


Linux 文本三剑客(2)sed命令的使用

sed引言
sed (意为 流编辑器 ,源自 英语 “stream editor”的缩写)是一个使用简单紧凑的编程语言来解析和转换文本 Unix 实用程序。虽然在某些方面类似于允许脚本编辑的编辑器,但只需对输入进行一次传递即可工作,因此效率更高。但是,它能够过滤管道中的文本,这特别将其与其他类型的编辑器区分开来。
sed由 贝尔实验室 的 李·E·麦克马洪 于1973年至1974年开发, 并且现在大多数操作系统都可以使用。 sed基于交互式编辑器ed(“editor”,1971)和早期qed(“quick editor”,1965-66)的脚本功能。sed是最早支持 正则表达式 的工具之一,至今仍然用于文本处理,特别是用于替换命令。用于纯文本字符串操作和“流编辑”的常用工具还有 AWK 和 Perl 。
sed 工作原理
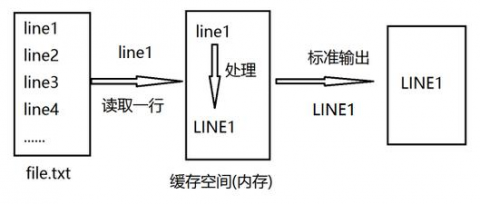
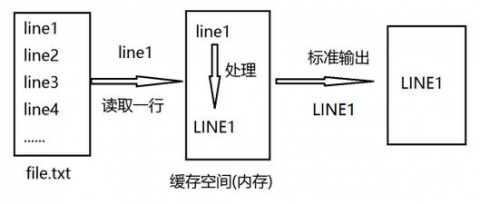
sed 和 vi 不同,sed是行编辑器。
sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为 模式空间(Pattern Space) ,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为vi命令打开文件是一次性将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快。
sed的作用
sed 是一款非常强大的程序,它能够针对文本流完成相当复杂的编辑任务。它最常用于简单的行任务,而不是长长的脚本。许多用户喜欢使用其它工具,来执行较大的工作。 在这些工具中最著名的是 awk 和 perl。
sed 可依照脚本的指令来处理、编辑文本文件。
sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
可以实现增删改查,取行、替换、查找等功能。
sed语法格式
sed [-hnV][-e<script>][-f<script文件>][文本文件]
sed OPTIONS... [SCRIPT] [INPUTFILE...]
参数说明 :
- -e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
- -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
- -h或--help 显示帮助。
- -n或--quiet或--silent 仅显示script处理后的结果。
- -V或--version 显示版本信息。
动作说明 :
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,d 后面通常不接任何字串;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
- s :取代,查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s### 替换修饰符
- g :行内全局替换
sed实例
这里我将使用Ubuntu18.04进行效果演示。
为了更好的探究 sed 程序,让我们创建一个包含以下数据的名为distros.txt文本文件:
Fedora 10 11/25/2008
Ubuntu 8.04 04/24/2008
