

使用类的继承实现多个MySQL连接泄以及相关操作说明

承接上文
本文是在上一篇文章内容的基础上的拓展: MySQL连接池DBUtils与线程池ThreadPoolExecutor的结合使用实例
需求拓展说明
上一篇文章实现的是一个数据库db的连接池的操作,但是在实际的业务场景中我们很可能在同一段业务代码中使用多个数据库db,如果只实现了一个数据库连接池,那么其他的db还是存在多次创建链接及拆除链接损耗的问题。
笔者在上文的基础上做了一下优化拓展,可以在同一段逻辑代码中使用多个数据库db的连接池。
实现说明
完整的代码建议大家从上面的文章中找出来并亲自实现一下,这里只描述核心的问题。
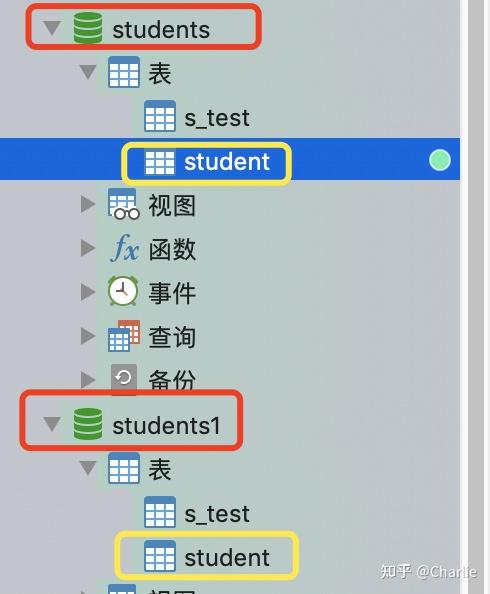
创建2个测试db
这里我创建了2个测试的db,作为2个连接池使用:

连接池的配置
# -*- coding:utf-8 -*-
# MySQL连接池的配置
MySQLS = {
'students': {
"maxconnections": 0, # 连接池允许的最大连接数,0和None表示不限制连接数
"mincached": 2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
"maxcached": 0, # 链接池中最多闲置的链接,0和None不限制
"maxusage": 1, # 一个链接最多被重复使用的次数,None表示无限制
"blocking": True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
'host': '127.0.0.1',
'user': 'root',
'password': '123',
'db': 'students',
'port': 3306,
'charset': 'utf8',
'students1': {
"maxconnections": 0,
"mincached": 2,
"maxcached": 0,
"maxusage": 1,
"blocking": True,
'host': '127.0.0.1',
'user': 'root',
'password': '123',
'db': 'students1',
'port': 3306,
'charset': 'utf8',
db_conn.py中多个连接池的实现
# -*- coding:utf-8 -*-
import pymysql
import logging
import traceback
from config import MySQLS
from DBUtils.PooledDB import PooledDB
# 获取MySQL连接池的配置
# students数据库连接池的配置
students_pool_config = MySQLS["students"]
# students1数据库连接池的配置
students1_pool_config = MySQLS["students1"]
### 多个MySQL连接池的实现
class MySQLPoolBase(object):
# with上下文
def __enter__(self):
self.conn = self.pool.connection()
self.cursor = self.conn.cursor(cursor=pymysql.cursors.DictCursor)
return self
def __exit__(self, exc_type, exc_val, exc_tb):
# 关闭连接池
self.cursor.close()
self.conn.close()
# 插入或修改操作
def insert_or_update(self, sql):
self.cursor.execute(sql)
self.conn.commit()
return 1
except Exception as error:
print(traceback.format_exc())
self.conn.rollback()
# 简单的日志处理
logging.error("=======ERROR=======\n%s\nsql:%s" % (error, sql))
raise
# 查询操作
def query(self, sql):
self.cursor.execute(sql)
results = self.cursor.fetchall()
return results
except Exception as error:
# 简单的日志处理
logging.error("=======ERROR=======:\n%s\nsql:%s" % (error, sql))
raise
# 子类1 students
class StudentsPool(MySQLPoolBase):
# 类变量
pool = PooledDB(creator=pymysql,**students_pool_config)
# 子类2 students1
class Students1Pool(MySQLPoolBase):
# 类变量
pool = PooledDB(pymysql,**students1_pool_config)
在同一段业务代码中使用多个连接池
这里使用了with语句支持的简洁的方法:
def change_db(class_id):
# 在这里面使用MySQL的连接池
# 多个连接池一起使用!
with StudentsPool() as students_pool, Students1Pool() as s1_pool:
# 这里每个对象使用的连接池都与类中的连接池一样!说明所有的线程池使用的是同一个MySQL的连接池!
print("students_pool_id>>>",id(students_pool.pool))
print("s1_pool_id>>>>>",id(s1_pool.pool))
线程池的使用
# -*- coding:utf-8 -*-
import time
from multiprocessing import Pool
from concurrent.futures import ThreadPoolExecutor,wait,as_completed
from utils import change_db
### 主函数
def main_func():
# class_id_lst = ["01","02","03","04","05","12","13","14","15"]
class_id_lst = ["01","02","03","04","05"]
start = time.time()
## 2、线程池 + MySQL连接池
executor = ThreadPoolExecutor(max_workers=3)
# class_id 是参数
all_tasks = [executor.submit(change_db,class_id) for class_id in class_id_lst]
## 获取返回值 ———— 本例不用获取返回值
for future in as_completed(all_tasks):
data = future.result()
print("线程池耗时:{}".format(time.time() - start))
if __name__ == '__main__':
main_func()
看一下业务代码中打印的类对象中连接池的id
我们可以看到: 相同连接池类实例化对象中使用的是同一个pool (这就是pool必须是类变量的原因!),验证完毕。
students_pool_id>>> 4506440088
s1_pool_id>>>>> 4509501032
students_pool_id>>> 4506440088
s1_pool_id>>>>> 4509501032
students_pool_id>>> 4506440088