

MySQL分组查询——group by

- 什么是分组查询?
将查询结果按照1个或多个字段进行分组,字段值相同的为一组
其实就是按照某一列进行分类
- 分组使用
SELECT gender from employee GROUP BY gender;
根据gender字段来分组,gender字段的全部值只有两个('男'和'女'),所以分为了两组
当group by单独使用时,只显示出每一组的第一条记录
所以group by单独使用时的实际意义不大
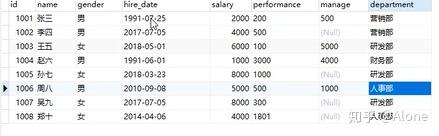
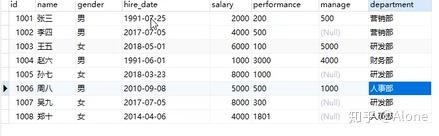
SELECT * FROM employee;
只显示了每一组第一条记录
男生的第一个人是张三 女生的第一个人是王五
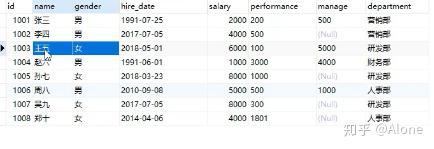
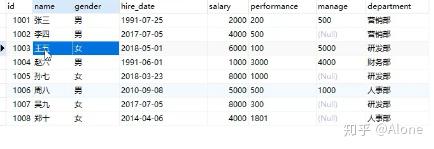
所以说GROUP BY 一般不单独使用
一般来说 你按照什么分组 就查询什么东西
比如:
select department from employee group by department;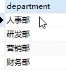
查询结果如上。
分完组然后呢?
- 如何对分组后的结果进行查询?
关键字:group_concat()
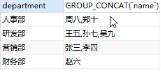
将职员表 按照部门分组 查询每个部门职员的姓名
select department,group_concat(name) from employee group by department;结果如下:
- GROUP BY + 聚合函数
for example:
将职员表 按照部门分组 查询每个部门职员的薪水 和 薪水总数
select department,group_concat(salary),sum(salary) from employee group by department;
查询每个部门的名称 以及 每个部门的人数
select department,group_concat(name),count(*) from employee group by department;查询每个部门的部门名称 以及 每个部门工资大于1500的人数
PS: 先把大于1500的人查出来 再做分组
select department,group_concat(salary),count(*) from employee group by department;group by + having
- 用来分组 查询后 制定一些条件来输出查询结果
- having的作用和where一样,但having只能用于group by
- 查询工资总和大于9000的部门名称以及工资和
SELECT department,GROUP_CONCAT(salary),SUM(salary) FROM employee
GROUP BY department HAVING SUM(salary) > 9000;- having和where的区别
having是在分组后对数据进行过滤
where是在分组前对数据进行过滤
having后面可以使用分组函数(统计函数)
where后面不可以使用分组函数
where是对分组前记录的条件,如果某行记录没有满足where子句的条件,那么这行记录不会参加分组;而having是对分组后数据的约束
- 查询工资和大于2000的 工资总和大于6000的部门名称以及工资和
SELECT department,GROUP_CONCAT(salary).SUM(salary) FROM employee