|
|
|


深度学习方面的科研工作中的实验代码有什么规范和写作技巧?如何妥善管理实验数据?
关注者
885
被浏览
137,294
17 个回答

跑大量实验的技巧 :
- 勤用git,至少做到在每次跑实验之前commit一次。这样做的好处是当你修改了代码但是想重复以前的实验时,可以快速回退;
- 避免在代码中 hardcode 参数信息,所有参数如 learning rate,optimizer等写在单独的一个configuration文件中;
- 写default configuration,这样每次实验只需要更改少量参数,且可以一目了然地比较不同实验的参数不同之处;
- 每次实验运行保存至少如下信息:log信息(如时间、Loss等),该次实验的configuration,训好的模型;
- 给每次实验取一个独特的id,所有实验结果保存在该id的目录下。好处是每次实验都有记录,不会相互覆盖,且可以同时跑多个实验没有写冲突;
- 训练过程中保存一个模型后,开启新线程调用评估脚本。这主要是为了自动评估那些具有复杂逻辑的评测代码。
- 如果有多块 GPU,每次实验代码自动选择空闲的GPU,保证多个实验不会挤在一起;
- 如果有多台机器,构建一个中央存储机器(比如 AFS),训练过程中自动把模型上传到中央存储机器;
推荐工具 :
- git (保存代码)
- sacred (记录实验log和configuration)
- omniboard (查看sacred保存的log和configuration)
- tensorboard (pytorch、mxnet等都可以使用相应的API接口)
参考代码 :
我写了一份使用深度学习的目标跟踪代码,上面说的所有点都覆盖了,供参考: https:// github.com/bilylee/Siam FC-TensorFlow


题主你好呀~
与其苦苦摸索实验代码规范和实验管理方法,不如来借鉴下 OpenMMLab 系列的项目规范,用 MMCV 武装自己的项目。
另外 OpenMMLab 已经开源了 20+ 个算法库,涵盖多个领域,在动手之前不妨先看看自己的方向是否与之重合,有一个好的轮子,往往会事半功倍。
实验管理
反复调参、反复实验是成为一名合格的深度学习炼丹师的必经之路。随着模型变得越来越复杂,超参变得越来越多,如何正确地管理实验,就变得尤为重要。
代码管理
建议使用 Git 对代码做版本管理。非常赞同 bily Lee 的说法,每次实验之前至少要做一次 commit,这样能够保证之前的实验是可复现的。除此之外,既然已经用 Git 来做版本管理,不妨使用 pre-commit hook 来规范自己的代码。可以参考 MMCV 的 CONTRIBUTING.md 配置一下 pre-commit,之后你每一次的提交都会受到诸如 flake8、isort、yapf 等多种代码检查工具的洗礼,代码规范化,从每一次提交做起。
MMCV 最近还引入了 mypy 来对代码做静态检查,如果不嫌麻烦,写代码的时候可以顺手加上 Type Hints,让自己的代码更加鲁棒。
mypy 和 Type Hints 的关系详情请见:
配置文件管理
随着算法越来越复杂,参数越来越多,现在很难光靠命令行传参来配置训练所需的全部参数。把训练参数全部写到配置文件里的确不失为一个好办法,不仅方便配置更多的参数,还能够做版本管理,一举两得。
不同格式的配置文件
但是我们应该用什么格式的配置文件呢?python 文件本身是能作为配置文件的,我们可以通过 import 来解析配置文件的各种字段。这样的好处很明显:大部分的深度学习研究员、算法工程师是非常熟悉 python 的,使用 python 格式的配置文件最为直观。
然而 python 格式配置文件的短板也同样明显:假设我们想把训练的模型部署到移动端,而移动端又没有 python 的解释器,也就无法配置文件。
json 和 yaml 格式的配置文件固然通用,但是又不如 python 的直观。怎么办?小孩子才做选择,MMCV 全都要!