SUSE 10.3 10/04/2007
Fedora 8 11/08/2007
Ubuntu 6.10 10/26/2006
Fedora 7 05/31/2007
SUSE 11.0 06/19/2008
Ubuntu 7.10 10/18/2007
Ubuntu 7.04 04/19/2007
Fedora 6 10/24/2006
Fedora 9 05/13/2008
Ubuntu 6.06 06/01/2006
SUSE 10.2 12/07/2006
Ubuntu 8.10 10/30/2008
Fedora 5 03/20/2006
SUSE 10.1 05/11/2006sed简单输出
通过 distros.txt 文件,我们将演示sed的各种用法。
首先,输出distros.txt文件的1-5行:
[me@linuxbox ~]$ sed -n '1,5p' distros.txt
SUSE 10.2 12/07/2006
Fedora 10 11/25/2008
SUSE 11.0 06/19/2008
Ubuntu 8.04 04/24/2008
Fedora 8 11/08/2007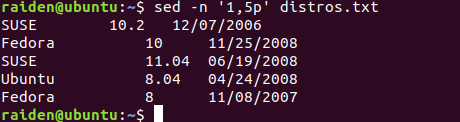
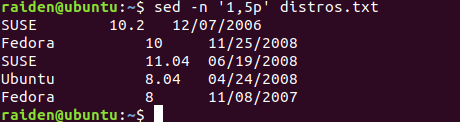
在这个例子中,我们打印出一系列的文本行,开始于第一行,直到第五行。为此,我们使用 p 命令, 其就是简单地把匹配的文本行打印出来。然而为了高效,我们必须包含选项 -n(不自动打印选项), 让 sed 不要默认地打印每一行。
sed默认显示所有内容,所以不加-n的话,如下图所示,会把目标行和所有内容都显示出来。
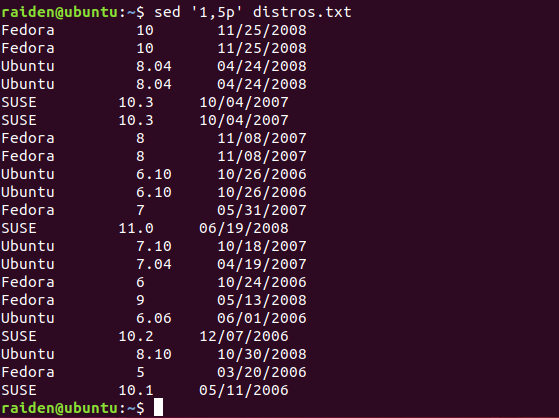
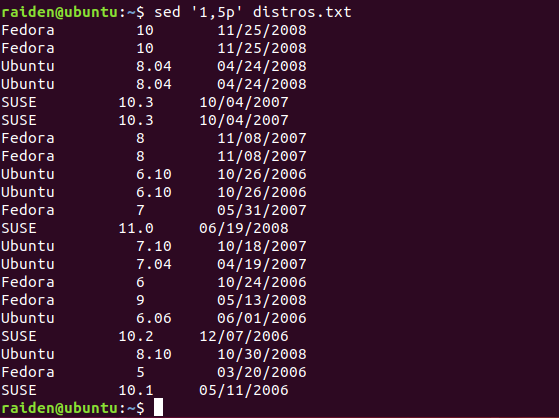
sed查询
下一步,我们将试用一下正则表达式:
[me@linuxbox ~]$ sed -n '/SUSE/p' distros.txt
SUSE 10.2 12/07/2006
SUSE 11.0 06/19/2008
SUSE 10.3 10/04/2007
SUSE 10.1 05/11/2006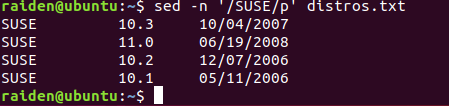
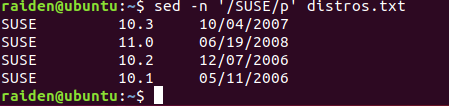
通过包含由斜杠界定的正则表达式 ‘/SUSE/’,我们能够孤立出包含它的文本行,和 grep 程序的功能是 相同 的。
试着否定上面的操作,通过给这个地址添加一个感叹号:
[me@linuxbox ~]$ sed -n '/SUSE/!p' distros.txt
Fedora 10 11/25/2008
Ubuntu 8.04 04/24/2008
Fedora 8 11/08/2007
Ubuntu 6.10 10/26/2006
Fedora 7 05/31/2007
Ubuntu 7.10 10/18/2007
Ubuntu 7.04 04/19/2007
Fedora 6 10/24/2006
Fedora 9 05/13/2008
Ubuntu 6.06 06/01/2006
Ubuntu 8.10 10/30/2008
Fedora 5 03/20/2006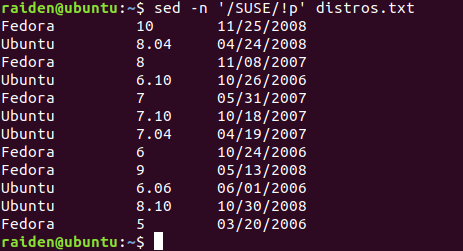
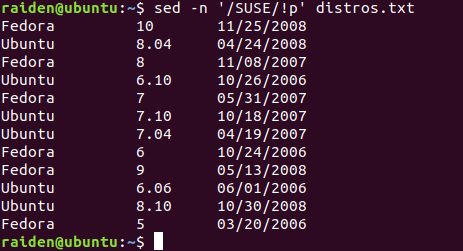
