


华中科大提出CE-FPN:通道增强特征金字塔网络

提出三大模块:亚像素跳跃融合模块,亚像素上下文增强模块,通道注意力指导模块,可助力基于FPN的检测器涨点!优于AugFPN等同类工作。
注1:文末附【目标检测】交流群
注2:整理不易,欢迎点赞,支持分享!
想看更多CVPR 2021论文和开源项目可以点击:
CE-FPN: Enhancing Channel Information for Object Detection


作者单位:华中科技大学, 河南大学
论文: https:// arxiv.org/abs/2103.1064 3
特征金字塔网络(FPN)已经成为提取目标检测中多尺度特征的有效框架。然而,当前基于FPN的方法大多遭受通道减少的固有缺陷,这带来了语义信息的丢失。并且其他融合特征图可能会导致严重的混叠效果。
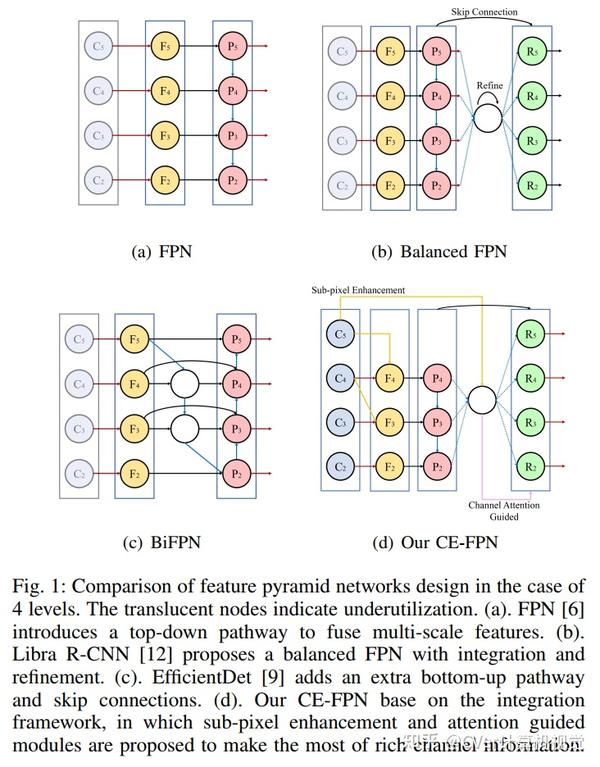

在本文中,我们提出了一种新颖的通道增强特征金字塔网络(CE-FPN),该网络具有三个简单而有效的模块来缓解这些问题。
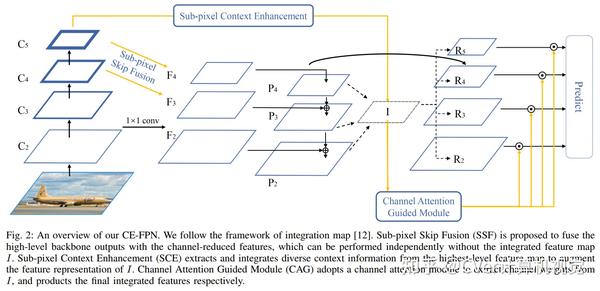

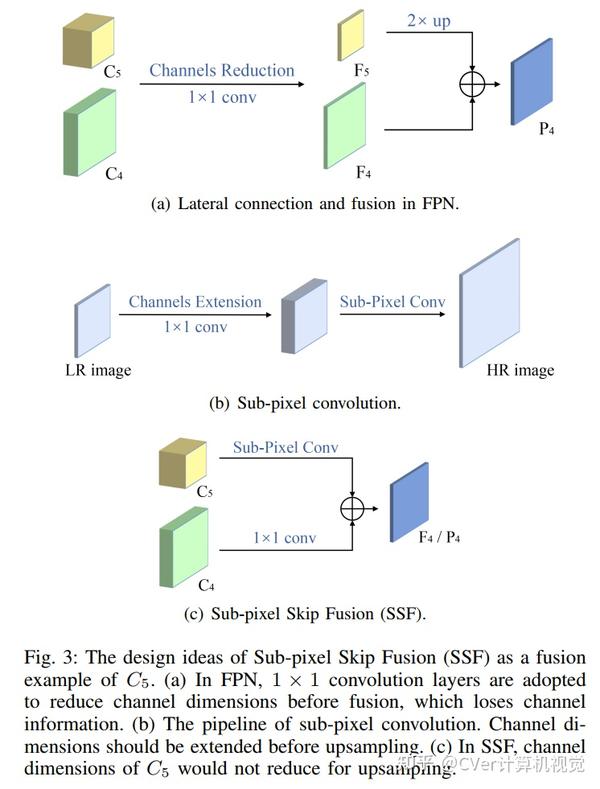
具体而言,受亚像素卷积的启发,我们提出了一种 亚像素跳跃融合方法(SSF) ,可同时执行通道增强和上采样。代替原始的1x1卷积和线性上采样,它可以减轻由于信道减少而导致的信息丢失。