MMCV 支持 python、json、yaml 格式的配置文件,用户可以根据自己的偏好自行选择。
python 格式
toy_config.py
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
gpu_ids = [0, 1]
model = dict(type='ResNet', depth=50) json 格式
toy_config.json
{"optimizer": {"type": "SGD", "lr": 0.02, "momentum": 0.9, "weight_decay": 0.0001}, "gpu_ids": [0, 1], "model": {"type": "ResNet", "depth": 50}} yaml 格式
toy_config.yaml
gpu_ids:
model:
depth: 50
type: ResNet
optimizer:
lr: 0.02
momentum: 0.9
type: SGD
weight_decay: 0.0001 加载配置文件:
from mmcv import Config
cfg_py = Config.fromfile('toy_config.py')
cfg_json = Config.fromfile('toy_config.json')
cfg_yaml = Config.fromfile('toy_config.yaml') 交叉导出配置文件:
from mmcv import Config
cfg_py = Config.fromfile('toy_config.py')
cfg_py.dump('toy_config1.json')
cfg_py.dump('toy_config1.yaml') 配置文件之间的继承
深度学习任务通常会有一些共用的配置文件,例如数据集、优化器参数、分布式配置等。为了能够不在每一个配置文件里重复定义这些参数,MMCV 选择实现了配置文件的继承功能。
以 MMDetection 为例,其配置文件的目录结构如下:
configs/
├── _base_
│ ├── datasets
│ ├── default_runtime.py
│ ├── models
│ └── schedules
├── albu_example
│ ├── mask_rcnn_r50_fpn_albu_1x_coco.py
│ └── README.md
├── atss
│ ├── atss_r101_fpn_1x_coco.py
│ ├── atss_r50_fpn_1x_coco.py
│ ├── metafile.yml
│ └── README.md
├── autoassign
│ ├── autoassign_r50_fpn_8x2_1x_coco.py
│ ├── metafile.yml
│ └── README.md
其中 _base_ 文件夹里存放了一些公共配置。我们可以在具体算法里引用这些配置文件,以单阶段检测器 atss 为例,只需要几行代码就能完成优化器、训练计划的配置:
atss_r50_fpn_1x_coco.py
_base_ = [
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
除此之外,配置文件的继承也让实验的控制变量变得更加简单。同样以 atss 为例,可以按照 backbone 深度分为
atss_r50_fpn_1x_coco.py
和
atss_r101_fpn_1x_coco.py
。如果没有配置文件的继承,写出来的效果可能是这样的:
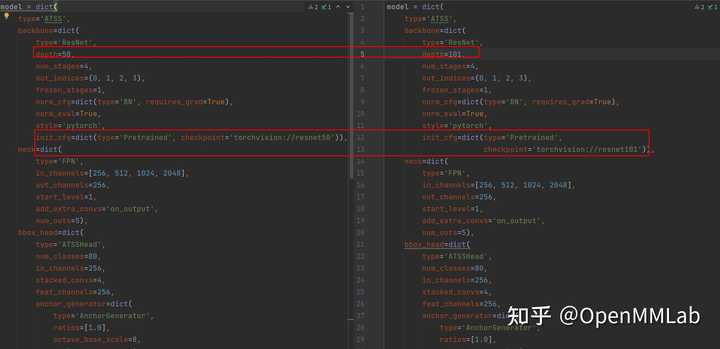
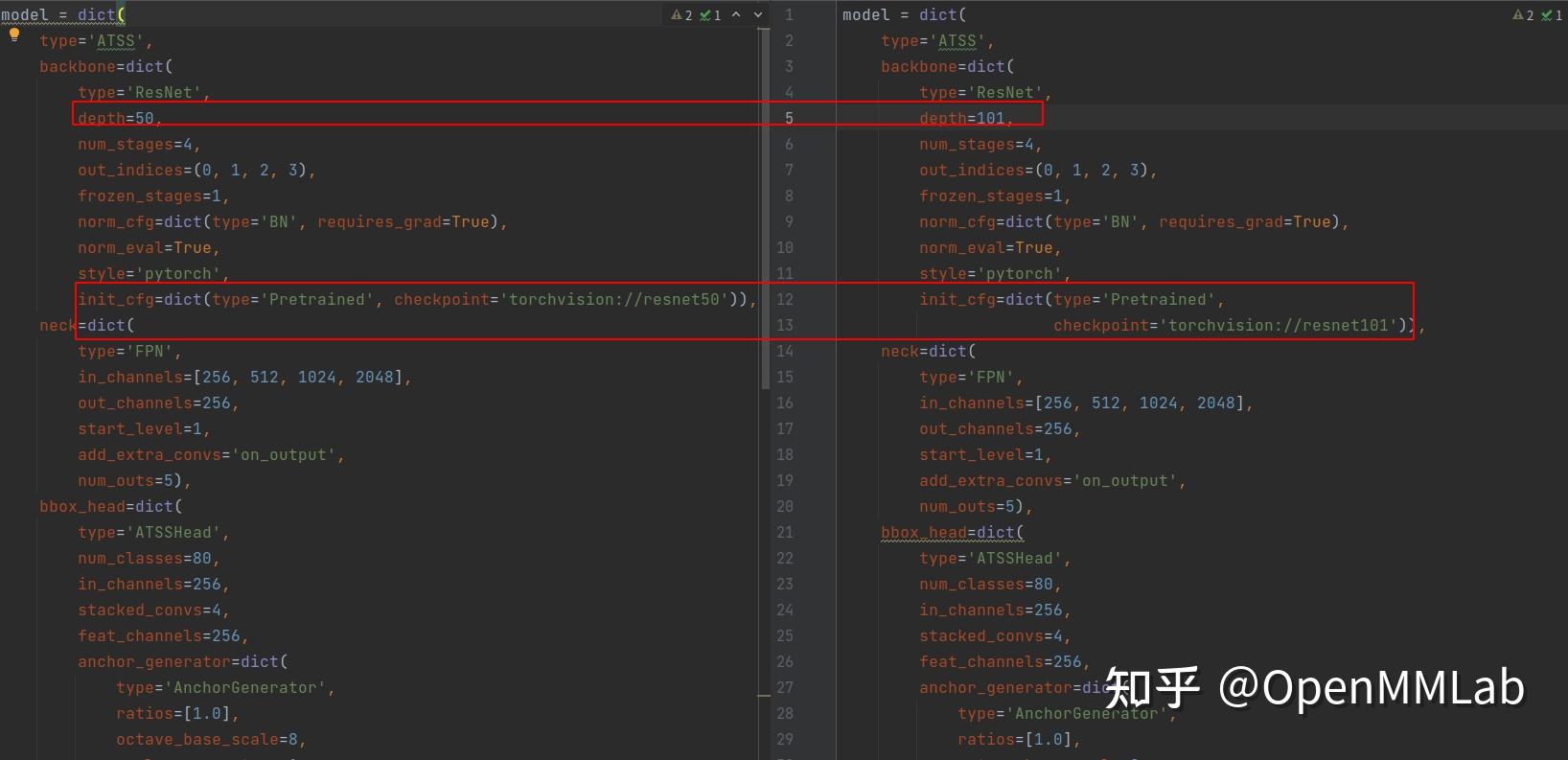
偌大的一个配置文件,差别只有这区区两行。跑实验的时候你可能还记得住二者的区别,等过段时间再回来看,你可能需要去一行一行地去对,才能确定两个配置文件的具体区别。
然而有了配置文件的继承,一切都变得更加简单:
_base_ = './atss_r50_fpn_1x_coco.py'
model = dict(
backbone=dict(
depth=101,
init_cfg=dict(type='Pretrained',
checkpoint='torchvision://resnet101'))) 一目了然有木有,一眼就能看出改了啥。
鲜为人知的小彩蛋
除了上述核心功能外,MMCV 的配置文件还有一些小功能,例如我们可以通过一些特定字段来获取配置文件路径、配置文件名、配置文件类型等信息(命名规则参考 vscode)
demo_config.py
file_dirname = '{{fileDirname}}'
file_basename = '{{fileBasename}}'
file_basename_no_extension = '{{fileBasenameNoExtension}}'
file_extname = '{{fileExtname}}'
demo_test.py
from mmcv import Config
cfg = Config.fromfile('demo_config.py')
print(cfg.file_dirname) # 配置文件路径
# /home/yehaochen/codebase/python/openmmlab/mmdetection