

TypeORM的那些事

介绍
Object–relational mapping (ORM, O/RM, and O/R mapping tool) ,在不同类型的系统中,使用对象的语言进行数据的转换
丰富的特性
| 较为丰富的特性 |
1. 支持 DataMapper 和 ActiveRecord 模式
2. 支持复杂语法查询(各种join、分页) 3. 支持多重继承模式、级联、索引、事务 4. 支持迁移和自动迁移、连接池、主从复制 5. 查询缓存 6. 懒加载 7. 支持多数据源,多数据库类型 8. 支持非关系数据库:mongo 9. 监听者和订阅者 10. 支持闭包表模式 11. 数据删除和恢复 12. 命名策略 13. 锁模式(lockMode) 14. 命令行工具 |
1. DataMapper:在存储库(Repository)而不是模型中访问数据库的方法。
2. Active Record:在模型(Entity)本身内定义所有方法,并使用模型方法来进行保存、删除和加载对象。Entity通过继承BaseEntity实现 3. 主从复制实际是读写分离 4. 继承:减少代码中的重复,有单表继承和类继承两种 5. 级联:ManyToOne,OneToOne等 6. 结果缓存,可以存储在DB的table中,或者redis 7. 监听者和订阅者:定义在实体内,可进行操作(update、insert、remove)前后的监听。两者应用范围不同,是同一类事件(InsertEvent) 8. 可支持的数据库:MySQL/MariaDB/Postgres/SQLite/Microsoft SQL Server/Oracle/SAP Hana/sql.js 9. 命名策略,用于对象关系映射 10. 数据删除和恢复 :softRemove/ recover, softDelete/ restore |
| 配置简便 |
1. 可通过编码方式来实现配置
2. 支持多种类型的配置文件("env", "js", "cjs", "ts", "json", "yml", "yaml", "xml") 3. 支持多种数据库 |
1. 默认配置文件名前缀为 ormconfig,配置在根路径下
2. 对数据库的支持,代码耦合较重,比如lockMode的处理,深度侵入在QueryBuilder中 |
| 跨平台 |
1. 可在NodeJS/浏览器/Ionic/Cordova/React Native/Expo/Electron等平台上使用
2. 支持TypeScript和JavaScript |
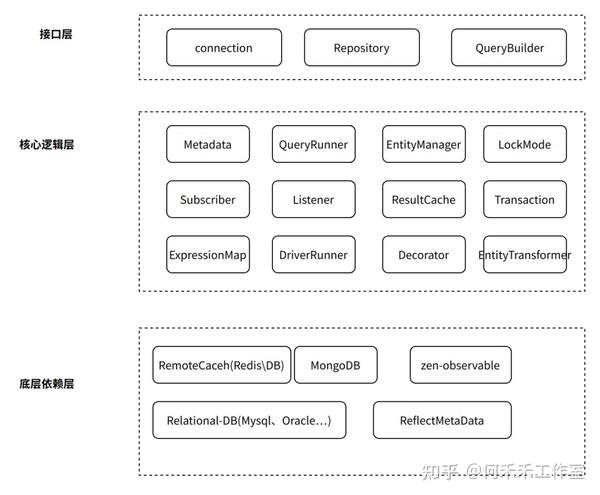
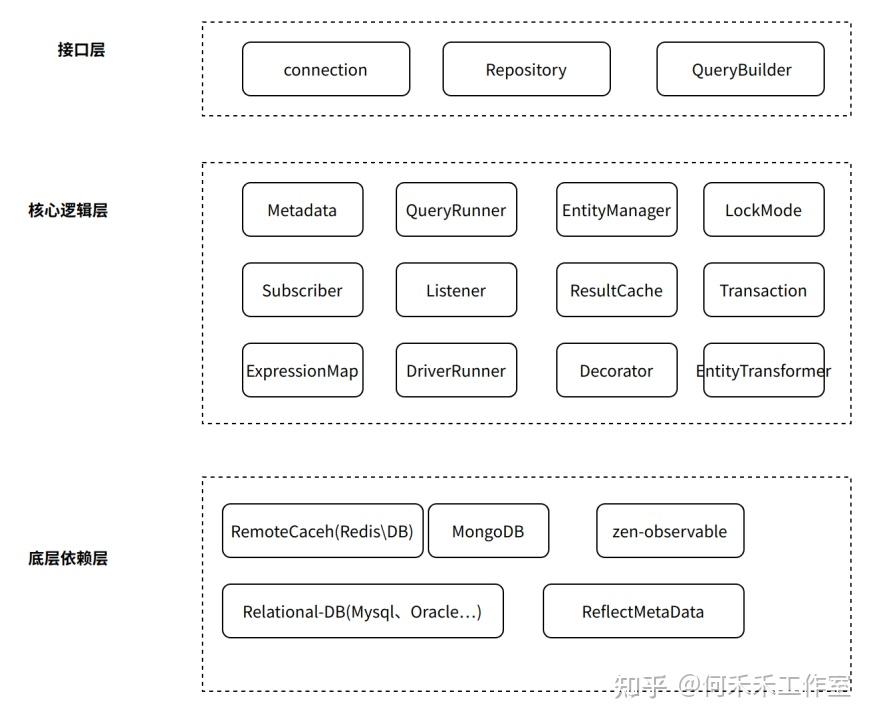
基础架构
组件/结构模型
对用户使用来说,有三种方式
1. 原生的sql语句
2. 基于Repository操作语法(api),通过定义OperationOptions方式设置参数
3. 基于QueryBuilder的操作语法(api),提供where、orderBy等语法糖
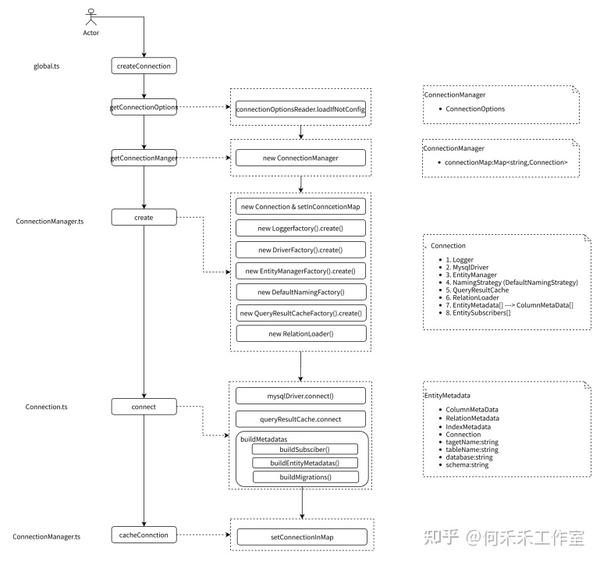
逻辑模型
Typeorm 初始化

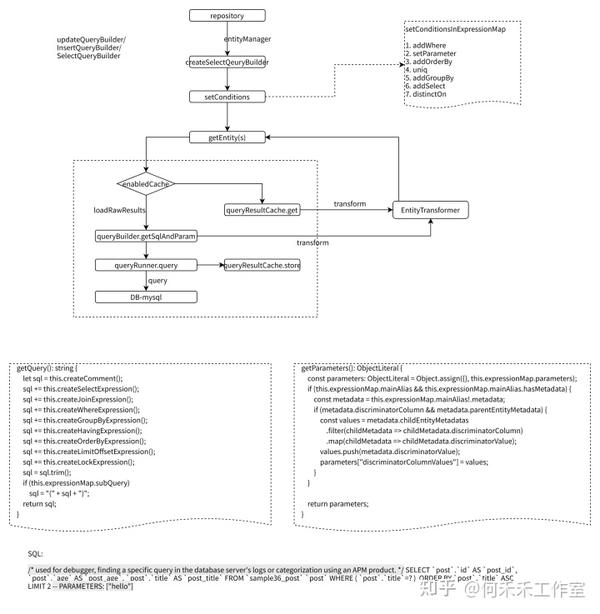
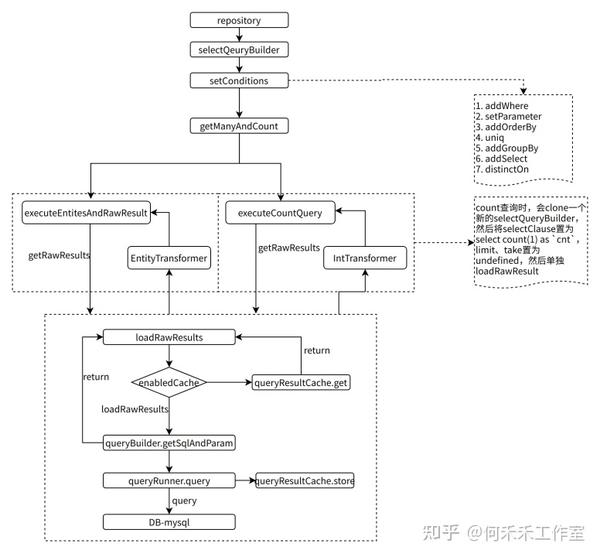
ORM执行过程
simple模式
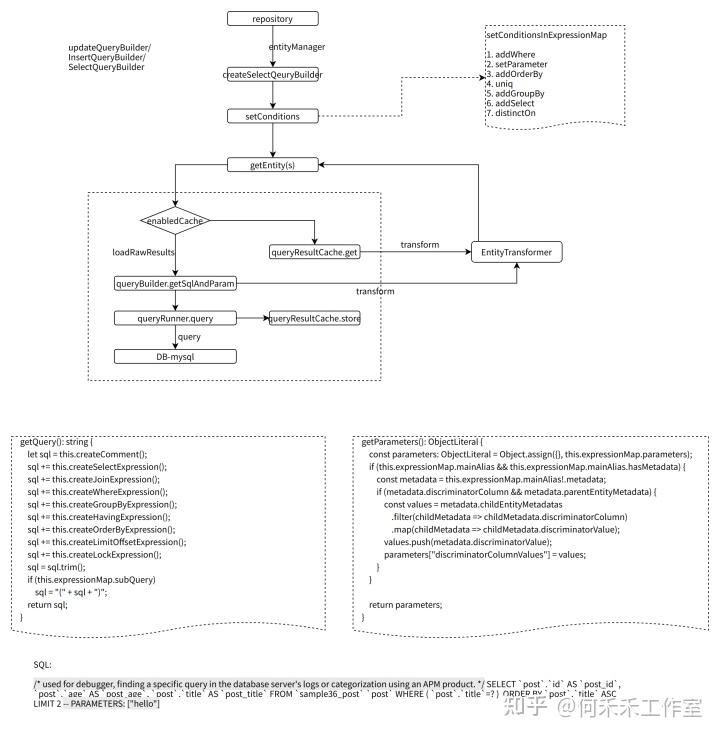
分页模式(getManyAndCount)
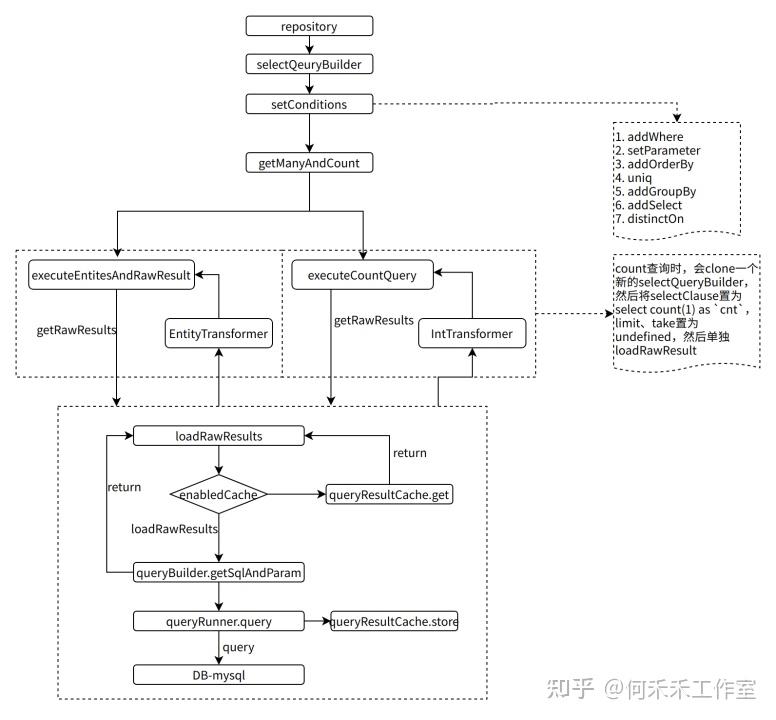
部分特性
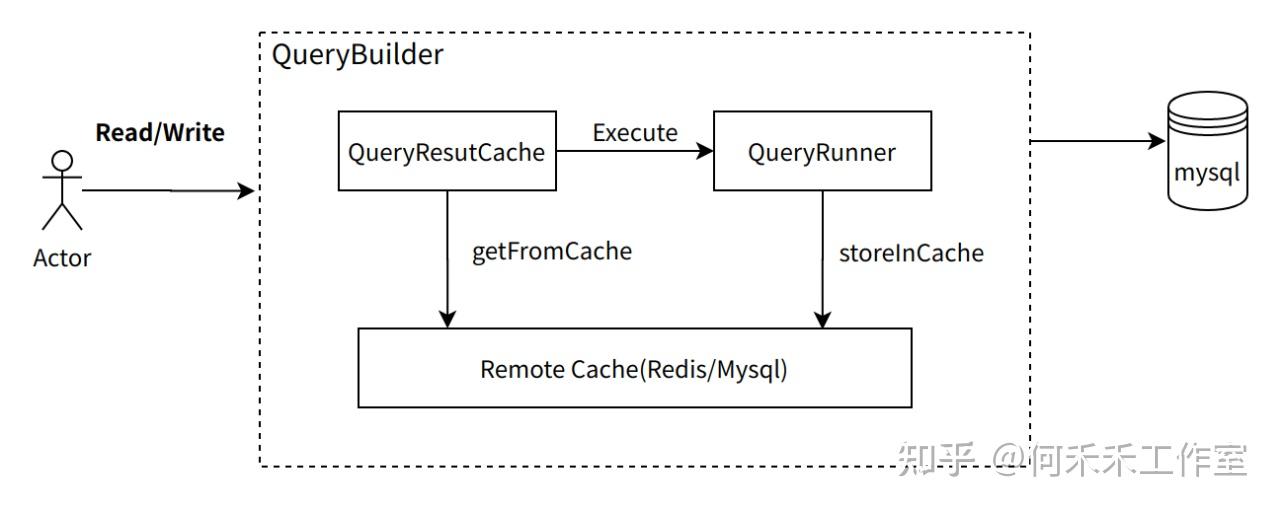
缓存设置
初始化
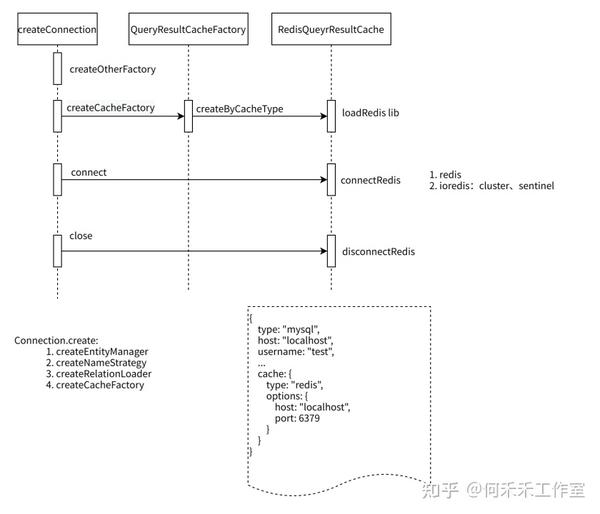
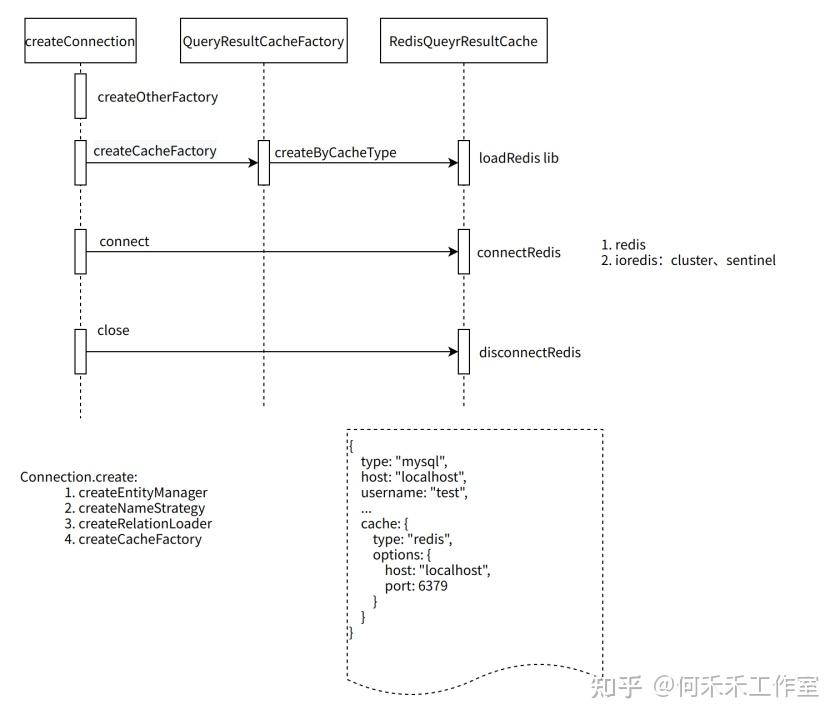
读写过程
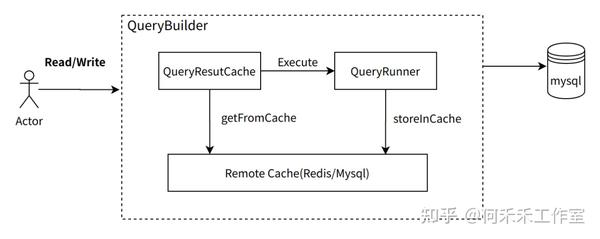
使用限制(注意事项)
1. 只能在queryBuilder\ repository中进行设置,没有对外暴漏直接的操作接口
2. 只能批量删除,不支持batchGet,其他操作如下
connect/disconnect
storeInCache
getFromCache
isExpire
remove(identifiers:string[])
clear: flushDB
3. redis-sentinel、cluster模式都支持,其中sentinel模式,需要在客户端初始化的时候,通过 options 传入
4. Connection(ORM)持有RedisQueryResultCache对象,RedisQueryResultCache在各个对象的操作中共享
使用方式
TypeScript
// 设置缓存 - queryBuilder
const users = await connection
.createQueryBuilder(User, "user")
.where("user.isAdmin = :isAdmin", { isAdmin: true })
.cache("users_admins", 25000)
.getMany();
// 设置缓存 - repository
const users = await connection.getRepository(User).find({
where: { isAdmin: true },
cache: {
id: "users_admins",
milisseconds: 25000
// 清理缓存
await connection.queryResultCache.remove(["users_admins"]);
懒加载
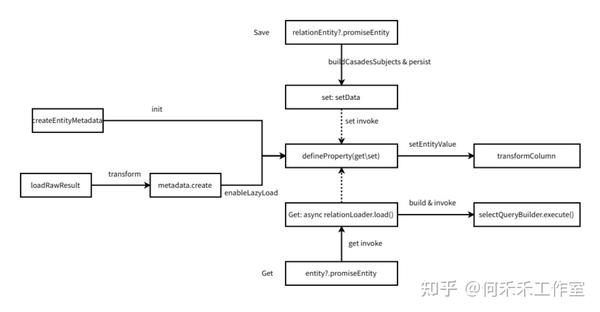
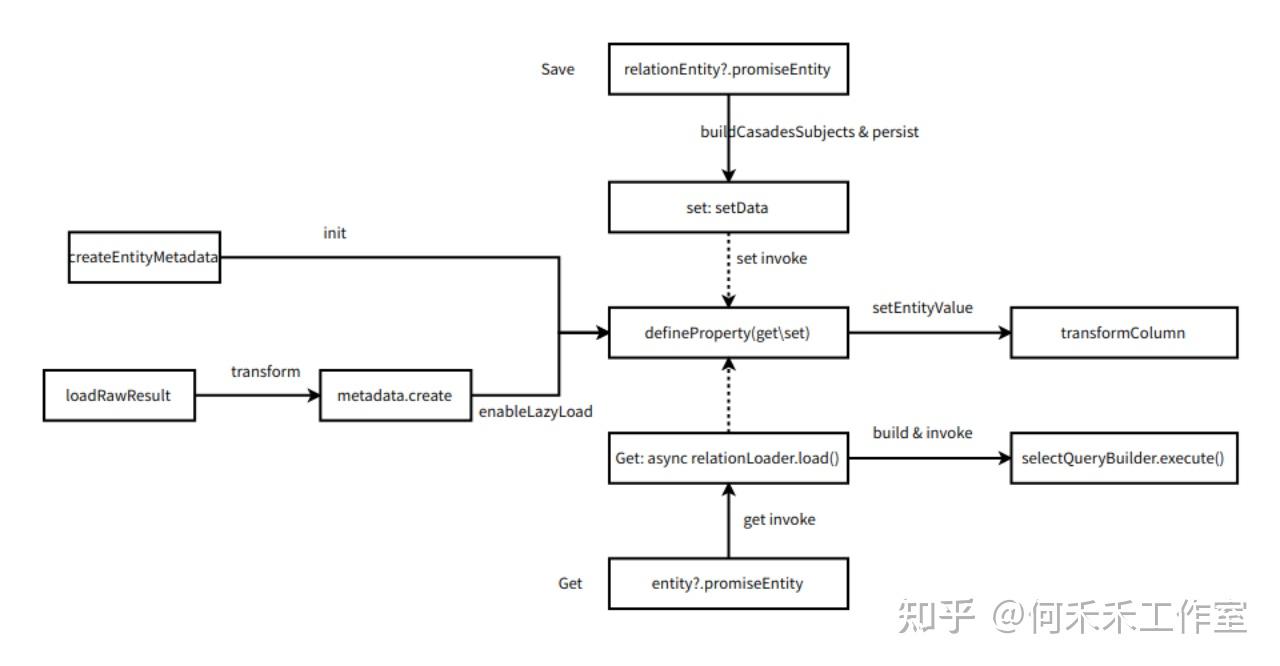
关联对象查询,有两种类型:直接加载、延迟加载(懒加载)
- 直接加载:执行完对主加载对象的 select 语句,马上执行对关联对象的 select 查询
- 延迟加载:执行对主加载对象的查询时,不会对关联对象执行查询。但当访问主加载对象的详情属性时,就会马上执行关联对象的select查询
延迟加载
-
在具有关系(比如@OneToMany)的实体类中,同时关系必须有
Promise作为类型 - 可实现分散SQL请求,解决嵌套子查询的并发效率问题
树形结构存储和查询
| closure-table | 闭包表 |
1. 实体类中添加注解
@Tree("closure-table") @TreeParent() @TreeChildren 2. 数据库中一张表维护父子关系 |
主要包含两个字段:<id_ancestor, id_descendant>
根据任何一个,可以向上查询到根结点,也可以向下查询到整个子树 |
读取和写入方面都很有效 |
| materialized-path | 物化路径 |
1. 实体类中添加注解
@Tree("materialized-path") @TreeParent() @TreeChildren 2. 表中默认增加一个mpath的字段 |
mpath维护从根结点到当前节点的完整路径 | |
| nested-set | 嵌套集 |
1. 实体类中添加注解
@Tree("nested-set") @TreeParent() @TreeChildren 2. 表中默认增加两个字段:nsleft, nsright |
集合的左右节点[nsleft,nsright]
增加节点时,新节点的所有右边节点的值都加 2。查询时按节点的边缘走,子节点的 _lft 值总是在其父节点的 _lft值 和 _rgt值 之间 |
1. 读取非常有效,对写入不利
2. 现有的设计,默认只能存在一棵树(root entity duplicated),不能在嵌套集中有多个根 |
| adjacency-list | 临接表 | 通过父子关系来维护 |
1. 查询因为要用递归,虽然容易理解但严重影响效率
2. 取不到整个树 |
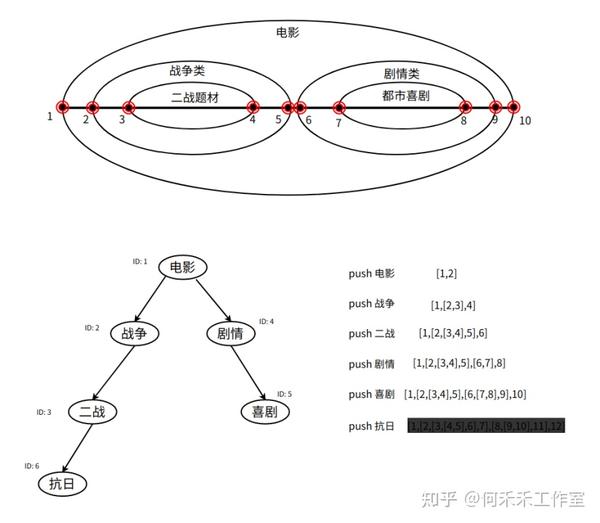
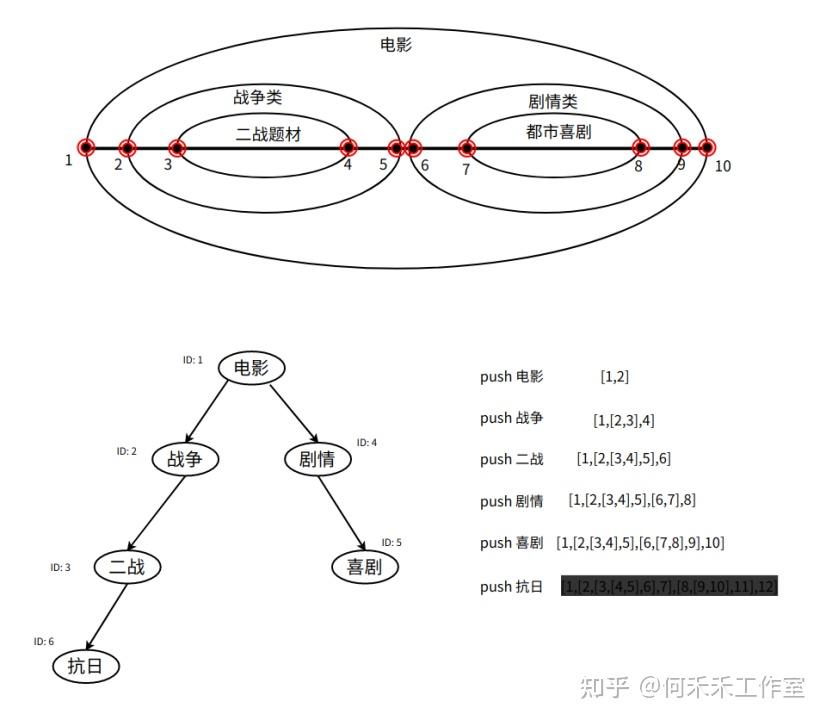
嵌套集合介绍
通过集合的包含关系表示分层结构,每一个分层可以用一个集合(如下图中的一个圈)来表示。在 MySQL 中定义两个字段 nsLeft 和 nsRight ,即集合的左值和右值来表示一个集合的范围。
多数据源
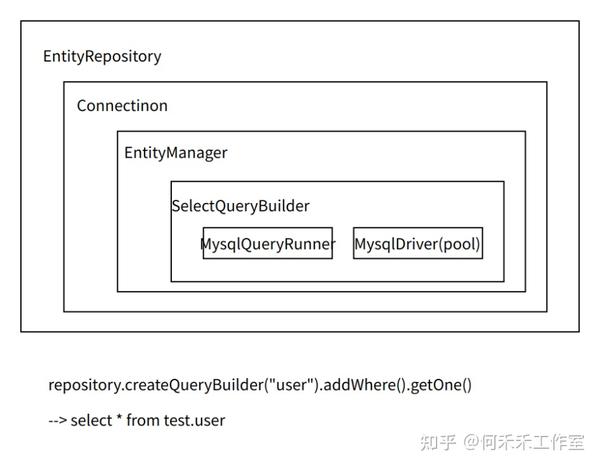
1. 单链接访问单独的库
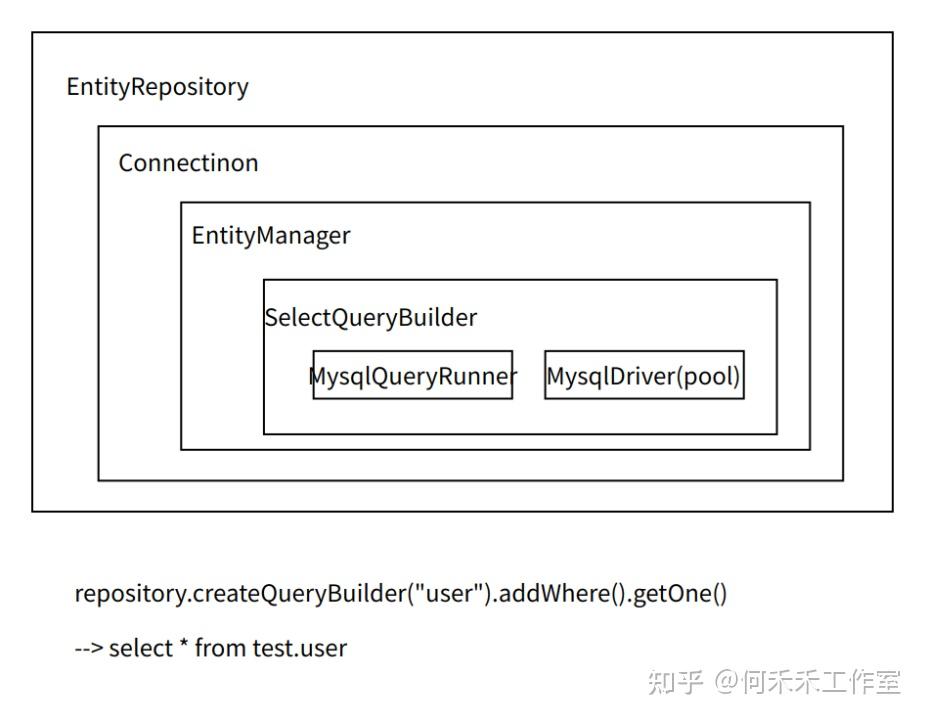
2. 单链接访问不同的库
const users = await connection
.createQueryBuilder()
.select()
.from(User, "user")