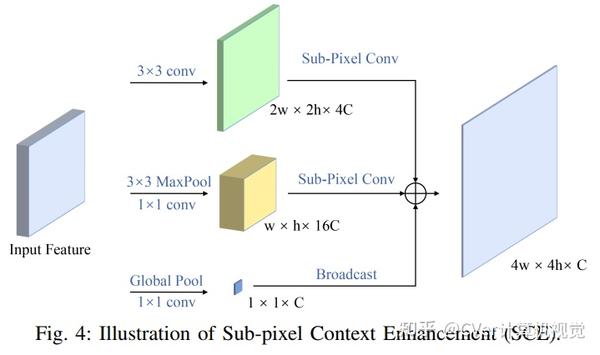
然后,我们提出了一种 亚像素上下文增强模块(SCE) ,用于提取更多的特征表示,由于亚像素卷积利用了丰富的通道信息,因此优于其他上下文方法。

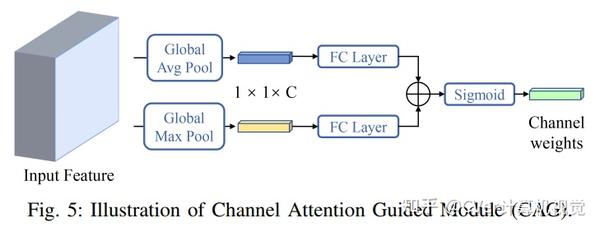
此外,引入了一个 通道注意力指导模块(CAG) 来优化每个级别上的最终集成特征,从而仅在少量计算负担的情况下减轻了混叠效应。

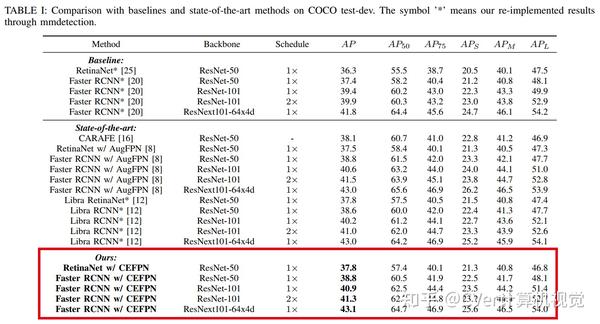
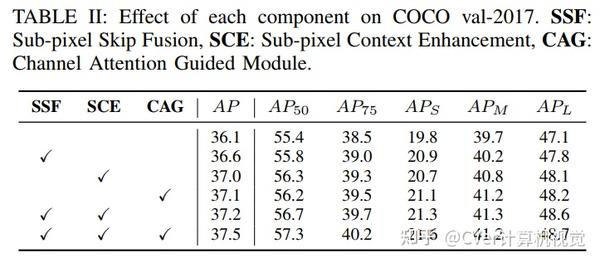
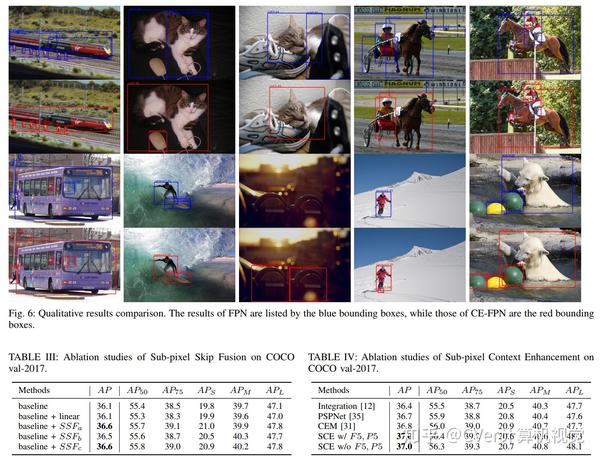
实验结果
我们的实验表明,与MS COCO基准上最先进的基于FPN的检测器相比,CE-FPN具有竞争优势。



