


硅谷之路33:实战Spark性能优化

查看完整视频:http://www.bittiger.io/classes
本文解读的是Databricks的Aaron的讲座《A Deeper Understanding of Spark’s Internals》。Aaron选择了一个很简单例子:统计每个首字母的单词个数。但他仅用几行代码就将运行时间从四十多秒优化到了十秒以内。

基于这个实战案例,我也总结了计算分布式程序性能的公式:
性能 =(计算时间+移动时间+调度时间)/并行度
希望我们不仅知其然,也知其所以然。
Spark超好的,可是用不好可能就感受不到它的好。今天来实战一下看看如何进行Spark性能优化!
我们要解决这样一个问题:找到首字母相同的单词的数量(可能有重复,要去重)。我们可以用如下code来实现:首先我们找到目标文件生成RDD,然后进行map(key是首字母,value是单词)。之后我们就按照key值来group,这是一个shuffle的环节,需要大量的数据移动。之后使用了toSet这个fuction去重,然后统计数量得到了最后的结果。It works, but it’s definitely not the best way to do it.


、
我们深入看一下Spark是如何执行这些过程的:
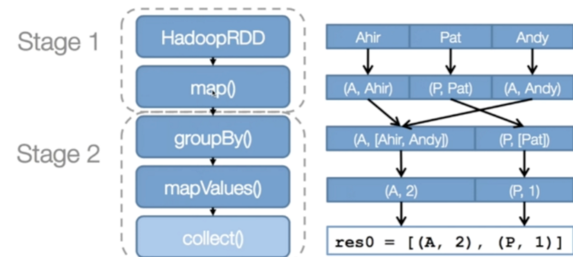
第一步生成RDD,RDD是Spark中的抽象数据模型,任何数据在Spark里都表示为RDD。

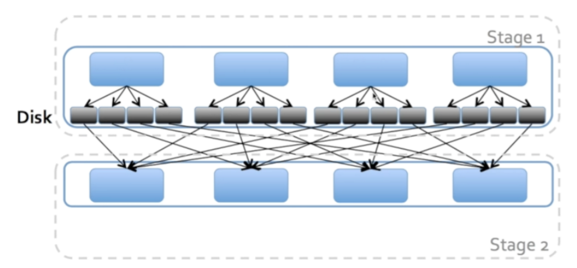
第二步会生成一个执行计划,像生成RDD,map等可以并行处理的放在一个Stage里,groupBy需要数据转移,不能和之前的并行了,所以用是另一个Stage。

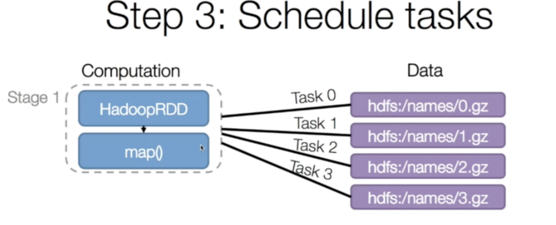
第三步针对每个Stage会生成很多task,Spark会对这些task进行调度,调度的时候会尽量将task分配到存储数据的机器,这样本地计算就减少了数据的网络传递,节约了时间和资源。
我们可以看一个小细节,就是每个task的调度是需要花费时间的,虽然是毫秒级别,可是如果task超多可能也是一笔不小的时间开销。还有一个问题是什么,我们要等Stage1的task都完成了才能进入Stage2,可是因为第一台机器执行的任务比较多,花费的时间比较长,其它两台机器会空闲着等待(好无聊)。这种对task的不合理切分是造成性能不佳的一个重要原因,怎么优化?把数据切小一点提升并行度。

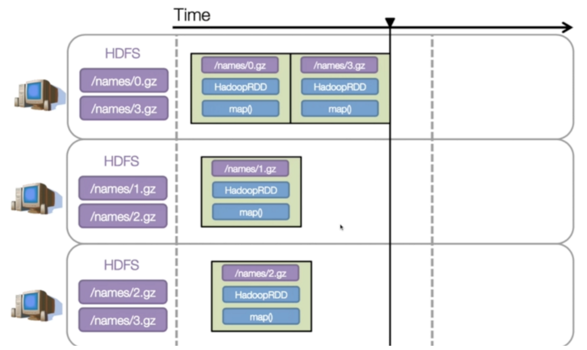

从Stage1到Stage2要进行一个shuffle的过程,为了优化这个过程,Spark会将数据切成小块,这样调度的时候只要搬运小块的数据,节省了网络流量和时间。

现在可以总结一下计算分布式程序性能的公式:
性能 =(计算时间+移动时间+调度时间)/并行度
超有用的,快记下来(敲黑板)。
学会了没有?看一下优化后的代码:


repartition是增加数据块,这些数据块并行处理提高了并行度;distinct是去重,先删掉重复的这样后面就省事了。这些简单的优化使原来要运行40多秒的程序嗖地提升到了10秒以内。棒不棒!
本文整理作者:Mengying Tian,
查看完整视频:http://www.bittiger.io/classes
更多精彩内容, 请扫描下面二维码,关注微信公众账号“论码农的自我修养”