这里我们看到期望的结果:输出了文件中所有的文本行,除了那些匹配这个正则表达式的文本行。
目前为止,我们已经知道了两个 sed 的编辑命令,s 和 p。
sed编辑修改
到目前为止,这个 s 命令是最常使用的编辑命令。我们将仅仅演示一些它的功能,通过编辑我们的 distros.txt 文件。我们以前讨论过 distros.txt 文件中的日期字段不是“友好地计算机”模式。 文件中的日期格式是 MM/DD/YYYY,但如果格式是 YYYY-MM-DD 会更好一些(利于排序)。手动修改 日期格式不仅浪费时间而且易出错,但是有了 sed,只需一步就能完成修改:
[me@linuxbox ~]$ sed 's/\([0-9]\{2\}\)\/\([0-9]\{2\}\)\/\([0-9]\{4\}\)$/\3-\1-\2/' distros.txt
SUSE 10.2 2006-12-07
Fedora 10 2008-11-25
SUSE 11.0 2008-06-19
Ubuntu 8.04 2008-04-24
Fedora 8 2007-11-08
SUSE 10.3 2007-10-04
Ubuntu 6.10 2006-10-26
Fedora 7 2007-05-31
Ubuntu 7.10 2007-10-18
Ubuntu 7.04 2007-04-19
SUSE 10.1 2006-05-11
Fedora 6 2006-10-24
Fedora 9 2008-05-13
Ubuntu 6.06 2006-06-01
Ubuntu 8.10 2008-10-30
Fedora 5 2006-03-20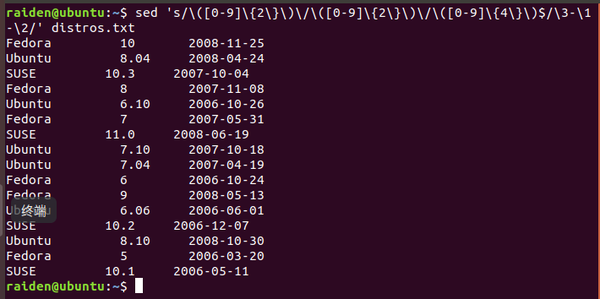
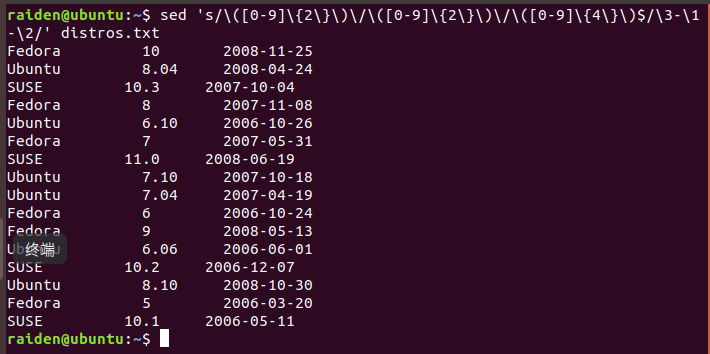
这个命令看起来很丑陋。但是它起作用了。仅用一步,我们就更改了文件中的日期格式。 它也是一个关于为什么有时候会开玩笑地把正则表达式称为是“只写”媒介的完美的例子。我们 能写正则表达式,但是有时候我们不能读它们。在我们恐惧地忍不住要逃离此命令之前,让我们看一下 怎样来构建它。首先,我们知道此命令有这样一个基本的结构:
sed 's/regexp/replacement/' distros.txt我们下一步是要弄明白一个正则表达式将要孤立出日期。因为日期是 MM/DD/YYYY 格式,并且 出现在文本行的末尾,我们可以使用这样的表达式:
[0-9]{2}/[0-9]{2}/[0-9]{4}$
此表达式匹配两位数字,一个斜杠,两位数字,一个斜杠,四位数字,以及行尾。如此关心
regexp
, 那么
replacement
又怎样呢?为了解决此问题,我们必须介绍一个正则表达式的新功能,它出现 在一些使用 BRE 的应用程序中。这个功能叫做
逆参照
,像这样工作:如果序列
\n
出现在
replacement
中 ,这里 n 是指从 1 到 9 的数字,则这个序列指的是在前面正则表达式中相对应的子表达式。为了 创建这个子表达式,我们简单地把它们用圆括号括起来,像这样:
([0-9]{2})/([0-9]{2})/([0-9]{4})$现在我们有了三个子表达式。第一个表达式包含月份,第二个包含某月中的某天,以及第三个包含年份。 现在我们就可以构建 replacement ,如下所示:
\3-\1-\2此表达式给出了年份,一个短划线,月份,一个短划线,和某天。
现在我们的命令看起来像下面这样:
sed 's/([0-9]{2})/([0-9]{2})/([0-9]{4})$/\3-\1-\2/' distros.txt我们还有两个问题。第一个是当 sed 试图解释这个 s 命令的时候在我们表达式中额外的斜杠将会使 sed 迷惑。 第二个是由于sed默认情况下只接受基本的正则表达式,在表达式中的几个字符会 被当作文字字面值,而不是元字符。我们能够通过反斜杠的自由应用来转义令人不快的字符解决这两个问题。
sed 's/\([0-9]\{2\}\)\/\([0-9]\{2\}\)\/\([0-9]\{4\}\)$/\3-\1-\2/' distros.txt
sed替换
s 命令的另一个功能是使用可选标志,其跟随替代字符串。一个最重要的可选标志是 g 标志,其 指示 sed 对某个文本行全范围地执行查找和替代操作,不仅仅是对第一个实例,这是默认行为。 这里有个例子:
[me@linuxbox ~]$ echo "aaabbbccc" | sed 's/b/B/'
aaaBbbccc我们看到虽然执行了替换操作,但是只针对第一个字母 “b” 实例,然而剩余的实例没有更改。通过添加 g 标志, 我们能够更改所有的实例:
[me@linuxbox ~]$ echo "aaabbbccc" | sed 's/b/B/g'
aaaBBBccc

sed脚本
目前为止,通过命令行我们只让 sed 执行单个命令。使用-f 选项,也有可能在一个脚本文件中构建更加复杂的命令。 为了演示,我们将使用 sed 和 distros.txt 文件来生成一个报告。我们的报告以开头标题,修改过的日期,以及 大写的发行版名称为特征。为此,我们需要编写一个脚本,所以我们将打开文本编辑器,然后输入以下文字:
# sed script to produce Linux distributions report
1 i\
Linux Distributions Report\
s/\([0-9]\{2\}\)\/\([0-9]\{2\}\)\/\([0-9]\{4\}\)$/\3-\1-\2/
y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/我们将把 sed 脚本保存为 distros.sed 文件,然后像这样运行它:
[me@linuxbox ~]$ sed -f distros.sed distros.txt
Linux Distributions Report
SUSE 10.2 2006-12-07
FEDORA 10 2008-11-25
SUSE 11.0 2008-06-19
UBUNTU 8.04 2008-04-24
FEDORA 8 2007-11-08
SUSE 10.3 2007-10-04
UBUNTU 6.10 2006-10-26
FEDORA 7 2007-05-31
UBUNTU 7.10 2007-10-18
UBUNTU 7.04 2007-04-19
SUSE 10.1 2006-05-11
FEDORA 6 2006-10-24
FEDORA 9 2008-05-13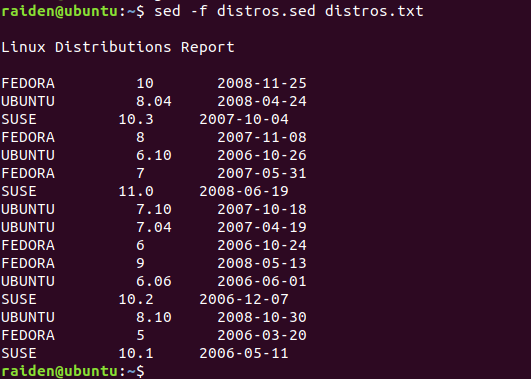
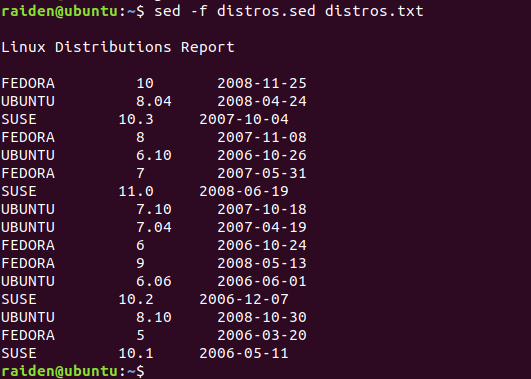
正如我们所见,我们的脚本文件产生了期望的结果,但是它是如何做到的呢?让我们再看一下我们的脚本文件。 我们将使用 cat 来给每行文本编号:
[me@linuxbox ~]$ cat -n distros.sed
1 # sed script to produce Linux distributions report