自增Long类型的主键可以主键自增,数字类型占用空间小,走索引速度更快,对于排序有更好的性能
①若需要手动插入,或者从其他系统导入带有ID的数据,这些数据的id和原来数据的id容易造成冲突,若其他系统的ID不是数值型的,则同步数据更加痛苦
②从1自增上去的ID,容易被猜测进行数据窃取等安全问题
③对分布式很不友好,即使用分段生成的ID(比如定义5千万后的ID给二数据库)也有可能之前一段的超额导致重复的问题;若是采用取余分布ID(3个数据库集群,就对三取余,相同余数的位于一个数据库)的策略,扩容后该如何对之前的数据进行处理又是难题。
ID设计:唯一性自增ID(int),或者Guid(string)(36位,32位英文字符+4位横杠)
1、空间考虑:int型比Guid暂用空间少。//1,000,000,000(10位数就是10亿,顶多再扩张几位,足够用了)
2、效率考虑:整型比对 比字符型快。
转载于:https://www.cnblogs.com/zhangj391/p/6713629.html...
在 MySQL 数据表的设计中,官方推荐我们不要使用 UUID 或者其他不连续不重复的 id,而是推荐使用连续自增的主键 id(auto_increment),那么为什么会这样建议呢,我们来简单地分析一下。
随着现在许多项目都涉及到了分布式或者微服务,后续或多或少都会针对具体的服务需求对数据库进行拆分(分库分表),这里就会产生一个问题,拆分后的 id 该如何妥善处理?
例如,在之前的业务中,所有的数据内容都是存放在同一张数据表中的,主键 id 都是自增的,这当然没有任何问题。但是当单表的数据量上
雪花算法及爬坑雪花算法的原理java代码实现前端接收精度丢失问题处理1.现象描述2.处理方案参考链接
雪花算法的原理
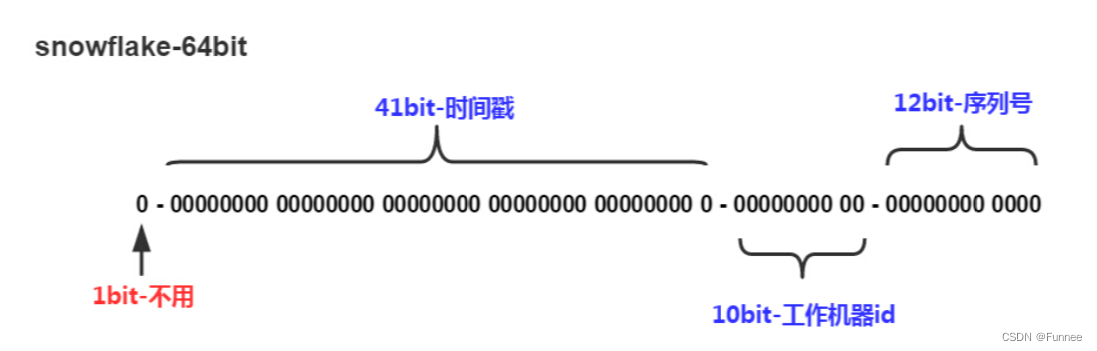
SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,基本上保持自增的。
这 64 个 bit 中,其中 1 个 bit 是不用的,然后用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号。