|
|
|


在文本分类任务中,有哪些论文中很少提及却对性能有重要影响的tricks?
这些tricks可能位于预处理环节、神经网络的结构中、梯度计算和优化环节、参数初始化环节、超参选取环节等。
关注者
2,965
被浏览
264,088
22 个回答

知乎用户

提一个 too trivial for a paper 的点。之前在魔改 Tensorflow 的 Adam 时发现了这个问题,AllenNLP 也在 2018 EMNLP 的 Tutorial 里面提到。
和图像等领域不同,对 NLU 之类的任务,每个 batch 采样到的词有限,每次更新对 Embedding 的梯度估计都是稀疏的。非 momentum-based 的 Optimizer 每步只会更新采样到的词,而对于 momentum-based 的 Optimizer,现在所有框架的实现都会用当前的 momentum 去更新所有的词,即使这些词在连续的几十步更新里都没有被采样到。这可能会使 Embedding 过拟合。
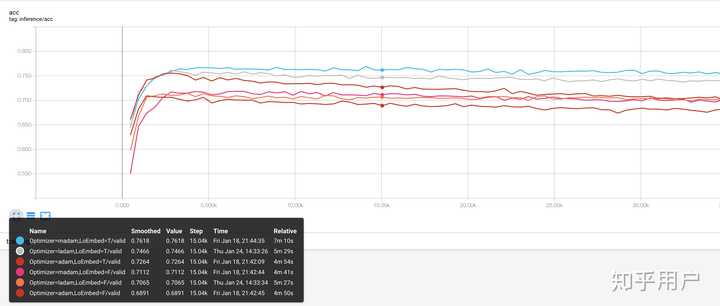
下面是一个文本分类问题在不同 setting 下对应的 valid set 准确率曲线。learning rate 固定不变。madam 指的是修正过后的 adam,LoEmbed 表示是否加载预训练的词向量。在加载词向量的 setting 下,不加修正的 Adam 过拟合的不能看。

给伸手党的代码:
# for tensorflow 1.12.0
from tensorflow.python.ops import array_ops
from tensorflow.python.training import adam
from tensorflow.python.framework import ops
from tensorflow.python.ops import control_flow_ops
from tensorflow.python.ops import math_ops
from tensorflow.python.ops import resource_variable_ops
from tensorflow.python.ops import state_ops
from tensorflow.python.ops import variable_scope
from tensorflow.python.training import optimizer
class MaskedAdamOptimizer(adam.AdamOptimizer):
def _apply_sparse_shared(self, grad, var, indices, scatter_add):
beta1_power, beta2_power = self._get_beta_accumulators()
beta1_power = math_ops.cast(beta1_power, var.dtype.base_dtype)
beta2_power = math_ops.cast(beta2_power, var.dtype.base_dtype)
lr_t = math_ops.cast(self._lr_t, var.dtype.base_dtype)
beta1_t = math_ops.cast(self._beta1_t, var.dtype.base_dtype)
beta2_t = math_ops.cast(self._beta2_t, var.dtype.base_dtype)
epsilon_t = math_ops.cast(self._epsilon_t, var.dtype.base_dtype)
lr = (lr_t * math_ops.sqrt(1 - beta2_power) / (1 - beta1_power))
# m_t = beta1 * m + (1 - beta1) * g_t
m = self.get_slot(var, "m")
m_scaled_g_values = grad * (1 - beta1_t)
m_t = state_ops.assign(m, m * beta1_t,
use_locking=self._use_locking)
with ops.control_dependencies([m_t]):
m_t = scatter_add(m, indices, m_scaled_g_values)
# v_t = beta2 * v + (1 - beta2) * (g_t * g_t)
v = self.get_slot(var, "v")
v_scaled_g_values = (grad * grad) * (1 - beta2_t)
v_t = state_ops.assign(v, v * beta2_t, use_locking=self._use_locking)
with ops.control_dependencies([v_t]):