一、图联邦学习介绍
大多数图学习模型如
图神经网络
(Graph Neural Networks,GNNs)都是基于大量的图数据进行训练的,然而在许多现实场景中,例如医疗保健系统中的住院预测,图数据通常存储在多个数据所有者处,由于涉及患者的隐私和相关法律法规限制,不同数据所有者的数据不能直接共享。
联邦学习
(Federated Learning, FL)是一种分布式学习方案,通过多个参与方(即客户端)协作训练一个模型而无需共享他们的隐私数据,以解决数据隔离问题。
图联邦学习
(Federated Graph Learning,FGL)是联邦学习在图数据上的应用,通过以联邦方式训练图神经网络,来解决图数据隐私保护的问题。
图联邦学习的分类:
按照图数据在客户端之间的分布方式,将图联邦学习划分为
:
图间联邦学习(inter-graph FL)、图内联邦学习(intra-graph FL)、图结构联邦学习(graph-structured FL)。
图联邦学习的分类
二、图间联邦学习(inter-graph FL)
图间联邦学习是图联邦学习最常见的学习方式,其中每个客户端样本都是图数据,全局模型执行图级任务。 图间联邦学习最典型的应用是在生物化学行业,研究人员使用图神经网络来研究分子的图结构。一个分子可以表示为一个图,其中节点表示原子,边表示化学键。在药物特性研究中,每个制药公司都拥有一个机密数据集
 ,其中包含多个分子结构
,其中包含多个分子结构
 (即特征)和相应的性质
(即特征)和相应的性质
 (即标签)。在过去,由于商业竞争的阻碍,各公司之间无法共享数据,但在图间联邦学习框架下能够实现数据的共享。在这种情况下,
(即标签)。在过去,由于商业竞争的阻碍,各公司之间无法共享数据,但在图间联邦学习框架下能够实现数据的共享。在这种情况下,
 ,则图神经网络的全局模型为:
,则图神经网络的全局模型为:
其中,
 和
和
 分别表示第
分别表示第
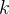 个客户端的数据集中第
个客户端的数据集中第
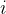 个图的特征和邻接矩阵,
个图的特征和邻接矩阵,
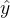 表示输出。
表示输出。
应用FedAvg后,目标函数为:
其中,
 为本地目标函数,L为全局损失函数。
为本地目标函数,L为全局损失函数。
 表示 第
个客户端的数据集中所有节点的数量。
表示 第
个客户端的数据集中所有节点的数量。
图间联邦学习
三、图内联邦学习(Intra-graph FL)
在图内联邦学习中,每个客户端拥有整张图的一部分数据(即子图),与联邦学习类似地,图内联邦学习可以分为横向图联邦学习和纵向图联邦学习。
1、横向图联邦学习
在横向图联邦学习中,每个客户端中持有的子图数据
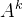 可以看作是从潜在的整张图
可以看作是从潜在的整张图
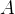 中水平划分出来的(各子图之间的连接丢失了,严格来说可以有重叠),即
中水平划分出来的(各子图之间的连接丢失了,严格来说可以有重叠),即
 。水平分布的子图具有相同的属性,客户端共享相同的特征和标签空间,但节点ID不同。例如:一个省内,不同城市的多家银行拥有大不相同的客户群体,银行
构建有行内客户的关联关系网络
。水平分布的子图具有相同的属性,客户端共享相同的特征和标签空间,但节点ID不同。例如:一个省内,不同城市的多家银行拥有大不相同的客户群体,银行
构建有行内客户的关联关系网络
 ,而对于任意两家银行的客户关系网络而言可能存在一些用户的潜在关联。 因此,所有银行的客户关系网络汇总起来可以构成整个省内银行客户关系网络
,而对于任意两家银行的客户关系网络而言可能存在一些用户的潜在关联。 因此,所有银行的客户关系网络汇总起来可以构成整个省内银行客户关系网络
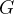 。持有不同客户关系数据的多家银行可以在横向图联邦学习框架下共享数据,以进行各自的反欺诈、反洗钱、关联风险预警等业务。
。持有不同客户关系数据的多家银行可以在横向图联邦学习框架下共享数据,以进行各自的反欺诈、反洗钱、关联风险预警等业务。
在这种情况下,
 ,则图神经网络的全局模型为:
,则图神经网络的全局模型为:
其中,
 和
和
 分别表示第
个客户端数据集的特征和邻接矩阵,
分别表示第
个客户端数据集的特征和邻接矩阵,
