


【爬虫最全实战&动漫迷福利】动漫之家高清原图爬虫


项目地址: QuantumLiu/ComicSpider
提供双语文档。
动机
技术层面:
爬虫时大数据时代的利器,需求量极大。以个人经验,外包活20%是爬虫相关。熟练掌握爬虫技术意义不言而喻。
网上Python爬虫教程不少,我也写过一些 世界那么大我想写代码 ,还有一两篇存稿。
然而这些教程虽然不乏优秀之作,但是很少有介绍 从调研需求到编写爬虫逻辑再到包装为程序、编写GUI、发布exe文件的完整过程。
本文较为详细的叙述了一个班级完整的爬虫项目的开发过程 ,希望对各位开发者有借鉴、补充的意义。
实际需求:
本人DC粉,偏爱美漫,平时主要在 动漫之家 看各位汉化大佬翻译的熟肉。
动漫之家有手机APP,十分方便,还支持离线下载。但是APP版的漫画都是经过压缩的非高清图片,很多小字看不清楚,影响阅读体验。抱着笔记本或者平板在北京一号线上看漫画又不现实。于是我想能不能写一个爬虫把漫画爬到本地,在平板或者手机图库里直接看。
目录:
- 简介
- 使用
- GUI版本
- 使用源码
- 使用二进制
- 命令行版本
- 使用源码
- 使用二进制
- 编程实现
- 已有项目
- 难点分析与解决思路
- 目标网页分析
- 面向对象的多线程爬虫
- 基于PyQt的GUI爬虫
- 使用pyinstaller打包发布exe程序
- 总结
把使用写在前面,后面是编程实现
简介
第一个从 动漫之家 漫画站爬取电脑版原图的开源爬虫。使用 PhantomJS ,和 selenuium 获取每个漫画章节的分页索引。爬取并下载漫画图片到本地文件。
爬虫逻辑实现在comic.py,功能完整,支持增量下载,可供开发者自行开发爬虫。提供双语文档。
提供命令行download_f.py和图形界面comic_gui.py两种爬虫程序。
提供打包好的win32/64 .exe程序。
运行结果:
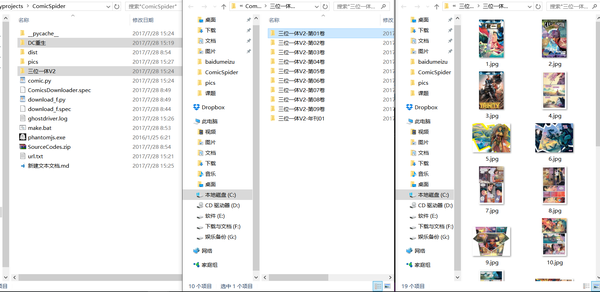

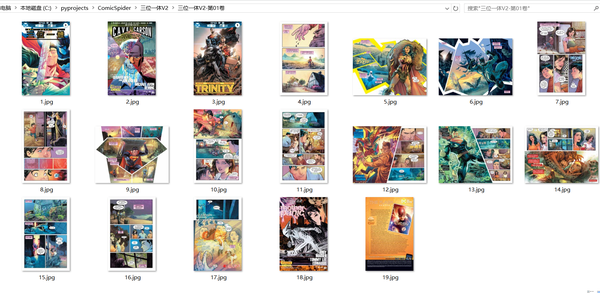

使用
安装依赖 。
在命令行cmd或终端:
git clone
https://
github.com/QuantumLiu/C
omicSpider.git
下载
PhantomJS
, 解压并将phantomjs.exe文件放在.py文件的同一个文件夹。或者把phantomjs.exe所在路径添加到环境变量PATH。
如果需要使用二进制文件 (Windows),请下载最新的
releases
.
GUI版本:
使用源码:
python comic_gui.py
或双击comic_gui.exe
输入你想要爬取的漫画的地址
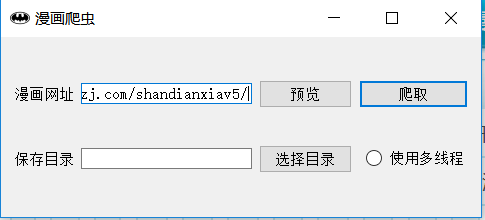

如果点击预览可预览漫画封面及相关信息,并自动生成一个保存目录。

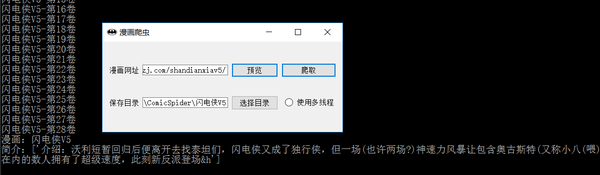

可选择是否使用多线程。
输入或点击选择目录来制定保存目录。
点击爬取开始爬取漫画。
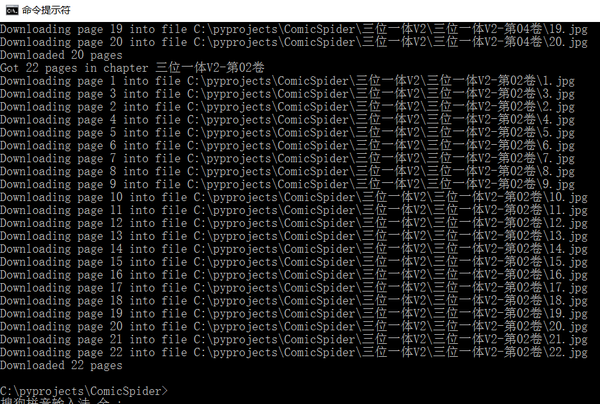

命令行版本:
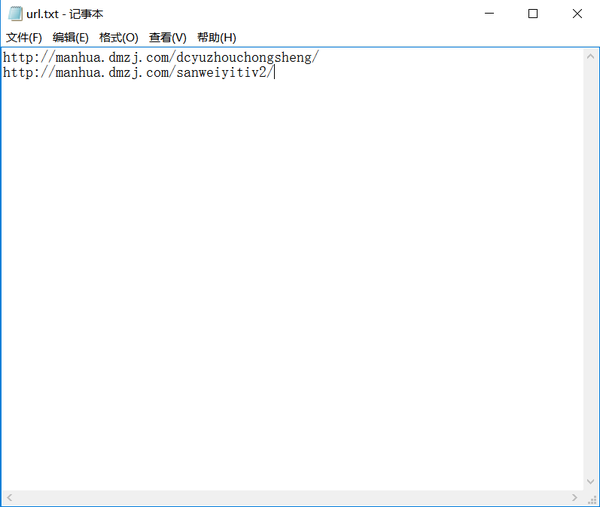
请在 ComicSpider/ 文件夹创建一个文本文件,并写入你要下载的漫画的网址。
例如,将以下内容写入 url.txt:
http://manhua.dmzj.com/dcyuzhouchongsheng/
http://manhua.dmzj.com/sanweiyitiv2/

那么程序将下载这两部漫画:


在cmd/shell:
cd ComicSpider
python download_f.py url.txt 1有两个可选参数:
第一个参数用来指定存放要下载的漫画地址的文本文件的路径,默认值为 './url.txt'. 最后一个参数用来指定是否使用多线程。'1' 即 'True' e其他的是 'False'.默认值 'False'. 运行结果:
================================================
编程实现
已有项目
调研了一下已有开源项目,发现所有实现都是基于动漫之家wap版,爬取的图片还是压缩的移动版,意义不大。 Search 动漫之家 , 开发一个漫画下载器(爬虫)
难点分析与解决思路
之所以这些项目都只能爬wap版本,是因为动漫之家采用了 AJAX 技术,无法通过一般的获得网页源码的方法来获取一个章节每一页图片的链接。各位可以试一试
requests.get('http://manhua.dmzj.com/dcyuzhouchongsheng/65929.shtml')



章节链接应该是通过js动态加载的,只用requests一个搞不定。于是,我们不得不使用爬虫的终极杀器: Selenium + Phantomjs
Selenium是一个自动化测试工具,通俗的说就是自动化控制浏览器,phantomjs则是一个可编程的无头浏览器,没有界面,不渲染网页,但是拥有完整浏览器内核。
我们的思路是通过phantomjs访问一个章节的第一页,获取完整的page source,然后用正则获得每一页的图片链接,然后用requests下载。
这样的话一个漫画只需要调用一次Phantomjs,效率可以接受。
目标网页分析
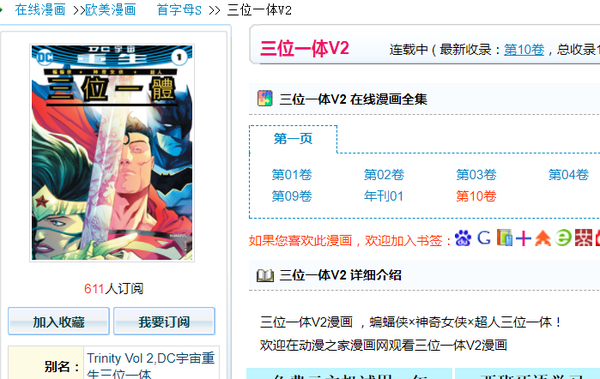
以 三位一体V2-动漫之家漫画网 为例:
首先我们需要知道一个漫画的标题、封面、章节目录等信息
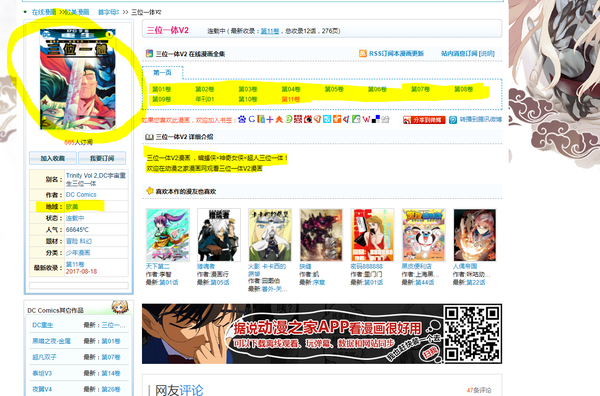

这个网页是静态的,也就是说我们可以通过GET请求返回的html获得所有元素。通过检查元素我们可以获得各种信息的html并写出正则。
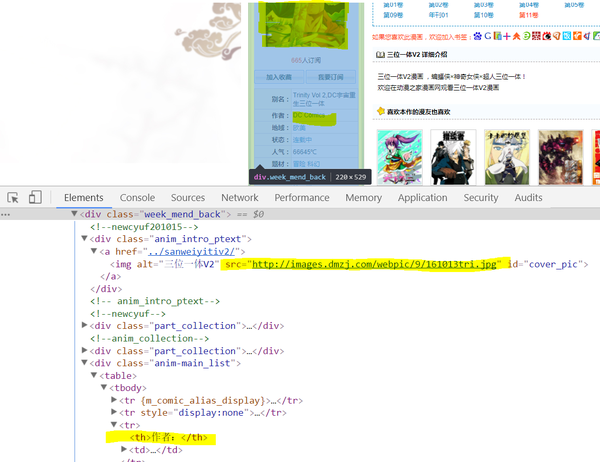

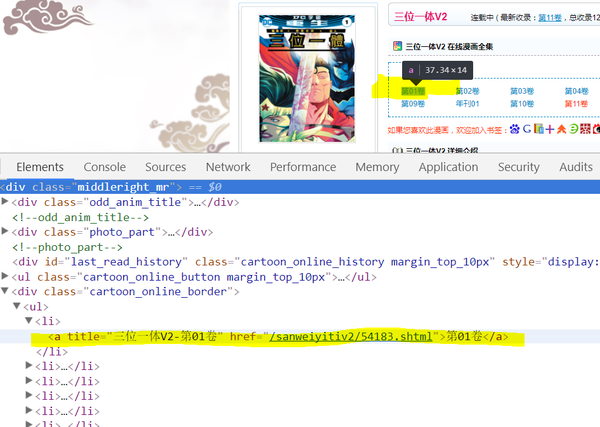

正则:
r_title=r'<span class="anim_title_text"><a href=".*?"><h1>(.*?)</h1></a></span>'
r_des=r'<meta name=\'description\' content=".*?(介绍.*?)"/>'#简介正则
r_cover=r'src="(.*?)" id="cover_pic"/></a>'#封面url正则
r_cb=r'<div class="cartoon_online_border" >([\s\S]*?)<div class="clearfix"></div>'#章节border
r_cs=r'<li><a title="(.*?)" href="(.*?)" .*?>.*?</a>'#章节链接正则可以定义一个根据漫画首页返回信息的函数:
def get_info(self):
获取漫画标题、简介、封面url,章节url
Get informations of the comic
return:
comic title,description,cover url,chapters' urls
headers={'use-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"}
root='http://manhua.dmzj.com'
r_title=r'<span class="anim_title_text"><a href=".*?"><h1>(.*?)</h1></a></span>'
r_des=r'<meta name=\'description\' content=".*?(介绍.*?)"/>'#简介正则
r_cover=r'src="(.*?)" id="cover_pic"/></a>'#封面url正则
r_cb=r'<div class="cartoon_online_border" >([\s\S]*?)<div class="clearfix"></div>'#章节border
r_cs=r'<li><a title="(.*?)" href="(.*?)" .*?>.*?</a>'#章节链接正则
try:
text=requests.get(self.comic_url,headers=headers).text
except ConnectionError:
traceback.print_exc()
raise ConnectionError
title=re.findall(r_title,text)[0]
cb=re.findall(r_cb,text)[0]
chapter_urls=[(c[0],root+c[1]+'#@page=1') for c in re.findall(r_cs,cb)]
cover_url=re.findall(r_cover,text)[0]
des=re.findall(r_des,text)
return title,des,cover_url,chapter_urls然后我们再看看每个章节的首页:
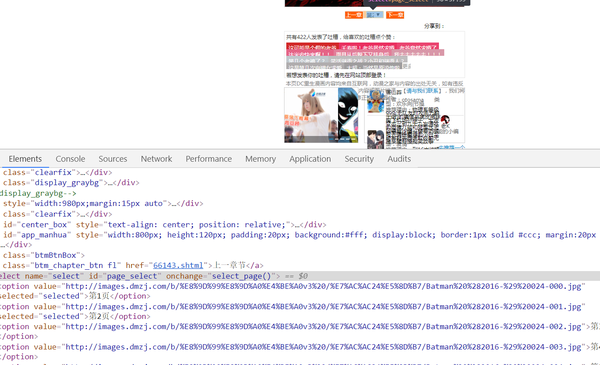
这样的下拉框是动态加载的,根据之前提到的解决思路我们需要用Phantomjs浏览器像普通浏览器一样加载这个章节页然后再获得每一页的URL。
def get_pages(self):
通过Phantomjs获得网页完整源码,解析出每一页漫画的url
Get all pages' urls using selenium an phantomJS
return:
a list of tuple (page_num,page_url)
r_slt=r'onchange="select_page\(\)">([\s\S]*?)</select>'
r_p=r'<option value="(.*?)".*?>第(\d*?)页<'
try:
dcap = dict(DesiredCapabilities.PHANTOMJS)
# 不载入图片,爬页面速度会快很多
dcap["phantomjs.page.settings.loadImages"] = False
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.get(self.chapter_url)
text=driver.page_source
st=re.findall(r_slt,text)[0]
self.pages = [(int(p[-1]),p[0]) for p in re.findall(r_p,st)]
except Exception:
traceback.print_exc()
self.pages = []
except KeyboardInterrupt:
raise KeyboardInterrupt
finally:
driver.quit()
print('Got {l} pages in chapter {ch}'.format(l=len(self.pages),ch=self.chapter_title))
return self.pages获得了每一页的URL,我们直接使用requests进行下载,注意,GET图片的请求的headers需要章节首页URL作为refer。
def download_page(self,page):
下载一页漫画
Download a page and save it in a local file
args:
page:
a tuple (page_num,page_url)
return:
status code
headers={'use-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",'referer':self.chapter_url}
n=page[0]
url=page[-1]
if not os.path.exists(self.chapter_dir):
os.mkdir(self.chapter_dir)
path=os.path.join(self.chapter_dir,str(n)+'.'+url.split('.')[-1])
try:
print('Downloading page {n} into file {f}'.format(n=n,f=path))
res=requests.get(url,headers=headers)
data=res.content
with open(path,'wb') as f
:
f.write(data)
except Exception:
e=traceback.format_exc()
print('Got eorr when downloading picture\n'+e)
return 0
except KeyboardInterrupt:
raise KeyboardInterrupt
else:
return 1至此,这个爬虫的核心部分已经完成
面向对象的多线程爬虫
下载 PhantomJS , 解压并将phantomjs.exe文件放在.py文件的同一个文件夹。或者把phantomjs.exe所在路径添加到环境变量PATH。
在我编写爬虫时,一般按照面向对象编程的style将目标网页的各个层次抽象为一个类。
在本程序在,每个 漫画对象 包含若干 章节对象 ,我们分别把他们抽象为Comic类和Chapter类。
一个章节对象拥有一系列属性和方法来下载自己的使用页:
class Chapter():
一个对漫画章节的抽象
def __init__(self,comic_title,comic_dir,chapter_title,chapter_url):
self.comic_title,self.comic_dir,self.chapter_title,self.chapter_url=comic_title,comic_dir,chapter_title,chapter_url
self.chapter_dir=os.path.join(self.comic_dir,validatetitle(self.chapter_title))
if not os.path.exists(self.chapter_dir):
os.mkdir(self.chapter_dir)
self.pages=[]
def get_pages(self):
通过Phantomjs获得网页完整源码,解析出每一页漫画的url
Get all pages' urls using selenium an phantomJS
return:
a list of tuple (page_num,page_url)
r_slt=r'onchange="select_page\(\)">([\s\S]*?)</select>'
r_p=r'<option value="(.*?)".*?>第(\d*?)页<'
try:
dcap = dict(DesiredCapabilities.PHANTOMJS)
# 不载入图片,爬页面速度会快很多
dcap["phantomjs.page.settings.loadImages"] = False
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.get(self.chapter_url)
text=driver.page_source
st=re.findall(r_slt,text)[0]
self.pages = [(int(p[-1]),p[0]) for p in re.findall(r_p,st)]
except Exception:
traceback.print_exc()
self.pages = []
except KeyboardInterrupt:
raise KeyboardInterrupt
finally:
driver.quit()
print('Got {l} pages in chapter {ch}'.format(l=len(self.pages),ch=self.chapter_title))
return self.pages
def download_page(self,page):
下载一页漫画
Download a page and save it in a local file
args:
page:
a tuple (page_num,page_url)
return:
status code
headers={'use-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",'referer':self.chapter_url}
n=page[0]
url=page[-1]
if not os.path.exists(self.chapter_dir):
os.mkdir(self.chapter_dir)
path=os.path.join(self.chapter_dir,str(n)+'.'+url.split('.')[-1])
try:
print('Downloading page {n} into file {f}'.format(n=n,f=path))
res=requests.get(url,headers=headers)
data=res.content
with open(path,'wb') as f:
f.write(data)
except Exception:
e=traceback.format_exc()
print('Got eorr when downloading picture\n'+e)
return 0
except KeyboardInterrupt:
raise KeyboardInterrupt
else:
return 1
def download_chapter_s(self):
单线程下载本章节全部页
Download all pages of the chapter not using multiprocessing
freeze_support()
results=[]
if not self.pages:
print('No page')
return None
print('Downloading chapter {c}'.format(c=self.chapter_title))
results=[self.download_page(page) for page in self.pages]
num=sum(results)
print('Downloaded {} pages'.format(num))
def download_chapter_m(self):
多线程下载本章节全部页
Download all pages of the chapter using multiprocessing
results=[]
if not self.pages:
print('No page')
return None
freeze_support()
mp=Pool(min(8,max(cpu_count(),4)))
for page in self.pages:
results.append(mp.apply_async(self.download_page,(page,)))
mp.close()
mp.join()
num=sum([result.get() for result in
results])
print('Downloaded {} pages'.format(num))一个漫画对象拥有一系列的章节对象,我们把它们存为字典数据类型。
漫画对象拥有一系列属性和方法在各个章节的层面上迭代,逐章节下载。
class Comic():
对一部漫画的抽象
An abstraction of comic
args:
comic_url:漫画主页URL
comic_title:漫画标题,缺省值为自动填充
comic_dir:漫画保存目录,缺省值为根据标题自动填充
def __init__(self,comic_url,comic_title=None,comic_dir=None):
self.comic_url=comic_url
n_comic_title,self.des,self.cover,self.chapter_urls=self.get_info()
self.chapter_num=len(self.chapter_urls)
self.comic_title=(comic_title if comic_title else n_comic_title)
self.comic_dir=os.path.abspath((comic_dir if comic_dir else validatetitle(self.comic_title)))
if not os.path.exists(self.comic_dir):
os.mkdir(self.comic_dir)
print('There are {n} chapters in comic {c}'.format(n=self.chapter_num,c=self.comic_title))
self.chapters={info[0]:Chapter(self.comic_title, self.comic_dir, *info) for info in self.chapter_urls}
self.pages=[]
def get_info(self):
获取漫画标题、简介、封面url,章节url
Get informations of the comic
return:
comic title,description,cover url,chapters' urls
headers={'use-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",'Referer':'http://manhua.dmzj.com/tags/s.shtml'}
