


左手用R右手Python系列13——字符串处理与正则表达式

学习数据分析,掌握一些灵巧的分析工具可以使得数据清洗效率事半功倍,比如在处理非结构化的文本数据时,如果能够了解一下简单的正则表达式,那么你可以免去大量的冗余代码,效率那叫一个高。
正则表达式是一套微型的袖珍语言,非常强大,依靠一些特定的字母和符号作为匹配模式,灵活组合,可以匹配出任何我们需要的文本信息。
而且它不依赖任何软件平台,没有属于自己的GUI,就像是流动的水一样,可以支持绝大多数主流编程语言。
今天这一篇只给大家简单介绍正则表达式基础,涉及到一些常用的字符及符号含义,及其在R语言和Python中所支持的常用函数。
-------------------------------------------------------
R语言中有两套支持正则表达式的函数,基础函数和stringr包中的字符串处理函数系统。
因为两套系统完成的需求差别不大,我个人用惯了基础函数系统,同时对于一些基础函数无法完成的需求,给出stringr中对应函数的解决方案,最后会给出基础函数和stringr系统函数功能对照表,供大家参考。
R语言的基础函数中,支持正则表达式的函数主要由以下几个
- strsplit() #字符串分割函数
- grep/grepl() #字符串筛选函数
- sub/gsub() #字符串替换函数
- regexpr()/gregexpr() #返回目标字符串起始位置
- substr( )substring() #字符串截取函数
- str_extract() #返回匹配值
以上便是R语言中支持正则表达式的高频应用函数,其中R语言基础函数中缺少一个精确返回匹配模式结果的函数,但是stringr中弥补了这一缺陷,这里仅详解stringr的这一函数,其他函数感兴趣可以查阅源文档。
strsplit()
strsplit() 函数用于字符串分割,可以根据给定分隔符执行分割操作。
myword<-c("fff-888","hh-333","ff-666","ccc-666")
result<-strsplit(myword,"-")

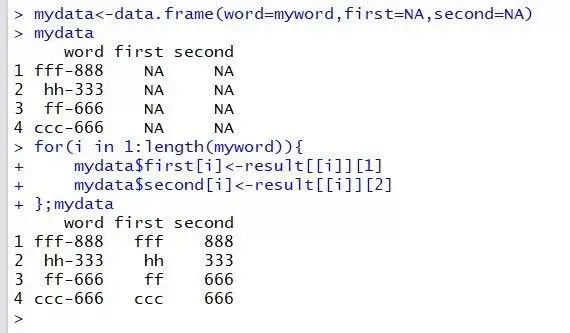
strsplit函数分割之后,输出一个与输入对象等长的列表,如需提取分割后的两列则需要自己构造循环。
mydata<-data.frame(word=myword,first=NA,second=NA)
for(i in 1:length(myword)){
mydata$first[i]<-result[[i]][1]
mydata$second[i]<-result[[i]][2]
};mydata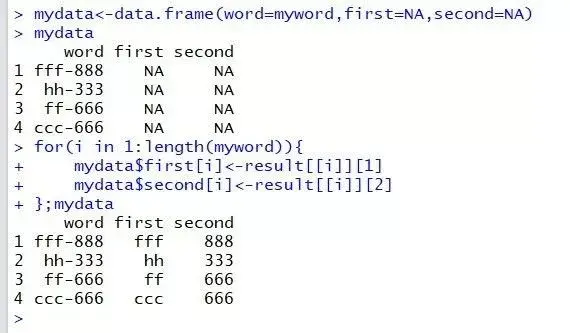
这样就完成了批量字符串的分割与提取。
grep/grepl()
这是一组功能雷同的字符串筛选函数(前者可以输出对应符合条件的记录序号或者真实值,后者直接输出布尔值),何为筛选,就是它只能把包含目标匹配模式的字符串对象筛选出来,但是呢,如果你需要继续提取其中的目标字符串模式,则需进一步使用其他提取函数进行提取,所以实际上他只是过滤掉了那些不包含目标模式的字符串。
myword<-c("fff-888","hh-333","ff-666","ccc-666")
grep("[a-z]{3}",myword,value=FALSE)
grep("[a-z]{3}",myword,value=TRUE)
grepl("[a-z]{3}",myword)

以上需求匹配了含有三个小写英文字母的记录,分别返回了序号、记录、布尔值,这三种方法都可以作为进一步筛选,进行行索引的合法输入条件。
sub/gsub()
这是一组配对的字符串替换函数,用于清除输入字符串中的若干对象或者替换成目标对象。
myword<-c("fff-888","hh-333","ff-666","ccc-666")比如我想把以上字符串向量中的横杠清除掉,则可以写成如下格式:
sub("-","",myword)
[1] "fff888" "hh333" "ff666" "ccc666"
sub("-","_",myword)
[1] "fff_888" "hh_333" "ff_666" "ccc_666"
sub("-","*",myword)
[1] "fff*888" "hh*333" "ff*666" "ccc*666"gsub是针对单个记录有多个匹配模式时,可以执行全部替换。
myword<-c("fff-888-ccc","hh-333","ff-666","ccc-666")
sub("-","",myword)
[1] "fff888-ccc" "hh333" "ff666" "ccc666"
gsub("-","",myword)
[1] "fff888ccc" "hh333" "ff666" "ccc666"
regexpr()/gregexpr()
这是一对返回目标字符串起始位置的匹配函数。
myword<-c("fff-8880000rrrr","hh-333ccccc","ff-666ooooo","ccc-666jjjjj")以上字符串如果想要获知每个对象中的数字部分起始位置,则需要该函数进行位置锁定。
regexpr("\\d{3,}",myword)
[1] 5 4 4 5
attr(,"match.length")
[1] 7 3 3 3
attr(,"useBytes")
[1] TRUE返回值是一个带有属性信息的原子型向量,我们可以看到目标数字在四个记录中的开始位置分别是5,4,4,5,长度分别是7,3,3,3
gregexpr() 与regexpr的关系类比sub与gsub的关系,当记录中出现多个匹配模式时,gregexpr值输出第一个匹配模式的开始位置和长度,而regexpr则会输出所有的匹配模式和长度。
myword<-c("fff-8880000rrrr7777","hh-333ccccc","ff-666ooooo","ccc-666jjjjj")
regexpr("\\d{3,}",myword)
gregexpr("\\d{3,}",myword)

从输出上来看,regexpr忽略了第一个记录中最后的几个数字,但是gregexpr成功捕获并返回其开始位置和长度,但是也导致其输出结果冗长繁琐,一般不常用到。
substr( )/substring()
既然获取到了目标字符串在原始记录中的位置和长度,那么提取它是分分钟的事儿。
接下来就是substr()/substring()大显神通的时候啦。
这两个函数虽然完成的需求相同,但是其作用原理差异很大,substr()一次只能匹配一个字符串,所以对于向量而言需要构造循环,substring()则可以直接赋值其开始向量和结束向量,因而我们只需提前构造好开始于结束位置向量,直接传递参数给它就避免手动循环了。
myword<-c("fff-8880000rrrr","hh-333ccccc","ff-666ooooo","ccc-666jjjjj")
add<-regexpr("\\d{3,}",myword)
[1] 5 4 4 5
attr(,"match.length")
[1] 7 3 3 3
attr(,"useBytes")
[1] TRUE使用substr方法提取:
result<-c()
for(i in 1:length(myword)){
result[i]<-substr(myword[i],add[i],add[i]+attr(add,"match.length")[i]-1)
};result
[1] "8880000" "333" "666" "666" 使用substring方法提取:
substring(myword,as.numeric(add),as.numeric(add)+attr(add,"match.length")-1)
[1] "8880000" "333" "666" "666"结果一模一样,但是效率就差距很大了,很明显substring具有矢量化避免显式循环的优势。
but,你难道不觉得以上两步简直是火坑嘛,不是说正则表达式无敌嘛,肿么会匹配个目标字符串这么困难捏!
下面祭出大杀器!!!
str_extract(myword,"\\d{3,}")
[1] "8880000" "333" "666" "666"
请瞪大你的汪眼仔细看清楚,一个str_extract函数等于regexpr+substr/substring,这等神器你敢信,主要是它的作者也很流弊,大名鼎鼎的哈德利威科姆,没错就是小编经常提到那位神一样存在的ggplot2作者。关于stringr我今天只讲了一个函数,主要是很多类型需求在基础函数中基本都可以找到对照函数。
如果你想详细的了解stringr包的话,请一定要仔细阅读它的官方文档。
http://www.cnblogs.com/nxld/p/6062950.html这里有一篇总结的还算良心的R语言基础字符串处理函数与stringr包函数的对比。
下图是R语言中基础字符串处理函数(支持正则表达式)与stringr内 函数的对照图。你可以选择一套适合记忆用着顺序的去熟练运用(很多都是同名+str_前缀组成的),但是,无论你用哪套,str_extract()函数一定要给我记清清楚喽,除非你跟我说你喜欢用基础函数写更多冗长的代码,那样的话你自便。
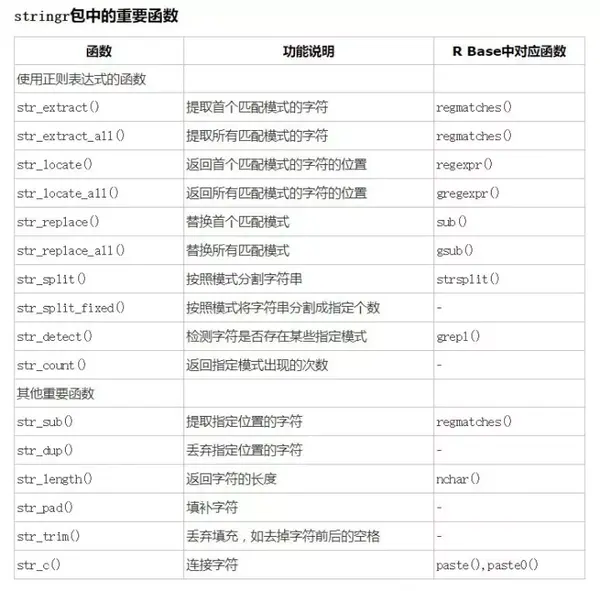
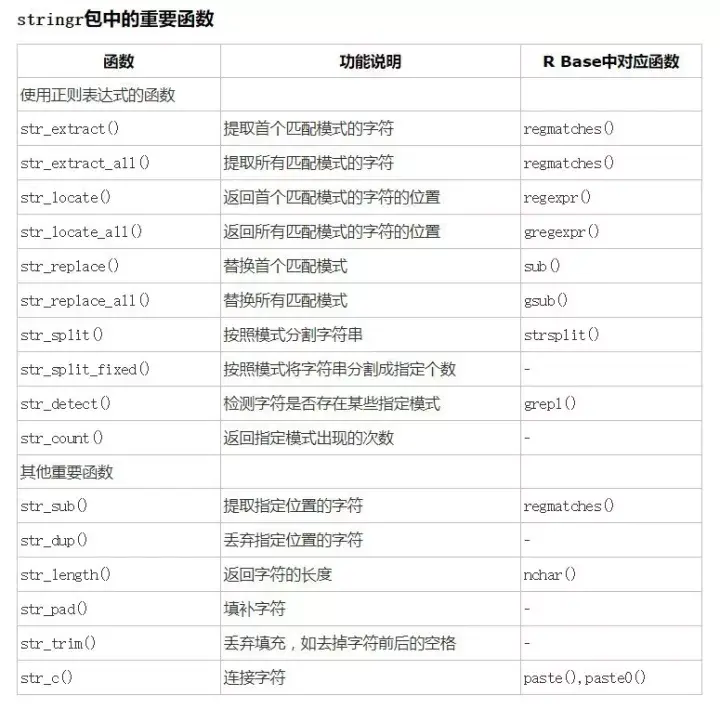
-------------
Python:
-----------
每次写R VS Pyhton系列,我都内心特别忐忑,因为我知道有很多Pyhton大佬在看我的公众号,害怕自己丢脸的,毕竟自己才学不到四个月的python。但是害怕丢人就不能进步了,所以还是坚持写了哈哈~_~。
Python中的正则表达式函数相对集中,没有那么分散,我觉的最主要的原因是很多不应该由正则或者说没必要杀鸡用宰牛刀的字符串处理需求都已经内置成很多对象的方法中去了,而os库仅仅保留了那些最为强大的几组核心字符串处理函数,而且Pyhton作为面向对象的高级编程语言,其对正则表达式的支持度很高,很多正则的原生方法都保留了下来,比如字符串包装,匹配分组等(在R中你是做不到的,R对正则的支持真的很有限)。
python为了解决转义符“\”的困扰问题,使用r作为字符前缀,直接绕过了转义难题,我们可以大胆的使用原生正则表示方法。(R中没有解决呢,遇到多重转义不懵逼那都是大侠)。
re模块给出了常用的几个支持正则匹配的字符串处理函数。
#以下为匹配所用函数
- re.split(pattern, string[, maxsplit]) #字符串拆分
- re.match(pattern, string[, flags]) #字符串匹配(只从开头匹配模式)
- re.search(pattern, string[, flags]) #不限制位置(任何位置开始匹配)
- re.findall(pattern, string[, flags]) #查找
- re.sub(pattern, repl, string[, count]) #替换
re.split(pattern, string[, maxsplit])
拆分函数与R语言中strsplit函数作用相同,按照某种特定规则进行字符串拆分。
import re
myword=["fff-888","hh-333","ff-666","ccc-666"]
name=[];value=[]
for i in myword:
name.append(re.split("-",i)[0])
value.append(re.split("-",i)[1])
myresult={"name":name,"value":value}
{'name': ['fff', 'hh', 'ff', 'ccc'], 'value': ['888', '333', '666', '666']}
以上过程成功的将myword中所有字符串按照“-”分成了两列的字典。
re.match()/re.search()
这是一对匹配目标字符串的函数,前者仅能匹配从字符串开头开始的模式,后者则不限制位置,只要符合模式即可。
name=[]
for i in myword:
name.append(re.match("[a-z]{2,3}",i).group())
['fff', 'hh', 'ff', 'ccc']
以上过程成功提取出了myword中的所有以小写字母开头连续小写字母部分。
myword=["333-fff-888","hh-333","ff-666","ccc-666"]
name=[]
for i in myword:
name.append(re.match("[a-z]{2,3}",i).group())
AttributeError: 'NoneType' object has no attribute 'group'
name=[]
for i in myword:
name.append(re.search("[a-z]{2,3}",i).group())
['fff', 'hh', 'ff', 'ccc']
我将myword中的第一个字符串字母部分开头加了数字,这种情况下re.match就无能为力了,此时就需要re.search大显神通了。
re.findall()
re.findall()是一个强大的字符串查找函数,它会以列表形式默认返回所有搜索到的结果。
myword=["333-fff-888","hh-333-hhh","ff-666-nnn","ccc-666"]
name=[]
for i in myword:
name.append(re.findall("[a-z]{2,3}",i))
[['fff'], ['hh', 'hhh'], ['ff', 'nnn'], ['ccc']]
re.findall成功捕获了myword中所有观测值的不同位置符合条件的模式字符串,如果单个记录有两处符合目标模式的字符串,则会组成列表同时输出。
这时候大家肯定会疑惑到底re.search和re.findall如何区别运用,各自的使用场景是什么。
我觉得,re.search更加适合目标字符串中嵌套有很规范的匹配对象的情况,比如一段文本包含一组日期或者职业信息,可以最大化利用正则表达式所具有的分组捕获功能分别提取各自位置的信息。re.findall则会不佳思索的不管你想要返回具体哪一个信息,都一咕噜全部甩给你。之后你还需要在嵌套列表中继续筛选,但是倘若是不规范文本,里面嵌套的信息不是很规律,re.findall可以发挥它的全面性优势,把所有符合条件的全部给你筛选出,这在网页文本这种非结构化文本中超级有用。(个人看法,比较粗浅)。
举一个小小的例子!
word="222-555ggg999dddd000dfff"
re.search(r"(\d{3})-(\d{3}).*?(\d{3}).*?(\d{3})[a-z].+$",word).group()
re.search(r"(\d{3})-(\d{3}).*?(\d{3}).*?(\d{3})[a-z].+$",word).group(1)
re.search(r"(\d{3})-(\d{3}).*?(\d{3}).*?(\d{3})[a-z].+$",word).group(2)
re.search(r"(\d{3})-(\d{3}).*?(\d{3}).*?(\d{3})[a-z].+$",word).group(3)
re.search(r"(\d{3})-(\d{3}).*?(\d{3}).*?(\d{3})[a-z].+$",word).group(4)
'222-555ggg999dddd000dfff'
'222'
'555'
'999'
'000'
re.search结合正则表达式的分组功能,可以轻而易举的按照顺序匹配出所有特定位置的目标模式字符串。
re.findall(r"(\d{3})-(\d{3}).*?(\d{3}).*?(\d{3})[a-z].+$",word)
[('222', '555', '999', '000')]
re.findall更狠,不管你愿不愿意,直接把所有捕获到的内容都给你弄成列表输出了。
re.sub()
最后一个re.sub就很好理解了,它跟R语言里面的sub函数作用差不多,就是替换。不过通常 我们用来清洗数据中的无效内容。
myword=["333-fff-888","hh-333","ff-666","ccc-666"]比如我们想要把myword中的“-”全部清除掉,仅需以下步骤。
name=[]
for i in myword:
name.append(re.sub("-","",i))
print(name)
['333fff888', 'hh333hhh', 'ff666nnn', 'ccc666']然后输出就基本不带无效字符串啦。
好了,R语言和派森中的有关字符串处理与正则支持函数基本就这些了(并未包含完,主要我使用的也很有限,这几个是很高频的需求,可以解决数据清洗中的大部分问题)。
擦,介绍了这么多,上面使用的正则还没有怎么介绍呢,不过正则表达式博大精深,绝非一两篇文章能够将清除的,我这里仅仅做一些常见匹配模式罗列,强烈建议大家去看专业的参考书和网站,说实话,正则表达式写好了,就像艺术家 一样,短短几行火星文,能够让你少写十行代码。
首先几个元字符必须要掌握:
\ 转义符,对没有任何特殊含义的字母进行转义,使之具备某种特殊含义(包括转义它自己),或者对具有特殊含义的字符进行本义还原。
^ 匹配以目标模式开头的字符串。
$ 匹配以目标模式结束的字符串。
* 这是一个数量限定符,匹配前面的子表达式零次或多次,不可独立实用。
+ 同上,匹配前面的子表达式一次或多次。
? 同上,匹配前面的子表达式零次或一次。
{n} 同上,n是一个非负整数。匹配确定的n次。
{n,} 同上,n是一个非负整数。至少匹配n次。
{n,m} 同上,匹配目标字符串出现次数在n~m之间。
. 匹配除“\n”之外的任何单个字符。
[] 匹配一组可能出现的组合,内部的任意单个模式之间是或关系。
[^] 匹配一组不可能出现的组合,内部的任意单个模式之间是或关系。
() 将可能出现的模式进行分组,可以从返回的匹配结果中捕获分组内容。
x|y 匹配x或y
常用的数字与字母匹配:
[0-9] #匹配任意一个数字(0~9之间)
[a-z] #匹配任意一个小写字母
[A-Z] #匹配任意一个大写字母
[a-zA-Z] #匹配任意一个字母
[0-9a-zA-Z] #匹配任意一个字母或者数字
当出现连续数字或者 字母时,使用以上模式看起来很不美观,正则表达式中提供了经过转义的简写形式。
\d #匹配任意一个数字