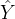 表示输出。
表示输出。
应用FedAvg后,目标函数为:
2、纵向图联邦学习
子图的垂直分布是指它们是平行的,并且彼此之间有很大的重叠,可以看作是从潜在的整张图中纵向划分出来的,即
、
 、
、
 。在这种情况下,客户端具有大部分相同的节点ID,特征和标签大不相同。例如,对于同一地区中不同行业的多家公司,可能具有大部分相同的客户群体,而特征和标签不同。
。在这种情况下,客户端具有大部分相同的节点ID,特征和标签大不相同。例如,对于同一地区中不同行业的多家公司,可能具有大部分相同的客户群体,而特征和标签不同。
在这种情况下,
,
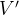 表示节点的集合,
表示
的大小。而图神经网络的全局模型不是唯一的(取决于多少客户端有标签),这表明纵向图联邦学习支持多任务学习。纵向图联邦学习的目的是通过在隐私保护的前提下结合
表示节点的集合,
表示
的大小。而图神经网络的全局模型不是唯一的(取决于多少客户端有标签),这表明纵向图联邦学习支持多任务学习。纵向图联邦学习的目的是通过在隐私保护的前提下结合
 并共享
并共享
 ,进行图神经网络的学习。不考虑实体匹配和数据共享的方法,目标函数可以表示为:
,进行图神经网络的学习。不考虑实体匹配和数据共享的方法,目标函数可以表示为:
六、图联邦学习的挑战
图联邦学习是近两年兴起的技术,其中存在许多挑战,多为传统联邦学习的遗留问题,如非独立同分布数据(Non-IID data)、通信效率(communication efficiency)、鲁棒性(robustness)。此外,还存在图联邦学习所特有的问题,如横向图内联邦学习的孤立图问题(Isolated graph in horizontal intra-graph FL)、纵向图内联邦学习的实体匹配和安全数据共享问题(Entities matching and secure data sharing in vertical intra-graph FL)、图内联邦学习缺乏数据集(Dataset of intra-graph FL)等。
1、非独立同分布的图结构
无论哪种类型的图联邦学习,非独立同分布问题都不可避免。与联邦学习一样,它既影响收敛速度,又影响收敛精度,目前还没有方法可以彻底解决此问题。除了特征和标签之外,图数据还具有边(结构)信息,这表明图结构的非独立同分布也可能影响学习过程。图结构的性质包括度分布、平均路径长度、平均聚类系数等。研究这些性质的非独立同分布可能是解决图域非独立同分布问题的一个重要方向。
2、横向图内
联邦学习的孤立图
图模型上的表示学习依赖于遍历或多阶邻域间的消息传递。然而,在横向图内联邦学习中,不同的客户端持有潜在整张图的一部分数据,本地子图的直径一般很小。这将影响图神经网络的准确性,因为本地子图不能提供来自高阶邻居的信息。一个极端的情况是,若本地子图只包含一个节点,图卷积网络GCN将退化为多层感知机MLP。因此在横向图内联邦学习中,发现客户端本地子图中的潜在边是一个至关重要的挑战。
3、纵向图内联邦学习的实体匹配与安全数据共享
实体匹配(隐私集合求交PSI)和安全数据共享是纵向联邦和纵向图内联邦学习的关键问题。纵向图内联邦学习的主要难点还在于在隐私保护的前提下尽可能地提升精度和通信效率。有相关研究提出了一种联邦框架,通过在服务器中保存的匹配表进行知识图谱嵌入,这在一定程度上违反了隐私保护原则。
4、图内联邦学习缺乏数据集
图像和语料库数据集的丰富性是计算机视觉和自然语言处理快速发展的必要条件,然而适合图内联邦学习的公开图数据集目前还很少。对于欧式数据,可以很容易地通过实验模拟数据分布,例如将样本集合
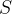 划分为
划分为
 ,将特征集
,将特征集
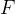 划分为
划分为
 ,这很容易实现,不需要考虑额外的因素。但涉及到图形数据时,由于图中存在着结构,很难模拟数据分布。例如,在横向图联邦学习中,需要将一整张图分割成多个子图以模拟多个客户端的数据,但是有一些边被破坏,并且子图分布也不符合实际情况。在纵向图联邦学习也一样困难,虽然可以将特征划分为几部分,但需要考虑所有部分是否具有相同的结构。在现实场景中,结合相关业务规则,这还要复杂得多。因此,数据集的缺乏限制了图内联邦学习的发展。
,这很容易实现,不需要考虑额外的因素。但涉及到图形数据时,由于图中存在着结构,很难模拟数据分布。例如,在横向图联邦学习中,需要将一整张图分割成多个子图以模拟多个客户端的数据,但是有一些边被破坏,并且子图分布也不符合实际情况。在纵向图联邦学习也一样困难,虽然可以将特征划分为几部分,但需要考虑所有部分是否具有相同的结构。在现实场景中,结合相关业务规则,这还要复杂得多。因此,数据集的缺乏限制了图内联邦学习的发展。
5、通信和内存消耗
在实际应用图联邦学习算法时,通信和内存消耗是一个关键瓶颈。例如,对于联邦推荐系统,服务器和客户端之间传输的模型可能很大,其中用户和商品隐藏层占据了大部分模型参数,并且隐藏层参数的大小随着用户和商品节点的规模不断增加而线性增长,会造成通信和内存的大量消耗。对于这一问题,模型量化、剪枝、蒸馏是模型压缩的有效方法。
参考文献:
1、(2021)Zhang H, Shen T, Wu F, et al. Federated graph learning--a position paper[J]. arXiv preprint arXiv:2105.11099, 2021.
2、(2022)Fu X, Zhang B, Dong Y, et al. Federated graph machine learning: A survey of concepts, techniques, and applications[J]. ACM SIGKDD Explorations Newsletter, 2022, 24(2): 32-47.
联邦学习(Federated Learning, FL)是一种分布式学习方案,通过多个参与方(即客户端)协作训练一个模型而无需共享他们的隐私数据,以解决数据隔离问题。图联邦学习(Federated Graph Learning,FGL)是联邦学习在图数据上的应用,通过以联邦方式训练图神经网络,来解决图数据隐私保护的问题。
【资源说明】
课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip
课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip
课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip
课程大作业基于
联邦学习
模型的对抗攻击python源码+详细注释+模型.zip
1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用!
2、本项目适合计算机相关专业(如计科、
人工智能
、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载使用,也适合小白学习进阶,当然也可作为毕设项目、课程设计、作业、项目初期立项演示等。
3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可直接用于毕设、课设、作业等。
欢迎下载,沟通交流,互相学习,共同进步!
文章目录论文信息摘要主要贡献聚类驱动的
图
联邦学习
问题定义联邦聚类聚类模型聚类模型的联系FedCG框架
Cluster-driven
Graph
Federated
L
ear
ning
over Multiple Domains
原文链接:Cluster-driven
Graph
Federated
L
ear
ning
over Multiple Domains:https://openaccess.thecvf.com/content/CVPR2021W/LLID/papers/Caldarola
spreadgnn是一种无服务器多任务
联邦学习
方法,针对
图
神经网络。
联邦学习
是一种新兴的机器学习方法,它允许不同设备(例如移动设备)上的数据进行局部训练,然后将训练后的模型聚合,以获得更好的泛化性能。
Graph
Neural Network是一类可以处理
图
形和网络数据的神经网络,目前在社交网络、化学和蛋白质结构等领域有广泛应用。
spreadgnn使用无服务器架构设计来实现多任务
联邦学习
。本方法采用一种名为
Federated
Averaging的模型聚合方法,它将本地模型分发到各个设备上,让每个设备进行本地模型的训练,并将本地模型更新结果汇聚回全局模型中。spreadgnn还使用了一种名为
联邦学习
架构的方法来处理不同的
联邦学习
任务,以提高模型泛化性能。同时,spreadgnn使用了一种名为
Graph
Sage的
图
神经网络模型,以应对
图
和网络数据。
总之,spreadgnn在无服务器架构、
Federated
Averaging、
联邦学习
架构和
Graph
Sage等方面做出了创新,能够有效地应对多任务
联邦学习
的挑战。
CSDN-Ada助手:
知识图谱嵌入:TransE算法原理及代码详解
$690:

