大家好,我是明哥!
本篇文章,我们回顾一次 hbase 线上问题的分析和解决 - KeyValue size too large,总结下背后的知识点,并分享一下查看开源组件不同版本差异点的方法。
希望大家有所收获,谢谢大家!
01 Hbase 简介
Hbase 作为 hadoop database, 是一款开源,分布式易扩展,面向大数据场景的,多版本,非关系型,数据库管理系统,是 Google Bigtable 的 JAVA 版开源实现。
Hbase 的底层存储引擎是 HDFS,可以在普通商业级服务器硬件(即常说的 x86 架构的服务器)的基础上,提供对超大表(表的数据量可以有百万行,每行的列数可以有百万级)的随机实时读写访问。
Hbase具有以下特征:
正是因为 Hbase 的上述特征,Hbase 在各行各业有许多线上应用案列,可以说是 NoSql 数据库的一个典型代表:
Nosql 数据库有几大类,几个典型代表是:Hbase, ElasticSearch, MongoDb;
有个有趣的现象,笔者发现国内 Hbase 使用的多,而国外似乎 Cassandra 使用的多。
02 一次线上 Hbase 问题的问题现象
某线上应用使用了 Hive 到 Hbase 的映射表,在使用 insert overwrite 从 hive 表查询数据并插入 HBASE 表时,发生了错误。
通过查看 HIVE 背后 YARN 上的作业的日志,发现主要错误信息是 java.lang.IllegalArgumentException: KeyValue size too large,详细报错截屏和日志如下:
- 2020-04-08 09:34:38,120 ERROR [main] ExecReducer: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row (tag=0) {"key":{"_col0":"0","_col1":"","_col2":"2020-04-08","_col3":"joyshebaoBeiJing","_col4":"105","_col5":"北京,"},"value":null}
- at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.reduce(ExecReducer.java:253)
- at org.apache.hadoop.mapred.ReduceTask.runOldReducer(ReduceTask.java:444)
- at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:392)
- at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:422)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
- at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
- Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: KeyValue size too large
- at org.apache.hadoop.hive.ql.exec.GroupByOperator.processOp(GroupByOperator.java:763)
- at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.reduce(ExecReducer.java:244)
- ... 7 more
- Caused by: java.lang.IllegalArgumentException: KeyValue size too large
- at org.apache.hadoop.hbase.client.HTable.validatePut(HTable.java:1577)
- at org.apache.hadoop.hbase.client.BufferedMutatorImpl.validatePut(BufferedMutatorImpl.java:158)
- at org.apache.hadoop.hbase.client.BufferedMutatorImpl.mutate(BufferedMutatorImpl.java:133)
- at org.apache.hadoop.hbase.client.BufferedMutatorImpl.mutate(BufferedMutatorImpl.java:119)
- at org.apache.hadoop.hbase.client.HTable.put(HTable.java:1085)
- at org.apache.hadoop.hive.hbase.HiveHBaseTableOutputFormat$MyRecordWriter.write(HiveHBaseTableOutputFormat.java:146)
- at org.apache.hadoop.hive.hbase.HiveHBaseTableOutputFormat$MyRecordWriter.write(HiveHBaseTableOutputFormat.java:117)
- at org.apache.hadoop.hive.ql.io.HivePassThroughRecordWriter.write(HivePassThroughRecordWriter.java:40)
- at org.apache.hadoop.hive.ql.exec.FileSinkOperator.processOp(FileSinkOperator.java:717)
- at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)
- at org.apache.hadoop.hive.ql.exec.SelectOperator.processOp(SelectOperator.java:84)
- at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)
- at org.apache.hadoop.hive.ql.exec.GroupByOperator.forward(GroupByOperator.java:1007)
- at org.apache.hadoop.hive.ql.exec.GroupByOperator.processAggr(GroupByOperator.java:818)
- at org.apache.hadoop.hive.ql.exec.GroupByOperator.processKey(GroupByOperator.java:692)
- at org.apache.hadoop.hive.ql.exec.GroupByOperator.processOp(GroupByOperator.java:758)
- ... 8 more
03 该线上 Hbase 问题的问题原因
其实以上作业的报错日志还是比较详细的:Caused by: java.lang.IllegalArgumentException: KeyValue size too large at org.apache.hadoop.hbase.client.HTable.validatePut(HTable.java:1577);
熟悉 Hbase 的小伙伴(其实不熟悉 Hbase 的小伙伴,也能从报错信息和报错类上猜到一点点),从以上信息能够猜到,是 Hbase 对每条记录的 KyeValue 的大小做了限制,当实际插入的 KeyValue 的大小超过该大小限制阈值时,就会报上述错误。
什么是 KeyValue 呢?
Hbase 为什么要限制每个 KeyValue 的大小呢?
04 该线上 Hbase 问题的扩展知识-不同 Hbase 版本相关的参数
Hbase 作为一个流行的 Nosql数据库,推出十多年来,目前有多个经典版本:
对应该 “KeyValue size too large” 问题,不同版本推出了不同的相关参数:
其实,由于笔者并没有持续跟进 HBASE 社区对 feautre 和 issue相关的讨论(大部分使用者可能都不会),所以也是在查阅不同版本的官方文档时留意到了上述细节,然后通过在本地 IDEA 中使用 git->show history 对比不同版本 HBASE 中 hbase-default.xml 的源码,进而确认到了JIRA记录号,并在JIRA中确认了这点:
正如该 JIRA 中描述:
HBASE-18043:
For sake of service protection we should not give absolute trust to clients regarding resource limits that can impact stability, like cell size limits. We should add a server side configuration that sets a hard limit for individual cell size that cannot be overridden by the client. We can keep the client side check, because it's expensive to reject a RPC that has already come in.
所以,不同版本中遇到不同情况,可能会包的错误主要有两个:
报错情况一和报错情况而,问题原因如下:
报错情况一:没有配置客户端参数 hbase.client.keyvalue.maxsize,且实际插入的 keyvalue 的大小超过了该客户端参数的默认大小限制;
报错情况二:程序设置调大了客户端参数 hbase.client.keyvalue.maxsize,但没有调大服务端参数 hbase.server.keyvalue.maxsize,且实际插入的 keyvalue 小于该客户端参数,但大于该服务端参数:
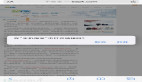
报错情况二,某次作业日志:
- Exception in thread "main"org.apache.hadoop.hbase.DoNotRetryIOException:
- org.apache.hadoop.hbase.DoNotRetryIOException: Cell with size 25000046 exceeds limit of 10485760 bytes at org.apache.hadoop.hbase.regionserver.RSRpcServices.checkCellSizeLimit(RSRpcServices.java:944)
- at org.apache.hadoop.hbase.regionserver.RSRpcServices.mutate(RSRpcServices.java:2792)
- at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:42000)
- at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
- at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130)
- at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
- at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
报错情况二,某次报错截图:
05 该线上 Hbase 问题的解决方案
知道了问题原因,其实解决方法也就呼之欲出了,在确认要插入的业务数据没有异常,确实需要调大 keyvalue 限制的阈值时,大体总结下,有以下解决办法:
06 该线上 Hbase 问题的技术背景