root='http://manhua.dmzj.com'
r_title=r'<span class="anim_title_text"><a href=".*?"><h1>(.*?)</h1></a></span>'
r_des=r'<meta name=\'description\' content=".*?(介绍.*?)"/>'#简介正则
r_cover=r'src="(.*?)" id="cover_pic"/></a>'#封面url正则
r_cb=r'<div class="cartoon_online_border" >([\s\S]*?)<div class="clearfix"></div>'#章节border
r_cs=r'<li><a title="(.*?)" href="(.*?)" .*?>.*?</a>'#章节链接正则
try:
text=requests.get(self.comic_url,headers=headers).text
except ConnectionError:
traceback.print_exc()
raise ConnectionError
title=re.findall(r_title,text)[0]
cb=re.findall(r_cb,text)[0]
chapter_urls=[(c[0],root+c[1]+'#@page=1') for c in re.findall(r_cs,cb)]
cover_url=re.findall(r_cover,text)[0]
des=re.findall(r_des,text)
return title,des,cover_url,chapter_urls
def update(self):
更新漫画(未测试)
n_chapter_urls=self.get_info()
num=0
for info in n_chapter_urls:
if not info in self.chapter_urls:
num+=1
self.chapters[info[0]]=Chapter(self.comic_title, self.comic_dir, *info)
if num:
self.chapter_urls=n_chapter_urls
print('Got {n} new chapters:\n{chs}'.format(n=num,chs='\n'.join([info[0] for info in self.chapter_urls])))
else:
print('No new chapter found')
def print_chapters(self,show=False):
打印章节信息
Display infos of chapters.
headers={'use-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",'Referer':'http://manhua.dmzj.com/tags/s.shtml'}
text='There are {n} chapters in comic {c}:\n{chs}'.format(n=self.chapter_num,c=self.comic_title,chs='\n'.join([info[0] for info in self.chapter_urls]))
print(text)
if show:
try:
res=requests.get(self.cover,headers=headers)
if b'403' in res.content:
raise ValueError('Got cover img failed')
out=BytesIO(res.content)
out.seek(0)
Image.open(out).show()
except (ConnectionError,ValueError):
traceback.print_exc()
return text
def download_chapter(self,key,p=True):
下载一个章节
Download a chapter by chapter title
key:title
p:multiprocessing or not
if not key in self.chapters:
print('No such chapter {key}\nThere are chapters:\n{chs}'.format(key=key,chs='\n'.join(self
.chapters.keys())))
return None
if not self.chapters[key].pages:
self.pages+=self.chapters[key].get_pages()
(self.chapters[key].download_chapter_m() if p else self.chapters[key].download_chapter_s())
def download_all_chapters_s(self,p=False):
下载所有章节,在章节层面单线程
p:在页层面是否使用多线程
print('Downloading all chapters of comic {title} into dir {d}'.format(title=self.comic_title,d=self.comic_dir))
[self.download_chapter(key=title,p=p) for title in self.chapters.keys()]
def download_all_chapters_p(self):
在章节层面多线程
mp=Pool(min(8,max(cpu_count(),4)))
for key in self.chapters.keys():
mp.apply_async(self.download_chapter,(key,False))
mp.close()
mp.join()注意,因为本文开发的是多线程爬虫,所以没有在漫画层面建立一个webdriver而是每个章节即时创建一个,用后即弃。
简单地包装一下,我们就可以得到一个命令行爬虫:
from comic import *
import sys
def download_from_file(path,p=False):
with open(path,'r') as f:
ls=f.readlines()
for l in ls:
comic=Comic(l)
comic.download_all_chapters_s(p)
if __name__=='__main__':
if sys.platform.startswith('win'):
freeze_support()
path=(sys.argv[1] if len(sys.argv)>1 else './url.txt')
print('Download comics based on file {f}'.format(f=path))
p= (sys.argv[-1]=='1')
if p:
print('Using multi threads...')
else:
print('Using single thread...')
download_from_file(path,p)
基于PyQt的GUI爬虫
对于熟悉计算机技术的用户,命令行程序是十分方便的,然而,对于大部分习惯使用图形界面(GUI)的普通用户来说,命令行就是写满了密密麻麻乱码的恐怖天书。
在发布一款程序时,应当尽可能提供直观易用的GUI版本。
基于Python开发GUI应用, PyQt 或许是最好的选择之一。
一般来说,GUI的窗体布局和程序逻辑分开实现
使用 Eric6 和 Qt Designer 创建窗体,编译为py文件。
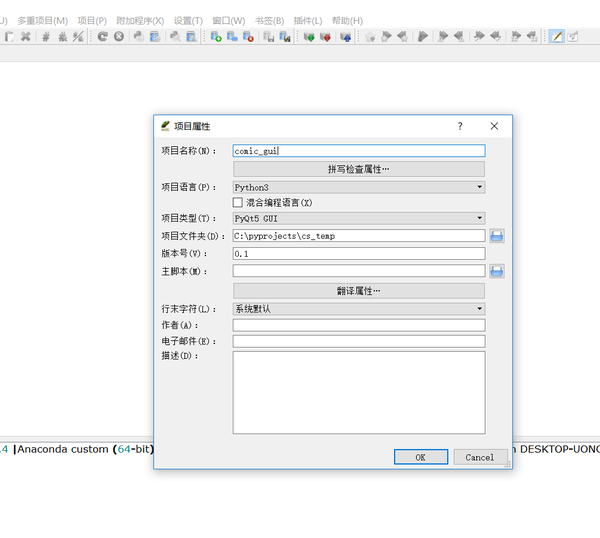
首先我们使用eric新建一个项目。
注意,这些项目文件夹应该是我们之前的ComicSpider文件夹,这里是为了演示新建的临时文件夹。