CVer-目标检测交流群
建了CVer-目标检测交流群!想要进目标检测学习交流群的同学,可以直接加微信号: CVer9999 。加的时候备注一下: 目标检测+学校/公司+昵称 ,即可。然后就可以拉你进群了。
强烈推荐大家关注 CVer知乎 账号和 CVer 微信公众号,可以快速了解到最新优质的CV论文。
推荐阅读
谷歌大脑提出:理解用于图像分类的Transformer的鲁棒性
CVPR 2021 | Sewer-ML:多标签下水道缺陷分类数据集和基准
性能没到SOTA!POET:基于Transformer的端到端可训练多人体姿态估计
CVPR 2021 | 使用Transformer和自监督学习改进跨模态食谱检索
屠榜各大CV任务!Swin Transformer:层次化视觉Transformer
一张图等于16x16个字,那一个视频呢?STAM:基于Transformer的行为识别新网络
视觉Transformer可以在没有自然图像的情况下学习吗?
DeepMind提出DetCon:用于高效视觉预训练的对比检测
Transformer再下一城!VolT:用于多视图3D重建的3D Volume Transformer
商汤提出CeiT:将卷积设计整合到视觉Transformers中
新Backbone来了!谷歌提出HaloNets:缩放局部自注意力获得超强视觉Backbone | CVPR 2021 Oral
CVPR 2021 Oral | Transformer遇见跟踪器:利用时间上下文进行视觉追踪
无卷积!PoseFormer:第一个基于时空Transformer的3D人体姿态估计
CVPR 2021 | ReDet:用于遥感目标检测的旋转等变检测器
TransFG:首个基于Transformer的细粒度视觉识别网络
CVPR 2021 | 全新Backbone!ReXNet:助力CV任务全面涨点
56.4 AP!超越YOLOv4,更快更强的CenterNet2来了!
谷歌新论文石锤Transformer!别只看注意力,没有残差和MLP,它啥都不是
CVPR 2021 | 自监督学习新方法!Kakao提出SCRL:空间一致表示学习
TransMed:Transformer推动多模态医学图像分类
CVPR 2021 | 真内卷!Involution:反转卷积的固有性以进行视觉识别
CVPR 2021 Oral | 何恺明等提出SimSiam:探索简单的孪生表示学习
CVPR 2021 Oral | Transformer再突破!美团等提出VisTR:视频实例分割网络
CVPR 2021 | WebFace260M:百万级人脸识别数据集和基准
CVPR 2021 | 旷视提出GID:用于目标检测的通用实例蒸馏
Facebook提出SEER:10亿参数,10亿张图,无需标记,自监督训练数据集!
CoTr:基于CNN和Transformer进行3D医学图像分割
新视觉任务!CVPR 2021 Oral | OWOD:面向开放世界的目标检测
CV和NLP通吃!谷歌提出OmniNet:Transformers的全方位表示
CVPR 2021 | Transformer进军low-level视觉!北大华为等提出预训练模型IPT
华为诺亚提出TNT:Transformer in Transformer
Transformer携手Evolving Attention在CV与NLP领域全面涨点!
视觉Transformer再升级!美团提出CPVT:条件位置编码Transformer
无卷积!金字塔视觉Transformer(PVT):用于密集预测的多功能backbone
Transformer is All You Need:使用统一Transfomer的多模态多任务学习
更深、更轻量级的Transformer!Facebook提出:DeLighT
基于深度学习的单图像超分辨率:全面综述(2014-2020)
视觉Transformer上榜!DeepMind科学家:2020年AI领域十大研究进展
没有卷积!TransGAN:首个基于纯Transformer的GAN网络
最强ResNet变体!归一化再见!DeepMind提出NFNet,代码已开源!
Facebook提出:基于视觉Transformer的图像检索
效果远超Transformer!AAAI 2021最佳论文Informer:最强最快的序列预测神器
DeepMind重新设计高性能ResNet!无需激活归一化层
T2T-ViT:在ImageNet上从头训练视觉Transformer
84.7%!BoTNet:视觉识别的Bottleneck Transformers
