测试集也必须要经过相同的处理。
std_scale = preprocessing.StandardScaler().fit(X_train)
X_train = std_scale.transform(X_train)
X_test = std_scale.transform(X_test)标准化处理对PCA主成分分析的影响
主成分分析(PCA)和一个非常有用的套路,接下来,咱们来看看数据经过标准化处理和未经标准化处理后使用 PCA 的效果。
import pandas as pd
df = pd.read_excel('data/wine_data.xlsx') #葡萄酒数据集
df.head()
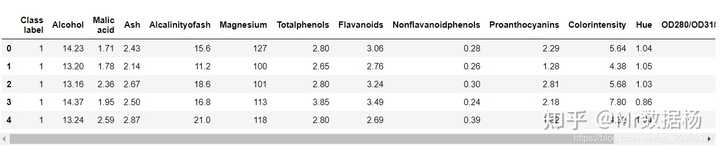
将数据集划分为单独的训练和测试数据集,将随机将葡萄酒数据集分为训练数据集和测试数据集,其中训练数据集包含70%的样本,测试数据集包含30%的样本。
from sklearn.model_selection import train_test_split
X_wine = df.values[:,1:]
y_wine = df.values[:,0]
X_train, X_test, y_train, y_test = train_test_split(X_wine, y_wine,
test_size=0.30, random_state=12345)
# 标准化处理数据
from sklearn import preprocessing
std_scale = preprocessing.StandardScaler().fit(X_train)
X_train_std = std_scale.transform(X_train)
X_test_std = std_scale.transform(X_test)
# 使用PCA进行降维
# 在标准化和非标准化数据集上执行PCA,将数据集转换成二维特征子空间。
from sklearn.decomposition import PCA
# 非标准化数据
pca = PCA(n_components=2).fit(X_train)
X_train = pca.transform(X_train)
X_test = pca.transform(X_test)
# 标准化数据
pca_std = PCA(n_components=2).fit(X_train_std)
X_train_std = pca_std.transform(X_train_std)
X_test_std = pca_std.transform(X_test_std)
from matplotlib import pyplot as plt
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(10,4))
for l,c,m in zip(range(1,4), ('blue', 'red', 'green'), ('^', 's', 'o')):
ax1.scatter(X_train[y_train==l, 0], X_train[y_train==l, 1],
color=c,
label='class %s' %l,
alpha=0.5,
marker=m
for l,c,m in zip(range(1,4), ('blue', 'red', 'green'), ('^', 's', 'o')):
ax2.scatter(X_train_std[y_train==l, 0], X_train_std[y_train==l, 1],
color=c,
label='class %s' %l,
alpha=0.5,
marker=m
ax1.set_title('Transformed NON-standardized training dataset after PCA')
ax2.set_title('Transformed standardized training dataset after PCA')
for ax in (ax1, ax2):
ax.set_xlabel('1st principal component')