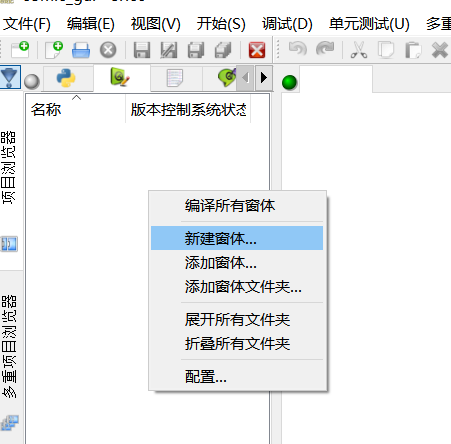
之后新建一个窗体

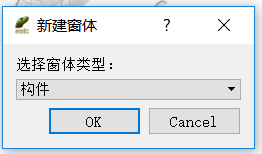
中性一点选择构件
通过拖拽构件来进行布置窗体
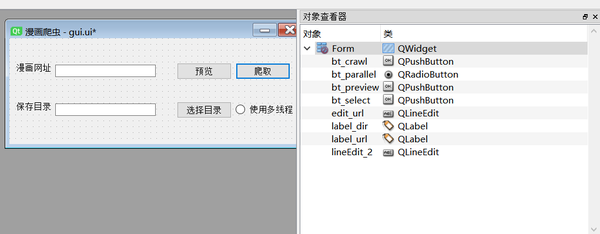

使用预设布局,ctrl+s保存。
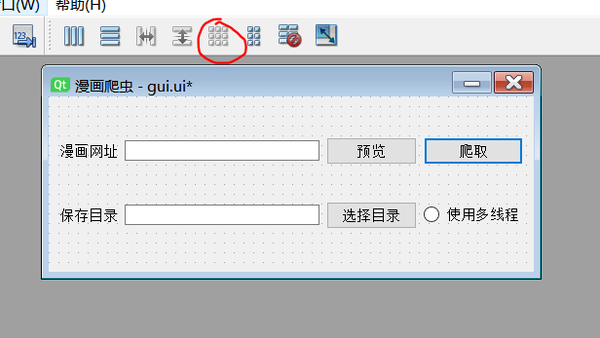

回到eric编译窗体
得到窗体原始源码。
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_Form(object):
def setupUi(self, Form):
Form.setObjectName("Form")
Form.resize(498, 180)
Form.setLayoutDirection(QtCore.Qt.LeftToRight)
Form.setAutoFillBackground(False)
self.gridLayout = QtWidgets.QGridLayout(Form)
self.gridLayout.setObjectName("gridLayout")
self.label_url = QtWidgets.QLabel(Form)
self.label_url.setAlignment(QtCore.Qt.AlignCenter)
self.label_url.setObjectName("label_url")
self.gridLayout.addWidget(self.label_url, 0, 0, 1, 1)
self.edit_url = QtWidgets.QLineEdit(Form)
self.edit_url.setObjectName("edit_url")
self.gridLayout.addWidget(self.edit_url, 0, 1, 1, 1)
self.bt_preview = QtWidgets.QPushButton(Form)
self.bt_preview.setAutoDefault(True)
self.bt_preview.setDefault(False)
self.bt_preview.setObjectName("bt_preview")
self.gridLayout.addWidget(self.bt_preview, 0, 2, 1, 1)
self.bt_crawl = QtWidgets.QPushButton(Form)
self.bt_crawl.setDefault(True)
self.bt_crawl.setObjectName("bt_crawl")
self.gridLayout.addWidget(self.bt_crawl, 0, 3, 1, 2)
self.label_dir = QtWidgets.QLabel(Form)
self.label_dir.setAlignment(QtCore.Qt.AlignCenter)
self.label_dir.setObjectName("label_dir")
self.gridLayout.addWidget(self.label_dir, 1, 0, 1, 1)
self.lineEdit_2 = QtWidgets.QLineEdit(Form)
self.lineEdit_2.setObjectName("lineEdit_2")
self.gridLayout.addWidget(self.lineEdit_2, 1, 1, 1, 1)
self.bt_select = QtWidgets.QPushButton(Form)
self.bt_select.setObjectName("bt_select")
self.gridLayout.addWidget(self.bt_select, 1, 2, 1, 1)
self.bt_parallel = QtWidgets.QRadioButton(Form)
self.bt_parallel.setChecked(False)
self.bt_parallel.setObjectName("bt_parallel")
self.gridLayout.addWidget(self.bt_parallel, 1, 4, 1, 1)
self.retranslateUi(Form)
QtCore.QMetaObject.connectSlotsByName(Form)
def retranslateUi(self, Form):
_translate = QtCore.QCoreApplication.translate
Form.setWindowTitle(_translate("Form", "漫画爬虫"))
self.label_url.setText(_translate("Form", "漫画网址"))
self.bt_preview.setText(_translate("Form", "预览"))
self.bt_crawl.setText(_translate("Form", "爬取"))
self.label_dir.setText(_translate("Form", "保存目录"))
self.bt_select.setText(_translate("Form", "选择目录"))
self.bt_parallel.setText(_translate("Form", "使用多线程"))
if __name__ == "__main__":
import sys
app = QtWidgets.QApplication(sys.argv)
Form = QtWidgets.QWidget()
ui = Ui_Form()
ui.setupUi(Form)
Form.show()
sys.exit(app.exec_())接下来就是要为GUI添加逻辑,得到完整程序。
我们
from comic import *
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QFileDialog
import sys
class Ui_Form(QtWidgets.QWidget):
def __init__(self):
super(Ui_Form,self).__init__()
self.url=''
self.dir=''
self.show=True
self.loaded=False
self.comic=None
def setupUi(self, Form):
Form.setObjectName("Form")
Form.resize(480, 180)
Form.setLayoutDirection(QtCore.Qt.LeftToRight)
Form.setAutoFillBackground(False)
Form.setWindowIcon(QtGui.QIcon('./batman.ico'))
self.gridLayout = QtWidgets.QGridLayout(Form)
self.gridLayout.setObjectName("gridLayout")
self.label_url = QtWidgets.QLabel(Form)
self.label_url.setAlignment(QtCore.Qt.AlignCenter)
self.label_url.setObjectName("label_url")
self.gridLayout.addWidget(self.label_url, 0, 0, 1, 1)
#输入url的文本框
self.edit_url = QtWidgets.QLineEdit(Form)
self.edit_url.setObjectName("edit_url")
self.gridLayout.addWidget(self.edit_url, 0, 1, 1, 1)
#预览按键
self.bt_preview = QtWidgets.QPushButton(Form)
self.bt_preview.setAutoDefault(True)
self.bt_preview.setDefault(False)
self.bt_preview.setObjectName("bt_preview")
self.bt_preview.clicked.connect(self.preview)#槽
self.gridLayout.addWidget(self.bt_preview, 0, 2, 1, 1)
#启动爬取按键
self.bt_crawl = QtWidgets.QPushButton(Form)
self.bt_crawl.setDefault(True)
self.bt_crawl.setObjectName("bt_crawl")
self.bt_crawl.clicked.connect(self.crawl)#槽
self.gridLayout.addWidget(self.bt_crawl, 0, 3, 1, 2)
self.label_dir = QtWidgets.QLabel(Form)
self.label_dir.setAlignment(QtCore.Qt.AlignCenter)
self.label_dir.setObjectName("label_dir")
self.gridLayout.addWidget(self.label_dir, 1, 0, 1, 1)
#选择目录的文本框
self.edit_dir = QtWidgets.QLineEdit(Form)
self.edit_dir.setObjectName("edit_dir")
self.edit_url.textChanged.connect(self.edit_dir.clear)#URL变化就清空目录
self.edit_url.textChanged.connect(self.loaded_statu)#预览加载状态
self.edit_dir.textChanged.connect(self.loaded_statu)#预览加载状态
self.gridLayout.addWidget(self.edit_dir, 1, 1, 1, 1)
#选择目录按钮
self.bt_select = QtWidgets.QPushButton(Form)
self.bt_select.setObjectName("bt_select")
self.bt_select.clicked.connect(self.select_dir)
self.gridLayout.addWidget(self.bt_select, 1, 2, 1, 1)
#并行按钮
self.bt_parallel = QtWidgets.QRadioButton(Form)
self.bt_parallel.setChecked(False)
self.bt_parallel.setObjectName("bt_parallel")
self.gridLayout.addWidget(self.bt_parallel, 1, 4, 1, 1)
self.retranslateUi(Form)
QtCore.QMetaObject.connectSlotsByName(Form)
def retranslateUi(self, Form):
_translate = QtCore.QCoreApplication.translate
Form.setWindowTitle(_translate("Form", "漫画爬虫"))
self.label_url.setText(_translate("Form", "漫画网址"))
self.bt_preview.setText(_translate("Form", "预览"))
self.bt_crawl.setText(_translate("Form", "爬取"))
self.label_dir.setText(_translate("Form", "保存目录"))
self.bt_select.setText(_translate("Form", "选择目录"))
self.bt_parallel.setText(_translate("Form", "使用多线程"))
def select_dir(self):
弹出文件对话框选择保存目录
self.dir=QFileDialog.getExistingDirectory(self,'选择保存路径',(self.dirname if self.dirname else './'))
def loaded_statu(self):
更改预览状态
self.loaded=False
def preview(self):
self.url=self.edit_url.text()
try:
self.comic=Comic(self.url)
except:
traceback.print_exc()
return False
self.loaded=True
title,des=self.comic.get_info()[:2]
if self.show:
self.comic.print_chapters(self.show)
else:
print('使用自动设置')
print('漫画:{t}\n简介:{d}'.format(t=title,d=des))
if not (self.edit_dir.text()):
dirname=os.path.join(os.path.abspath('./'),validatetitle(title))
self.edit_dir.setText(dirname)
self.dir=dirname
return True
def crawl(self):
if not self.url:
print('请指定漫画地址!')
return
if not self.dir:
self.show=False
self.preview()
self.show=True
self.parallel=(self.bt_parallel.isChecked() and cpu_count()>1)
print(('使用多线程下载' if self.parallel else '使用单线程下载'))
if not self.loaded:
comic=Comic(self.url,None,self.dir)
self.dir,self.url='',''
self.comic.download_all_chapters_s(self.parallel)
if __name__ == "__main__":
if sys.platform.startswith('win'):
freeze_support()#pyinstaller多线程
app = QtWidgets.QApplication(sys.argv)
Form = QtWidgets.QWidget()
ui = Ui_Form()
ui.setupUi(Form)
Form.show()
sys.exit(app.exec_())
使用pyinstaller打包发布exe程序
当Python爬虫项目面向广泛的用户群体时,必须要考虑到易用性、便携性,做到开箱即用。
然而Python程序的一大缺点就是依赖Python解释器、第三方包等众多依赖,特别是在windows平台便携性极差。
我们需要将Python项目打包为一键运行的exe文件。
pyinstaller 几乎是最好的选择,它可以自动分析依赖,生成单个exe可执行文件或者单目录程序。
以本项目为例,我们使用以下命令来打包
pyinstaller -D -i batman.ico -p c:\Anaconda3\Lib\site-packages\PyQt5\Qt\bin comic_gui.py -y
pyinstaller -D download_f.py -n comicspider_console -i batman.ico -y
copy batman.ico .\dist\comicspider_console
copy url.txt .\dist\comicspider_console
copy batman.ico .\dist\comic_gui其中`-p c:\Anaconda3\Lib\site-packages\PyQt5\Qt\bin`是指定pyqt搜索目录根据需求替换为自己的安装目录,`-i`指定图标。
-D或-F是选择单目录或者单文件模式。
需要特别注意的是,在用pyinstaller打包使用了multiprocessing的python程序时,必须在主程序其实执行`multiprocessing.freeze_support()`
Recipe Multiprocessing · pyinstaller/pyinstaller Wiki · GitHub
如本项目脚本:
if __name__ == "__main__":
if sys.platform.startswith('win'):
freeze_support()#pyinstaller多线程