


推荐一些优秀的开源Java爬虫项目


本篇文章来自我的回答: GitHub 上有哪些优秀的 Java 爬虫项目? 但是在此回答上做了一些修改以及增加了一些项目,这些项目来自github和开源中国,希望这些开源Java爬虫项目对大家有帮助。阅读源码可以帮你得到一个质的提升。
1、Gecco
github地址: xtuhcy/gecco
Gecco是一款用java语言开发的轻量化的易用的网络爬虫。整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器就能很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对修改关闭、对扩展开放。
2、WebCollector
github地址: CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
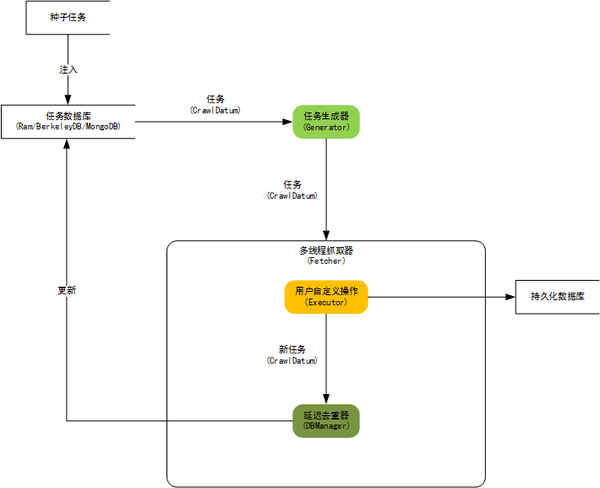

3、Spiderman
码云地址: l-weiwei/Spiderman2 - 码云 - 开源中国
使用案例: 展现垂直爬虫的能力 - 像风一样自由
Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。
4、WebMagic
码云地址: flashsword20/webmagic - 码云 - 开源中国
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。

5、Heritrix
github地址: internetarchive/heritrix3
Heritrix是一个开源,可扩展的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格按照robots.txt文件的排除指示和META robots标签。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
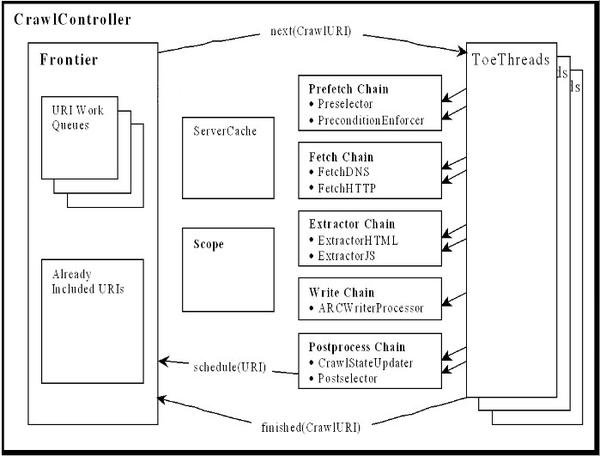

6、crawler4j
github地址: yasserg/crawler4j · GitHub
crawler4j是Java实现的开源网络爬虫。提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫。
7、Nutch
github地址: apache/nutch
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
在Nutch的进化过程中,产生了Hadoop、Tika、Gora和Crawler Commons四个Java开源项目。如今这四个项目都发展迅速,极其火爆,尤其是Hadoop,其已成为大规模数据处理的事实上的标准。Tika使用多种现有的开源内容解析项目来实现从多种格式的文件中提取元数据和结构化文本,Gora支持把大数据持久化到多种存储实现,Crawler Commons是一个通用的网络爬虫组件。
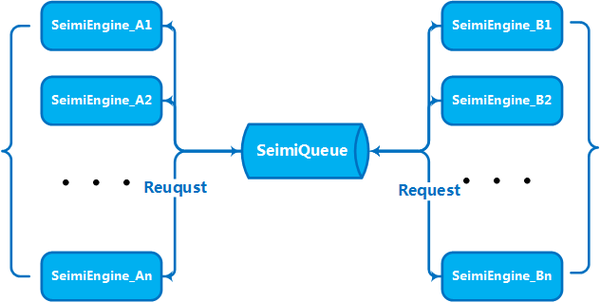
8、SeimiCrawler
github地址: zhegexiaohuozi/SeimiCrawler
SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门槛,以及提升开发爬虫系统的开发效率。在SeimiCrawler的世界里,绝大多数人只需关心去写抓取的业务逻辑就够了,其余的Seimi帮你搞定。设计思想上SeimiCrawler受Python的爬虫框架Scrapy启发,同时融合了Java语言本身特点与Spring的特性,并希望在国内更方便且普遍的使用更有效率的XPath解析HTML,所以SeimiCrawler默认的HTML解析器是JsoupXpath(独立扩展项目,非jsoup自带),默认解析提取HTML数据工作均使用XPath来完成(当然,数据处理亦可以自行选择其他解析器)。并结合SeimiAgent彻底完美解决复杂动态页面渲染抓取问题。
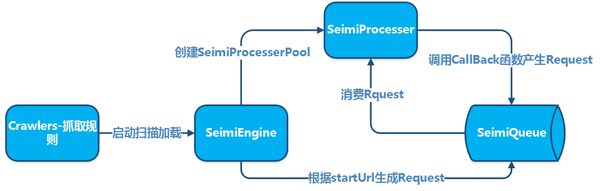

9、Jsoup
github地址: jhy/jsoup
中文指南: jsoup开发指南,jsoup中文文档
jsoup 是一款Java 的HTML解析器,可直接解析URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
