"ResultSet object has no attribute '%s'. You're probably treating a list of elements like a single e
最新推荐文章于 2022-12-07 16:19:59 发布
Nurbiya_K
于 2020-03-16 01:02:12 发布
"ResultSet object has no attribute ‘%s’. You’re probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?" % key
AttributeError: ResultSet object has no attribute ‘text’. You’re probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?
查看是否该使用find()方法的地方使用了find_all()方法,当不是一个单独的对象的时候不能使用.text方法
我错误的代码:
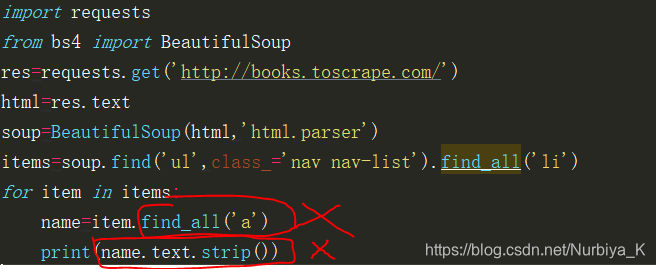
最后一行报错了,其实问题在倒数第二行,这里的标签‘a’是一个单独的对象,但我使用了find_all()方法,这样使用是错误的,应改成find()
正确的代码:
import requests
from bs4 import BeautifulSoup
res=requests.get('http://books.toscrape.com/')
html=res.text
soup=BeautifulSoup(html,'html.parser')
items=soup.find('ul',class_='nav nav-list').find_all('li')
for item in items:
name=item.find('a')
print(name.text.strip())
"ResultSet object has no attribute '%s'. You're probably treating a list of elements like a single e
"ResultSet object has no attribute ‘%s’. You’re probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?" % keyAttributeError: ResultSet obje...
import requests
from bs4 import BeautifulSoup
res = requests.get('http://www.weather.com.cn/weather/101190401.shtml')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,"html5lib")
res = requests.get(url_temp)
bs = BeautifulSoup(res.text,'html.parser')
movie_
list
= bs.find_all('ol',class_="grid_view")
**for i in movie_
list
.find_all('li'):**
num = ...
page_
list
= bs4_obj.find_all("div",attrs={"class":"paginator"})
得到的是'bs4.element.
ResultSet
'类型的结果
使用for循环取出结果中的网址时,报错:
for page_ele in page_
list
.find_all("a"):
print(page_ele.attrs.get("hr
Attribute
Error:
ResultSet
object
has no
attribute
‘find_all’. You’re
pro
bably
trea
ting
a
list
of
elements
like a
single
element. Did you call find_all() when you meant to call find()?
Attribute
Error:
ResultSet
object
has no
attribute
'find_all'. You're
pro
import requests
from bs4 import BeautifulSoup
res = requests.get('https://wordpress-edu-3autumn.local
pro
d.oc.forchange.cn/all-about-the-future_04/')
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup(res.text,'html.parser')
items=soup.find_all(class_='comment-
Attribute
Error:
ResultSet
object
has no
attribute
‘find_all’. You’re
pro
bably
trea
ting
a
list
of
elements
like a
single
element. Did you call find_all() when you meant to call find()?
意思是:属性错误:
ResultSet
对象没有属性’find_all’。您可能将一个元素列表当作一个元素来处理。当您打算调用find()时,是否调
soup = get_link_decode(URL)
for link in range(10):
link = soup.find_all("a",text="{}".format(link))
list
_links_docs.append(link)
for link in
list
_links_docs:
lis = link.get("href")
print(lis)
执行这个程序出现
Attribute
Error: ‘set’
object
has no
attribute
‘append’ ##将items={0} 改为 items=[] 问题解决。
items=[]
p_={0}
p_={‘0’,‘1’,‘2’,‘3’,‘15’}
p_end=0
#p_=re.findall(regA,html)
#end1 = time.time()
#print("Page数...
resultset
object
has no
attribute
'find_all'. you're
pro
bably
trea
ting
a
list
of
elements
like a
single
element. did you call find_all() when you meant to call find()?
org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://Master11:9000/user
hhh12300:
UnicodeEncodeError: 'gbk' codec can't encode character '\xe6' in position 1: illegal multibyte seque
ugly__boy:
org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://Master11:9000/user
嘿呀嘿4911:
网页爬取时执行状态成功,但获取不到想要的数据的时候解决方法(Network,XHR,json)
俺也不知道:
MapReduce —— 驱动类 Driver
花开富贵520:


