|
|
|
相关文章推荐

|
忐忑的薯片 · 日本原装进口PILOT百乐上墨器旋转式CON ...· 8 月前 · |
|
|
直爽的青蛙 · 《阿里阿德涅在拿索斯岛》开演 ...· 9 月前 · |
|
|
精明的核桃 · 哥萨克:东欧的“超级雇佣兵”,帮俄罗斯扩张西 ...· 10 月前 · |
|
|
非常酷的斑马 · 学院简介-广东技术师范大学-民族学院· 10 月前 · |
|
|
冷静的葫芦 · 《忏悔录》:一个人觉醒的三个迹象_卢梭_生活_研究· 10 月前 · |


ColossalChat:完整RLHF平替ChatGPT的开源方案
小虎AI珏爷
NLP,CV,语音,大数据,对话系统,KG,区块链,强化学习
215
赞同
14
评论
887
收藏
小虎AI珏爷:ChatGPT背后的技术之理解人类反馈强化学习(RLHF)
小虎AI珏爷:OpenAI ChatGPT前身-InstructGPT:训练语言模型,使其能够根据人的反馈来执行指令
Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
ColossalAI/applications/Chat at main · hpcaitech/ColossalAI
LLAMA底座模型下载 :
https:// ipfs.io/ipfs/Qmb9y5GCkT G7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
LLAMA底座模型下载(Hugging Face) :
https://www. 123pan.com/s/Su8ZVv-g97 q3.html 提取码:xgOP
Bloomz-7b底座模型下载(Hugging Face) :
bigscience/bloomz-7b1-mt at main
小虎AI珏爷:ChatGPT平替-中文ChatGLM-6B本地部署
小虎AI珏爷:ChatGPT可能的应用场景及Prompt使用方式
小虎AI珏爷:ChatGPT指令模板大全-通用人工智能的觉醒
小虎AI珏爷:论文阅读-PaLM-E:一种体现的多模态语言模型
小虎AI珏爷:论文阅读:Language Models are Few-Shot Learners(巨无霸OpenAI GPT3 2020)
小虎AI珏爷:论文阅读:语言模型是无监督的多任务学习者(GPT2 2019)
小虎AI珏爷:LLaMA:开放高效的基础语言模型(Meta AI-2023)
小虎AI珏爷:OpenAI ChatGPT前身-InstructGPT:训练语言模型,使其能够根据人的反馈来执行指令
小虎AI珏爷:OpenAI默认算法-PPO:近端策略优化算法
1 介绍
Colossal人工智能是基于加州大学伯克利分校杰出教授James Demmel教授和新加坡国立大学总统青年教授Yang You教授的专业知识开发的。自开源发布以来,Colossal AI已多次在GitHub Trending上排名第一,拥有约20000名GitHub stars,并成功被接受为SC、AAAI、PPoPP、CVPR和ISC等国际人工智能和HPC顶级会议的官方教程。
ColossalChat是对 小虎AI珏爷:ChatGPT背后的技术之理解人类反馈强化学习(RLHF) 、 小虎AI珏爷:OpenAI ChatGPT前身-InstructGPT:训练语言模型,使其能够根据人的反馈来执行指令 的完整实现方案。基础语言模型使用Meta AI的 小虎AI珏爷:LLaMA:开放高效的基础语言模型(Meta AI-2023) 。
ColossalChat是第一个基于LLaMA预训练模型开源完整RLHF pipline实现,包括有监督数据收集、有监督微调、奖励模型训练和强化学习微调。您可以开始用1.6GB的GPU内存复制ChatGPT训练过程,并在训练过程中体验7.73倍的加速。
它包括以下内容:
- 在线Demo: 一个交互式演示,可以在没有注册或等待名单的情况下在线尝试。
- 训练代码: 开源完整的RLHF训练代码,包括7B和13B的模型。
- 数据集: 开源104K中英文双语数据集。
- 推理: 仅需要4GB GPU内存的70亿参数模型的4位量化推理。
- 模型权重: 在单个服务器上只需少量计算能力即可实现快速复制。
- 将快速更新和添加其他更大的模型、数据集和其他优化。
ColossalChat只需要不到100亿个参数,就可以在大型语言模型的基础上通过RLHF微调达到中英文双语水平,达到与ChatGPT和GPT-3.5相当的效果。
Meta已经开源了 LLaMA 模型,该模型提供了70亿至650亿的参数大小。在大多数基准测试中, 130亿参数 的模型可以 优于1750亿GPT-3模型 。然而,由于它没有指令调优阶段,因此实际生成的结果并不令人满意。
斯坦福大学的Alpaca通过调用OpenAI的API,以自学的方式生成训练数据。这个轻量级模型只有70亿个参数,可以以很小的成本进行微调,以实现类似于GPT-3.5这样的具有1750亿个参数的大型语言模型的会话性能。
然而,现有的开源解决方案只能被视为RLHF(从人类反馈中进行强化学习)第一阶段的监督微调模型,而后续的调整和微调阶段则不执行。此外,Alpaca的训练数据集仅限于英语,这在一定程度上限制了模型的性能。
然而,ChatGPT和GPT-4令人印象深刻的效果是由于在训练过程中引入了RLHF,这增加了生成的内容与人类价值观的一致性。
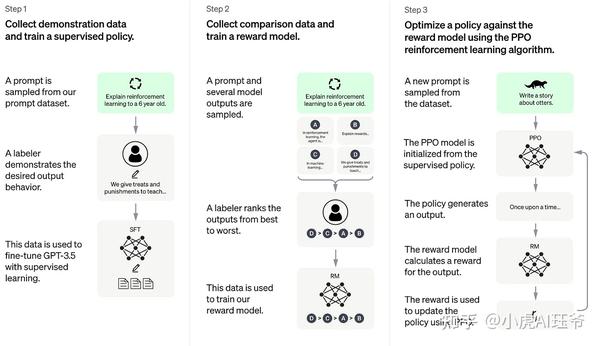
基于LLaMA模型,ColossalChat是第一个实用的开源项目,它包括一个完整的RLHF过程来复制类似ChatGPT的模型,也是最接近ChatGPT原始技术路线的项目。
2 开源训练数据集
2.1 SFT指令微调)数据集
样例
{"prompt": "Task: Find out what are the key topics in the document? output \"topic 1\", \"topic 2\", ... , \"topic n\".\n\nThe United States has withdrawn from the Paris Climate Agreement.\n\n", "completion": "Topic 1<|endoftext|>"}
{"prompt": "Given a list of numbers, find out if they are prime or not. you can answer \"prime\" or \"not prime\".\n\nInput: List: 1, 4, 6, 8, 9\n\nOutput:", "completion": " not prime<|endoftext|>"}
{"prompt": "Task: What are some of your favorite websites, and why do you visit them often?\n\n", "completion": "- Stack Overflow - I like to learn new things, and this is a great place to find answers to questions.<|endoftext|>"}
{"prompt": "Should i take this class or not?\nThe professor of this class is not good at all. He doesn't teach well and he is always late for class.\n\n", "completion": "No<|endoftext|>"}
{"prompt": "Given an array of integers, find two integers that sum up to a specific target integer.\n\n[1, 2, 3, 4]\nTarget: 7\n\n", "completion": "5 and 2<|endoftext|>"}
{"prompt": "Find out how many times does the word appear in the document. output the number of times.\nThe quick brown fox jumps over the lazy dog.\n\n", "completion": "3<|endoftext|>"}
{"prompt": "Rank these users according to their social influence.\nUser: The new movie is great. I would recommend it to anyone who likes action movies.\n\n", "completion": "2<|endoftext|>"}(SFT指令微调)数据集下载 :
yizhongw/self_instruct: https:// raw.githubusercontent.com /yizhongw/self-instruct/main/data/finetuning/self_instruct_221203/gpt3_finetuning_data.jsonl
全量数据 可以公众号【 小虎AI珏爷 】回复 【 ChatGPT】 获取
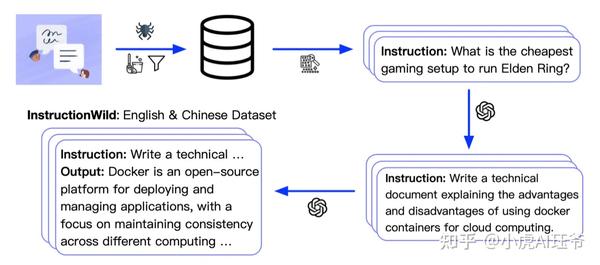
2.2 奖励模型排序数据集
rm-static样例:
| prompt (string) | response (string) | chosen (string) | rejected (string) |
|---|---|---|---|
|
" Human: Can you describe the steps to clean fingerprints and smudges from a laptop screen
Assistant: Yes, certainly. To clean your screen, you first need to use a microfiber cloth or soft, damp cloth to gently wipe down the surface of the screen. Next, you’ll want to grab a soft, lint-free, microfiber cleaning cloth and gently rub it back and forth across the screen to remove fingerprints and smudges. Human: Can I spray isopropyl alcohol onto the cloth and clean it that way? Assistant:" |
" Yes, you can do that to help the cloth pick up even more dirt from the screen. Be sure to always use a clean, soft cloth, not a piece of scratchy, roughened, or textured material, and make sure it’s lint-free." | " Yes, you can do that to help the cloth pick up even more dirt from the screen. Be sure to always use a clean, soft cloth, not a piece of scratchy, roughened, or textured material, and make sure it’s lint-free." | " Yes, you can spray it directly onto the cloth." |
| " Human: What are some foods that are good for diabetics? Assistant: To be honest, some of these are better than others, and they’re a little more like opinions than facts. For example, many of the diets say to limit vegetables with high sugar content, and there’s some debate on the subject, as far as how much of these vegetables are actually bad for diabetics. Human: Okay, any other advice? Assistant:" | " What exactly are you asking? There’s a lot of different kinds of diabetic diets. I could try to recommend you some specific foods and recipes. I could help you look up any of the foods, and I could find recipes for them." | " What exactly are you asking? There’s a lot of different kinds of diabetic diets. I could try to recommend you some specific foods and recipes. I could help you look up any of the foods, and I could find recipes for them." | " Sure, we’ve got information on common mistakes that diabetic patients make with their diets, and even some specific things to do when you eat out and on the go. One thing that’s recommended in these articles is just to be very mindful of the timing of food intake." |
| " Human: What animal would be the dominate life form on Earth if humans weren't here? Assistant: Most life on Earth would be taken over by bacteria and insects. Human: What about birds? Could they ever come to dominate the Earth? Assistant:" | " Possibly. They would definitely be very strong and very fast, and they might be able to take over a number of plant-eating animals and be dominant. That's a guess, I'm not sure what exactly a dominant lifeform would be." | " Possibly. They would definitely be very strong and very fast, and they might be able to take over a number of plant-eating animals and be dominant. That's a guess, I'm not sure what exactly a dominant lifeform would be." | " Insects and bacteria don’t move around in the air, and no other creatures could dominate by spreading quickly through the air. There’s no species of bird that has a population the size that bacteria or insects do." |
| " Human: How often are the Olympics? Assistant:" | " It is estimated that the Olympics occur every four years. Did that answer your question?" | " It is estimated that the Olympics occur every four years. Did that answer your question?" | " For 2017, it was every four years." |
Dahoas/rm-static · Datasets at Hugging Face
https:// huggingface.co/datasets /Anthropic/hh-rlhf
spark读取parquet文件
val df_test = spark.read.parquet("src/main/resource/data/parquet/rm-static-test.parquet")
val df_train = spark.read.parquet("src/main/resource/data/parquet/rm-static-train.parquet")
df_test.show()
df_test.coalesce(1).write
.option("header", "true")
.csv("test.csv")
df_train.coalesce(1).write
.option("header", "true")
.csv("train.csv")需要 CSV格式 的可以公众号【 小虎AI珏爷 】回复 【 ChatGPT】 获取
2.3 人类反馈强化学习数据集
ColossalChat发布了一个双语数据集,包含约100000对英语和汉语问答。该数据集是从社交媒体平台上的真实问题场景中收集和清理的,用作种子数据集,并使用自学技术进行扩展, 标注成本约为900美元 。与其他自学方法生成的数据集相比,该数据集包含了更真实、更多样的种子数据,并涵盖了更广泛的主题。该数据集适用于微调和RLHF训练。通过提供高质量的数据,ColossalChat可以实现更好的对话互动,也可以支持中文。
[{
"instruction": "请讲解如何缓解上班族病的症状。",
"input": "",
"output": "一种有效的缓解上班族病的症状方法是出去散步,每天晚上可以花几个小时去散步,减少坐姿固定的时间,放松肩痛、腰痛和背部综合症的发作。另外,可以试着利用午休时间或者其他空余时间锻炼一下,比如慢跑,打太极拳等,帮助舒缓,运动释放时也可以练习深呼吸,这能帮助消除压力,更有利于解除病症。",
"id": 0
"instruction": "描述一下优质的客户关系管理模式。",
"input": "",
"output": "优质的客户关系管理模式是指,通过建立客户之间的关系,建立并提供优质的服务,将客户的满意度转变为重复购买概念。这种模式强调人性化服务,以及知识和技能的结合,建立关系是一种长期的过程,而且可以建立起客户的忠诚度和口碑好评。该模式还可以培养客户之间的信任关系,增强客户感受到优质服务的同时,建立起长期客户风险防范机制,以及客户满意度机制,使企业拥有稳定、可持续和良好的客户关系管理能力。",
"id": 1
"instruction": "如果你要在你的城市建造一座新图书馆,你会考虑哪些因素,例如地点、设计和设施?",
"input": "",
"output": "如果要在城市建立一座新图书馆,首先需要考虑其地理位置,以及图书馆所在社区的需求状况,这样才能保证图书馆的功能能够有效地发挥出来。此外,需要考虑的还有当地特色,如地形、气候、文化等,以及周边的交通状况,可以考虑把新图书馆放在通勤方便的位置。最后是设计和设施的考量,应该根据预期使用用户的需求,把简洁的外观设计和时尚的设施结合在一起,以及图书馆有利的环境,来提高职能,建造现代化的图书馆。",
"id": 2
https:// github.com/tatsu-lab/st anford_alpaca/blob/main/alpaca_data.json
https:// github.com/XueFuzhao/In structionWild/tree/main/data
中文(instinwild_ch.json) : https:// drive.google.com/file/d /1OqfOUWYfrK6riE9erOx-Izp3nItfqz_K/view
英文(instinwild_en.json) : https:// drive.google.com/file/d /1qOfrl0RIWgH2_b1rYCEVxjHF3u3Dwqay/view
如果下载不了可以公众号【 小虎AI珏爷 】回复 【 ChatGPT】 获取
3 RLHF算法实现
底座语言模型:
LLAMA底座模型下载 :
https:// ipfs.io/ipfs/Qmb9y5GCkT G7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
LLAMA底座模型下载(Hugging Face) :
https://www. 123pan.com/s/Su8ZVv-g97 q3.html 提取码:xgOP
decapoda-research/llama-7b-hf · Hugging Face
decapoda-research/llama-30b-hf · Hugging Face
https:// huggingface.co/decapoda -research/llama-65b-hf
https:// huggingface.co/decapoda -research/llama-13b-hf
Bloomz-7b底座模型下载(Hugging Face) :
开源中文对话大模型 BELLE(Bloom-Enhanced Large Language model Engine)基于斯坦福的 Alpaca。
bigscience/bloomz-7b1-mt at main
RLHF实现包括三个阶段。
3.1 步骤一:指令微调
阶段一:使用前面提到的数据集执行有监督指令微调,以微调模型。
加载语言模型,并使用lora微调
def convert_to_lora_recursively(module: nn.Module, lora_rank: int) -> None:
for name, child in module.named_children():
if isinstance(child, nn.Linear):
setattr(module, name, lora_linear_wrapper(child, lora_rank))
else:
convert_to_lora_recursively(child, lora_rank)
运行 examples/train_sft.sh 来启动 有监督的指令微调 。
使用4-GPU 训练。
torchrun --standalone --nproc_per_node=4 train_sft.py \
--pretrain "/path/to/LLaMa-7B/" \
--model 'llama' \
--strategy colossalai_zero2 \
--log_interval 10 \
--save_path /path/to/Coati-7B \
--dataset "yizhongw/self_instruct" \
--batch_size 4 \
--accimulation_steps 8 \
--lr 2e-5 \
--max_datasets_size 512 \
--max_epochs 1 \
3.2 步骤二:训练奖励模型
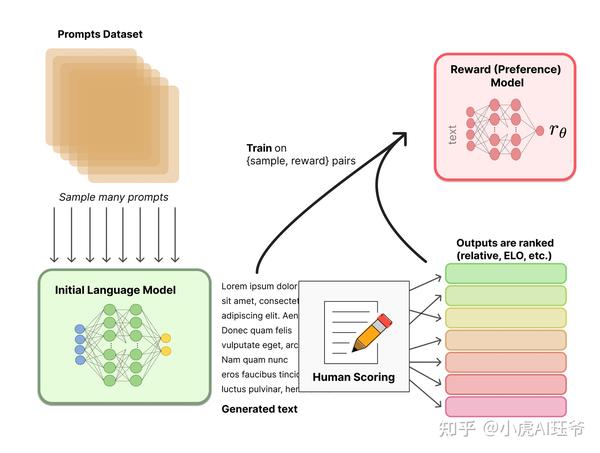
阶段二:训练奖励模型,通过手动对同一提示的不同输出进行排序来分配相应的分数,然后有监督奖励模型的训练。

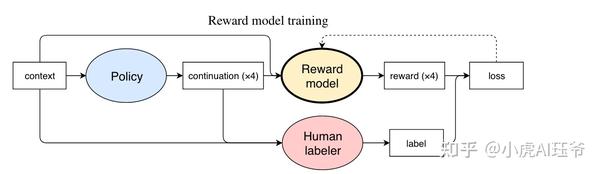
排序数据集: Dahoas/rm-static · Datasets at Hugging Face
Pairwise Loss :
小虎AI珏爷:OpenAI ChatGPT前身-InstructGPT:训练语言模型,使其能够根据人的反馈来执行指令
class LogSigLoss(nn.Module):
Pairwise Loss for Reward Model
Details: https://arxiv.org/abs/2203.02155
def forward(self, chosen_reward: torch.Tensor, reject_reward: torch.Tensor) -> torch.Tensor:
probs = torch.sigmoid(chosen_reward - reject_reward)
log_probs = torch.log(probs)
loss = -log_probs.mean()
return loss
class RewardModel(LoRAModule):
def forward(self, sequences: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
outputs = self.model(sequences, attention_mask=attention_mask)
last_hidden_states = outputs['last_hidden_state']
values = self.value_head(last_hidden_states)[:, :-1]
value = values.mean(dim=1).squeeze(1) # ensure shape is (B)
return value
运行examples/train_rm.sh 开始奖励模型训练。
使用4-GPU 训练。
torchrun --standalone --nproc_per_node=4 train_reward_model.py
--pretrain "/path/to/Coati-7B" \
--model 'llama' \
--dataset 'Dahoas/rm-static'
--strategy colossalai_zero2 \
--loss_fn 'log_exp'\
--save_path '/path/to/rmstatic.pt' \
3.3 步骤三人类反馈强化学习
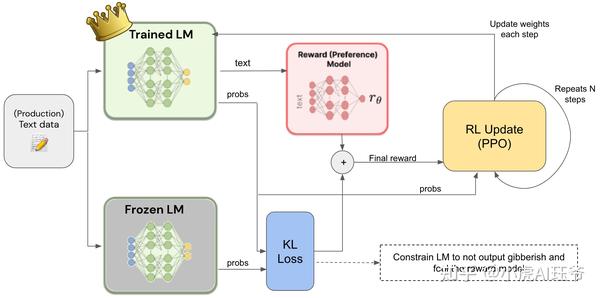
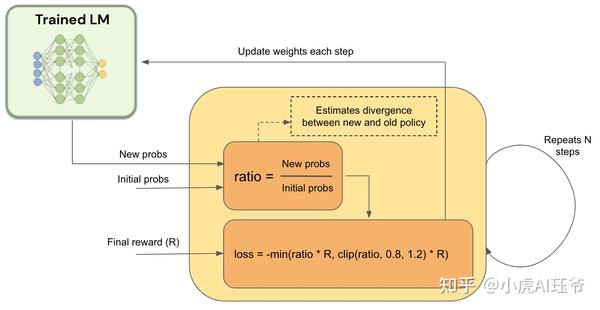
阶段三:人类反馈强化学习。 在第一阶段的监督微调模型和第二阶段的奖励模型的基础上,使用强化学习算法进一步训练大型语言模型。该阶段是RLHF训练的核心部分,在强化学习中使用近端策略优化(PPO)算法来引入奖励信号,并生成更符合人类偏好的内容。
此步骤的目标是使用奖励模型提供的奖励来训练主模型,即您训练的LM。然而,由于奖励是不可微分的,需要使用RL来构造我们可以反向传播到LM的损失。
class Actor(LoRAModule):
def forward(self,
sequences: torch.LongTensor,
num_actions: int,
attention_mask
: Optional[torch.Tensor] = None) -> torch.Tensor:
"""Returns action log probs
output = self.model(sequences, attention_mask=attention_mask)
logits = output['logits']
log_probs = log_probs_from_logits(logits[:, :-1, :], sequences[:, 1:])
return log_probs[:, -num_actions:]
class Critic(LoRAModule):
def forward(self,
sequences: torch.LongTensor,
action_mask: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
outputs = self.model(sequences, attention_mask=attention_mask)
last_hidden_states = outputs['last_hidden_state']
values = self.value_head(last_hidden_states).squeeze(-1)
if action_mask is not None and self.use_action_mask:
num_actions = action_mask.size(1)
prompt_mask = attention_mask[:, :-num_actions]
values = values[:, :-num_actions]
value = masked_mean(values, prompt_mask, dim=1)
return value
values = values[:, :-1]
value = values.mean(dim=1)
return value
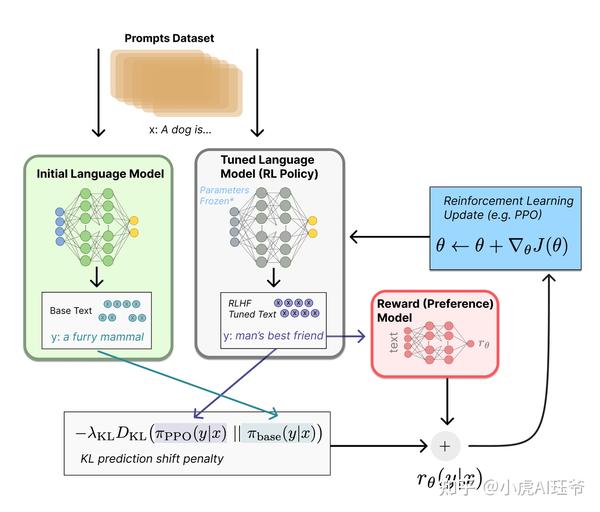
运行examples/train_prompts.sh,开始使用人类反馈训练PPO。
使用8-GPU进行训练。
torchrun --standalone --nproc_per_node=4 train_prompts.py \
--pretrain "/path/to/Coati-7B" \
--model 'llama' \
--strategy colossalai_zero2 \
--prompt_path /path/to/your/instinwild_ch.json \
--pretrain_dataset /path/to/gpt3_finetuning_data.jsonl \
--rm_pretrain "/path/to/Coati-7B" \
--rm_path "/path/to/rmstatic.pt"
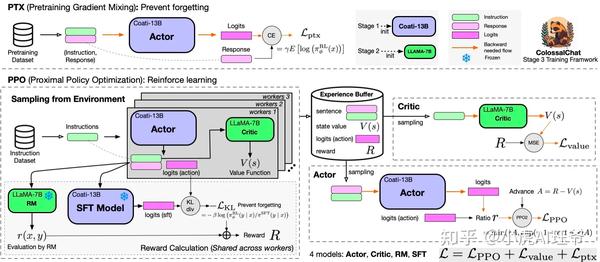
在 PPO 部分,ColossalChat遵循两个阶段的过程:首先,构造实验阶段,它使用SFT(有监督微调)、Actor、RM(奖励模型)和Critic模型来计算生成的实验并将其存储在经验回放缓冲区中。然后是参数更新阶段,使用经验计算策略损失和价值损失。
在PTX部分,ColossalChat计算Actor的输出响应和输入语料库的响应部分之间的 交叉熵损失 。这种损失用于将预训练梯度添加到PPO梯度中,以保持语言模型的原始性能并防止遗忘。最后,总结了 策略损失 、 价值损失 和 PTX损失 ,用于反向传播和参数更新。
4 推理
8位量化推理。
from transformers import LlamaForCausalLM
USE_8BIT = True # use 8-bit quantization; otherwise, use fp16
model = LlamaForCausalLM.from_pretrained(
"pretrained/path",
load_in_8bit=USE_8BIT,
torch_dtype=torch.float16,
device_map="auto",
if not USE_8BIT:
model.half() # use fp16
model.eval()
python server.py /path/to/pretrained — quant 4bit — gptq_checkpoint /path/to/coati-7b-4bit-128g.pt — gptq_group_size 128
低成本量化推理, 为了降低推理部署成本,Colossal AI使用GPTQ 4位量化推理。在GPT/OPT/BLOM模型上,它可以获得比传统RTN(四舍五入)量化技术更好的困惑度结果。与普通的FP16推理相比,它可以减少75%的内存消耗,同时只牺牲少量的吞吐速度和困惑度性能。
对于ColossalChat-7B,使用4位量化推理,70亿参数模型只需要大约 4GB的GPU内存 就可以完成短序列(128长度的生成)推理,这可以在普通消费级GPU上完成,比如 RTX 3060 。
CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt5 局限性
- LLaMA微调模型的限制Alpaca和ColossalChat都基于LLaMA。在预训练阶段,很难弥补缺失的知识。
- 缺乏计数能力:无法计数列表中的项目数。
- 缺乏逻辑(推理和计算)倾向于重复最后一句话(无法产生结束语)。
- 多语言效果不佳:LLaMA主要在英语数据集上进行训练(Generation比QA表现更好)。
- 缺乏摘要能力:在微调数据集中没有这样的指令。
- 缺乏多回合聊天:微调数据集中没有这样的指令缺乏自我识别:微调数据集中没有这样的指示缺乏安全性。
- 当输入包含虚假事实时,模型会编造虚假事实和解释。
6 样例
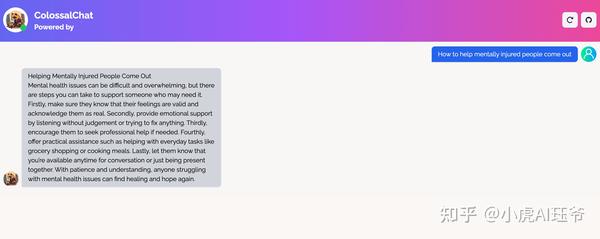
6.1 情感
How to help mentally injured people come out?
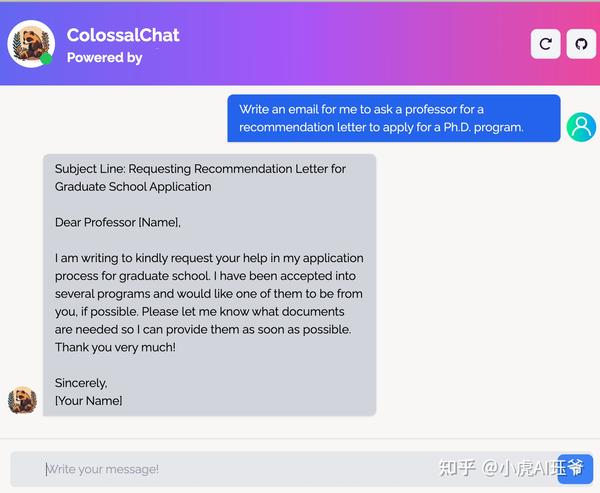
6.2 写邮件
6.3 写代码
6.4 开放式问答
7 资源需求
ChatGPT资源需求。 由于引入了强化学习,ChatGPT模型的复杂性导致了许多模型调用。例如,当使用具有PPO算法的Actor Critic(AC)结构时,必须对Actor和Critic模型进行正向推理和反向传播,以及在训练期间对监督微调模型和奖励模型进行多次正向推理。Actor和监督微调模型都使用具有1750亿参数的GPT-3系列模型,而Critic和奖励模型使用具有60亿参数的GPT-3系列模型。
启动最初的ChatGPT训练过程需要 数千GB的GPU内存 ,这远远超出了单个GPU甚至常见数据并行技术的容量。即使在分区参数中引入了张量并行和流水线并行,仍然需要至少 64个80GB A100 GPU作为硬件基础 。此外,由于流水线的复杂性和效率,它不适合AIGC的生成任务,这使得ChatGPT训练过程的代码复制更加困难和具有挑战性。
使用Colossal AI优化类似ChatGPT的训练:硬件节省50%,速度提高7.73倍 。Colossal AI通过利用先进的内存管理技术,减少了类似ChatGPT训练的GPU内存开销。它只需要一半的硬件资源就可以开始训练1750亿个参数模型,从而为ChatGPT类型的应用程序节省了大量成本。在相同的硬件资源下,Colossal AI能够在更短的时间内完成训练,降低训练成本,加快产品迭代。
Colossal AI支持ZeRO(零冗余优化器)来提高内存使用效率 ,使更大的模型能够以更低的成本被容纳,而不会影响计算粒度和通信效率。自动组块机制可以通过提高内存使用效率、降低通信频率和避免内存碎片来进一步提高ZeRO的性能。异构内存空间管理器Gemini支持将优化器状态从GPU内存卸载到CPU内存或硬盘空间,以克服GPU内存容量的限制,扩大可训练模型的规模,降低大型AI模型应用的成本。
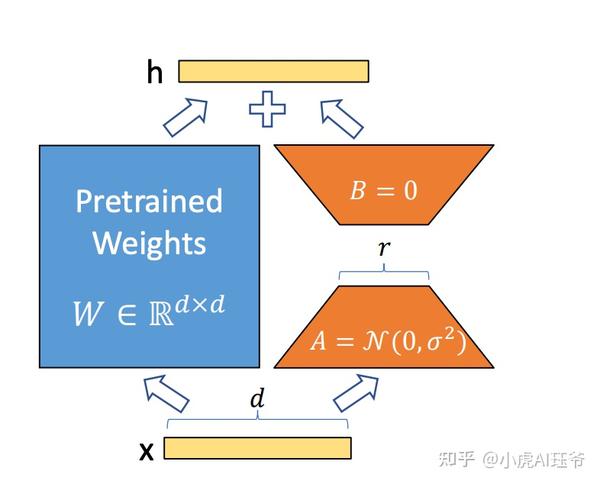
Colossal AI包括低秩自适应(LoRA)方法 ,用于对大型模型进行低成本微调。 LoRA 方法假设大型语言模型过度参数化,并且微调期间的参数变化是低秩矩阵。因此,这个矩阵可以分解为两个较小矩阵的乘积。在微调过程中,大模型的参数是固定的,只调整低秩矩阵的参数,显著减少了训练所需的参数数量,降低了成本。
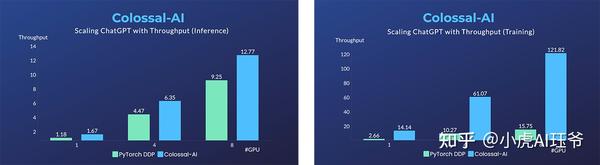
在单个多GPU服务器上,即使使用最高端的A100 80GB GPU,由于ChatGPT进程的复杂性和内存碎片,PyTorch也只能使用GPT-L(774M)等小型模型启动ChatGPT。因此,使用PyTorch的DistributedDataParallel(DDP)最多可扩展到4或8个GPU,性能提升有限。
Colossal AI不仅为单GPU训练提供了显著的速度和效率提高,而且随着并行度的提高,还可以进一步提高。单服务器训练速度快7.73倍,单GPU推理速度快1.42倍,并且可以继续扩展到大规模并行,降低了复制ChatGPT的成本。
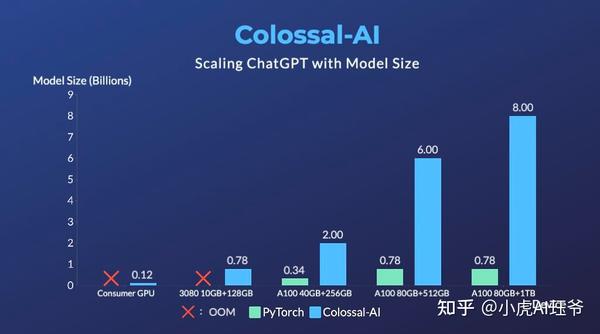
为了最大限度地降低训练成本并提高易用性,Colossal AI提供了类似ChatGPT的单一GPU版本的训练过程。PyTorch在售价14999美元的A100 80GB GPU上只能启动参数高达7.8亿的模型,相比之下,Colossal AI将单个GPU的容量提高了10.3倍,达到80亿个参数。为了复制基于具有1.2亿个参数的小型模型的ChatGPT训练,需要至少1.62GB的GPU内存,这在任何消费者级GPU上都很容易获得。
PyTorch和Colossal AI在各种设备上的吞吐量比较如下表所示,启动设备是配备10GB GPU内存和128GB CPU内存的NVIDIA GeForce RTX 3080显卡。
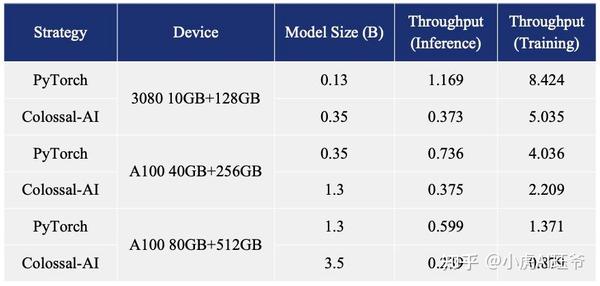
此外,Colossal AI正在不断努力降低基于预训练的大型模型微调任务的成本。例如,对于与ChatGPT OPT模型相关的微调任务,与PyTorch相比,Colossal AI能够将单个GPU上的微调模型容量提高3.7倍,同时保持高速。
8 代码
https:// github.com/hpcaitech/Co lossalAI/tree/main/applications/Chat/coati
8.1 Actor
from typing import Optional, Tuple, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
from ..generation import generate
from ..lora import LoRAModule
from ..utils import log_probs_from_logits
class Actor(LoRAModule):
Actor model base class.
Args:
model (nn.Module): Actor Model.
lora_rank (int): LoRA rank.
lora_train_bias (str): LoRA bias training mode.
def __init__(self, model: nn.Module, lora_rank: int = 0, lora_train_bias: str = 'none') -> None:
super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
self.model = model
self.convert_to_lora()
@torch.no_grad()
def generate(
self,
input_ids: torch.Tensor,
return_action_mask: bool = True,
**kwargs
) -> Union[Tuple[torch.LongTensor, torch.LongTensor], Tuple[torch.LongTensor, torch.LongTensor, torch.BoolTensor]]:
sequences = generate(self.model, input_ids, **kwargs)
attention_mask = None
pad_token_id = kwargs.get('pad_token_id', None)
if pad_token_id is not None:
attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
if not return_action_mask:
return sequences, attention_mask, None
input_len = input_ids.size(1)
eos_token_id = kwargs.get('eos_token_id', None)
if eos_token_id is None:
action_mask = torch.ones_like(sequences, dtype=torch.bool)
else:
# left padding may be applied, only mask action
action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
action_mask[:, :input_len] = False
action_mask = action_mask[:, 1:]
return sequences, attention_mask, action_mask[:, -(sequences.size(1) - input_len):]
def forward(self,
sequences: torch.LongTensor,
num_actions: int,
attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
"""Returns action log probs
output = self.model(sequences, attention_mask=attention_mask)
logits = output['logits']
log_probs = log_probs_from_logits(logits[:, :-1, :], sequences[:, 1:])
return log_probs[:, -num_actions:]
def get_base_model(self):
return self.model
class LlamaActor(Actor):
Llama Actor
model.
Args:
pretrained (str): Pretrained model name or path.
config (LlamaConfig): Model config.
checkpoint (bool): Enable gradient checkpointing.
lora_rank (int): LoRA rank.
lora_train_bias (str): LoRA bias training mode.
def __init__(self,
pretrained: Optional[str] = None,
config: Optional[LlamaConfig] = None,
checkpoint: bool = False,
lora_rank: int = 0,
lora_train_bias: str = 'none') -> None:
if pretrained is not None:
model = LlamaForCausalLM.from_pretrained(pretrained)
elif config is not None:
model = LlamaForCausalLM(config)
else:
model = LlamaForCausalLM(LlamaConfig())
if checkpoint:
model.gradient_checkpointing_enable()
super().__init__(model, lora_rank, lora_train_bias)
8.2 Critic
from typing import Optional
import torch
import torch.nn as nn
from ..lora import LoRAModule
from ..utils import masked_mean
class Critic(LoRAModule):
Critic model base class.
Args:
model (nn.Module): Critic model.
value_head (nn.Module): Value head to get value.
lora_rank (int): LoRA rank.
lora_train_bias (str): LoRA bias training mode.
def __init__(
self,
model: nn.Module,
value_head: nn.Module,
lora_rank: int = 0,
lora_train_bias: str = 'none',
use_action_mask: bool = False,
) -> None:
super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
self.model = model
self.value_head = value_head
self.use_action_mask = use_action_mask
self.convert_to_lora()
def forward(self,
sequences: torch.LongTensor,
action_mask: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
outputs = self.model(sequences, attention_mask=attention_mask)
last_hidden_states = outputs['last_hidden_state']
values = self.value_head(last_hidden_states).squeeze(-1)
if action_mask is not None and self.use_action_mask:
num_actions = action_mask.size(1)
prompt_mask = attention_mask[:, :-num_actions]
values = values[:, :-num_actions]
value = masked_mean(values, prompt_mask, dim=1)
return value
values = values[:, :-1]
value = values.mean(dim=1)
return value
class LlamaCritic(Critic):
Llama Critic model.
Args:
pretrained (str): Pretrained model name or path.
config (LlamaConfig): Model config.
checkpoint (bool): Enable gradient checkpointing.
lora_rank (int): LoRA rank.
lora_train_bias (str): LoRA bias training mode.
def __init__(self,
pretrained: Optional[str] = None,
config: Optional[LlamaConfig] = None,
checkpoint: bool = False,
lora_rank: int = 0,
lora_train_bias: str = 'none',
**kwargs) -> None:
if pretrained is not None:
model = LlamaForCausalLM.from_pretrained(pretrained)
elif config is not None:
model = LlamaForCausalLM(config)
else:
model = LlamaForCausalLM(LlamaConfig())
if checkpoint:
model.gradient_checkpointing_enable()
value_head = nn.Linear(model.config.hidden_size, 1)
super().__init__(model, value_head, lora_rank, lora_train_bias, **kwargs)
8.3 Reward
from typing import Optional
import torch
import torch.nn as nn
from ..lora import LoRAModule
class RewardModel(LoRAModule)
:
Reward model base class.
Args:
model (nn.Module): Reward model.
value_head (nn.Module): Value head to get reward score.
lora_rank (int): LoRA rank.
lora_train_bias (str): LoRA bias training mode.
def __init__(self,
model: nn.Module,
value_head: Optional[nn.Module] = None,
lora_rank: int = 0,
lora_train_bias: str = 'none') -> None:
super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
self.model = model
self.convert_to_lora()
if value_head is not None:
if value_head.out_features != 1:
raise ValueError("The value head of reward model's output dim should be 1!")
self.value_head = value_head
else:
self.value_head = nn.Linear(model.config.n_embd, 1)
def forward(self, sequences: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
outputs = self.model(sequences, attention_mask=attention_mask)
last_hidden_states = outputs['last_hidden_state']
values = self.value_head(last_hidden_states)[:, :-1]
value = values.mean(dim=1).squeeze(1) # ensure shape is (B)
return value
class LlamaRM(RewardModel):
Llama Reward model.
Args:
pretrained (str): Pretrained model name or path.
config (LlamaConfig): Model config.
checkpoint (bool): Enable gradient checkpointing.
lora_rank (int): LoRA rank.
lora_train_bias (str): LoRA bias training mode.
def __init__(self,
pretrained: Optional[str] = None,
config: Optional[LlamaConfig] = None,
checkpoint: bool = False,
lora_rank: int = 0,
lora_train_bias: str = 'none') -> None:
if pretrained is not None:
model = LlamaModel.from_pretrained(pretrained)
elif config is not None:
model = LlamaModel(config)
else:
model = LlamaModel(LlamaConfig())
if checkpoint:
model.gradient_checkpointing_enable()
value_head = nn.Linear(model.config.hidden_size, 1)
value_head.weight.data.normal_(mean=0.0, std=1 / (model.config.hidden_size + 1))
super().__init__(model, value_head, lora_rank, lora_train_bias)
# This software may be used and distributed according to the terms of the GNU General Public License version 3.
from typing import Optional, Tuple
from dataclasses import dataclass
import math
import torch
from torch import nn
import torch.nn.functional as F
import fairscale.nn.model_parallel.initialize as fs_init
from fairscale.nn.model_parallel.layers import (
ParallelEmbedding,
RowParallelLinear,
ColumnParallelLinear,
@dataclass
class ModelArgs:
dim: int = 512
n_layers: int = 8
n_heads: int = 8
vocab_size: int = -1 # defined later by tokenizer
multiple_of: int = 256 # make SwiGLU hidden layer size multiple of large power of 2
norm_eps: float = 1e-5
max_batch_size: int = 32
max_seq_len: int = 2048
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
def precompute_freqs_cis(dim
: int, end: int, theta: float = 10000.0):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # type: ignore
freqs = torch.outer(t, freqs).float() # type: ignore
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size()
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
self.wk = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
self.wv = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
self.cache_k = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k
[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
#计算未归一化的注意力分数
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, slen, cache_len + slen)
#计算归一化的注意力分数
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
#将V使用注意力分数加权获得输出表示
output = torch.matmul(scores, values) # (bs, n_local_heads, slen, head_dim)
output = output.transpose(
1, 2
).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
self.freqs_cis =
precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h[:, -1, :]) # only compute last logits
return output.float()
from typing import Optional, Tuple, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
from ..generation import generate
from .actor import Actor
class LM(Actor):
Language model base class.
Args:
model (nn.Module): Language Model.
lora_rank (int): LoRA rank.
lora_train_bias (str): LoRA bias training mode.
def __init__(self, model: nn.Module, lora_rank: int = 0, lora_train_bias: str = 'none') -> None:
super().__init__(model=model, lora_rank=lora_rank, lora_train_bias=lora_train_bias)
def forward(self, sequences: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
"""Returns output log probs
output = self.model(sequences, attention_mask=attention_mask)
logits = output['logits']
log_probs = F.log_softmax(logits, dim=-1)
return log_probs
8.5 PPO
from typing import Any, Callable, Dict, List, Optional
import torch
import torch.nn as nn
from coati.experience_maker import Experience, NaiveExperienceMaker
from coati.models.base import Actor, Critic
from coati.models.generation_utils import update_model_kwargs_fn
from coati.models.loss import PolicyLoss, ValueLoss
from coati.replay_buffer import NaiveReplayBuffer
from torch.optim import Optimizer
from transformers.tokenization_utils_base import PreTrainedTokenizerBase
from .base import Trainer
from .callbacks import Callback
from .strategies import Strategy
class PPOTrainer(Trainer):
Trainer for PPO algorithm.
Args:
strategy (Strategy): the strategy to use for training
actor (Actor): the actor model in ppo algorithm
critic (Critic): the critic model in ppo algorithm
reward_model (nn.Module): the reward model in rlhf algorithm to make reward of sentences
initial_model (Actor): the initial model in rlhf algorithm to generate reference logits to limit the update of actor
actor_optim (Optimizer): the optimizer to use for actor model
critic_optim (Optimizer): the optimizer to use for critic model
kl_coef (float, defaults to 0.1): the coefficient of kl divergence loss
train_batch_size (int, defaults to 8): the batch size to use for training
buffer_limit (int, defaults to 0): the max_size limitaiton of replay buffer
buffer_cpu_offload (bool, defaults to True): whether to offload replay buffer to cpu
eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
value_clip (float, defaults to 0.4): the clip coefficient of value loss
experience_batch_size (int, defaults
to 8): the batch size to use for experience generation
max_epochs (int, defaults to 1): the number of epochs of training process
tokenier (Callable, optional): the tokenizer to use for tokenizing the input
sample_replay_buffer (bool, defaults to False): whether to sample from replay buffer
dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
callbacks (List[Callback], defaults to []): the callbacks to call during training process
generate_kwargs (dict, optional): the kwargs to use while model generating
def __init__(self,
strategy: Strategy,
actor: Actor,
critic: Critic,
reward_model: nn.Module,
initial_model: Actor,
actor_optim: Optimizer,
critic_optim: Optimizer,
kl_coef: float = 0.1,
ptx_coef: float = 0.9,
train_batch_size: int = 8,
buffer_limit: int = 0,
buffer_cpu_offload: bool = True,
eps_clip: float = 0.2,
value_clip: float = 0.4,
experience_batch_size: int = 8,
max_epochs: int = 1,
tokenizer: Optional[Callable[[Any], dict]] = None,
sample_replay_buffer: bool = False,
dataloader_pin_memory: bool = True,
callbacks: List[Callback] = [],
**generate_kwargs) -> None:
experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, kl_coef)
replay_buffer = NaiveReplayBuffer(train_batch_size, buffer_limit, buffer_cpu_offload)
generate_kwargs = _set_default_generate_kwargs(strategy, generate_kwargs, actor)
super().__init__(strategy, experience_maker, replay_buffer, experience_batch_size, max_epochs, tokenizer,
sample_replay_buffer, dataloader_pin_memory, callbacks, **generate_kwargs)
self.actor = actor
self.critic = critic
self.actor_loss_fn = PolicyLoss(eps_clip)
self.critic_loss_fn = ValueLoss(value_clip)
self.ptx_loss_fn = nn.CrossEntropyLoss(ignore_index=-100)
self.ptx_coef = ptx_coef
self.actor_optim = actor_optim
self.critic_optim = critic_optim
def training_step(self, experience: Experience) -> Dict[str, float]:
self.actor.train()
self.critic.train()
# policy loss
num_actions = experience.action_mask.size(1)
action_log_probs = self.actor(experience.sequences, num_actions, attention_mask=experience.attention_mask)
actor_loss = self.actor_loss_fn(action_log_probs,
experience.action_log_probs,
experience.advantages,
action_mask=experience.action_mask)
# ptx loss
if self.ptx_coef != 0:
ptx = next(iter(self.pretrain_dataloader))['input_ids'].to(torch.cuda.current_device())
label = next(iter(self.pretrain_dataloader))['labels'].to(torch.cuda.current_device())[:, 1:]
attention_mask = next(iter(self.pretrain_dataloader))['attention_mask'].to(torch.cuda.current_device())
ptx_log_probs = self.actor.get_base_model()(ptx, attention_mask=attention_mask)['logits'][..., :-1, :]
ptx_loss = self.ptx_loss_fn(ptx_log_probs.view(-1, ptx_log_probs.size(-1)), label.view(-1))
actor_loss = ptx_loss * self.ptx_coef + actor_loss * (1 - self.ptx_coef)
self.strategy.backward(actor_loss, self.actor, self.actor_optim)
self.strategy.optimizer_step(self.actor_optim)
self.actor_optim.zero_grad()
# value loss
values = self.critic(experience.sequences,
action_mask=experience.action_mask,
attention_mask=experience.attention_mask)
critic_loss = self.critic_loss_fn(values,
experience.values,
experience.reward,
action_mask=experience.action_mask)
self.strategy.backward(critic_loss, self.critic, self.critic_optim)
self.strategy.optimizer_step(self.critic_optim)
self.critic_optim.zero_grad()
return {'reward': experience.reward.mean().item()}
def _set_default_generate_kwargs(strategy: Strategy, generate_kwargs: dict, actor: Actor) -> None:
origin_model = strategy._unwrap_actor(actor)
new_kwargs = {**generate_kwargs}
# use huggingface models method directly
if 'prepare_inputs_fn' not in generate_kwargs and hasattr(origin_model, 'prepare_inputs_for_generation'):
new_kwargs['prepare_inputs_fn'] = origin_model.prepare_inputs_for_generation
if 'update_model_kwargs_fn' not in generate_kwargs:
new_kwargs['update_model_kwargs_fn'] = update_model_kwargs_fn
return new_kwargs
def save_model(self, path: str, only_rank0: bool = False, tokenizer: Optional[PreTrainedTokenizerBase] = None) -> None:
self.strategy.save_model(model=self.actor, path=path, only_rank0=only_rank0, tokenizer=tokenizer)
https://www. hpc-ai.tech/blog/coloss al-ai-chatgpt